算法金 | 一个强大的算法模型,GP !!

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
高斯过程算法是一种强大的非参数机器学习方法,广泛应用于回归、分类和优化等任务中。其核心思想是利用高斯分布来描述数据的分布,通过核函数来度量数据之间的相似性。与传统的机器学习方法相比,高斯过程在处理小样本数据和不确定性估计方面具有独特的优势。
接下来,我们将详细探讨高斯过程的基本原理、数学表述及其在机器学习中的应用,并提供相关的代码示范和实际案例分析。

1. 高斯过程的基本原理
1.1 高斯过程定义
高斯过程是一种用于定义数据分布的概率模型。其核心在于任意数量的随机变量的集合中,每个子集的联合分布都是多元正态分布。通俗来讲,高斯过程是一种“函数的分布”,用来描述函数值在给定输入下的可能取值。
1.2 高斯过程的核心思想
高斯过程通过核函数来度量数据点之间的相似性。核函数不仅决定了数据点之间的相互关系,还影响了整个高斯过程模型的平滑性和复杂性。常用的核函数包括线性核、径向基核(RBF核)和多项式核。
1.3 高斯过程与正态分布的关系
高斯过程是由多元正态分布推广而来的。在高斯过程中,每个数据点都可以看作是一个多元正态分布的一部分,其均值和协方差由核函数决定。因此,高斯过程具有与正态分布相同的优良性质,如平稳性和解析性。
更多分布见微*公号往期文章:数据科学家 95% 时间都在使用的 10 大基本分布
95% 数据科学家都在使用,确定数据分布正态性 10 大方法,附 Python 代码
1.4 高斯过程的优点
高斯过程在处理小样本数据和不确定性估计方面具有独特的优势:
- 不确定性估计:高斯过程能够自然地给出预测的不确定性。
- 非参数特性:不需要预设数据的分布形式,灵活应对各种数据特征。
- 处理小样本数据:在样本较少的情况下,高斯过程仍能提供准确的预测。
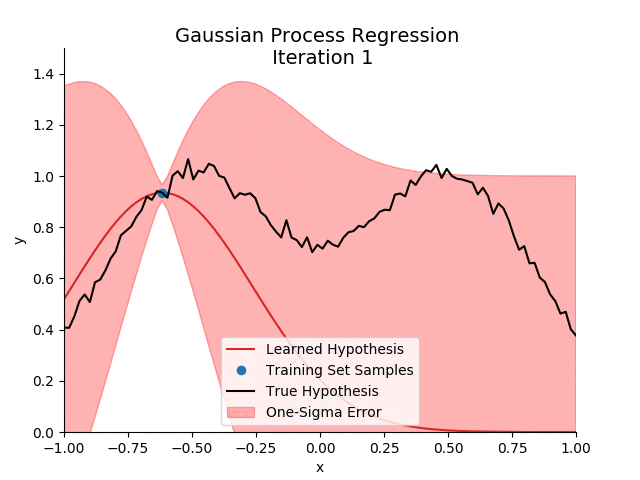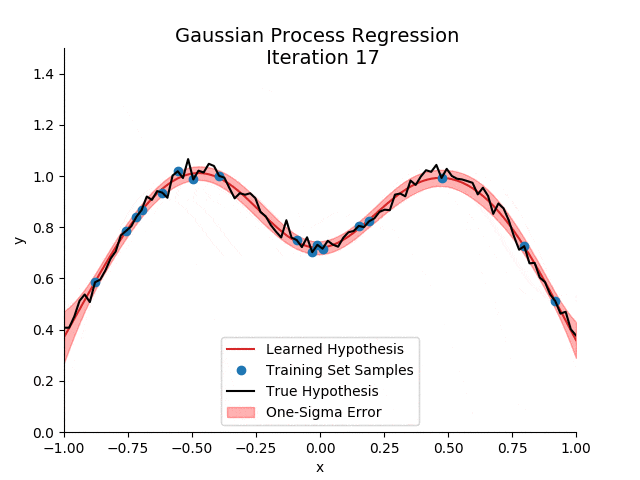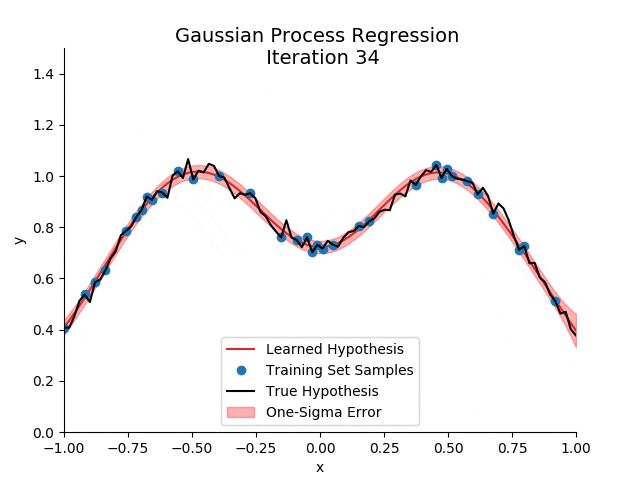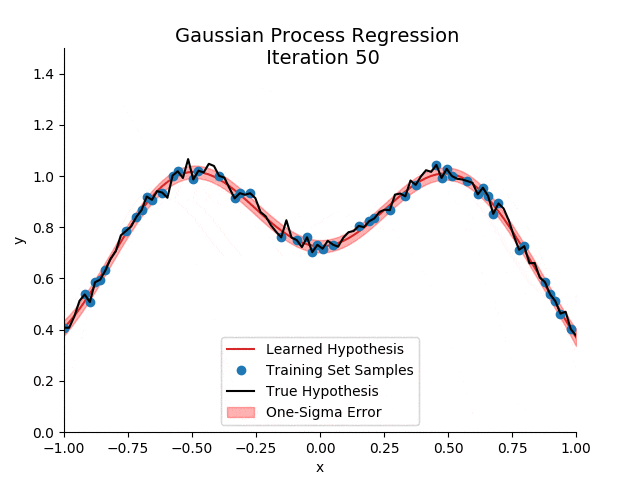
2. 高斯过程的数学表述
不想脑瓜疼的铁子,可以考虑跳过这一部分
2.1 核函数的定义与作用
在高斯过程模型中,核函数(或称为协方差函数)是关键组成部分。它用于度量数据点之间的相似性。常见的核函数包括:
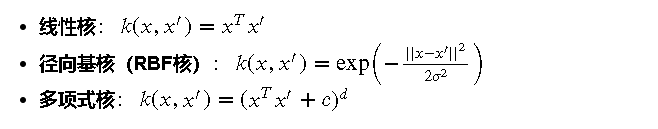
核函数的选择对高斯过程的性能有显著影响,不同的核函数能够捕捉数据的不同特性。
2.2 协方差函数
协方差函数 (,′)描述了两个输入点 和 ′ 之间的相关性。给定输入数据 ={1,2,…,},我们可以构建协方差矩阵 ,其元素为 =(,)。这个协方差矩阵用于确定高斯过程的平滑性和复杂性。
2.3 高斯过程的先验和后验分布
在高斯过程中,先验分布和后验分布是两个重要概念:
- 先验分布:在没有观察数据的情况下,假设函数的分布。通常,先验分布假设为零均值和核函数定义的协方差矩阵。
- 后验分布:在观察到数据后,更新函数的分布。

3. 高斯过程的优缺点
3.1 优点
高斯过程在机器学习中具有以下优点:
- 不确定性估计:高斯过程能够自然地给出预测的不确定性,对于风险评估和决策具有重要意义。
- 非参数特性:不需要预设数据的分布形式,灵活应对各种数据特征。
- 小样本数据处理:在样本较少的情况下,高斯过程仍能提供准确的预测。
- 高斯过程的平滑性:通过选择合适的核函数,高斯过程能够很好地捕捉数据的平滑性和复杂性。
3.2 缺点
尽管高斯过程有许多优点,但也存在一些缺点:
- 计算复杂度高:高斯过程的计算复杂度为 (3)(3),在大规模数据集上计算成本高。
- 内存需求大:由于需要存储协方差矩阵,高斯过程对内存需求较大。
- 超参数选择困难:高斯过程模型的性能依赖于核函数和超参数的选择,选择不当会影响模型效果。
- 对核函数的依赖:核函数的选择对高斯过程的性能影响重大,不同的核函数可能导致截然不同的结果。
3.3 高斯过程与其他机器学习方法的比较
与其他常见的机器学习方法相比,高斯过程具有以下特点:
- 与线性回归的比较:高斯过程可以看作是线性回归的非参数扩展,能够处理非线性关系,而线性回归只能捕捉线性关系。
- 与支持向量机(SVM)的比较:高斯过程和 SVM 都依赖于核函数,但高斯过程能够提供不确定性估计,而 SVM 不具备此特性。
- 与神经网络的比较:神经网络在处理大规模数据和复杂模型方面具有优势,但高斯过程在小样本和不确定性估计方面更为出色。
- 与决策树和随机森林的比较:决策树和随机森林适用于大规模数据和高维数据,而高斯过程更适合处理小样本数据和提供不确定性估计。
更多分布见微*公号往期文章:十大回归算法 ,支持向量机 SVM , 决策树算法,随机森林, 神经网络

添加图片注释,不超过 140 字(可选)
4. 高斯过程的扩展与变体
4.1 稀疏高斯过程
高斯过程模型的一个主要缺点是其计算复杂度随着数据量的增加而迅速增长。稀疏高斯过程(Sparse Gaussian Processes, SGP)通过引入一组少量的诱导点来近似完整数据集,从而显著降低计算复杂度。稀疏高斯过程的方法包括:
- 确定性诱导点方法(DTC):选择固定数量的诱导点,构建近似模型。
- 鞅变分近似(VFE):通过变分推断优化诱导点的位置和数量,提供更好的近似。
稀疏高斯过程能够在保证模型性能的同时,大幅降低计算和存储需求,非常适合大规模数据集的应用。
4.2 非平稳高斯过程
标准高斯过程假设数据的协方差结构是平稳的,即核函数参数在整个数据空间内是固定的。然而,许多实际问题中,数据的协方差结构可能随空间或时间变化。非平稳高斯过程(Non-stationary Gaussian Processes, NSGP)通过引入位置或时间依赖的核函数参数来建模这种变化。
常见的非平稳高斯过程模型包括:
- 位置依赖核函数:核函数参数如长度尺度和方差随位置变化。
- 时间依赖核函数:核函数参数随时间变化,用于建模时间序列中的非平稳性。
非平稳高斯过程能够更灵活地适应实际数据的复杂特性,提高模型的预测准确性。
4.3 多任务高斯过程
多任务高斯过程(Multi-task Gaussian Processes, MTGP)扩展了标准高斯过程,能够同时处理多个相关任务。其核心思想是通过共享协方差结构来捕捉不同任务之间的相关性。
多任务高斯过程的典型应用包括:
- 多变量时间序列预测:同时预测多个相关时间序列。
- 多任务回归:建模多个相关输出变量的回归问题。
多任务高斯过程不仅能够提高单个任务的预测性能,还能有效利用不同任务之间的相互信息,提高整体模型的鲁棒性和准确性。
代码示例及可视化
我们生成一个包含 30 天数据的小规模数据集,其中包括武林高手的功力、武器熟练度以及战斗胜率。接下来,我们使用高斯过程回归模型对战斗胜率进行建模和预测。
数据集生成
数据生成代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel as C
# 生成数据集
np.random.seed(42)
days = np.arange(1, 31)
power = 50 + 0.5 * days + np.random.normal(0, 5, len(days))
weapon_skill = 50 + 0.3 * days + np.random.normal(0, 5, len(days))
battle_win_rate = 0.3 * power + 0.7 * weapon_skill + np.random.normal(0, 5, len(days))
data = pd.DataFrame({
'天数': days,
'功力': power,
'武器熟练度': weapon_skill,
'战斗胜率': battle_win_rate
})
# 提取特征和目标变量
X = data[['天数']].values
y = data['战斗胜率'].values
模型训练和预测
定义高斯过程回归模型并进行训练和预测:
# 定义高斯过程回归模型
kernel = C(1.0, (1e-3, 1e3)) * RBF(1.0, (1e-2, 1e2))
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)
# 训练模型
gp.fit(X, y)
# 生成一组测试数据
X_test = np.linspace(1, 30, 100).reshape(-1, 1)
# 预测战斗胜率
y_pred, sigma = gp.predict(X_test, return_std=True)
结果可视化
绘制拟合曲线和不确定性范围:
# 绘制拟合曲线和不确定性
plt.figure(figsize=(10, 6))
plt.scatter(X, y, c='b', label='实际战斗胜率')
plt.plot(X_test, y_pred, 'r', label='预测战斗胜率')
plt.fill_between(X_test.flatten(), y_pred - 1.96 * sigma, y_pred + 1.96 * sigma, alpha=0.2, color='darkorange', label='95% 置信区间')
plt.xlabel('天数')
plt.ylabel('战斗胜率')
plt.title('高斯过程回归预测战斗胜率')
plt.legend()
plt.show()
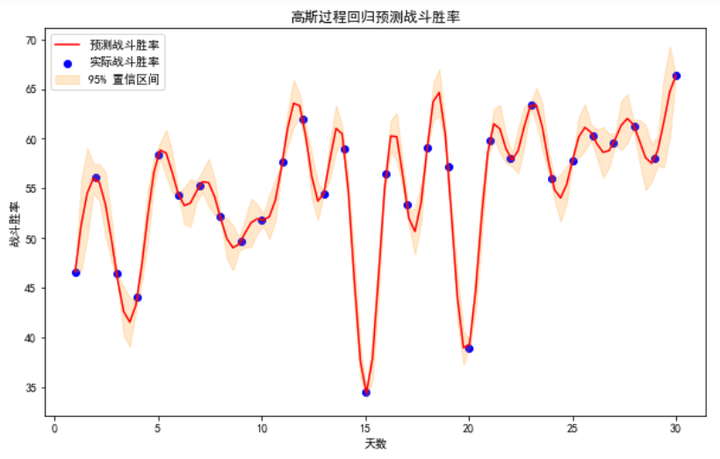
解说可视化结果
在上述可视化结果中,我们可以观察到以下几点:
- 实际战斗胜率:图中蓝色点表示实际战斗胜率,这些点是我们生成的训练数据中的实际观测值。
- 预测战斗胜率:红色曲线表示高斯过程回归模型对战斗胜率的预测值。这条曲线平滑地通过数据点,并尽量接近实际观测值,显示了模型对数据的拟合能力。
- 置信区间:图中橙色阴影区域表示预测值的 95% 置信区间。这一范围表示预测值的不确定性,其中包括了大部分的实际观测值。这表明模型在预测中的不确定性较小,且较好地捕捉了数据的趋势。
- 天数与战斗胜率的关系:从图中可以看出,随着天数的增加,战斗胜率总体上呈现上升趋势。这是因为功力和武器熟练度随着天数增加而提升,导致战斗胜率也随之上升。
我们展示了高斯过程回归模型在预测战斗胜率方面的应用。模型能够较好地拟合数据,并提供置信区间以表示预测的不确定性。
每天一个简单通透的小案例,如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~

[ 抱个拳,总个结 ]
- 高斯过程的基本原理和数学表述:高斯过程是一种强大的非参数机器学习方法,通过核函数度量数据点之间的相似性,并能够提供预测的不确定性估计。高斯过程的核心思想和基本数学表述在本文中得到了详细说明。
- 高斯过程在机器学习中的应用:高斯过程广泛应用于回归和分类问题。通过代码示范,我们展示了如何使用高斯过程模型进行训练和预测,并提供了相关的可视化结果,帮助大侠们更好地理解其应用效果。
- 高斯过程与其他算法:与线性回归、支持向量机和神经网络等算法相比,高斯过程在处理小样本数据和提供不确定性估计方面具有独特优势。同时,我们也讨论了高斯过程的计算复杂度和内存需求较高等缺点。
- 高斯过程的误区和注意事项:在使用高斯过程时,大侠们需要注意合理选择核函数和超参数,避免计算复杂度过高和内存需求过大。此外,应注意数据的完整性和代表性,以提高模型的预测性能。
- 高斯过程的扩展与实际案例:我们探讨了稀疏高斯过程、非平稳高斯过程和多任务高斯过程等扩展变体,展示了其在不同应用场景中的灵活性和优势。通过实际案例分析,我们展示了高斯过程在武侠数据集上的应用效果,并进行了详细的结果解读和可视化。
希望本文能够帮助大侠们更好地理解和应用高斯过程算法,提高在实际问题中的分析和预测能力。
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
算法金 | 一个强大的算法模型,GP !!的更多相关文章
- SIFT算法的应用--目标识别之Bag-of-words模型
原文:http://blog.csdn.net/v_JULY_v/article/details/6555899 SIFT算法的应用 -目标识别之用Bag-of-words模型表示一幅图像 作者:wa ...
- 【年终分享】彩票数据预测算法(一):离散型马尔可夫链模型实现【附C#代码】
原文:[年终分享]彩票数据预测算法(一):离散型马尔可夫链模型实现[附C#代码] 前言:彩票是一个坑,千万不要往里面跳.任何预测彩票的方法都不可能100%,都只能说比你盲目去买要多那么一些机会而已. ...
- Adaboost算法的一个简单实现——基于《统计学习方法(李航)》第八章
最近阅读了李航的<统计学习方法(第二版)>,对AdaBoost算法进行了学习. 在第八章的8.1.3小节中,举了一个具体的算法计算实例.美中不足的是书上只给出了数值解,这里用代码将它实现一 ...
- ZeroMQ接口函数之 :zmq_z85_decode – 从一个用Z85算法生成的文本中解析出二进制密码
ZeroMQ 官方地址 :http://api.zeromq.org/4-0:zmq_z85_decode zmq_z85_decode(3) ØMQ Manual - ØMQ/4.1 ...
- ZeroMQ接口函数之 :zmq_z85_encode – 使用Z85算法对一个二进制秘钥进行加密,输出可打印的文本
ZeroMQ 官方地址 :http://api.zeromq.org/4-0:zmq-z85-encode zmq_z85_encode(3) ØMQ Manual - ØMQ/4. ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- 深度剖析:如何实现一个 Virtual DOM 算法
本文转载自:https://github.com/livoras/blog/issues/13 目录: 1 前言 2 对前端应用状态管理思考 3 Virtual DOM 算法 4 算法实现 4.1 步 ...
- javascript 一个关于时间排序的算法(一个页面多个倒计时排序)
上周要做一个活动页面 秒杀列表页 需要一个时间的算法排序 自己琢磨了半天想了各种算法也没搞出来,后来问了下一个后台的php同学 他写了个算法给我看了下 ,刚开始看的时候觉得这就是个纯算法,不能转化成页 ...
- 一个UUID生成算法的C语言实现 --- WIN32版本 .
一个UUID生成算法的C语言实现——WIN32版本 cheungmine 2007-9-16 根据定义,UUID(Universally Unique IDentifier,也称GUID)在时 ...
- 一个由IsPrime算法引发的细节问题
//******************************* // // 2014年9月18日星期四,于宿舍撰写 // 作者:夏华林 // //******************* ...
随机推荐
- HarmonyOS 实战开发-Worker子线程中解压文件
介绍 本示例介绍在Worker子线程使用@ohos.zlib提供的zlib.decompressfile接口对沙箱目录中的压缩文件进行解压操作,解压成功后将解压路径返回主线程,获取解压文件列表. 效果 ...
- [FE] uni-app 导航栏开发指南
一种是 原生导航栏添加自定义按钮.简单明了. pages.json 配置 { "path": "pages/log/log", "style" ...
- WPF 简单实现一个支持删除自身的应用
我准备写一个逗比的应用,然而我担心被小伙伴看到这个应用的文件从而知道是我写的,于是我就需要实现让应用能自删除的功能.核心实现方法就是调用 cmd 传入命令行,等待几秒之后删除文件 应用程序在运行时,是 ...
- OLAP系列之分析型数据库clickhouse单机版部署(一)
一.概述 官网:https://clickhouse.com/docs/zh ClickHouse是Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够 ...
- 在网页上直接运行Win11,5秒内用AI克隆自己的声音 | 蛮三刀酱的Github周刊第二期
大家好,这里是每周更新的Github精彩分享周刊,我是每周都在搬砖的蛮三刀酱. 我会从Github热门趋势榜里选出 高质量.有趣,牛B 的开源项目进行分享. 1. PowerShell:不止于Wind ...
- CRAPS赌博小游戏
游戏规则 代码实现 首先把这个规则用代码写出来 再在它基础上进行简单的可视化(主要是利用Easygui的界面) 最后查缺补漏,看看有没有什么Bug 利用pyinstaller -F -w -i xx. ...
- 记录几十页html生成pdf的历程和坑(已用bookjs-easy解决)(生成、转换、拼接pdf)
懒得看的朋友,先说最终解决办法,主力为 前端依靠插件 bookjs-easy(点击直接跳转官网)并跳转到下面的第三点查看 接下来详细记录下整个试探的方向和历程 项目需求:是生成一个页数达到大几十页的p ...
- Mac安装mysql5.7
1.下载文件(访问就直接下载了) http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.10-osx10.10-x86_64.dmg 2.打开下 ...
- ansible(8)--ansible的hostname模块
1. hostname模块 功能:管理远程主机的主机名. 示例一:更改192.168.20.22的主机名为nginx01: [root@xuzhichao ~]# ansible 192.168.20 ...
- List集合中获取重复元素
一.方法1 ## 测试数据 List<String> words = Arrays.asList("a", "b", "c", ...