Bellman-Ford算法及SPFA算法的思路及进一步优化
Bellman-Ford算法
算法
以边为研究对象的最短路算法。
应用场景
有负边权的最短路问题。
负环的判定。
算法原理
\(n\) 个点的最短路径最多经过 \(n - 1\) 条边。
每条边要么经过,要么不经过,对于一条边的两个端点 \(x\) 和 \(y\)。
所以我们把每一条边都枚举一遍看是否可以进行松弛。将步骤 \(2\) 重复 \(n - 1\) 轮后,\(dis[i]\) 即为起点到达点 \(i\) 的最短路。
代码:
for (int i = 1; i <= n - 1; i++)
for (int j = 1; j <= m; j++)
if (dis[e[j].x] + e[j].w < dis[e[j].y])
dis[e[j].y] = dis[e[j].x] + e[j].w;
时间复杂度
显然是\(O(nm)\)。
Bellman-Ford算法的队列优化(SPFA)
一个点只会松弛它的邻接点,因此,只有 \(x\) 的邻接点的 \(y\) 被松驰过,点 \(x\) 才有松弛的必要。
用队列维护被松弛过的点集。
对于随机数据优化明显,但是最坏情况时间复杂度仍然为 \(O(nm)\)。
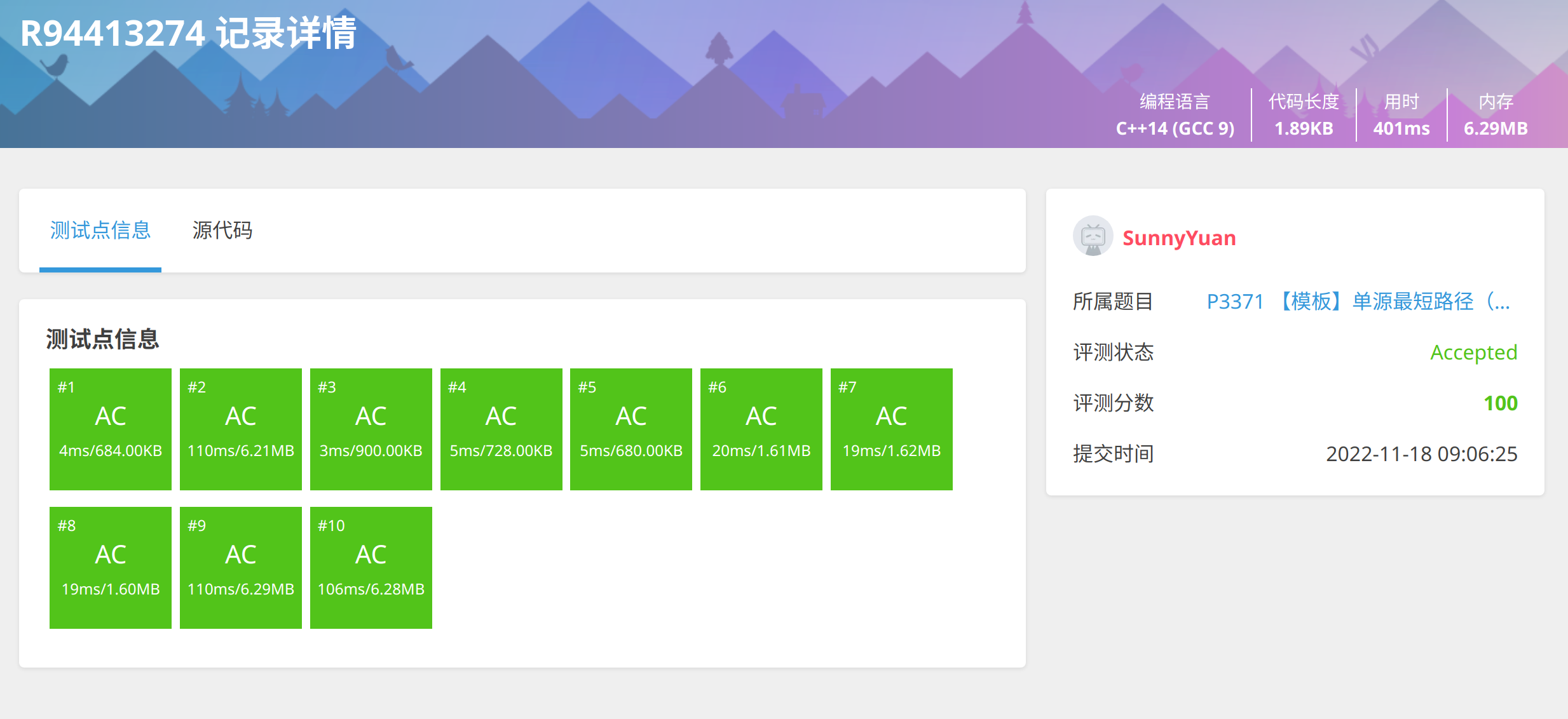
模板:Luogu P3371
1.SPFA代码
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
void spfa(int u)
{
queue<int> q;
q.push(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
while (q.size())
{
int t = q.front();
q.pop();
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
q.push(to);
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
2. 优化1:加一个st数组,防止元素重复进队列。
快了215ms
重点关注第27,35,41,49,50,51,52,53行。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
void spfa(int u)
{
queue<int> q;
q.push(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
while (q.size())
{
int t = q.front();
q.pop();
st[t] = false;
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
q.push(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
3. 优化2:SLF 优化
每次压入队列时,是看放后面还是前面,所以需要双端队列。
快了18ms
重点关注代码第31,52,53行。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
void spfa(int u)
{
deque<int> q;
q.emplace_back(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
while (q.size())
{
int t = q.front();
q.pop_front();
st[t] = false;
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
if (q.size() && dis[q.front()] >= dis[to]) q.emplace_front(to);
else q.emplace_back(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
4. 优化3:此优化仅针对不开O2优化时。
使用循环队列进行优化(我改编的)。
(开了O2优化效果不明显,亲自测试在跑网络流时快了800ms,TLE->AC)
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
int q[N];
int hh, tt;
int sz;
void push_back(int x)
{
sz++;
q[tt++] = x;
if (tt == N) tt = 0;
}
void push_front(int x)
{
sz++;
hh--;
if (hh == -1) hh = N - 1;
q[hh] = x;
}
void pop_back()
{
sz--;
tt--;
if (tt == -1) tt = N - 1;
}
void pop_front()
{
sz--;
hh++;
if (hh == N) hh = 0;
}
void spfa(int u)
{
push_back(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
while (sz)
{
int t = q[hh];
pop_front();
st[t] = false;
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
if (sz && dis[q[hh]] >= dis[to]) push_front(to);
else push_back(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
5. 优化4:LLL优化
如果当前队首元素 \(t\),队列长度为 \(size\),队列里各元素和为 \(sum\) ,有 \(dis[t] \times size \leq sum\),才取队首。
否则把队首元素压入队尾并弹出队首。
效果好像不怎么明显
重点关注代码的第68,72,73,74,75,76,91行。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
int q[N];
int hh, tt;
int sz;
void push_back(int x)
{
sz++;
q[tt++] = x;
if (tt == N) tt = 0;
}
void push_front(int x)
{
sz++;
hh--;
if (hh == -1) hh = N - 1;
q[hh] = x;
}
void pop_back()
{
sz--;
tt--;
if (tt == -1) tt = N - 1;
}
void pop_front()
{
sz--;
hh++;
if (hh == N) hh = 0;
}
void spfa(int u)
{
push_back(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
int sum = dis[u];
while (sz)
{
while (dis[q[hh]] * sz > sum)
{
push_back(q[hh]);
pop_front();
}
int t = q[hh];
pop_front();
st[t] = false;
sum -= dis[t];
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
sum += dis[to];
if (sz && dis[q[hh]] >= dis[to]) push_front(to);
else push_back(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
本文终
Bellman-Ford算法及SPFA算法的思路及进一步优化的更多相关文章
- 数据结构与算法--最短路径之Bellman算法、SPFA算法
数据结构与算法--最短路径之Bellman算法.SPFA算法 除了Floyd算法,另外一个使用广泛且可以处理负权边的是Bellman-Ford算法. Bellman-Ford算法 假设某个图有V个顶点 ...
- 最短路径——Bellman-Ford算法以及SPFA算法
说完dijkstra算法,有提到过朴素dij算法无法处理负权边的情况,这里就需要用到Bellman-Ford算法,抛弃贪心的想法,牺牲时间的基础上,换取负权有向图的处理正确. 单源最短路径 Bellm ...
- Bellman-ford算法、SPFA算法求解最短路模板
Bellman-ford 算法适用于含有负权边的最短路求解,复杂度是O( VE ),其原理是依次对每条边进行松弛操作,重复这个操作E-1次后则一定得到最短路,如果还能继续松弛,则有负环.这是因为最长的 ...
- Bellman-Ford算法与SPFA算法详解
PS:如果您只需要Bellman-Ford/SPFA/判负环模板,请到相应的模板部分 上一篇中简单讲解了用于多源最短路的Floyd算法.本篇要介绍的则是用与单源最短路的Bellman-Ford算法和它 ...
- 最短路径算法 4.SPFA算法(1)
今天所说的就是常用的解决最短路径问题最后一个算法,这个算法同样是求连通图中单源点到其他结点的最短路径,功能和Bellman-Ford算法大致相同,可以求有负权的边的图,但不能出现负回路.但是SPFA算 ...
- 图论之最短路算法之SPFA算法
SPFA(Shortest Path Faster Algorithm)算法,是一种求最短路的算法. SPFA的思路及写法和BFS有相同的地方,我就举一道例题(洛谷--P3371 [模板]单源最短路径 ...
- 最短路径算法之四——SPFA算法
SPAF算法 求单源最短路的SPFA算法的全称是:Shortest Path Faster Algorithm,该算法是西南交通大学段凡丁于1994年发表的. 它可以在O(kE)的时间复杂度内求出源点 ...
- 最短路径问题---Floyed(弗洛伊德算法),dijkstra算法,SPFA算法
在NOIP比赛中,如果出图论题最短路径应该是个常考点. 求解最短路径常用的算法有:Floyed算法(O(n^3)的暴力算法,在比赛中大概能过三十分) dijkstra算法 (堆优化之后是O(MlogE ...
- hdoj 1874 畅通工程续【dijkstra算法or spfa算法】
畅通工程续 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submi ...
- Bellman-ford算法与SPFA算法思想详解及判负权环(负权回路)
我们先看一下负权环为什么这么特殊:在一个图中,只要一个多边结构不是负权环,那么重复经过此结构时就会导致代价不断增大.在多边结构中唯有负权环会导致重复经过时代价不断减小,故在一些最短路径算法中可能会凭借 ...
随机推荐
- PyInstaller打包的文件闪退
问题描述:使用PyInstaller打包的pycharm写的python程序,打包好后从windows上打开一直闪退 一.双击exe文件闪退,从cmd命令行中与加载程序,可以看到具体的报错 D:\di ...
- Carla 自动驾驶仿真平台的安装与配置指南
简介 Carla 是一款基于 Python 编写和 UE(虚幻引擎)的开源仿真器,用于模拟自动驾驶车辆在不同场景下的行为和决策.它提供了高度可定制和可扩展的驾驶环境,包括城市.高速公路和农村道路等.C ...
- 你真的懂synchronized锁?
1. 前言 synchronized在我们的程序中非常的常见,主要是为了解决多个线程抢占同一个资源.那么我们知道synchronized有多种用法,以下从实践出发,题目由简入深,看你能答对几道题目? ...
- Hugging News #0414: Attention 在多模态情景中的应用、Unity API 以及 Gradio 主题构建器
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- Rainbond 结合 Jpom 实现云原生 & 本地一体化项目管理
Jpom 是一个简而轻的低侵入式在线构建.自动部署.日常运维.项目运维监控软件.提供了: 节点管理:集群节点,统一管理多节点的项目,实现快速一键分发项目文件 项目管理:创建.启动.停止.实时查看项目控 ...
- docker上面部署nginx-waf 防火墙“modsecurity”,使用CRS规则,搭建WEB应用防火墙
web防火墙(waf)免费开源的比较少,并且真正可以商用的WAF少之又少,modsecurity 是开源防火墙鼻祖并且有正规公司在维护着,目前是https://www.trustwave.com在维护 ...
- 阿里云交互式建模(DSW)的探索和踩坑
前言 自己的笔记本炼丹还是太吃力了些,风扇嘶吼有点心疼,看到阿里云出了一些免费试用的资源,想着能白嫖一下高端显卡跑一跑自制模型还挺有趣,于是有了下面的一些操作,其实没啥难度的,大胆的按文档来做基本就可 ...
- NC20279 [SCOI2010]序列操作
题目链接 题目 题目描述 lxhgww最近收到了一个01序列,序列里面包含了n个数,这些数要么是0,要么是1,现在对于这个序列有五种变换操作和询问操作: 0 a b 把[a, b]区间内的所有数全变成 ...
- 案例分享-full gc导致k8s pod重启
在之前的记一次k8s pod频繁重启的优化之旅中分享过对于pod频繁重启的一些案例,最近又遇到一例,继续分享出来希望能给大家带来些许收获. 问题现象 报警群里突然显示某pod频繁重启,我随即上去查看日 ...
- 音视频八股文(11)-- ffmpeg avio 内存输入和内存输出。内存输出有完整代码,网上很少有的。
1.avio介绍 avio是FFmpeg中的一个模块,用于实现多种输入输出方式的封装. avio提供了一系列API,可以将数据从内存读取到缓冲区中,也可以将缓冲区中的数据写入到内存中.其实现依赖于IO ...