python sweetviz_数据分析及解决报告图表中文乱码
python sweetviz_数据分析
python 做数据分析,传入数据进去,就可以使用python现有的插件,进行数据分析,生成数据分析的报表,可以将复杂的数据,通过图表的形式,清晰将数据展示出来
其实,就是将负责的数据,通过图表的形式,统计各个数据的情况
python 做数据分析的探索
第一种:探索数据分析由几个部分组成,再通过画图表的方法,进行数据分析
参考:http://www.py.cn/jishu/jichu/13184.html
第二种:现有已提供Sweetviz,只需要几行代码,即可进行数据分析,综合考虑,先使用这种进行数据分析
参考:https://www.jb51.net/article/226963.htm
使用Sweetviz数据分析的实际操作
首先将Sweetviz安装,自动安装
Pip install sweetviz 或直接通过pycharm工具进行搜索下载
安装好之后,操作文章里面,进行数据分析,希望得到的效果,生成数据分析的html报告
Sweetviz基本用法
- 数据准备:使用pandas读取数据之前,要将数据存放到csv格式的文件里面
- 数据读取:pandas进行读取数据,这里需要根据csv文件,配置文件的编码格式,否则报告中包含中文的也是乱码
- 使用sweetviz.analyze(),将读取回来的dataframe的数据,进行分析
- 分析完成后,分析结果以html的格式进行展示
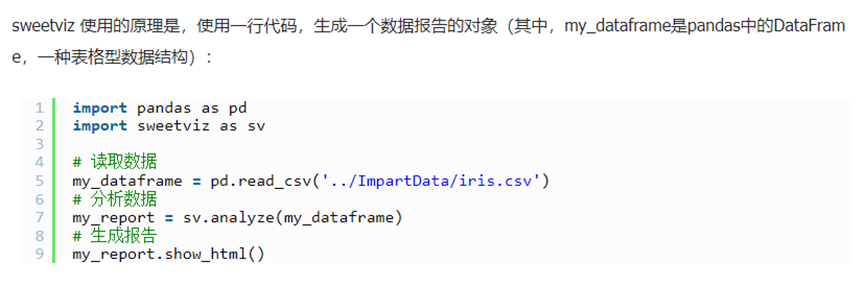
实操代码
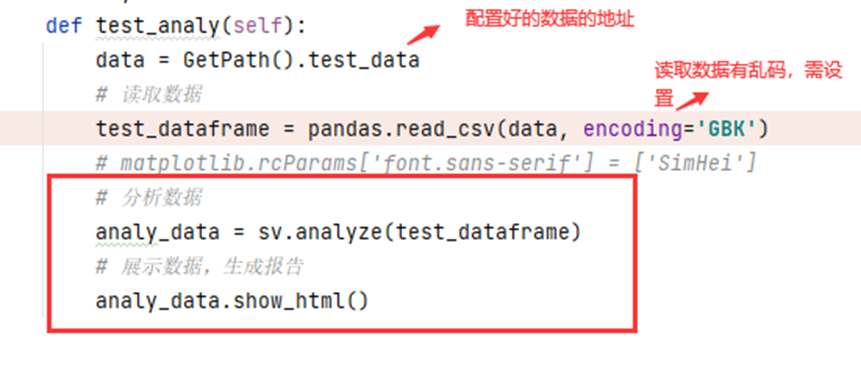
def test_analy(self):
data = GetPath().test_data # 读取数据
test_dataframe = pandas.read_csv(data, encoding='GBK') # 分析数据
analy_data = sv.analyze(test_dataframe) # 展示数据,生成报告
analy_data.show_html()
解决图表中的中文乱码
来到第4步都很顺利执行完成,打开报告查看的时候,发现报告里面的图表有中文的,展示成框框
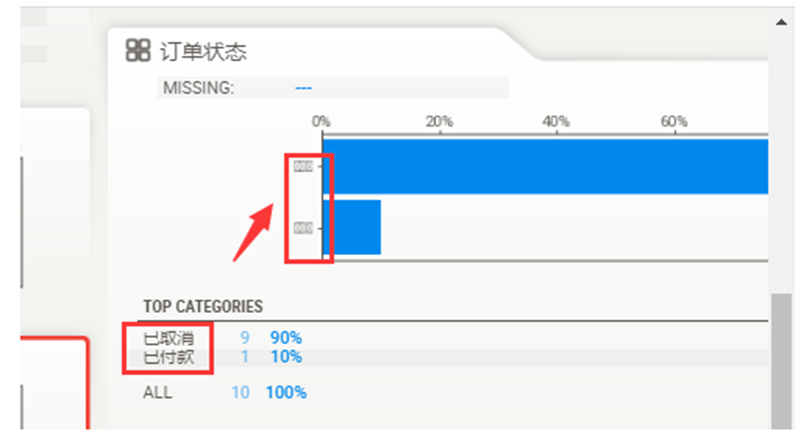
分析报错
Glyph绘制图表时,可在控制台看到报错,UserWarning: Glyph xxxxx missing from current font,字面意思就是确实了常用的字符

实际报错中的36890,对应的是unicode中的中文字符,当前的配置中,找不到对应的字体文件对应,所以这个中文缺失,前端展示成框框


参考:https://blog.csdn.net/weixin_43257735/article/details/120170615
下载字体
只是当前的字体没有对应中文的字体文件,不是解析中文,就去下载可以显示中文的字体,进行配置
下载黑体的字体,包含中文,
字体地址:http://www.font5.com.cn/font_download.php?id=151&part=1237887120
下载成功后,将SimHei.ttf,放到对应的文件夹目录下
有点提个醒,使用的是sweetviz进行数据分析,而不是直接使用matplotlib
中的graph进行画图,将下载的字体,放置到matplotlib的font/下,是起不了作用的
直接从报错的信息中,发现sweetviz里面也有graph文件来生成图表,要到这个路径下,将字体放置到font里面,
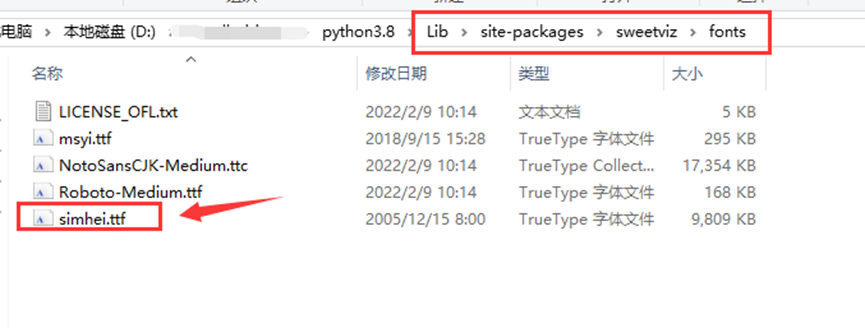
配置使用字体
再到配置文件graph_base.mplstyle,设置graph使用的字体
…\python3.8\Lib\site-packages\sweetviz\mpl_styles\graph_base.mplstyle
找到配置文件里面的font的配置,将配置改成使用黑体

查看效果
这个时候,重新运行程序,进行数据分析,控制台没有输出缺失字体,报告收集成功,生成到当前文件下

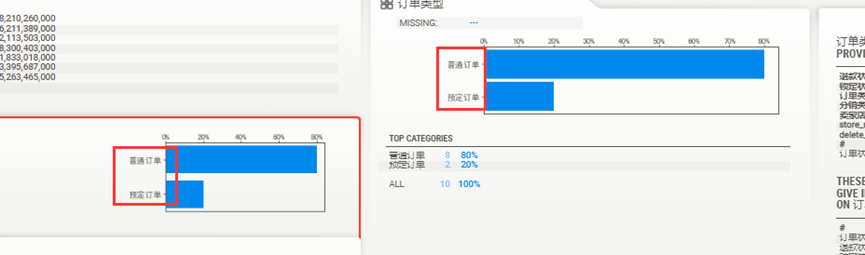
报告中生成的图表的中文,正常显示,问题解决

Sweetviz三种常用的方法
其中,分析数据有三种函数可以用,除了上面提到的analyze函数,还有 compare 和 compare_intra 函数。
首先是analyze函数:
analyze(source: Union[pd.DataFrame, Tuple[pd.DataFrame, str]],
target_feat: str = None,
feat_cfg: FeatureConfig = None,
pairwise_analysis: str = 'auto')
source: 以pandas中的DataFrame数据结构作为分析对象。可见其有以下4个参数可以配置:
target_feat: 需要被标记为目标对象的字符串。
feat_cfg: 需要被跳过、或是需要被强制转换为某种数据类型的特征。
pairwise_analysis: 相关性分析可能需要花费较长时间。如果超过了你的忍受范围,就需要设置这个参数为on或者off,以判断是否需要分析数据相关性。
compare()丨两个数据集比较
my_report = sv.compare([my_dataframe, "Training Data"], [test_df, "Test Data"], "Survived”)
要比较两个数据集,只需使用该 compare() 函数。它的参数与 analyze() 相同,只是插入了第二个参数来覆盖比较数据帧。建议使用 [dataframe, “name”] 参数格式以更好地区分基础数据帧和比较数据帧。(例如 [my_df, "Train"] 比 my_df 更好)
Sweetviz比较数据
用于比较两个数据集,比如一样的数据,不同的用户或不同的平台,进行数据比较,可以得出数据分析的结果
使用到的compare()方法
Compare基本用法
1、 数据准备:两组比较的数据的文件,csv格式
2、 其他参数配置,按需进行配置
3、 使用compare(),进行比较
4、 最后将分析的结果,通过html展示
参数配置:
1、 source: 以pandas中的DataFrame数据结构作为分析对象。
2、 target_feat: 需要被标记为目标对象的字符串。
3、 feat_cfg: 需要被跳过、或是需要被强制转换为某种数据类型的特征。
4、 pairwise_analysis: 相关性分析可能需要花费较长时间。如果超过了你的忍受范围,就需要设置这个参数为on或者off,以判断是否需要分析数据相关性。
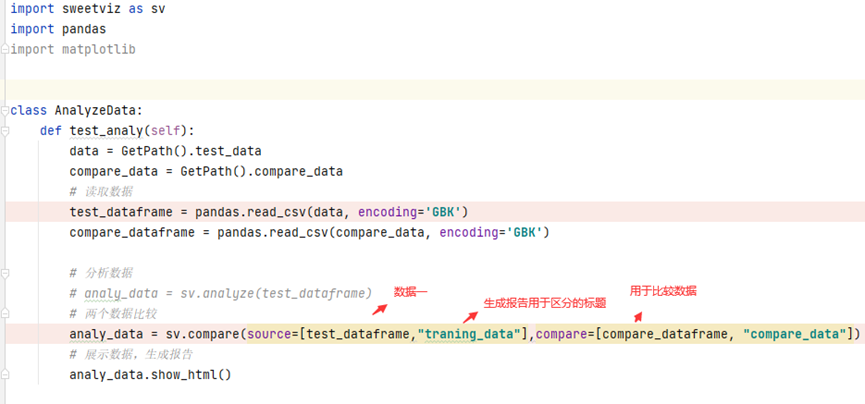
def test_analy(self):
data = GetPath().test_data
compare_data = GetPath().compare_data
# 读取数据
test_dataframe = pandas.read_csv(data, encoding='GBK')
compare_dataframe = pandas.read_csv(compare_data, encoding='GBK') # 两个数据比较
analy_data = sv.compare(source=[test_dataframe,"traning_data"],compare=[compare_dataframe, "compare_data"])
# 展示数据,生成报告
analy_data.show_html()
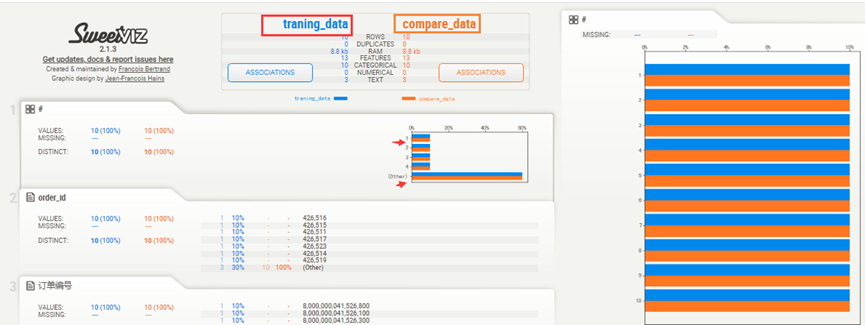
比较完成后的报告
看生成的报告中的分别用不同的颜色,标注两组不同的数据
python sweetviz_数据分析及解决报告图表中文乱码的更多相关文章
- JMeter学习-039-JMeter 3.0 生成 dashboard HTML 报告图表中文乱码
近期,经常有人问 JMeter 3.0 使用时,生成的 HTML 报告图表中的中文乱码问题.在此,简略的说一下解决的方法. 编码相关信息如下: 1.查看控制 csv.xml 等配置结果文件生成.读取的 ...
- 教你解决Sublime Text中文乱码问题
教你解决Sublime Text中文乱码问题[转载自成长的企鹅] Sublime Text 2是一个非常不错的源代码及文本编辑器,但是不支持GB2312和GBK编码在很多情况下会非常麻烦. ...
- 分享一个解决MySQL写入中文乱码的方法
分享一个解决MySQL写入中文乱码的方法 之前有发帖请教过如何解决MySQL写入中文乱码的问题.但没人会,或者是会的人不想回答.搜索网上的答案并尝试很多次无效,所以当时就因为这个乱码问题搁浅了一个软件 ...
- 完美解决Informix的中文乱码问题
完美解决Informix的中文乱码问题 Informix是IBM旗下的一款数据库,要不是这个项目需要,估计这辈子我都不知道居然还有这么一款数据库.想来公司的项目遍布全国各地,各种部署环境各种应用场景 ...
- 使用过滤器(Filter)解决请求参数中文乱码问题(复杂方式)
前述: 在写这篇笔记之前,对笔记中的设计模式进行介绍: 本篇笔记中将要使用到的设计模式是:装饰(包装)设计模式 (1)装饰(包装)设计模式口诀: ...
- 解决Ubuntu系统中文乱码显示问题,终端打开文件及查看目录
解决Ubuntu系统中文乱码显示问题 [日期:2014-02-20] 来源:Linux社区 作者:njchenyi [字体:大 中 小] 我是先安装了Ubuntu 12.04 Server,然后 ...
- gedit 没有preference项,使preference回归,并用命令行设置行号,解决centos7下中文乱码,text wrapping等问题
1. 最简单的,使preference选项回来: gsettings set org.gnome.settings-daemon.plugins.xsettings overrides '@a{sv} ...
- 尚硅谷面试第一季-09SpringMVC中如何解决POST请求中文乱码问题GET的又如何处理呢
目录结构: 关键代码: web.xml <filter> <filter-name>CharacterEncodingFilter</filter-name> &l ...
- 解决phantomjs输出中文乱码
解决phantomjs输出中文乱码,可以在js文件里添加如下语句: phantom.outputEncoding="gb2312"; // 解决输出乱码
- zabbix解决监控图形中文乱码
原文: https://blog.csdn.net/xujiamin0022016/article/details/86541783 zabbix 4解决监控图形中文乱码首先在windows里找到你想 ...
随机推荐
- Python:Short Circuiting -- “OR”
Short Circuiting Operator Checks if: Evaluates from left to right up to: Example AND All values are ...
- 前端之JavaScript基础学习
一.JS代码引入以及基本代码规范 # 1.js代码书写格式 <script> ....js的代码 </script> #2.script标签写在页面那个位置 1)页面的head ...
- JavaScript中对数组.map()、some()、every()、filter()、forEach的区别
1.区别说明 共同点: 不会对原数组发生修改,而是返回新的变量,用变量接收. 不同点: 1.some():返回一个Boolean类型变量,判断是否有元素符合func条件 2.every():返回一个B ...
- jquery中.html(),.text()和.val()的差异总结
.html(),.text(),.val()三种方法都是用来读取选定元素的内容: .html()是用来读取元素的html内容(包括html标签): .text()用来读取元素的纯文本内容,包括其后代元 ...
- C 语言编程 — 高级数据类型 — 字符串
目录 文章目录 目录 前文列表 字符串 前文列表 <程序编译流程与 GCC 编译器> <C 语言编程 - 基本语法> <C 语言编程 - 基本数据类型> <C ...
- 前后端分离项目集成PageOffice——实现在线编辑Word文件的版本控制
PageOffice本身提供了SaveFilePage的js方法,但是由于该方法不支持代理且不能跨域导致在前后端分离项目中无法使用 功能:实现三个按钮分别保存不同版本的文件 1.PageOffice可 ...
- kubernetes 之 Rolling Update 滚动升级
滚动升级 1.错误的yml文件 [machangwei@mcwk8s-master ~]$ cat mcwHttpd.yml apiVersion: apps/v1 kind: Deployment ...
- webapi创建WCF WebService+WCF WebService远程服务调用
首先需要引入soapcore包 这个包提供了所需的类和soap终结点中间件. 引入这个这个包之后,我们需要定义提供的服务. 这里我写了一个用于查询省份面积的服务. 省份信息服务 /// <sum ...
- JSON数据压缩传输(一)- 无标记数组
服务端 //需要传回前端的字段string[] fields = dto.fields.Split(','); var resluts=new List<dynamic>(); //只取前 ...
- JSON转化工具的使用
概述 JSON是一种轻量化的数据传输格式,在各种场景都有运用.比如在ajax中,服务端的数据一般通过JSON字符串的格式传输给前端,前端ajax引擎自动将JSON字符串转化为JS对象(需要将ajax的 ...