基于Python的性能分析
1、什么是性能分析
字面意思就是对程序的性能,从用户角度出发就是运行的速度,占用的内存。
通过对以上情况的分析,来决定程序的哪部份能被优化。提高程序的速度以及内存的使用效率。
首先我们要弄清楚造成时间方面性能低的原因有哪些
- 沉重的I/O操作,比如读取分析大文件,长时间执行数据库查询,调用外部服务例如请求。
- 出现了内存泄露,消耗了所有内存,导致没有内存使用程序崩溃。
- 未经过优化的代码被频繁执行。
- 密集的操作在可以缓存的时没有缓存,占用大量资源。
大部分的性能瓶颈都是由I/O关联的代码引起
2、运行时间分析
1.1、cProfile性能分析器
这个工具并不关心内存消耗等信息。
import cProfile
def is_prime(n)-> bool:
'''
判断一个数是否为素数
- n : 待判断的数
'''
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
def sum_of_primes_below_n(n)-> bool:
'''
计算小于等于 n 的所有素数的和
- n : 待计算的数
- return : 所有素数的和
'''
total = 0
for i in range(2, n + 1):
if is_prime(i):
total += i
return total
def factorial(n)-> int:
'''
计算 n 的阶乘
- n : 待计算的数
- return : n 的阶乘
'''
if n == 0:
return 1
return n * factorial(n - 1)
def fibonacci(n)-> int:
'''
计算斐波那契数列的第 n 个数
- n : 待计算的数
- return : 第 n 个斐波那契数
'''
if n <= 1:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
def main():
cProfile.run('sum_of_primes_below_n(1000)')
cProfile.run('factorial(20)')
cProfile.run('fibonacci(20)')
if __name__ == "__main__":
main()
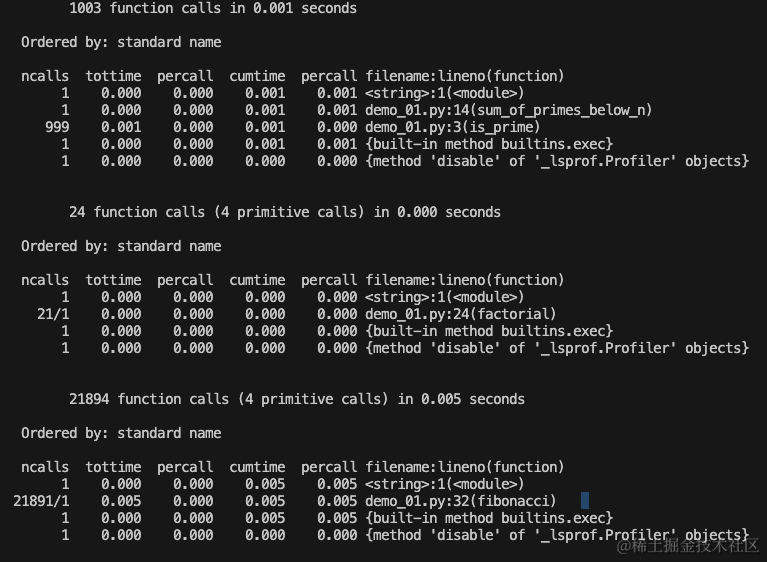
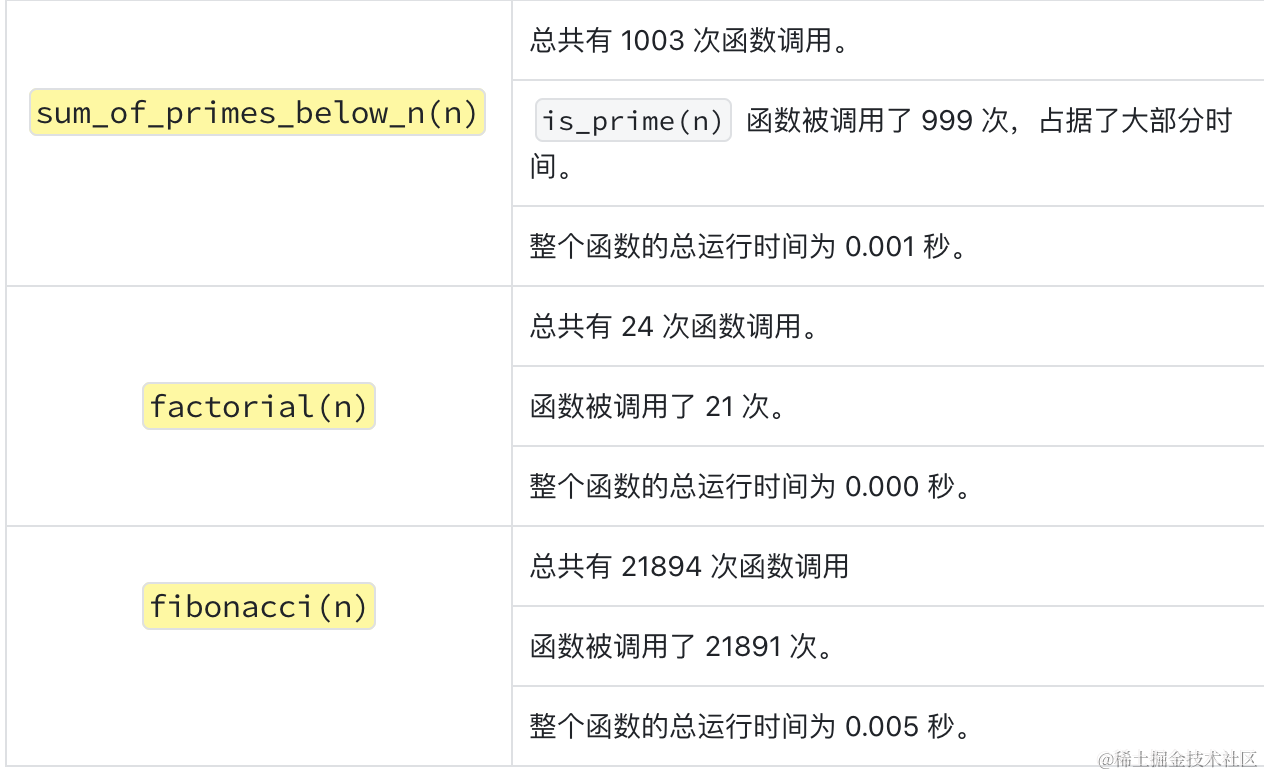
这里用于统计函数的调用次数以及允许的时间,用于排查程序的瓶颈。
这里只作为举例,感兴趣的可以自行下去了解。
1.1.1、Profile类
这里只需要修改部分代码即可。
不存在透明的性能分析器,虽然cProfile只消耗极小的性能分析器,仍然会对代码造成影响。如果大量使用会对程序造成很大影响。
if __name__ == "__main__":
pro = cProfile.Profile()
pro.enable()
main()
pro.create_stats()
pro.print_stats()
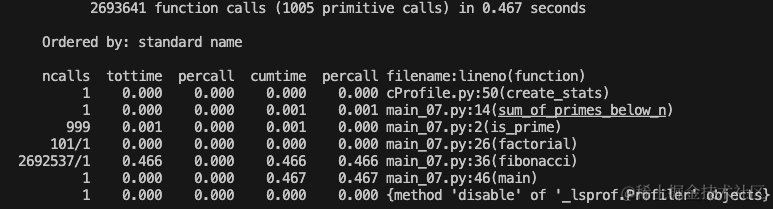
ncalls: 函数调用的次数。tottime: 函数的总运行时间。percall: 平均每次函数调用的运行时间(tottime除以ncalls)。cumtime: 函数及其所有子函数调用的总运行时间。percall: 平均每次函数调用的累积运行时间(cumtime除以ncalls)。filename:lineno(function): 函数所在的文件名、行号以及函数名。
这里很显然更详细,更可靠。这里补充一些其他方法,感兴趣的可以下去自行了解。
enable() |
开始收集性能分析数据 |
|---|---|
disable() |
停止收集性能分析数据 |
create_stats() |
停止收集数据,并为已收集的数据创建stats对象 |
print_stats(sort=-1) |
创建一个stats对象,打印分析结果 |
dump_stats(filename) |
把当前性能分析的内容写进一个文件 |
run(cmd) |
将指定函数的性能分析结果打印出来 |
runctx(cmd,globals,locals) |
在指定的全局和局部命名空间中运行一个字符串表示的 Python 命令,并对其进行性能分析 |
runcall(func,*args,**kwargs) |
收集被调用函数func的性能分析信息 |
1.1.2、Sats类
用于分析 Profile 收集的数据。
if __name__ == "__main__":
pro = cProfile.Profile()
pro.enable()
main()
pro.create_stats()
p = pstats.Stats(pro)
p.print_stats(3,1.0,'.*.py.*')

3: 限制打印输出的行数,仅打印前10行。1.0: 限制仅打印累积运行时间占总运行时间的1%以上的函数。'.*.py.*': 使用正则表达式过滤函数名,仅打印包含'.py.'的函数。
这里还有许多其他的用法,这里只是简单举例。感兴趣的可以自行了解。
1.2、statprof统计式性能分析
优点:
- 分析的数据更少:对程序执行过程中进行抽样,不用保留每一条数据。
- 对性能造成的影响更小:使用抽样式(用操作系统中断),目标程序的性能遭受的干扰更小。
import statprof
def is_prime(n)-> bool:
'''
判断一个数是否为素数
- n : 待判断的数
'''
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
def sum_of_primes_below_n(n)-> bool:
'''
计算小于等于 n 的所有素数的和
- n : 待计算的数
- return : 所有素数的和
'''
total = 0
for i in range(2, n + 1):
if is_prime(i):
total += i
return total
def factorial(n)-> int:
'''
计算 n 的阶乘
- n : 待计算的数
- return : n 的阶乘
'''
if n == 0:
return 1
return n * factorial(n - 1)
def fibonacci(n)-> int:
'''
计算斐波那契数列的第 n 个数
- n : 待计算的数
- return : 第 n 个斐波那契数
'''
if n <= 1:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
def main():
sum_of_primes_below_n(1000)
factorial(100)
fibonacci(30)
if __name__ == "__main__":
statprof.start()
main()
statprof.stop()
statprof.display()
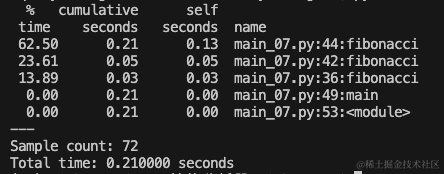
Sample count: 72 |
这里表示采样的次数,statprof一共采样了72次 |
|---|---|
Total time: 0.210000 seconds |
整个性能分析的总时间 |
time |
这一列为占用程序的百分比 |
seconds |
这一列为函数在调用栈中的累积时间 |
seconds |
这一列为函数自身消耗的时间,不包括调用其他函数 |
name |
这一列为函数的名称 |
这里不必将整个程序运行完毕,更节省时间(在性能需要优化的情况下)。其次采样分析,数据更加可靠。
这里依然只是做个简单的例子,感兴趣的可以自行下去了解。
总结:cProfile主要用于统计函数调用次数、执行时间等。相对来说性能开销是比较小的。并且有多种输出格式,例如JSON等数据格式,这里只是举例,感兴趣的可以自行了解。
3、运行内存分析
这里使用模块memory_profiler举例,用对程序运行时的内存监控。
可以分别对单进程、多进程、记录子进程内存占用,多进程记录子进程内存占用。
并且可以使用matplotlib进行数据的可视化,支持多种可视化样式。这里分别做简单解释。
3.1、单进程分析
这里为了便于理解,就不涉及复杂的代码,所以可能效果没有这么明显,感兴趣可以自己去了解
import numpy as np
import time
def create_large_array(n):
'''创建n*n的矩阵
- param size: 矩阵大小
- return: 矩阵'''
return np.zeros((n, n))
def modify_array(arr):
'''修改矩阵的值
arr: 矩阵'''
size = arr.shape[0]
arr[:size//2, :size//2] += 1
if __name__ == "__main__":
large_array = create_large_array(1000)
for i in range(10):
modify_array(large_array)
time.sleep(1)
large_array = create_large_array(1000 + i * 100)
运行mprof run main.py
会生成一个.dat文件。可以使用matplotlib进行可视化,效果更明显。
如果只有一个dat文件的话,可以直接运行mprof plot
如果有多个dat文件的话,需要接文件名mprof plot filename.dat
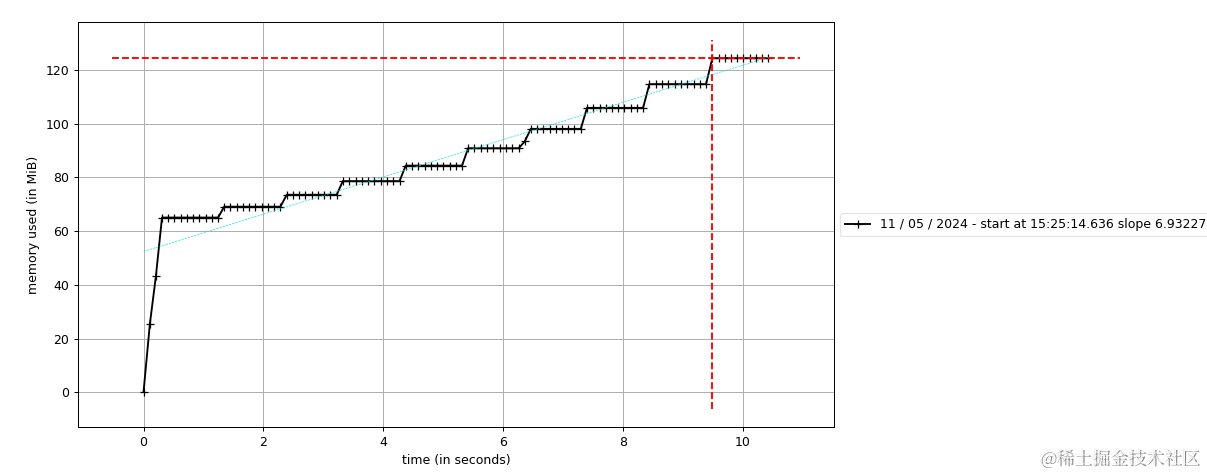
可以清晰的看到程序运行时间段的内存使用情况,情况在业务中远比这复杂的多。
3.2、多进程分析
import numpy as np
import time
from multiprocessing import Process, Queue
def create_large_array(n, queue):
'''创建n*n的矩阵并将其放入队列中
- param n: 矩阵大小
- param queue: 进程通信队列
'''
arr = np.zeros((n, n))
queue.put(arr)
def modify_array(arr):
'''修改矩阵的值
arr: 矩阵'''
size = arr.shape[0]
arr[:size//2, :size//2] += 1
if __name__ == "__main__":
queue = Queue()
create_large_array(1000, queue)
for i in range(5):
large_array = queue.get()
process = Process(target=modify_array, args=(large_array,))
process.start()
time.sleep(1)
create_large_array(1000 + i * 100, queue)
process.join()
mprof run --include-children --multiprocess filename.py
生成dat分析文件,使用matplotlib可视化
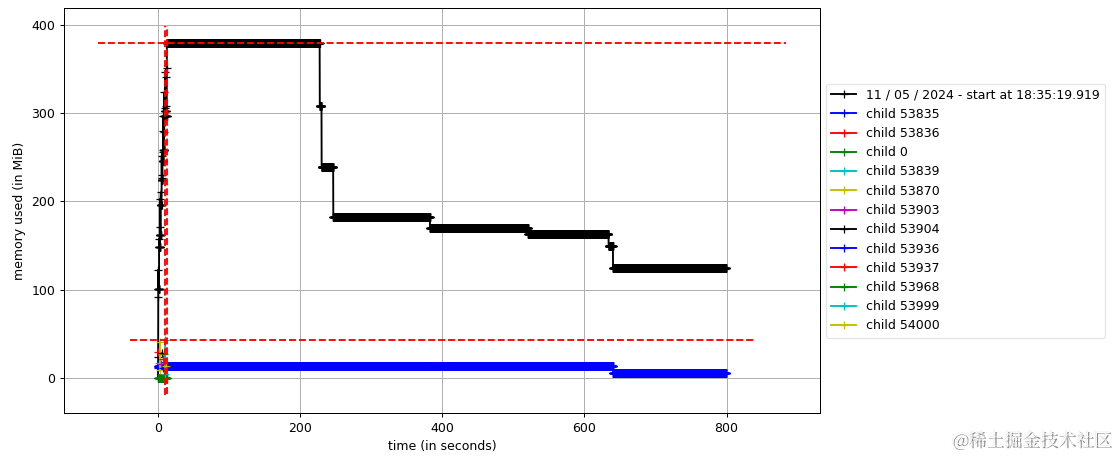
可以很直观的感受程序中各进程的内存使用情况,可以看到是下降趋势的,说明没有出现内存泄露,如果是一直规律的向上增长,那么你可能需要注意啦。
这里使用matplotlib绘图还有各种各样的样式,感兴趣的可以下去了解。包括各式各样的分析工具。
4、总结
这里主要简单分析程序的运行的运行时间和程序在运行过程中的内存使用情况。
时间方面,可以函数分析也可以逐句分析。这里大家可以自行下去了解。
内存方面,主要是要避免出现内存泄露,通过分析进程、线程的内存使用情况,判断瓶颈。
实际情况可能远比这复杂的多,这里的代码都只是用于简单示例,感兴趣的可以去研究一下。
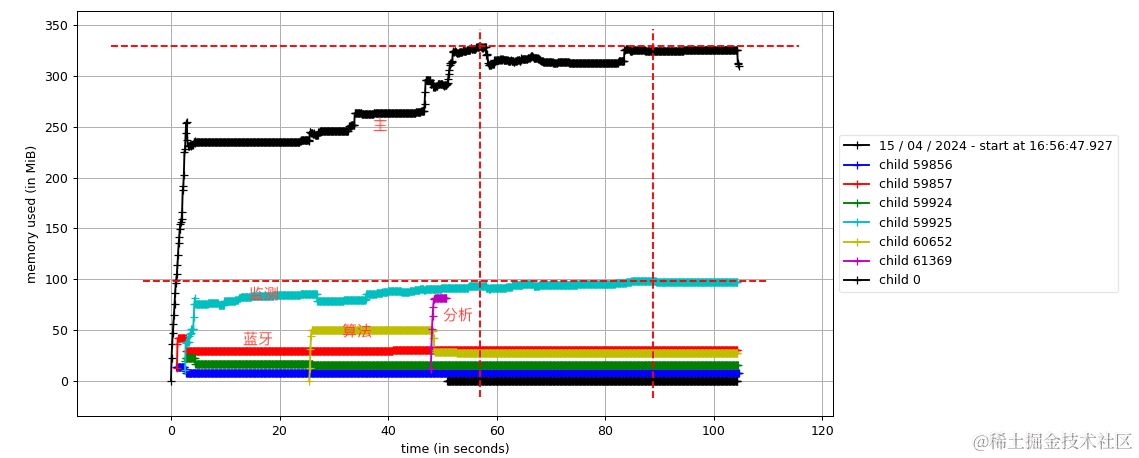
顺便分享一下我在实际项目中对内存分析的结果。
基于Python的性能分析的更多相关文章
- Python, Django 性能分析工具的使用
最近接手的 Apache HUE 项目性能出现了问题,线上经常出现响应时间过长或因为时间过长而无法服务等问题.老大让我准备弄个性能分析工具,便于追踪和分析平台当前的瓶颈出现在哪里. 那就搞起吧!先从代 ...
- 符号执行-基于python的二进制分析框架angr
转载:All Right 符号执行概述 在学习这个框架之前首先要知道符号执行.符号执行技术使用符号值代替数字值执行程序,得到的变量的值是由输入变 量的符号值和常量组成的表达式.符号执行技术首先由Kin ...
- 使用 profile 进行python代码性能分析
定位程序性能瓶颈 对代码优化的前提是需要了解性能瓶颈在什么地方,程序运行的主要时间是消耗在哪里,对于比较复杂的代码可以借助一些工具来定位,python 内置了丰富的性能分析工具,如 profile,c ...
- python 代码性能分析 库
问题描述 1.Python开发的程序在使用过程中很慢,想确定下是哪段代码比较慢: 2.Python开发的程序在使用过程中占用内存很大,想确定下是哪段代码引起的: 解决方案 使用profile分析分析c ...
- Python脚本性能分析
来自:http://www.cnblogs.com/btchenguang/archive/2012/02/03/2337112.html def foo(): sum = 0 for i in ra ...
- python 函数性能分析
1 使用profile分析函数性能示例1, 以profile为例: import profile def profileTest(): Total =1; for i in range(10): To ...
- python profile性能分析
#! /usr/bin/env python # encoding=utf8 import profile def func1(): for i in range(1000): pass def fu ...
- Python性能分析与优化PDF高清完整版免费下载|百度云盘
百度云盘|Python性能分析与优化PDF高清完整版免费下载 提取码:ubjt 内容简介 全面掌握Python代码性能分析和优化方法,消除性能瓶颈,迅速改善程序性能! 对于Python程序员来说,仅仅 ...
- 关于Python Profilers性能分析器
1. 介绍性能分析器 作者:btchenguang profiler是一个程序,用来描述运行时的程序性能,并且从不同方面提供统计数据加以表述.Python中含有3个模块提供这样的功能,分别是cProf ...
- python——关于Python Profilers性能分析器
1. 介绍性能分析器 profiler是一个程序,用来描述运行时的程序性能,并且从不同方面提供统计数据加以表述.Python中含有3个模块提供这样的功能,分别是cProfile, profile和ps ...
随机推荐
- 使用OHOS SDK构建cityhash
参照OHOS IDE和SDK的安装方法配置好开发环境. 从github下载源码. 执行如下命令: git clone https://github.com/google/cityhash.git 从v ...
- 虚实相生,构建数智生活|HMS Core. Sparkle应用创新分论坛报名启动
XR技术的发展,为用户带来了全新的体验模式.那么,作为支撑XR发展主要学科之一的图形学,将迎来哪些发展新机遇?移动应用开发者,该如何拥抱3D数字化转型? 7月15日,HDD·HMS Core. Spa ...
- 你真会判断DataGuard的延迟吗?
这是一个比较细节的知识点,但必须要理解这个才能准确判断Oracle ADG的延迟情况. 以前做运维工作时,记得是要同时重点关注v$dataguard_stats视图中的几个字段的值,分别是:NAME. ...
- EZHTTP(一键安装Nginx Apache PHP MySQL Memcached Pureftpd)安装【测试ing】
EZHTTP(一键安装Nginx Apache PHP MySQL Memcached Pureftpd)安装 [复制链接] 本帖最后由 梁国平 于 2014-2-11 22:47 编辑 简介 ...
- This beta version of Typora is expired, please download and install a newer version. 实测最简单有效的方案
This beta version of Typora is expired, please download and install a newer version. 实测最简单有效的方案 一.问题 ...
- 【笔记】rocketMQ了解
记录rocketMQ 忘了从哪儿保存的图了 原图链接:https://www.jianshu.com/p/2838890f3284
- 关于Kubernetes规划的灵魂n问
Kubernetes已经成为企业新一代云IT架构的重要基础设施,但是在企业部署和运维Kubernetes集群的过程中,依然充满了复杂性和困扰.阿里云容器服务自从2015年上线后,一路伴随客户和社区的成 ...
- 混合云K8s容器化应用弹性伸缩实战
简介: 混合云K8s容器化应用弹性伸缩实战 1. 前提条件 本最佳实践的软件环境要求如下:应用环境:①容器服务ACK基于专有云V3.10.0版本.②公共云云企业网服务CEN.③公共云弹性伸缩组服务ES ...
- 百信银行基于 Apache Hudi 实时数据湖演进方案
简介: 本文介绍了百信银行实时计算平台的建设情况,实时数据湖构建在 Hudi 上的方案和实践方法,以及实时计算平台集成 Hudi 和使用 Hudi 的方式. 本文介绍了百信银行实时计算平台的建设情况, ...
- 鸿蒙HarmonyOS实战-ArkUI动画(页面转场动画)
前言 页面转场动画是指在应用程序中,当用户导航到另一个页面时,使用动画效果来过渡页面之间的切换.这样做的目的是为了提升用户体验,使页面之间的切换更加平滑和有趣. 常见的页面转场动画包括淡入淡出.滑动. ...