JDK源码分析 – LinkedList
LinkedList类的申明
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
}
LinkedList实现的接口与ArrayList大同小异,其中一个重要的接口Deque<E>,这个接口表示一个双向队列,也就是说LinkedList也是一个双向队列,实现了双向队列两端的增加、删除操作。
LinkedList主要字段、属性说明
//记录LinkedList当前节点数
transient int size = 0; /**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
//第一个节点
transient Node<E> first; /**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
//最后一个节点
transient Node<E> last;
到这里,基本可以看出来LinkedList内部使用的是双向链表的数据结构,定义了一个头节点和为节点,应用时可以通过头节点顺序遍历整个链表,也可以通过尾节点逆序遍历链表,对链表做一系列操作,所以LinkedList内部的数据结构如下:
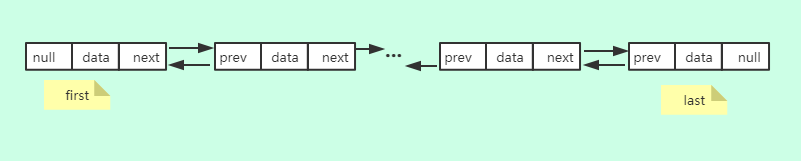
LinkedList部分方法分析
构造函数
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
LinkedList提供了两个构造函数,无参构造函数默认初始化一个空的链表,LinkedList(Collection<? extends E> c)构造函数调用无参构造函数初始化链表,并将参数集合添加到链表中,内部通过addAll方法实现。
add(E e)、add(int index, E element)、addAll(Collection<? extends E> c)、addAll(int index, Collection<? extends E> c)
- add(E e):将指定的元素追加到此列表的末尾
public boolean add(E e) {
//将元素添加到链表末尾
linkLast(e);
return true;
}
void linkLast(E e) {
//定义l节点,将尾节点暂存在该节点上
final Node<E> l = last;
//创建一个新节点,用于存储将要添加的元素,该节点前驱指向原先的尾节点l
final Node<E> newNode = new Node<>(l, e, null);
//重新赋值链表的为节点,更新为新创建的节点
last = newNode;
//如果尾节点为空,则说明该链表是一个空链表,那么需要为头节点初始化
if (l == null)
first = newNode; //此时链表只有一个节点,first和last是同一个节点
else
l.next = newNode; //将原先尾节点的后继指向新创建的节点
//链表长度自增
size++;
//操作数自增,用于迭代器迭代校验
modCount++;
}
学过数据结构的上面这段代码很容易理解,都是单纯的链表操作
- add(int index, E element):将指定元素插入此列表中的指定位置
public void add(int index, E element) {
//校验索引是否合法
checkPositionIndex(index);
//如果索引index和链表长度相同,那么相当于在链表为节点添加元素
if (index == size)
//将元素添加到为节点,同add()方法内部实现
linkLast(element);
else
/创建新节点,并插入到链表指定索引处
linkBefore(element, node(index));
}
//获取原先索引为index的节点
Node<E> node(int index) {
// assert isElementIndex(index);
//如果索引indec位于链表前半段,则
if (index < (size >> 1)) {
Node<E> x = first;
//正向遍历找到索引为index的节点并返回
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
//如果index位于链表后半段,则逆向遍历,查找索引为index的节点,并返回
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//插入新节点
//E e:将要插入的元素
// Node<E> succ 原先index索引处的节点
void linkBefore(E e, Node<E> succ) {
//获取index-1的节点(该节点将作为即将要插入节点的前驱)
final Node<E> pred = succ.prev;
//构造新节点,并初始化前驱节点为第index-1的节点,后继节点为之前第index的节点
final Node<E> newNode = new Node<>(pred, e, succ);
//修改原先index的前驱节点,指向新创建的节点
succ.prev = newNode;
//判断第index-1的节点,如果为空,则说明之前链表首节点为空,重新赋值首节点
if (pred == null)
first = newNode;
else
//将第index-1的节点后继指向新创建的节点
pred.next = newNode;
size++;
modCount++;
}
这也是一个链表操作,主要就是在之前第index-1和第index两个节点之间插入一个新节点,并修改这三个节点的前驱和后继指针,使双向链表完整。
其他几个add相关的方法:
- addAll(Collection<? extends E> c):将指定集合中的所有元素按指定集合的迭代器返回的顺序附加到此列表的末尾
- addAll(int index, Collection<? extends E> c):从指定位置开始,将指定集合中的所有元素插入此列表
- addFirst(E e):在此列表的开头插入指定的元素
- addLast(E e):将指定的元素追加到此列表的末尾
remove()、remove(int index)、remove(Object o)、removeFirst()、removeLast()
- remove(int index):删除此列表中指定位置的元素,实现过程如下:
public E remove(int index) {
//校验索引的合法性
checkElementIndex(index);
//移除当前索引处的节点, node(index)获取索引index处的节点
return unlink(node(index));
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
unlink(Node<E> x) {
// assert x != null;
//暂存index处的节点
final E element = x.item;
//暂存index+1节点,后继节点
final Node<E> next = x.next;
//暂存第index-1节点,前驱节点
final Node<E> prev = x.prev;
//1处理前驱:如果pre节点为空,则说明x就是首节点
if (prev == null) {
//直接将原先的后继next赋值到首节点上即可
first = next;
} else {
//将index-1的后继指向index+1
prev.next = next;
//删除index节点的前驱
x.prev = null;
}
//2处理后继:如果next为空,说明x就是为节点
if (next == null) {
//直接将last赋值为原先节点的前驱
last = prev;
} else {
//将第index+1的前驱执行第index-1节点
next.prev = prev;
x.next = null;
}
//删除节点x的数据
x.item = null;
//链表长度-1
size--;
modCount++;
return element;
}
删除指定索引处的节点的实现过程就是将该节点的前驱前驱节点和后继接单 通过pre和next域连接起来。
其他几个remove相关的方法:
- remove():检索并删除此列表的头部(第一个元素)。
- remove(Object o):从该列表中删除指定元素的第一个匹配项(如果存在)。
- removeFirst():从此列表中删除并返回第一个元素。
- removeLast():从此列表中删除并返回最后一个元素。
前面一节我也分析过ArrayList的源码,那么LinkedList与ArrayList相比较有哪些区别呢:
LiskedList内部是基于双向链表的存储结构,而ArrayList是基于动态数据的数据结构。
对于增加删除元素操作,ArrayList中添加和删除涉及到index+1~length-1个元素向后或向前移动,LinkedList只需要添加或删除节点,这点上优于ArrayList(尾部情况特殊,arrayList操作尾部不不要移动数据)。
对其读取和修改操作,ArrayList实现RandomAccess接口,支持高效的随机访问,而LinkedList只能通过指针遍历。
分配空间上ArrayList的扩容策略会预先分配一定量的闲置空间,linkedlist的则是按节点按需分配。
JDK源码分析 – LinkedList的更多相关文章
- 【JDK】JDK源码分析-LinkedList
概述 相较于 ArrayList,LinkedList 在平时使用少一些. LinkedList 内部是一个双向链表,并且实现了 List 接口和 Deque 接口,因此它也具有 List 的操作以及 ...
- JDK源码分析(三)—— LinkedList
参考文档 JDK源码分析(4)之 LinkedList 相关
- JDK源码分析(2)LinkedList
JDK版本 LinkedList简介 LinkedList 是一个继承于AbstractSequentialList的双向链表.它也可以被当作堆栈.队列或双端队列进行操作. LinkedList 实现 ...
- JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue
JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue 目的:本文通过分析JDK源码来对比ArrayBlockingQueue 和LinkedBlocki ...
- JDK 源码分析(4)—— HashMap/LinkedHashMap/Hashtable
JDK 源码分析(4)-- HashMap/LinkedHashMap/Hashtable HashMap HashMap采用的是哈希算法+链表冲突解决,table的大小永远为2次幂,因为在初始化的时 ...
- JDK源码分析(一)—— String
dir 参考文档 JDK源码分析(1)之 String 相关
- 【JDK】JDK源码分析-LinkedHashMap
概述 前文「JDK源码分析-HashMap(1)」分析了 HashMap 主要方法的实现原理(其他问题以后分析),本文分析下 LinkedHashMap. 先看一下 LinkedHashMap 的类继 ...
- 【JDK】JDK源码分析-HashMap(1)
概述 HashMap 是 Java 开发中最常用的容器类之一,也是面试的常客.它其实就是前文「数据结构与算法笔记(二)」中「散列表」的实现,处理散列冲突用的是“链表法”,并且在 JDK 1.8 做了优 ...
- 【JDK】JDK源码分析-TreeMap(2)
前文「JDK源码分析-TreeMap(1)」分析了 TreeMap 的一些方法,本文分析其中的增删方法.这也是红黑树插入和删除节点的操作,由于相对复杂,因此单独进行分析. 插入操作 该操作其实就是红黑 ...
随机推荐
- Redis集群进阶之路
Redis集群规范 本文档基于Redis 3.X或更高版本,讲解Redis集群算法以及设计原理.此官方文档长期更新且随着Redis新版本特性的变化变动,详细请留意官网. 官网地址:https://re ...
- ActivatedRoute 当前激活的路由对象
ActivatedRoute,当前激活的路由对象,主要用于保存路由,获取路由传递的参数. 一:传递参数的三种方式,以及ActivatedRoute获取他们的方式: 1.在查询参数中传递数据: /pro ...
- 在树莓派上用 python 做一个炫酷的天气预报
教大家如何在树莓派上自己动手做一个天气预报.此次教程需要大家有一定的python 基础,没有也没关系,文末我会放出我已写好的代码供大家下载. 首先在开始之前 需要申请高德地图API,去高德地图官网注册 ...
- flask的查询,一对多,多对多
模型的关联: 一对多 class Role(db.Model): us = db.relationship('User',backref='role',lazy='dynamic') class Us ...
- java instanceof 的理解
简单来说,java 中的instanceof 运算符是用来在运行时指出对象是否是特定类的一个实例.instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例. 用法 ...
- js input 不可编辑可传值设置
在表单提交中,设置input不可编辑,但是可以向后台传输数据,的设置方法: $('#input').attr("readonly",true);
- E. Almost Regular Bracket Sequence
题目链接:http://codeforces.com/contest/1095/problem/E 解题心得: 刚开始拿到这个题的时候还真的没什么思路,后来仔细想想还是比较简单的.首先题目要求翻转一个 ...
- Developing iOS 8 Apps with Swift (stanford)
https://www.youtube.com/watch?v=JkiB8Zwk-9Q&index=2&list=PLcX0opNQliFl0RTGbY9HHWCFg0Q8_fIF4
- Java:内存泄露和内存溢出
1. 内存溢出 (Memory Overflow) 是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory:比如申请了一个integer,但给它存了long才能存下的数,那就 ...
- C#函数库
//读取文本文件并返回内容不同的那一行 public static String different(String sOldFile, String sNewFile) ...