spark 怎么读写 elasticsearch
参考文章:
- https://www.bmc.com/blogs/spark-elasticsearch-hadoop/
- https://blog.pythian.com/updating-elasticsearch-indexes-spark/
- https://qbox.io/blog/elasticsearch-in-apache-spark-python 这里有 RDD level 的写法,有些操作比如count, aggregation 在 DataFrame/DataSet level 不支持pushdown, 所有需要用到RDD level 的写法
Pre-requisite:
先装上 elasticsearch-hadoop 包
Step-by-Step guide
1. 先在ES创建3个document
[mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/1 -d '{
"school" : "Clemson"
}'
[mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/2 -d '{
"school" : "Harvard"
}'
2. Spark 里面去读,这里是pyspark 代码
reader = spark.read.format("org.elasticsearch.spark.sql").option("es.read.metadata", "true").option("es.nodes.wan.only","true").option("es.port","your_port").option("es.net.ssl","false").option("es.nodes", "your_ip")
df = reader.load("school")
df.show()
输出这个格式的信息
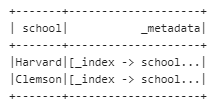
3. 接下来尝试update 一个记录,先得到一个要改的id
hot = df.filter(df["school"] == 'Harvard') \
.select(expr("_metadata._id as id")).withColumn('hot', lit(True))
hot.show()

4. 先来加一列
esconf={}
esconf["es.mapping.id"] = "id"
esconf["es.mapping.exclude"]='id'
esconf["es.nodes"] = "your_ip"
esconf["es.port"] = "your_port"
esconf["es.write.operation"] = "update"
esconf["es.nodes.discovery"] = "false"
esconf["es.nodes.wan.only"] = "true"
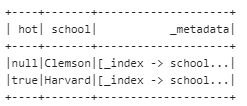
hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc")
看,成功加了 hot 列,满足条件的记录赋了对应的值
5. 又来update已经存在的信息
esconf={}
esconf["es.mapping.id"] = "id"
esconf["es.nodes"] = "your_ip"
esconf["es.port"] = "your_port"
esconf["es.update.script.inline"] = "ctx._source.school = params.school"
esconf["es.update.script.params"] = "school:<SCU>"
esconf["es.write.operation"] = "update"
esconf["es.nodes.discovery"] = "false"
esconf["es.nodes.wan.only"] = "true"
hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc")
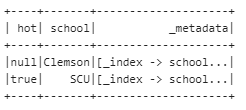
reader.load("school").show()
嗯。。。成功把Harvard改成了川大
另外,怎么upload attachment 到ES呢?可以用这个plugin Ingest Attachment Processor Plugin
END
spark 怎么读写 elasticsearch的更多相关文章
- 如何在spark中读写cassandra数据 ---- 分布式计算框架spark学习之六
由于预处理的数据都存储在cassandra里面,所以想要用spark进行数据分析的话,需要读取cassandra数据,并把分析结果也一并存回到cassandra:因此需要研究一下spark如何读写ca ...
- 【原创】大叔经验分享(26)hive通过外部表读写elasticsearch数据
hive通过外部表读写elasticsearch数据,和读写hbase数据差不多,差别是需要下载elasticsearch-hadoop-hive-6.6.2.jar,然后使用其中的EsStorage ...
- spark DataFrame 读写和保存数据
一.读写Parquet(DataFrame) Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源.前面的介绍中,我们已经涉及到了JSON.文本格式 ...
- spark block读写流程分析
之前分析了spark任务提交以及计算的流程,本文将分析在计算过程中数据的读写过程.我们知道:spark抽象出了RDD,在物理上RDD通常由多个Partition组成,一个partition对应一个bl ...
- 6.3 使用Spark SQL读写数据库
Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源 一.通过JDBC连接数据库 1.准备工作 ubuntu安装mysql教程 在Linux中启动M ...
- kafka spark steam 写入elasticsearch的部分问题
应用版本 elasticsearch 5.5 spark 2.2.0 hadoop 2.7 依赖包版本 docker cp /Users/cclient/.ivy2/cache/org.elastic ...
- Spark SQL读写方法
一.DataFrame:有列名的RDD 首先,我们知道SparkSQL的目的是用sql语句去操作RDD,和Hive类似.SparkSQL的核心结构是DataFrame,如果我们知道RDD里面的字段,也 ...
- Spark如何读写hive
原文引自:http://blog.csdn.net/zongzhiyuan/article/details/78076842 hive数据表建立可以在hive上建立,或者使用hiveContext.s ...
- spark mysql读写
val data2Mysql2 = (iterator: Iterator[(String, Int)]) => { var conn: Connection = null; var ps: P ...
- spark 集成elasticsearch
pyspark读写elasticsearch依赖elasticsearch-hadoop包,需要首先在这里下载,版本号可以通过自行修改url解决. """ write d ...
随机推荐
- Nuxt框架中内置组件详解及使用指南(四)
title: Nuxt框架中内置组件详解及使用指南(四) date: 2024/7/9 updated: 2024/7/9 author: cmdragon excerpt: 摘要:本文详细介绍了Nu ...
- R语言将多景遥感影像拼接在一起的方法
本文介绍基于R语言中的raster包,遍历文件夹,读取文件夹下的大量栅格遥感影像,并逐一对每一景栅格图像加以拼接.融合,使得全部栅格遥感影像拼接为完整的一景图像的方法. 其中,本文是用R语言来 ...
- Redis巡检检查 redis-check-aof
一.AOF1.AOF 是什么以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,R ...
- Python 基于Python生成短8位唯一id解决方案
基于Python生成短8位唯一id解决方案 by:授客 QQ:1033553122 测试环境: Win10 Python 3.5.4 实现思路 利用62个可打印字符,通过随机生成32位UUID,由 ...
- Python shortuuid生成库学习小结
shortuuid生成库学习小结 by:授客 QQ:1033553122 实践环境 win10 Python 3.5.4 shortuuid-1.0.1-py3-none-any.whl 下载地址: ...
- 计算机网络中的检验和(checksum)(包括计算文件的检验和附有c++代码)
介绍: 检验和(checksum),在数据处理和数据通信领域中,用于校验目的地一组数据项的和.它通常是以十六进制为数制表示的形式.如果校验和的数值超过十六进制的FF,也就是255. 就要求其补码作为校 ...
- Linux 中 Crontab 执行时的环境变量问题(allure命令不执行)
前几天做了UI自动化脚本部署linux服务器,但是放下脚本的allure命令不执行(生成allure报告和启动allure服务的命令不执行),然后就各种找问题,一开始怀疑是allure的环境变量问题, ...
- 【Java】【常用类】Calendar 日历类
Calendar 日历类,我居然念错发音,来,好好看下音标 ['kælɪndə] 卡琳达 public class DateTest { public static void main(Strin ...
- 基于 ChatGPT 的聊天软件合集打包分享
「基于 ChatGPT 的聊天软件合集打包」 链接:https://pan.quark.cn/s/ef1f5e9c48e4 BotGem(原名AMA) 官网:https://botgem.com/ ...
- 【转载】 Tensorflow学习笔记-模型保存与加载
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/lovelyaiq/article/det ...