Protobuf 的基本使用
Protobuf 是 Google 用于序列化数据对象的一种机制,使得数据对象能够在应用程序和服务器之间进行交互,尽管现在 Java 已经对应的序列化的实现方式,但是传统的序列化方式存在严重的缺陷,因此现在应该避免使用 Java 自带的序列化方式。
传统序列化方式的局限性
按照传统的实现,如果要使得一个对象能够被序列化成为一个二进制数据流,只需要使得定义的类实现 Serializable 接口即可,由于这个接口是一个空接口,因此大多数人认为实现序列化很简单,导致了 Serializable 接口的滥用
《Effective Java》(第三版)中总结了 Serializable 存在的不足[2]:
- 类如果实现
Serializable接口会大幅度降低类的灵活性 - 实现
Serializable接口会提高 bug 和漏洞出现的概率 - 随着类的发行版本的更新,相关测试的负担也会加重
在书中,作者建议如果必须实现传输二进制数据对象的话,建议使用 JSON 的序列化方式或者是 Protocol Buffer(ProtoBuf)的方式来实现
使用 JSON 的序列化方式比较简单,因为序列化之后的数据对于人类来讲是可见的,Jackson 和 Gson 都能够很好地帮助我们完成这一工作,在此不做过多的介绍
protoc 的安装
ProtoBuf 通过对应的 .proto 文件来生成需要的具体类信息,通过选择对应的参数选项即可生成不同的编程语言的版本,这个转换的过程是通过 protoc 来实现的。你可以认为这个工具是 .proto 源文件的一个编译器,与传统的编译器不同的地方在于别的编译器是将源文件转换为二进制文件,而 protoc 则是将 .proto 文件文件转换成为对应编程语言的源文件
如果是在 Ubuntu 操作系统上,可以通过如下的命令直接安装 protoc :
sudo apt-get install protobuf-compiler
如果是别的操作系统,如 Windows,可以直接到官方的 GitHub 的发行版本中直接下载对应的二进制版本,具体地址:https://github.com/protocolbuffers/protobuf/releases/tag/v3.19.1, 然后将 protoc 程序所在的目录添加到 PATH 环境变量即可
编写 proto 文件
以一个简单的 addressBook.proto 文件文件为例,介绍一下有关 .proto 的语法:
// 使用的 proto 语法的版本
syntax="proto2";
// 如果没有指定 java_package,那么将这个包位置作为生成类的目的包
package org.xhliu.proto.entity;
// 确保能够为每个类生成独立的 .java 文件而不是单个的 .java 文件
option java_multiple_files = true;
// 生成的目标类所在的包
option java_package = "org.xhliu.proto.entity";
// 定义生成的类的名字
option java_outer_classname = "AddressBookProtos";
// 简单的理解: message 和 class 关键字是对应的
message Person {
/*
对于属性的修饰:
optional 表示这个字段可能被设置属性,也可能不会设置属性
repeated 表示这个字段可能被设置多次,和数组是相对应的
required 表示这个字段必须被设置值,否则将会抛出 RuntimeException
*/
optional string name = 1;
optional int32 id = 2;
optional string email = 3;
// 相当于在类中定义了一个枚举类
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
// 相当于定义了一个内部类
message PhoneNumber {
optional string number = 1;
// type 属性默认为 HOME
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phones = 4;
}
// 再定义了一个类,其中包含 Person 类型的属性
message AddressBook {
repeated Person people = 1;
}
具体关于 proto 语言的内容可以参考:https://developers.google.com/protocol-buffers/docs/proto
具体类型和实际变成语言中的类型对应如下[1]:
| .proto Type | Notes | C++ Type | Java Type | Python Type[2] | Go Type |
|---|---|---|---|---|---|
| double | double | double | float | *float64 | |
| float | float | float | float | *float32 | |
| int32 | Uses variable-length encoding. Inefficient for encoding negative numbers – if your field is likely to have negative values, use sint32 instead. |
int32 | int | int | *int32 |
| int64 | Uses variable-length encoding. Inefficient for encoding negative numbers – if your field is likely to have negative values, use sint64 instead. |
int64 | long | int/long[3] | *int64 |
| uint32 | Uses variable-length encoding. | uint32 | int[1] | int/long[3] | *uint32 |
| uint64 | Uses variable-length encoding. | uint64 | long[1] | int/long[3] | *uint64 |
| sint32 | Uses variable-length encoding. Signed int value. These more efficiently encode negative numbers than regular int32s. |
int32 | int | int | *int32 |
| sint64 | Uses variable-length encoding. Signed int value. These more efficiently encode negative numbers than regular int64s. |
int64 | long | int/long[3] | *int64 |
| fixed32 | Always four bytes. More efficient than uint32 if values are often greater than 228. | uint32 | int[1] | int/long[3] | *uint32 |
| fixed64 | Always eight bytes. More efficient than uint64 if values are often greater than 256. | uint64 | long[1] | int/long[3] | *uint64 |
| sfixed32 | Always four bytes. | int32 | int | int | *int32 |
| sfixed64 | Always eight bytes. | int64 | long | int/long[3] | *int64 |
| bool | bool | boolean | bool | *bool | |
| string | A string must always contain UTF-8 encoded or 7-bit ASCII text. | string | String | unicode (Python 2) or str (Python 3) | *string |
| bytes | May contain any arbitrary sequence of bytes. | string | ByteString | bytes | []byte |
生成具体类
由于对应的项目为 Java 类型的项目,因此需要生成 Java 类型的类,使用示例如下所示:
# -I 表示 .proto 文件所在的路径,--java_out 表示输出 Java 的类,并且指定对应的输出路径
protoc -I=. --java_out=. addressBook.proto
得到的结果如下图所示:
可以看到,已经自动生成了能够使用 ProtoBuf 的类
序列化对象
生成了对应的 ProtoBuf 的类之后,就可以使用这些类来结合 ProtoBuf 来序列化对象了,在那之前,需要添加如下依赖:
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>${protobuf.version}</version><!-- 这里需要在 Maven 仓库找到对应的版本-->
</dependency>
明确一点,上文中的 .proto 文件只是帮助我们生成了能够使用 ProtoBuf 工具的类文件,实际上和序列化对象没有任何关系,具体的序列化操作是通过这个 protobuf-java 这个依赖项来实现的,请明确这一点
现在,直接使用 .proto 生成的类去调用 ProtoBuf 来实现对象的序列化和反序列化:
序列化
public static void main(String[] args) throws Exception {
// 首先,通过构建者模式的方式来构造 Person 对象
Person person = Person.newBuilder()
.setId(1)
.setEmail("123456789@gmail.com")
.setName("xhliu")
.addPhones(Person.PhoneNumber.newBuilder().setNumber("123456789").build())
.build(); // 再通过 AddressBook 的构建者方法来构建 AddressBook 对象
AddressBook addressBook = AddressBook.newBuilder().addPeople(person).build();
try (
FileOutputStream out = new FileOutputStream("/tmp/addressBook.obj");
){
addressBook.writeTo(out);
System.out.println("序列化 AddressBook 对象成功");
}
}
运行这段代码,可以在
/tmp/目录下发现一个名为addressBook.obj的二进制文件,这个对象就是通过 ProtoBuf 序列化之后二进制数据,此时使用hexdump命令再加上-C选项,可以大致查看一下文件的内容,具体如下图所示:
反序列化
public static void main(String[] args) throws Exception {
try (
FileInputStream in = new FileInputStream("/tmp/addressBook.obj")
){
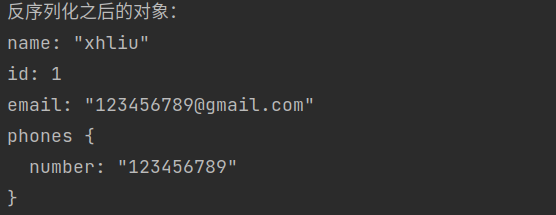
AddressBook obj = AddressBook.parseFrom(in);
System.out.println("反序列化之后的对象:");
System.out.println(obj.getPeople(0));
}
}
运行之后的结果如下图所示:
除了学习了 ProtoBuf 之外,我认为在这个过程中更加值得学习的是 Google 对于 ProtoBuf 的使用,通过 .proto 文件来结合使用对应的依赖库,大大减少了人工编写代码的成本,通过特定的小众语言来达到这一目标,这是十分值得学习的(《编程珠矶(续)》中讨论了对于小众语言的使用)
参考:
[1] https://developers.google.com/protocol-buffers/docs/proto#simple
[2] 《Effective Java》(第三版)
Protobuf 的基本使用的更多相关文章
- python通过protobuf实现rpc
由于项目组现在用的rpc是基于google protobuf rpc协议实现的,所以花了点时间了解下protobuf rpc.rpc对于做分布式系统的人来说肯定不陌生,对于rpc不了解的童鞋可以自行g ...
- Protobuf使用规范分享
一.Protobuf 的优点 Protobuf 有如 XML,不过它更小.更快.也更简单.它以高效的二进制方式存储,比 XML 小 3 到 10 倍,快 20 到 100 倍.你可以定义自己的数据结构 ...
- java netty socket库和自定义C#socket库利用protobuf进行通信完整实例
之前的文章讲述了socket通信的一些基本知识,已经本人自定义的C#版本的socket.和java netty 库的二次封装,但是没有真正的发表测试用例. 本文只是为了讲解利用protobuf 进行C ...
- 在Wcf中应用ProtoBuf替代默认的序列化器
Google的ProtoBuf序列化器性能的牛逼已经有目共睹了,可以把它应用到Socket通讯,队列,Wcf中,身为dotnet程序员一边期待着不久后Grpc对dotnet core的支持更期待着Wc ...
- protobuf的编译安装
github地址:https://github.com/google/protobuf支持多种语言,有多个语言的版本,本文采用的是在centos7下编译源码进行安装. github上有详细的安装说明: ...
- 编译protobuf的jar文件
1.准备工作 需要到github上下载相应的文件,地址https://github.com/google/protobuf/releases protobuf有很多不同语言的版本,因为我们需要的是ja ...
- protobuf学习(2)-相关学习资料
protobuf官方git地址 protobuf官方英文文档 (你懂的需要FQ) protobuf中文翻译文档 protobuf概述 (官方翻译 推荐阅读) protobuf入门 ...
- google protobuf安装与使用
google protobuf是一个灵活的.高效的用于序列化数据的协议.相比较XML和JSON格式,protobuf更小.更快.更便捷.google protobuf是跨语言的,并且自带了一个编译器( ...
- c# (ENUM)枚举组合类型的谷歌序列化Protobuf
c# (ENUM)枚举组合类型的谷歌序列化Protobuf,必须在序列化/反序列化时加上下面: RuntimeTypeModel.Default[typeof(Alarm)].EnumPassthru ...
- dubbox 增加google-gprc/protobuf支持
好久没写东西了,今年实在太忙,基本都在搞业务开发,晚上来补一篇,作为今年的收官博客.google-rpc 正式发布以来,受到了不少人的关注,这么知名的rpc框架,不集成到dubbox中有点说不过去. ...
随机推荐
- SQL连接符Left Join小实例
在一数据移植项目中,Left Join的应用 项目要求根据卡号获取最终用户号,规则如下: 1.根据card查询tbl_TestA表,获取userid,根据userid作为id查询tbl_TestB获 ...
- Matlab 设计仿真CIC滤波器
2023.09.26 使用CIC滤波器用于降采样.同样的,CIC滤波器也适用于升采样. 参考连接: [1] Matlab中CIC滤波器的应用_dsp.cicdecimator_张海军2013的博客-C ...
- Oracle:字符串的拼接、截取、查找、替换
一.拼接:1.使用"||"来拼接字符串: select '拼接'||'字符串' as Str from dual; 2.使用concat(param1,param2)函数实现: s ...
- linux日常运维(三) GRUB 2的维护
GRUB 2简介 GRUB GRUB是linux系统默认的引导加载程序.linux加载一个系统前,它必须有一个引导加载程序中特定指令(比如MBR记录)去引导系统.这个程序一般是位于系统的主硬盘驱动器或 ...
- 11. 用Rust手把手编写一个wmproxy(代理,内网穿透等), 实现健康检查
11. 用Rust手把手编写一个wmproxy(代理,内网穿透等), 实现健康检查 项目 ++wmproxy++ gite: https://gitee.com/tickbh/wmproxy gith ...
- 谈谈selenium4.0中的相对定位
相对定位历史 2021-10-13 发布的 selenium 4.0 开始引入,selenium 3.X是没有的 implement relative locator for find_element ...
- Redis 6 学习笔记 3 —— 用SpringBoot整合Redis的踩坑,了解事务、乐观锁、悲观锁
SpringBoot整合Redis时踩到的坑 jdk1.8环境,用idea的Spring Initializr创建spring boot项目,版本我选的2.7.6.pom文件添加的依赖如下,仅供参考. ...
- Ubuntu22.04 rc-local 配置开机自启动脚本
1. rc-local服务简介Linux中的rc-local服务是一个开机自动启动的,调用开发人员或系统管理员编写的可执行脚本或命令的,它的启动顺序是在系统所有服务加载完成之后执行. ubuntu22 ...
- 从HumanEval到CoderEval: 你的代码生成模型真的work吗?
本文分享自华为云社区<从HumanEval到CoderEval: 你的代码生成模型真的work吗?>,作者:华为云软件分析Lab . 本文主要介绍了一个名为CoderEval的代码生成大模 ...
- Python利用pandas进行数据合并
当使用Python中的pandas库时,merge函数是用于合并(或连接)两个数据框(DataFrame)的重要工具.它类似于SQL中的JOIN操作,允许你根据一个或多个键(key)将两个数据框连接起 ...