【合合TextIn】深度解析智能文档处理技术与应用

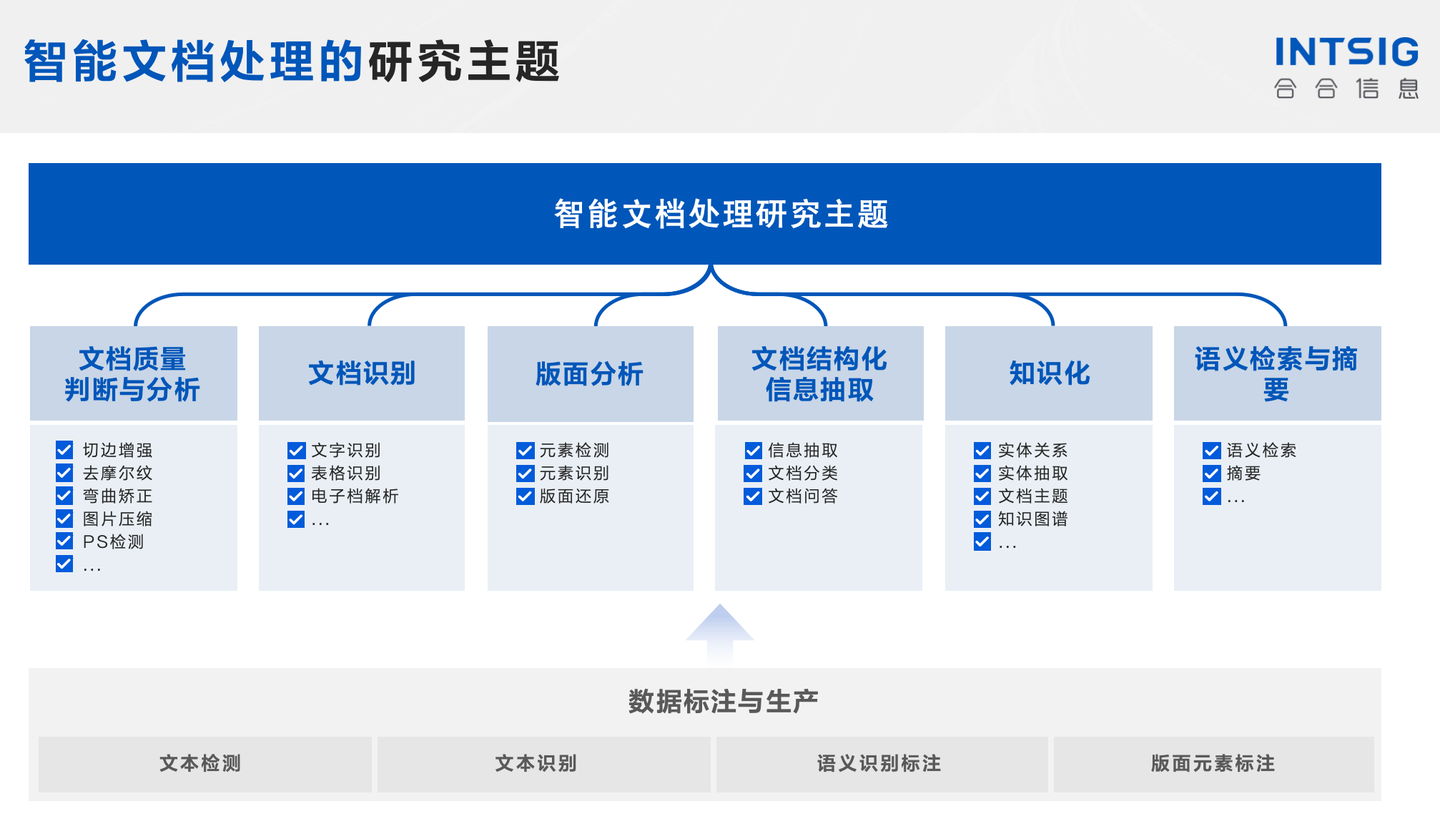
- 格式识别与转换:通过分析文件头信息或使用文件扩展名,确定文档的格式。针对特定格式的解析器将文档转换为统一的数据结构,以便进一步处理。
- 结构分析:识别和提取文档的逻辑结构,如章节、标题、段落、列表等。这一步骤通常需要利用机器学习或规则-based的方法来实现。
- 元数据提取:从文档中提取作者、创建日期、修改日期等元数据信息,这些信息在某些应用场景下非常重要。
- 嵌入元素处理:对文档中嵌入的图像、链接、表格等元素进行识别和提取。对于图像,可能需要调用OCR技术进行文字识别。
- 提高准确率:清晰的图像可以显著提高文字识别的准确率,尤其是对于低质量或受损图像。
- 降低处理难度:增强后的图像简化了后续处理步骤,如版面分析和信息提取,因为图像噪声和失真等问题已经得到了解决。
- 增强可用性:某些情况下,原始文档可能因为年代久远、存储条件不佳等原因变得难以阅读,图像增强技术可以恢复这些文档的可用性。
- 切边增强:切边增强是一种图像处理技术,通过增强图像中的边缘信息来提高图像的清晰度和对比度。该技术会突出显示图像中物体的边缘轮廓,使其更加清晰鲜明,从而改善图像的质量和可视效果。
- 去摩尔纹:去摩尔纹技术是一种用于消除图像中出现的摩尔纹现象的方法。摩尔纹是由于图像采样频率与被拍摄物体纹理之间的相互作用而产生的干扰,常见于数字图像和扫描图像中。去摩尔纹技术通过数学算法或滤波器处理来减少或消除这种干扰,从而提高图像的质量和清晰度。
- 弯曲矫正:弯曲矫正技术是一种用于修正图像中出现的弯曲或畸变现象的方法。在图像采集或传输过程中,由于设备或介质的问题,图像可能会发生弯曲或失真,影响图像的观感和应用效果。弯曲矫正技术通过数学模型或几何校正算法来对图像进行修正,使其恢复到原始状态或更接近真实场景,提高图像的可用性和可视化效果。
- 去模糊:去模糊技术是一种用于消除图像中模糊或不清晰部分的方法。图像模糊可能是由于摄像机晃动、焦点不准或运动模糊等因素引起的。去模糊技术通过分析图像模糊的原因并应用相应的算法或滤波器来恢复图像的清晰度和细节,使其更具可读性和观赏性。
- 锐化:锐化是一种图像处理技术,旨在增强图像中的边缘和细节,使图像更加清晰和逼真。该技术通过突出显示图像中的边缘和细节信息,增强图像的对比度和清晰度,从而改善图像的质量和观感效果。常见的锐化方法包括拉普拉斯变换、边缘增强滤波器等。
- 文字定位:通过检测图像中的文字区域,确定文字的位置和边界。这一步骤通常采用边缘检测、连通区域分析等技术,以识别出图像中的文字部分,并对其进行标记或边界框定位。
- 文字分割:将定位到的文字区域进行分割,将每个文字字符分离出来,为后续的文字识别做准备。文字分割通常使用投影分割、连通区域分割等方法,将文字区域划分为单个字符或单词。
- 特征提取:对分割后的文字字符进行特征提取,将文字字符转换成计算机可识别的特征向量或特征描述子。常用的特征提取方法包括形状特征、结构特征、灰度特征等,用于描述文字字符的形态和结构特征。
- 文字识别:利用模式识别算法,对提取到的文字特征进行分类和识别,将文字字符转换成对应的文本信息。
- 后处理与校正:对识别出的文字进行后处理和校正,包括语言模型校正、错别字纠正、格式规范化等操作,提高文字识别的准确性和可靠性。此步骤还可以结合语义分析和上下文理解,对识别结果进行进一步的语义校对和修正。
- 数据收集与标注:收集大规模的带有标注的图像数据集,包括不同字体、大小、颜色和背景的文字图像。这些图像需要经过手工标注,标注每个字符的位置和对应的文本内容,以用于深度学习模型的训练。
- 数据预处理:对收集到的图像数据进行预处理,包括图像去噪声、尺度归一化、灰度化、裁剪等操作,以减少数据的噪声和干扰,提高深度学习模型的训练效果。
- 模型选择与训练:选择合适的深度学习模型架构,如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)、转录者(Transformer)等,进行模型的训练和优化。在训练过程中,使用标注好的图像数据集,通过反向传播算法和梯度下降优化算法,不断调整模型参数,使其能够准确地识别文字。
- 模型评估与调优:通过验证集或测试集对训练好的深度学习模型进行评估,包括识别准确率、召回率、精确率等指标的评估。根据评估结果,对模型进行调优和改进,以提高模型的识别准确性和泛化能力。
- 部署与应用:将训练好的深度学习模型部署到实际应用环境中,例如移动设备、云服务器等,实现文字识别的功能。在部署过程中,需要考虑模型的计算资源消耗、响应速度和准确性等因素,以满足实际应用的需求。
- 持续优化与更新:持续监控和优化深度学习模型的性能,及时更新模型参数或架构,以适应新的数据分布和应用场景变化,保持模型的高效性和可靠性。
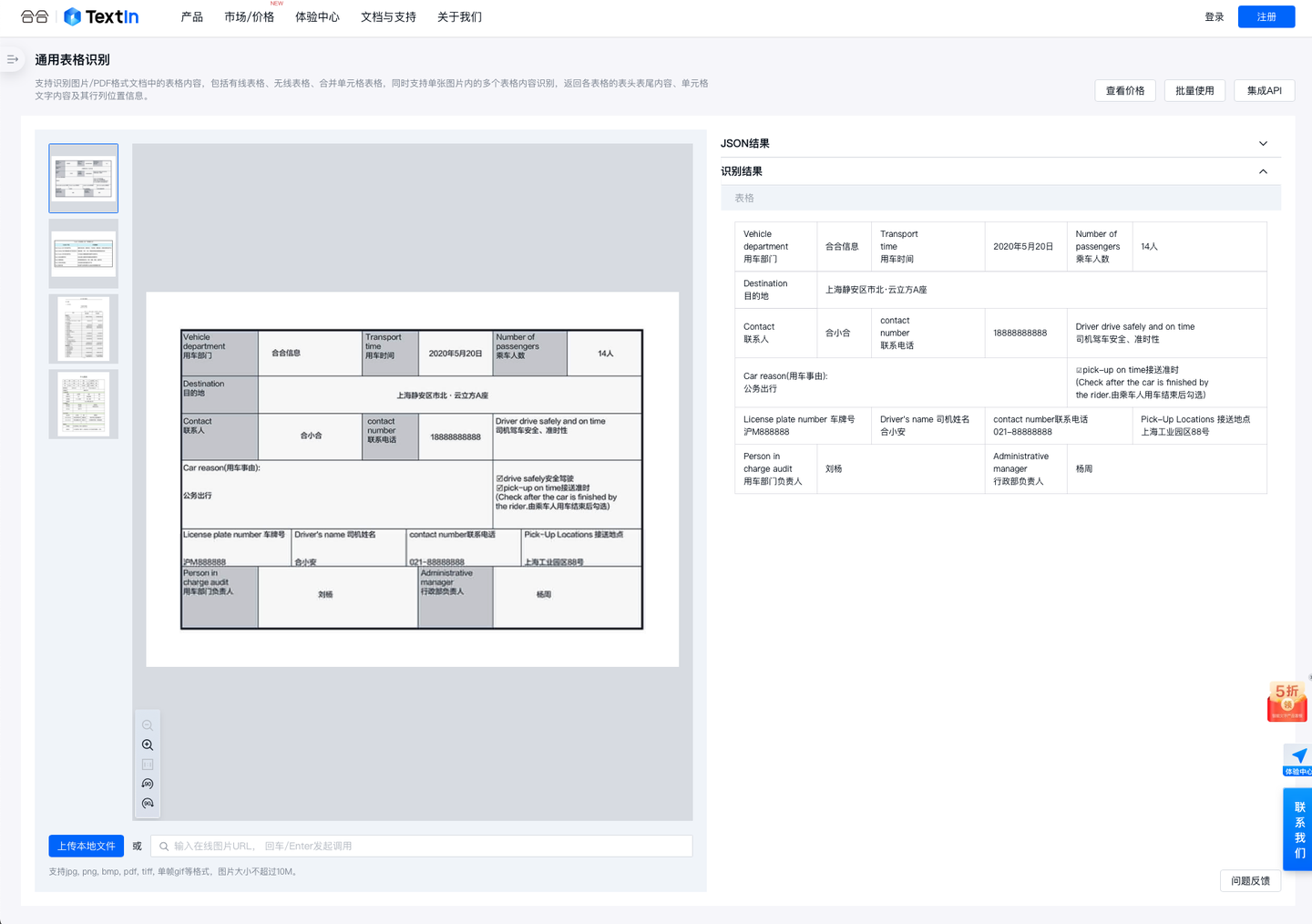
- 自动化内容提取:准确的版面分析为提取特定信息(如表格数据、标题、摘要等)提供了可能,进一步促进了文档自动化处理的实现。
- 元素检测:利用深度学习模型,如目标检测模型(如Faster R-CNN、YOLO、SSD等),对文档图像中的各种元素进行检测和定位。这些元素可以包括文字、图像、表格、标题等。通过元素检测,可以确定文档中不同元素的位置和边界框,为后续的分析和处理提供基础。
- 元素分类:对检测到的元素进行分类,区分文字、图像、表格等不同类型的元素。这一步骤可以采用深度学习中的图像分类模型或目标分类模型,对每个元素进行识别和分类,以便后续的结构解析和语义理解。
- 结构解析:在元素检测和分类的基础上,进行文档的结构解析,识别文档中不同元素之间的关系和层次结构。这包括文本段落与标题的对应关系、表格中不同字段的关系等。深度学习模型可以通过对文档布局和语义信息的分析,实现对文档结构的自动解析和理解。
- 版面校正:对检测到的文档元素进行版面校正,使其在整体文档中的位置和排布更加合理和统一。这一步骤可以包括文本对齐、图像矫正、表格对齐等操作,以提高文档的可读性和美观性。版面校正也可以通过深度学习模型来实现,例如基于生成对抗网络(GAN)的版面重构方法。
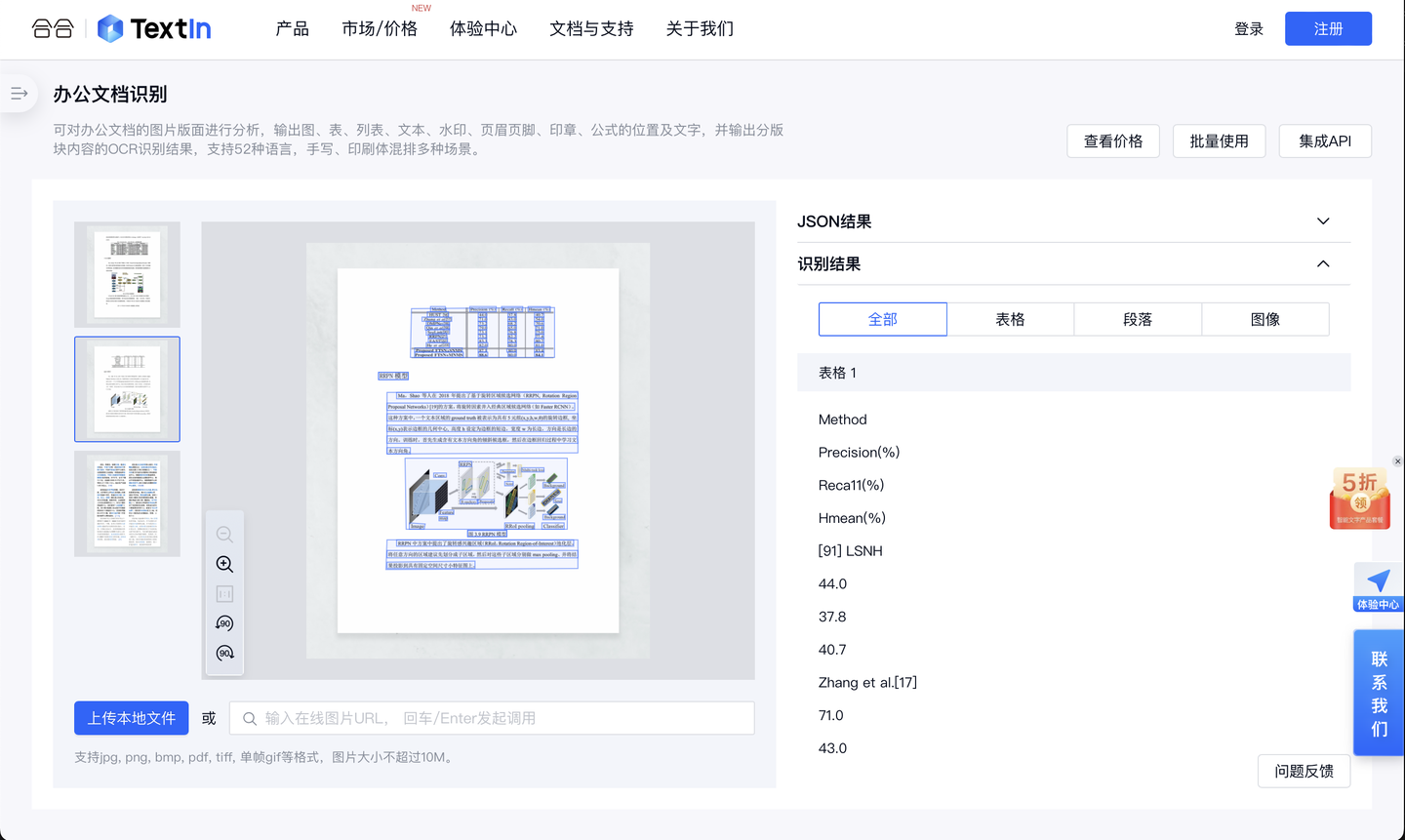
- 使用图片特征分类:图片特征的分类主要依赖于从文档中提取的视觉信息。这通常涉及到图像处理和计算机视觉技术,用于识别文档中的图形、布局和其他视觉元素。其中步骤包含特征提取、特征表示和降维、分类模型构建等步骤。
- 使用文本特征分类:文本特征的分类依赖于文档中的文字内容,涉及自然语言处理(NLP)技术,用于理解和分类文档的语义内容。其中步骤包含文本预处理、特征提取、模型构建、模型评估等步骤。

- 支持决策和分析:通过从大量文档中抽取关键信息,可以为决策制定和数据分析提供有价值的输入。
- 提高自动化程度:自动化的信息抽取减少了人工审核和录入的需要,提高了处理效率和准确性。
- 促进知识管理:信息抽取有助于构建知识库,支持知识检索和管理。
- 实体识别(Named Entity Recognition, NER):识别文本中的具名实体,如人名、地点和组织。
- 关系抽取:识别文本中实体之间的关系,如“公司-CEO”或“人物-出生地”等。
- 事件抽取:识别文本中的事件及其相关属性和参与实体,如事件类型、时间、地点和参与者等。
- 观点抽取(Opinion Mining):从文本中抽取观点、情感和评价,通常用于产品评论、市场分析等领域。
- 术语抽取:从专业文档中识别和提取关键术语和定义,用于构建术语库或知识图谱。
- 规则基础方法:早期的信息抽取系统主要依赖于手工编写的规则。这种方法在特定领域内效果明显,但缺乏通用性和扩展性。
- 机器学习方法:随着机器学习技术的发展,信息抽取开始采用监督学习、半监督学习和无监督学习方法。通过训练模型识别文本模式,提高了抽取的准确率和灵活性。
- 深度学习方法:近年来,基于深度学习的信息抽取方法成为研究热点,尤其是利用CNN、RNN和Transformer等神经网络模型。这些模型能够更好地理解文本的深层次语义,显著提高了信息抽取的性能。
- 端到端信息抽取:最新的研究趋势是开发端到端的信息抽取系统,这些系统能够直接从原始文本中抽取出结构化信息,无需复杂流程。

- 定义:应用程序接口(API)提供了一种让不同软件系统彼此通信的方法。通过开发和使用API,IDP系统可以将结构化数据直接发送到目标业务系统。
- 应用场景:实时数据传输、需要高度定制化集成的场景。
- 定义:一种基础但广泛使用的数据集成方法,涉及将数据导出为通用格式(如CSV、XML、JSON等),然后导入到目标系统。
- 应用场景:批量数据处理、非实时数据更新需求。
- 定义:直接通过数据库级别的操作,将IDP处理后的数据存储到企业的数据库系统中,再由各业务系统从数据库中读取所需数据。
- 应用场景:数据量大、需要长期存储和复用的场景。
- 场景:将客户相关的文档(如合同、通信记录)处理后的数据自动更新到客户关系管理(CRM)系统,以提供更准确的客户视图和服务。
- 技术方式:API集成、数据库集成。
- 场景:将发票、订单等财务文档处理后的数据自动录入企业资源计划(ERP)系统,简化财务流程,提高财务处理速度和准确性。
- 技术方式:文件导入/导出、API集成。
- 场景:将新闻、报告等内容文档处理后的数据自动归档和分类到内容管理系统(CMS),加速内容的发布流程。
- 技术方式:API集成、中间件技术。
- 场景:将处理后的数据集成到阿里云、百度云、AWS、Azure、Google Cloud等全球云平台提供的数据库和应用服务中,利用云平台的强大计算和存储能力支持企业的大数据分析和应用开发。
- 技术方式:API集成、中间件技术。
【合合TextIn】深度解析智能文档处理技术与应用的更多相关文章
- python之HTMLParser解析HTML文档
HTMLParser是Python自带的模块,使用简单,能够很容易的实现HTML文件的分析.本文主要简单讲一下HTMLParser的用法. 使用时需要定义一个从类HTMLParser继承的类,重定义函 ...
- 四种生成和解析XML文档的方法详解(介绍+优缺点比较+示例)
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml- ...
- 浅谈用java解析xml文档(四)
继续接上一文,这一阵子因为公司项目加紧,导致最后一个解析xml文档的方式,还没有总结,下面总结使用dom4J解析xml. DOM4J(Document Object Model for Java) 使 ...
- Java解析word文档
背景 在互联网教育行业,做内容相关的项目经常碰到的一个问题就是如何解析word文档. 因为系统如果无法智能的解析word,那么就只能通过其他方式手动录入word内容,效率低下,而且人工成本和录入出错率 ...
- 四种生成和解析XML文档的方法详解
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml- ...
- dom4j创建和解析xml文档
DOM4J解析 特征: 1.JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能. 2.它使用接口和抽象基本类方法. 3.具有性能优异.灵活性好.功能强大和极端易用的特点. 4.是一个开 ...
- Java高级特性 第15节 解析XML文档(3) - JDOM和DOM4J技术
一.JDOM解析 特征: 1.仅使用具体类,而不使用接口. 2.API大量使用了Collections类. Jdom由6个包构成: Element类表示XML文档的元素 org.jdom: 解析xml ...
- 大杂烩 -- 四种生成和解析XML文档的方法详解
基础大杂烩 -- 目录 众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J DOM:在现在的Java JDK里都自带了,在xml-apis.jar包 ...
- .Net解析html文档类库HtmlAgilityPack完整使用说明
在前几篇文章中([搜房网房产数据采集程序demo--GeckoWebBrowser实例] )都有提到一个解析html的C#类库HtmlAgilityPack, 今天终于有时间整理一下,并把Demo分享 ...
- 四种生成和解析XML文档的方法介绍
解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 1.DOM(Document Object Model) DOM是用与平台和语言无关的方式表示XML文档的官方 ...
随机推荐
- 洛谷P1020
又是一道做的很麻的题,准确来说感觉这不是一道很好的dfs题,没有体现dfs的一些特点 反而感觉是在考察dp,刚开始也是按照我的思路交了3次都没过 原本以为所选的数应该都是由上一次的最大值推出来的,后面 ...
- 基于Java“花鸣”B2C电子商务平台设计实现(源码+lw+部署文档+讲解等)
\n文末获取源码联系 感兴趣的可以先收藏起来,大家在毕设选题,项目以及论文编写等相关问题都可以给我加好友咨询 系统介绍: 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件 ...
- TIER 1: Responder
TIER 1: Responder Active Directory Active Directory(AD)是由微软开发的目录服务,用于在网络环境中管理和组织用户.计算机.应用程序和其他资源.它是 ...
- App如何利用推送消息有效实现拉新促活?
对于大多数App来说,如何快速建立与用户的联系.提高用户活跃度.提升用户转化率,是产品运营过程中十分关心的问题,在常见的运营手段中,Push推送消息以其高性价比成为首选策略.但在实际运营过程中,推送消 ...
- ffmpeg一些笔记: 代码调试数据
1.AAC,MP3他的解码数据格式不支持,程序中给的是这个AV_SAMPLE_FMT_FLTP, Screen-Cpature-Recoder的codec-id为AV_CODEC_RAW_VIDEO ...
- redis如何实现主从同步
redis实现主从同步分为两种:全量同步和增量同步:第一次连入集群的slave需要进行全量同步,那些断开后重连的slave需要进行增量同步 每个redis都有自己的replid,他们是master的标 ...
- 【Java】 Springboot+Vue 大文件断点续传
同事在重构老系统的项目时用到了这种大文件上传 第一篇文章是简书的这个: https://www.jianshu.com/p/b59d7dee15a6 是夏大佬写的vue-uploader组件: htt ...
- 【C3】02 操作总览
在这篇文章中,我们将会拿一个简单的HTML文档做例子,并且在上边使用CSS样式,期待你能在此过程中学会更多有关CSS的实战性知识. 前置知识 在开始本单元之前,您应该: 基本熟悉计算机操作. 基本工作 ...
- java多线程-补充-面试
1.背景 在这个课程之前我们已经讲了2个关于多线程的课程 一个是主要是关于多线程基础的: 另一个主要是关于JUC的: 今天我们对之前课程中没有讲到的或者重要的或者是童鞋们反馈的技术点做一个补充讲解 当 ...
- Apache DolphinScheduler 社区5月月报更新!
各位热爱 DolphinScheduler 的小伙伴们,社区5月份月报更新啦!这里将记录 DolphinScheduler 社区每月的重要更新,欢迎关注,期待下个月你也登上Merge Star月度榜单 ...