HADOOP (十一).安装hbase
下载安装包并解压
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.3.1/hbase-1.3.1-bin.tar.gz
…..
[hbase@hadoop1 opt]$ tar -zxvf hbase-1.3.1-bin.tar.gz
设置hbase环境变量
[hbase@hadoop1 opt]$ cd hbase-1.3.1/conf/
[hbase@hadoop1 conf]$ vi hbase-env.sh
#### 看情况设置以下环境变量:
#export JAVA_HOME=/usr/java/jdk1.6.0/
#export HBASE_HEAPSIZE=1G #堆内存
#export HBASE_OPTS="-XX:+UseConcMarkSweepGC" #jvm启动参数
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hmaster
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hregionserver
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps" #gc相关
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" #java 参数不太懂,自行修正
…………….
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.3.1/hbase-1.3.1-bin.tar.gz
…..
[hbase@hadoop1 opt]$ tar -zxvf hbase-1.3.1-bin.tar.gz
[hbase@hadoop1 opt]$ cd hbase-1.3.1/conf/
[hbase@hadoop1 conf]$ vi hbase-env.sh
#### 看情况设置以下环境变量:
#export JAVA_HOME=/usr/java/jdk1.6.0/
#export HBASE_HEAPSIZE=1G #堆内存
#export HBASE_OPTS="-XX:+UseConcMarkSweepGC" #jvm启动参数
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hmaster
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hregionserver
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps" #gc相关
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" #java 参数不太懂,自行修正
…………….参数较多,请逐个检查.
最重要的就是JAVA_HOME,但我在/etc/profile里设置了,这里就不管了.
由于是做实验,这里我就设置一下log目录.关于hbase-evn.sh的设置,以后会详细讲解.
export HBASE_LOG_DIR=/var/log/hbase/
注意:如果没有在/etc/profile中设置HADOOP_CONF_DIR,则需要在hbase-evn.sh中设置HADOOP_CONF_DIR,否则hbase读不到hdfs-site.xml,无法找到hdfs.或者将hdfs-site.xml复制到$HBASE_HOME/conf/下也行.这里的hdfs-site.xml用客户端的配置即可.
配置hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop3,hadoop4,hadoop5</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>HBASE_MANAGES_ZK</name>
<value>false</value>
</property>
</configuration>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop3,hadoop4,hadoop5</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>HBASE_MANAGES_ZK</name>
<value>false</value>
</property>
</configuration>
上面的参数意思分别是:
hbase在hdfs的主目录
zookeeper服务器节点
hbase在zookeeper中的目录
hbase是否是分布式的
是否用hbase自带的zookeeper
启动hbase
首先使用hdfs账号为hbase授权:
[hdfs@hadoop2 root]$ hdfs dfs -mkdir /hbase
[hdfs@hadoop2 root]$ hdfs dfs -chown hbase:hbase /hbase在hadoop1上启动master:
[hbase@hadoop1 hbase-1.3.1]$ bin/hbase-daemon.sh start master在hadoop3 hadoop4 hadoop5上启动hreigonserver:
[hbase@hadoop3 hbase-1.3.1]$ bin/hbase-daemon.sh start regionserver在需要的节点上启动master备份节点:
bin/hbase-daemon.sh start master --backup检测hbase启动情况
1.jps检查
[hbase@hadoop1 hbase-1.3.1]$ jps
25914 HMaster
[hbase@hadoop3 hbase-1.3.1]$ jps
12623 HRegionServe看到master和regionserver都启动了
2.打开hbase web
打开:http://hadoop1:16010/
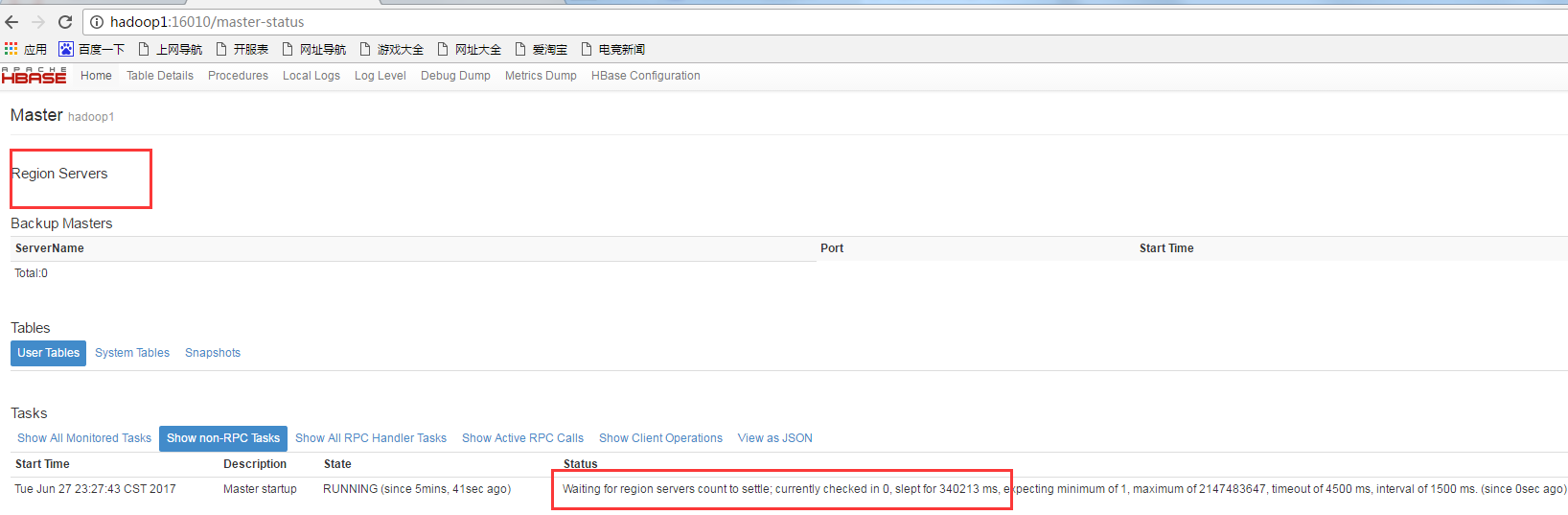
发现没有一个hregoinser连接上master!!!
好吧,打开/var/log/hbase/下的regionserver日志发现:
2017-06-27 23:16:51,039 FATAL [regionserver/hadoop3/192.168.0.12:16020] regionserver.HRegionServer: Master rejected startup because clock is out of sync
org.apache.hadoop.hbase.ClockOutOfSyncException: org.apache.hadoop.hbase.ClockOutOfSyncException: Server hadoop3,16020,1498576600617 has been rejected; Reported time is too far out of sync with master. Time difference of 54158ms > max allowed of 30000ms
at org.apache.hadoop.hbase.master.ServerManager.checkClockSkew(ServerManager.java:410)
at org.apache.hadoop.hbase.master.ServerManager.regionServerStartup(ServerManager.java:276)
at org.apache.hadoop.hbase.master.MasterRpcServices.regionServerStartup(MasterRpcServices.java:363)
at org.apache.hadoop.hbase.protobuf.generated.RegionServerStatusProtos$RegionServerStatusService$2.callBlockingMethod(RegionServerStatusProtos.java:8615)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2339)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:123)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:188)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:168)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:95)
at org.apache.hadoop.hbase.protobuf.ProtobufUtil.getRemoteException(ProtobufUtil.java:332)
at org.apache.hadoop.hbase.regionserver.HRegionServer.reportForDuty(HRegionServer.java:2337)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:929)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.ClockOutOfSyncException): org.apache.hadoop.hbase.ClockOutOfSyncException: Server hadoop3,16020,1498576600617 has been rejected; Reported time is too far out of sync with master. T
ime difference of 54158ms > max allowed of 30000ms
at org.apache.hadoop.hbase.master.ServerManager.checkClockSkew(ServerManager.java:410)
at org.apache.hadoop.hbase.master.ServerManager.regionServerStartup(ServerManager.java:276)原因是regionser和master的时间差太多了!又检查了一下,发现机器上的ntp服务挂了!!
设置各机器的时间:
date -s '2017-07-06 21:36:40'再次启动各进程,打开web页面,发现连接上master了:
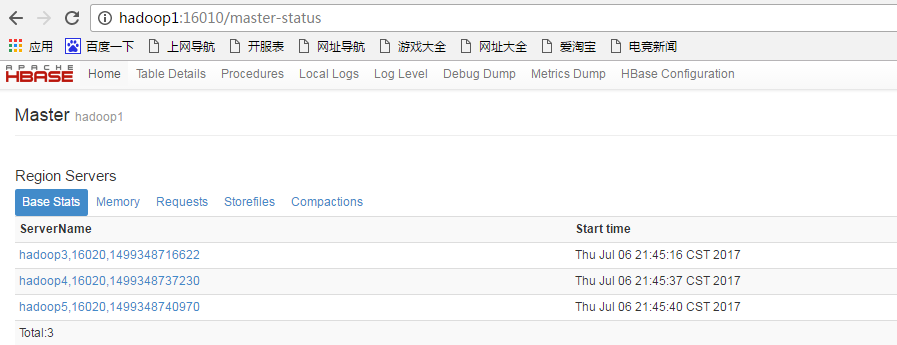
测试hbase shell
[hbase@hadoop5 hbase-1.3.1]$ bin/hbase shell
hbase(main):001:0> create 'test','cf1'
0 row(s) in 4.9050 seconds
=> Hbase::Table - test
hbase(main):002:0> list
TABLE
test
hbase(main):004:0> put 'test', 'row1', 'cf1:a', 'value1'
0 row(s) in 0.0170 seconds
hbase(main):005:0> put 'test', 'row2', 'cf1:b', 'value2'
0 row(s) in 0.0090 seconds
hbase(main):012:0* scan test
ArgumentError: wrong number of arguments (0 for 2)
hbase(main):013:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf1:a, timestamp=1499349174471, value=value1
row2 column=cf1:b, timestamp=1499349174533, value=value2
2 row(s) in 0.1140 seconds
[hbase@hadoop5 hbase-1.3.1]$ bin/hbase shell
hbase(main):001:0> create 'test','cf1'
0 row(s) in 4.9050 seconds
=> Hbase::Table - test
hbase(main):002:0> list
TABLE
test
hbase(main):004:0> put 'test', 'row1', 'cf1:a', 'value1'
0 row(s) in 0.0170 seconds
hbase(main):005:0> put 'test', 'row2', 'cf1:b', 'value2'
0 row(s) in 0.0090 seconds
hbase(main):012:0* scan test
ArgumentError: wrong number of arguments (0 for 2)
hbase(main):013:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf1:a, timestamp=1499349174471, value=value1
row2 column=cf1:b, timestamp=1499349174533, value=value2
2 row(s) in 0.1140 seconds
说明hbase能正常使用
HADOOP (十一).安装hbase的更多相关文章
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
- 在Hadoop伪分布式模式下安装Hbase
安装环境:Hadoop 1.2.0, Java 1.7.0_21 1.下载/解压 在hbase官网上选择自己要下的hbase版本,我选择的是hbase-0.94.8. 下载后解压到/usr/local ...
- hadoop生态圈安装详解(hadoop+zookeeper+hbase+pig+hive)
-------------------------------------------------------------------* 目录 * I hadoop分布式安装 * II zoo ...
- hadoop安装hbase
1.安装hadoop hadoop安装请参考我的centoos 安装hadoop集群 在安装hadoop的基础上新增了两台slave机器,新增后的配置为 H30(192.168.3.238) mast ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- Hadoop 伪分布式上安装 HBase
hbase下载:点此链接 (P.S.下载带bin的) 下载文件放入虚拟机文件夹,打开,放在自己指定的文件夹 -src.tar.gz -C /home/software/ 修改环境配置 gedit / ...
- hadoop备战:hbase的分布式安装经验
配置HBase时,首先考虑的肯定是Hbase版本号与你所装的hadoop版本号是否匹配.这一点我在之前 的博客中已经说明清楚,hadoop版本号与hbase版本号的匹配度,那是官方提供的.以下的实验就 ...
- WIN10下安装HBASE教程
工作需要,现在开始做大数据开发了,通过下面的配置步骤,你可以在win10系统中,部署出一套hadoop+hbase,便于单机测试调试开发. 准备资料: 1. hadoop-2.7.2: https:/ ...
随机推荐
- 基于MySql和Sails.js的RESTful风格的api实现
Sails.js是类似于express的node后台框架,她面向数据库的特性使得面向数据库的服务器的搭建变得特别简单快捷. 现在网上关于Sails的教程大多是基于V0.12版本的,但是现在Sails的 ...
- percona数据库监控工具的安装部署
Percona Monitoring and Management 安装 PMM是一个开源,免费的mysql管理监控平台,他可以用来分析mysql,mariadb和mongodb的服务器性能. 安装步 ...
- Flask中那些特殊的装饰器
模板相关的装饰器 @app.template_global() 用法: @app.template_global() # 记得加括号 def jiafa(a, b): # 这个方法每调用一次就需要传一 ...
- 【Spark】源码分析之RDD的生成及stage的切分
一.概述 Spark源码整体的逻辑(spark1.3.1): 从saveAsTextFile()方法入手 -->saveAsTextFile() --> saveAsHadoopFile ...
- 论反向ajax
在讨论反向ajax之前,说一下我大二写的一个聊天程序,通过前端ajax不断向服务器发送请求(通过http连接),服务器进行一次数据库查询,然后返回结果,断开与服务器的链接(绝大部分都是无用的结果)来维 ...
- 利用haohedi ETL将数据库中的数据抽取到hadoop Hive中
采用HIVE自带的apache 的JDBC驱动导入数据基本上只能采用Load data命令将文本文件导入,采用INSERT ... VALUES的方式插入速度极其慢,插入一条需要几十秒钟,基本上不可用 ...
- 2.1 摄像头V4L2驱动框架分析
学习目标:学习V4L2(V4L2:vidio for linux version 2)摄像头驱动框架,分析vivi.c(虚拟视频硬件相关)驱动源码程序,总结V4L2硬件相关的驱动的步骤: 一.V4L ...
- Linux常用服务器构建-samba(ubantu)
Samba是在Linux和UNIX系统上实现SMB协议的一个免费软件,由服务器及客户端程序构成.SMB(Server Messages Block,信息服务块)是一种在局域网上共享文件和打印机的一种通 ...
- 实现一个带有指纹加密功能的笔记本(Android)第二部分
上文基本完成了整个笔记本的笔记功能的实现,接下来记录实现指纹识别加密以及一些小注意事项. 首先判断该手机是否具备指纹识别的硬件功能和用户是否开启指纹识别. public boolean isFinge ...
- Java基础之进制转换
1.十进制与二进制之间的转换 (1)十进制转二进制的方法:使用十进制的数据不断除以2,直到商为0为止,从下往上取余就是对应的二进制. (2)二进制转十进制:使用二进制的每一位乘以2的n次方,n从0开始 ...