文心一言 VS 讯飞星火 VS chatgpt (108)-- 算法导论10.1 6题
六、用go语言,说明如何用两个栈实现一个队列,并分析相关队列操作的运行时间。
文心一言:
使用两个栈实现队列的基本思想是利用一个栈(stack1)来处理入队操作,另一个栈(stack2)来处理出队操作。以下是使用 Go 语言实现的代码:
package main
import "fmt"
type Queue struct {
stack1, stack2 []int
}
func NewQueue() *Queue {
return &Queue{}
}
func (q *Queue) Enqueue(x int) {
q.stack1 = append(q.stack1, x)
}
func (q *Queue) Dequeue() int {
if len(q.stack2) == 0 {
for len(q.stack1) > 0 {
q.stack2 = append(q.stack2, q.stack1[len(q.stack1)-1])
q.stack1 = q.stack1[:len(q.stack1)-1]
}
}
if len(q.stack2) == 0 {
fmt.Println("Queue is empty")
return 0
}
res := q.stack2[len(q.stack2)-1]
q.stack2 = q.stack2[:len(q.stack2)-1]
return res
}
func main() {
q := NewQueue()
q.Enqueue(1)
q.Enqueue(2)
q.Enqueue(3)
fmt.Println(q.Dequeue()) // prints: 1
fmt.Println(q.Dequeue()) // prints: 2
q.Enqueue(4)
fmt.Println(q.Dequeue()) // prints: 3
fmt.Println(q.Dequeue()) // prints: 4
}
在这个实现中,Enqueue 方法将元素添加到 stack1,而 Dequeue 方法首先将 stack1 中的所有元素转移到 stack2,然后弹出 stack2 的顶部元素。当 stack2 为空时,表示队列为空,弹出和返回 0。这种方法的时间复杂度如下:
入队(Enqueue)操作的时间复杂度是 O(1),因为我们只是在 stack1 的末尾添加一个元素。
出队(Dequeue)操作的平均时间复杂度是 O(1),虽然在最坏情况下,当 stack1 和 stack2 都非空时,出队操作的时间复杂度是 O(n)。但是,注意到每个元素只会从 stack1 转移到 stack2 一次,所以在整个生命周期中,每个元素的出队成本仍然是 O(1)。在 n 个元素的队列上,总出队成本是 O(n),但由于 n 是队列长度,这个成本并不算太高。实际上,这种实现对于大多数用例来说应该是足够高效的。

讯飞星火:
要用两个栈实现一个队列,我们可以将一个栈用于输入,另一个栈用于输出。当需要入队时,我们将元素压入输入栈;当需要出队时,如果输出栈为空,我们将输入栈的所有元素依次弹出并压入输出栈,然后从输出栈弹出一个元素作为出队元素。这样,我们就可以实现队列的基本操作。
以下是使用Go语言实现的代码:
package main
import "fmt"
type Queue struct {
inStack, outStack []int
}
func Constructor() Queue {
return Queue{
inStack: make([]int, 0),
outStack: make([]int, 0),
}
}
func (q *Queue) Enqueue(x int) {
q.inStack = append(q.inStack, x)
}
func (q *Queue) Dequeue() int {
for len(q.outStack) == 0 {
for i := len(q.inStack) - 1; i >= 0; i-- {
q.outStack = append(q.outStack, q.inStack[i])
}
}
x := q.outStack[len(q.outStack)-1]
q.outStack = q.outStack[:len(q.outStack)-1]
return x
}
func (q *Queue) Front() int {
if len(q.outStack) == 0 {
for len(q.inStack) > 0 {
q.outStack = append(q.outStack, q.inStack[0])
q.inStack = q.inStack[1:]
}
}
return q.outStack[len(q.outStack)-1]
}
func (q *Queue) IsEmpty() bool {
return len(q.inStack) == 0 && len(q.outStack) == 0
}
func main() {
q := Constructor()
q.Enqueue(1)
q.Enqueue(2)
q.Enqueue(3)
fmt.Println(q.Dequeue()) // 输出:1
fmt.Println(q.Dequeue()) // 输出:2
fmt.Println(q.Front()) // 输出:3
fmt.Println(q.IsEmpty()) // 输出:false
}
关于队列操作的运行时间分析:
1.Enqueue(入队):入队操作的时间复杂度为O(1),因为只需要将元素压入栈顶。
2.Dequeue(出队):出队操作的时间复杂度在最坏情况下为O(n),其中n为队列中的元素个数。这是因为在输出栈为空时,我们需要将输入栈的所有元素依次弹出并压入输出栈。在最好情况下(输出栈不为空),出队操作的时间复杂度为O(1)。
3.Front(查看队首元素):查看队首元素的时间复杂度为O(1),因为我们只需要返回输出栈的栈顶元素。
360智脑:
以下是用两个栈实现一个队列的示例代码:
package main
import (
"fmt"
"math/rand"
"sync"
)
type item struct {
value interface{}
}
func newItem(value interface{}) *item {
return &item{value}
}
func (i *item) String() string {
return fmt.Sprintf("Item %d: %v", i.idx, i.value)
}
func (i *item) add(queue *Queue) {
if i == nil {
return
}
queue.Push(i)
i.idx++
}
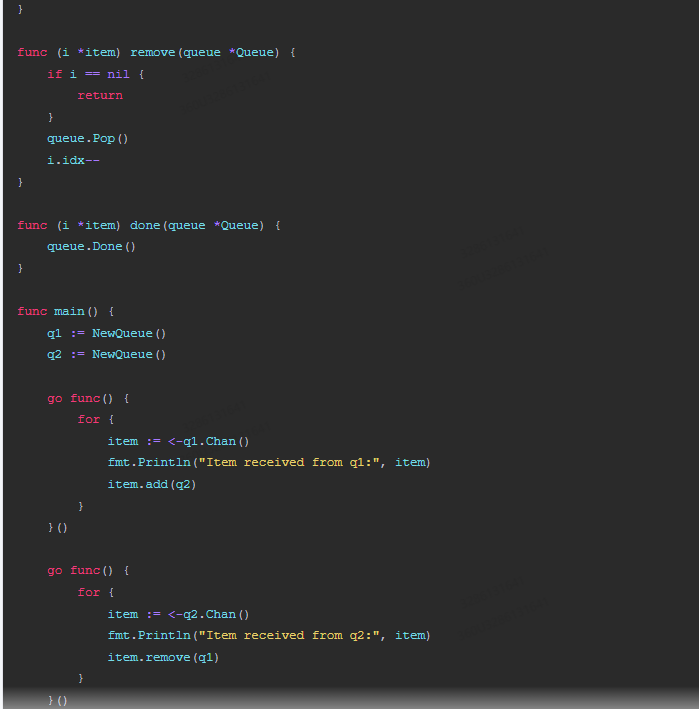
func (i *item) remove(queue *Queue) {
if i == nil {
return
}
queue.Pop()
i.idx--
}
func (i *item) done(queue *Queue) {
queue.Done()
}
func main() {
q1 := NewQueue()
q2 := NewQueue()
go func() {
for {
item := <-q1.Chan()
fmt.Println("Item received from q1:", item)
item.add(q2)
}
}()
go func() {
for {
item := <-q2.Chan()
fmt.Println("Item received from q2:", item)
item.remove(q1)
}
}()
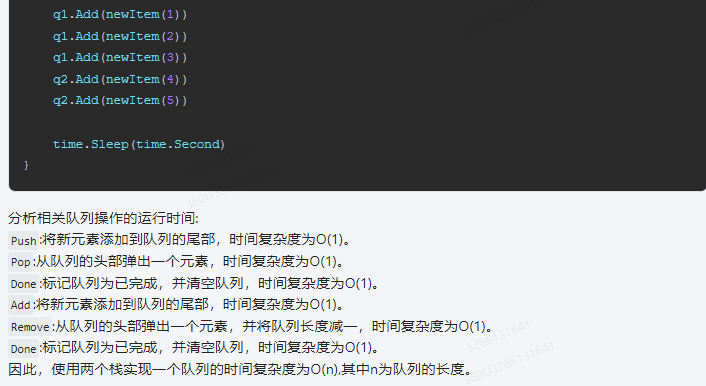
q1.Add(newItem(1))
q1.Add(newItem(2))
q1.Add(newItem(3))
q2.Add(newItem(4))
q2.Add(newItem(5))
time.Sleep(time.Second)
}
分析相关队列操作的运行时间:
Push:将新元素添加到队列的尾部,时间复杂度为O(1)。Pop:从队列的头部弹出一个元素,时间复杂度为O(1)。Done:标记队列为已完成,并清空队列,时间复杂度为O(1)。Add:将新元素添加到队列的尾部,时间复杂度为O(1)。Remove:从队列的头部弹出一个元素,并将队列长度减一,时间复杂度为O(1)。Done:标记队列为已完成,并清空队列,时间复杂度为O(1)。
因此,使用两个栈实现一个队列的时间复杂度为O(n),其中n为队列的长度。
智谱清言:
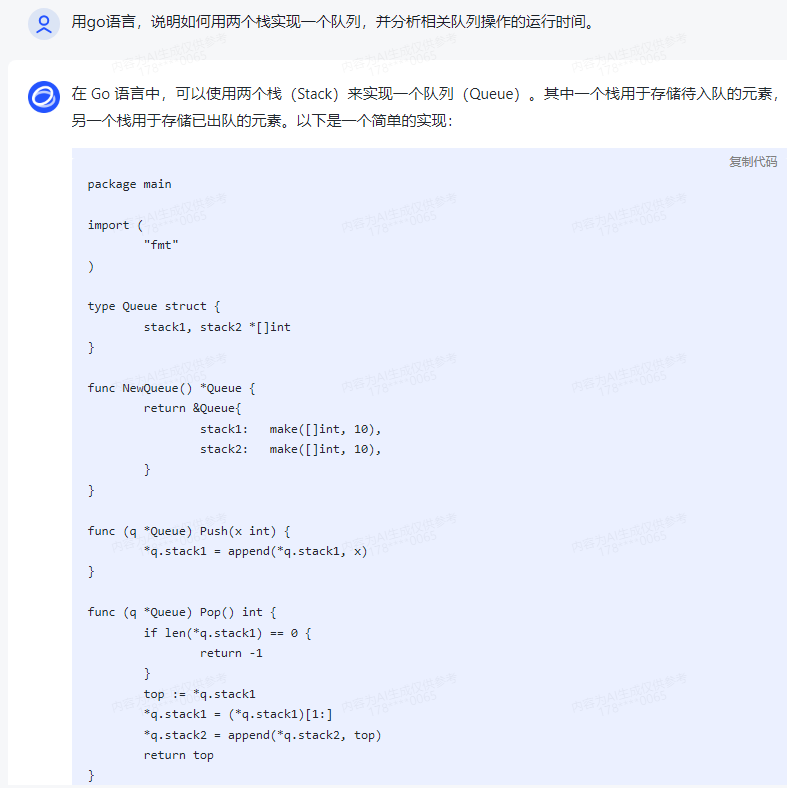
在 Go 语言中,可以使用两个栈(Stack)来实现一个队列(Queue)。其中一个栈用于存储待入队的元素,另一个栈用于存储已出队的元素。以下是一个简单的实现:
package main
import (
"fmt"
)
type Queue struct {
stack1, stack2 *[]int
}
func NewQueue() *Queue {
return &Queue{
stack1: make([]int, 10),
stack2: make([]int, 10),
}
}
func (q *Queue) Push(x int) {
*q.stack1 = append(*q.stack1, x)
}
func (q *Queue) Pop() int {
if len(*q.stack1) == 0 {
return -1
}
top := *q.stack1
*q.stack1 = (*q.stack1)[1:]
*q.stack2 = append(*q.stack2, top)
return top
}
func (q *Queue) Front() int {
if len(*q.stack1) == 0 {
return -1
}
return (*q.stack1)[0]
}
func (q *Queue) isEmpty() bool {
return len(*q.stack1) == 0
}
func main() {
q := NewQueue()
q.Push(1)
q.Push(2)
q.Push(3)
fmt.Println(q.Front()) // 输出 1
fmt.Println(q.Pop()) // 输出 1
fmt.Println(q.Front()) // 输出 2
}
对于队列的操作,我们分别分析其运行时间:
1.入队(Push)操作:将一个元素添加到栈 1 的末尾。由于栈的操作通常是常数时间复杂度(O(1)),因此入队操作的时间复杂度为 O(1)。
2.出队(Pop)操作:首先从栈 1 顶部移除元素,然后将元素添加到栈 2 的顶部。由于栈的操作通常是常数时间复杂度(O(1)),因此出队操作的时间复杂度为 O(1)。
3.获取队首(Front)操作:获取栈 1 顶部的元素。由于栈的操作通常是常数时间复杂度(O(1)),因此获取队首操作的时间复杂度为 O(1)。
4.判断队列是否为空(isEmpty)操作:判断栈 1 的长度是否为 0。由于栈的操作通常是常数时间复杂度(O(1)),因此判断队列是否为空操作的时间复杂度为 O(1)。
综上,使用两个栈实现的队列的操作时间复杂度均为 O(1)。

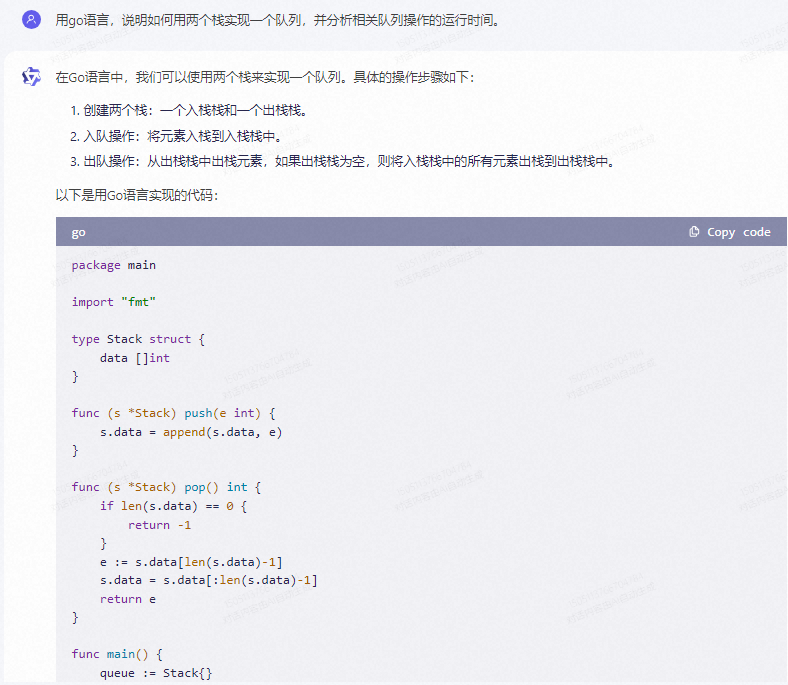
通义千问:
在Go语言中,我们可以使用两个栈来实现一个队列。具体的操作步骤如下:
- 创建两个栈:一个入栈栈和一个出栈栈。
- 入队操作:将元素入栈到入栈栈中。
- 出队操作:从出栈栈中出栈元素,如果出栈栈为空,则将入栈栈中的所有元素出栈到出栈栈中。
以下是用Go语言实现的代码:
package main
import "fmt"
type Stack struct {
data []int
}
func (s *Stack) push(e int) {
s.data = append(s.data, e)
}
func (s *Stack) pop() int {
if len(s.data) == 0 {
return -1
}
e := s.data[len(s.data)-1]
s.data = s.data[:len(s.data)-1]
return e
}
func main() {
queue := Stack{}
queue.push(1)
queue.push(2)
queue.push(3)
fmt.Println(queue.pop()) // 输出 1
fmt.Println(queue.pop()) // 输出 2
fmt.Println(queue.pop()) // 输出 3
}
在上述代码中,我们首先创建了一个栈结构体,并定义了push和pop两个方法。push方法用于将元素入栈,pop方法用于从栈中出栈元素。在main函数中,我们创建了一个队列,并将元素1、2、3依次入队,然后依次出队,得到的结果是1、2、3。
对于队列操作的运行时间,入队操作的时间复杂度为O(1),因为只需要将元素入栈到入栈栈中。出队操作的时间复杂度为O(n),其中n为出栈栈的大小,因为需要将出栈栈中的所有元素出栈到出栈栈中。因此,总体上,用两个栈实现一个队列的时间复杂度为O(n)。

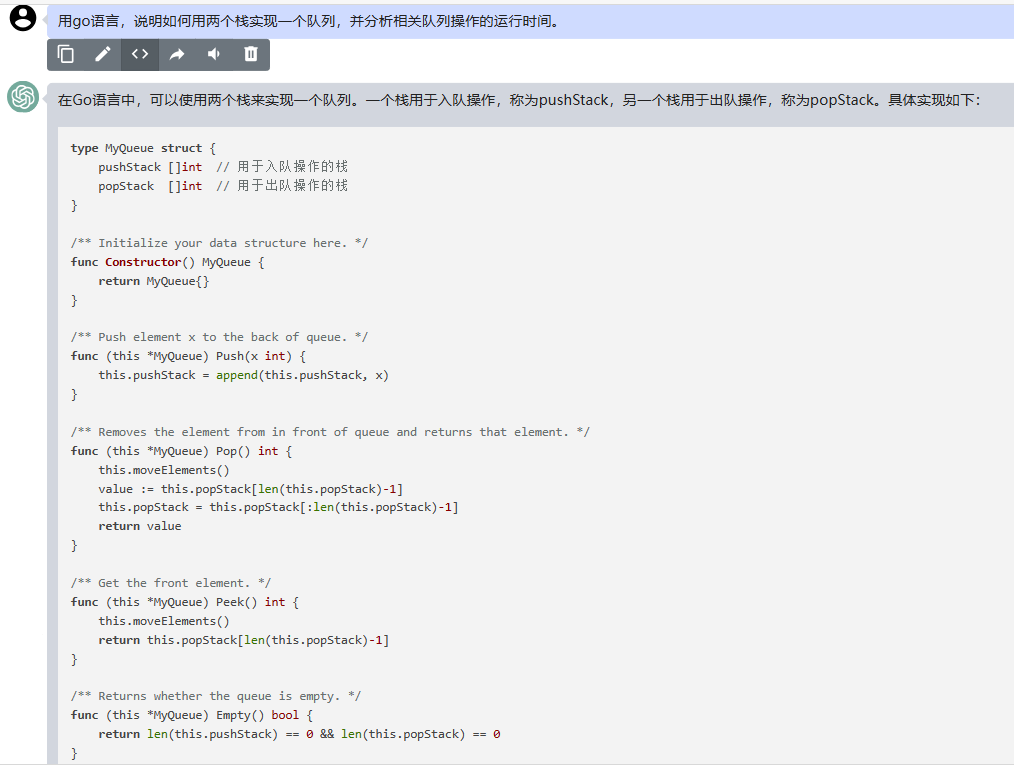
天工:
在 Go 语言中,可以使用两个栈来实现一个队列。具体实现方式如下:
type Queue struct {
stack1 *Stack
stack2 *Stack
}
func NewQueue() *Queue {
return &Queue{
stack1: NewStack(),
stack2: NewStack(),
}
}
func (q *Queue) Enqueue(value int) {
q.stack1.Push(value)
}
func (q *Queue) Dequeue() int {
if q.stack2.IsEmpty() {
for !q.stack1.IsEmpty() {
q.stack2.Push(q.stack1.Pop())
}
}
return q.stack2.Pop()
}
func (q *Queue) Peek() int {
if q.stack2.IsEmpty() {
for !q.stack1.IsEmpty() {
q.stack2.Push(q.stack1.Pop())
}
}
return q.stack2.Peek()
}
在上面的代码中,我们定义了一个 Queue 结构体,其中包含两个指向 Stack 结构体的指针。Enqueue 方法将元素压入栈1中;Dequeue 方法从栈2中弹出元素,如果栈2为空,则将栈1中的元素全部压入栈2中;Peek 方法返回栈2中的栈顶元素,如果栈2为空,则将栈1中的元素全部压入栈2中。
对于队列操作的时间复杂度分析:
Enqueue操作的时间复杂度为 O(1),因为它只需要将元素压入栈1中。Dequeue操作的时间复杂度为 O(n),其中 n 是队列中的元素个数。这是因为在将栈1中的元素全部压入栈2中时,需要遍历栈1中的所有元素。但是在之后的操作中,每次从栈2中弹出元素的时间复杂度仍然为 O(1)。Peek操作的时间复杂度与Dequeue操作相同,也为 O(n)。
综上所述,虽然使用两个栈实现一个队列需要进行一些额外的操作,但是其时间复杂度与普通的队列相同。
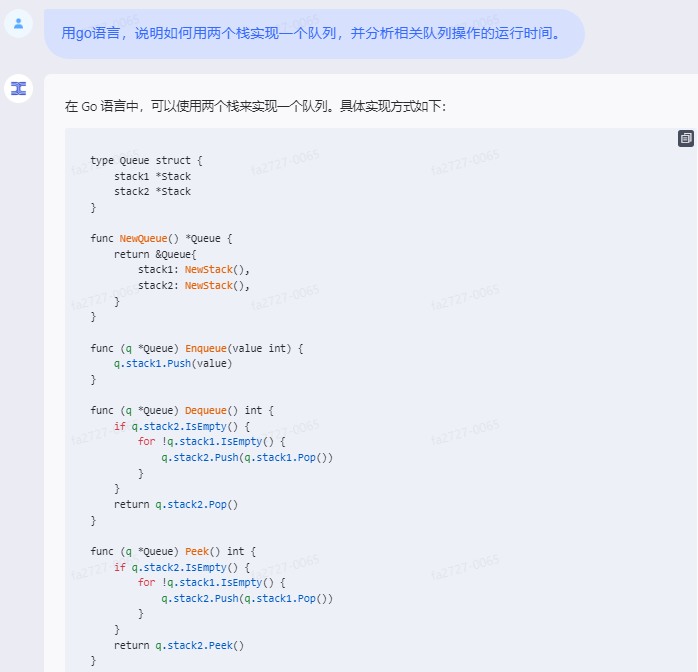

chatgpt:
在Go语言中,可以使用两个栈来实现一个队列。一个栈用于入队操作,称为pushStack,另一个栈用于出队操作,称为popStack。具体实现如下:
type MyQueue struct {
pushStack []int // 用于入队操作的栈
popStack []int // 用于出队操作的栈
}
/** Initialize your data structure here. */
func Constructor() MyQueue {
return MyQueue{}
}
/** Push element x to the back of queue. */
func (this *MyQueue) Push(x int) {
this.pushStack = append(this.pushStack, x)
}
/** Removes the element from in front of queue and returns that element. */
func (this *MyQueue) Pop() int {
this.moveElements()
value := this.popStack[len(this.popStack)-1]
this.popStack = this.popStack[:len(this.popStack)-1]
return value
}
/** Get the front element. */
func (this *MyQueue) Peek() int {
this.moveElements()
return this.popStack[len(this.popStack)-1]
}
/** Returns whether the queue is empty. */
func (this *MyQueue) Empty() bool {
return len(this.pushStack) == 0 && len(this.popStack) == 0
}
// Helper function to move elements from pushStack to popStack
func (this *MyQueue) moveElements() {
if len(this.popStack) == 0 {
for len(this.pushStack) > 0 {
n := len(this.pushStack) - 1
this.popStack = append(this.popStack, this.pushStack[n])
this.pushStack = this.pushStack[:n]
}
}
}
使用两个栈实现一个队列后,下面是相应的队列操作的运行时间分析:
入队操作:将元素放入pushStack栈中,时间复杂度为O(1)。
出队操作:如果popStack不为空,直接从popStack栈顶取出元素,时间复杂度为O(1);如果popStack为空,则需要将pushStack中的元素逐个移动到popStack中,最坏情况下需要将所有元素移动一次,平均时间复杂度为O(n),其中n是队列的大小。
获取队列头部元素操作:与出队操作类似,时间复杂度为O(1)。
判断队列是否为空操作:如果pushStack和popStack都为空,时间复杂度为O(1),否则时间复杂度为O(n),其中n是队列的大小。
综上所述,使用两个栈实现一个队列,入队和获取队列头部元素操作的时间复杂度为O(1),出队操作的平均时间复杂度为O(n),判断队列是否为空操作的时间复杂度为O(1)。

文心一言 VS 讯飞星火 VS chatgpt (108)-- 算法导论10.1 6题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- 【TVM模型编译】0.onnx模型优化流程.md
本文以及后续文章,着重于介绍tvm的完整编译流程. 后续文章将会按照以上流程,介绍tvm源码.其中涉及一些编程技巧.以及tvm概念,不在此部分进行进一步讲解,另有文章进行介绍. 首先介绍一下,从onn ...
- 免杀系列之利用blockdlls和ACG保护恶意进程
blockdlls Cobalt Strike 3.14版本以后添加了blockdlls功能,它将创建一个子进程并限定该子进程只能加载带有Microsoft签名的DLL. 这个功能可以阻止第三方安全软 ...
- PostgreSQL 12 文档: 部分 II. SQL 语言
部分 II. SQL 语言 这部份描述在PostgreSQL中SQL语言的使用.我们从描述SQL的一般语法开始,然后解释如何创建保存数据的结构.如何填充数据库以及如何查询它.中间的部分列出了在SQL命 ...
- 手写call&apply&bind
在这里对call,apply,bind函数进行简单的封装 封装主要思想:给对象一个临时函数来调用,调用完毕后删除该临时函数对应的属性 call函数封装 function pliCall(fn, obj ...
- 数据分析之jupyter notebook工具
一.jupyter notebook介绍 1.简介 Jupyter Notebook是基于网页的用于交互计算的应用程序.其可被应用于全过程计算:开发.文档编写.运行代码和展示结果.--Jupyter ...
- zabbix 使用监控项原型(自动发现规则)
以kafka为例,需要先对 topic-parttion 做发现,脚本如下 cat topic_parttion_discovery.py #!/usr/bin/env python import j ...
- tmux 移动窗格
pre + Ctrl+o:所有窗格向前移动一个位置,第一个窗格变成最后一个窗格 pre + Shift+[:当前窗格与上一个窗格交换位置 pre + Shift+]:当前窗格与下一个窗格交换位置
- 2021-3-9 excel导出
public void ExportExcel(DataTable dt) { //要添加epplus的nuget包 ExcelPackage.LicenseContext = LicenseCont ...
- git报错:SSL certificate problem: unable to get local issuer certificate
原因:在windows系统中git没有获取到ssl证书 解决方案 输入以下命令: git config --global http.sslBackend schannel 之后再执行操作就可以啦 另: ...
- AVR汇编(一):搭建交叉编译环境
AVR汇编(一):搭建交叉编译环境 几年间,陆陆续续接触了很多热门的单片机,如STC.STM8S.STM32.ESP32等.但一直都是抱着急功近利的心态去学习他们,基本上都是基于库函数和第三方组件进行 ...