UnixBench的简单测试与验证
UnixBench的简单测试与验证
目标
飞腾2000+ (物理机和虚拟机)
Intel Golden 6170 物理机
Intel Golden 5218 虚拟机 Gold 5218 CPU @ 2.30GHz
至强十年前的CPU E5-2620 物理机
E5-2630 v3 @ 2.40GHz 虚拟机
验证一下不同机器的最简单的性能数据.
过程
第一步 下载UnixBench
https://codeload.github.com/kdlucas/byte-unixbench/tar.gz/refs/tags/v5.1.3
下载完后 该改名, 放到不同的机器里面
tar -zxvf unixbench-5.1.3.tar.gz
cd byte-unixbench-5.1.3/UnixBench/
sed -i "s/GRAPHIC_TESTS = defined/#GRAPHIC_TESTS = defined/g" ./Makefile
make
执行命令为:
./Run
简单参数介绍
- StudyFrom: https://yuntue.com/post/29354.html
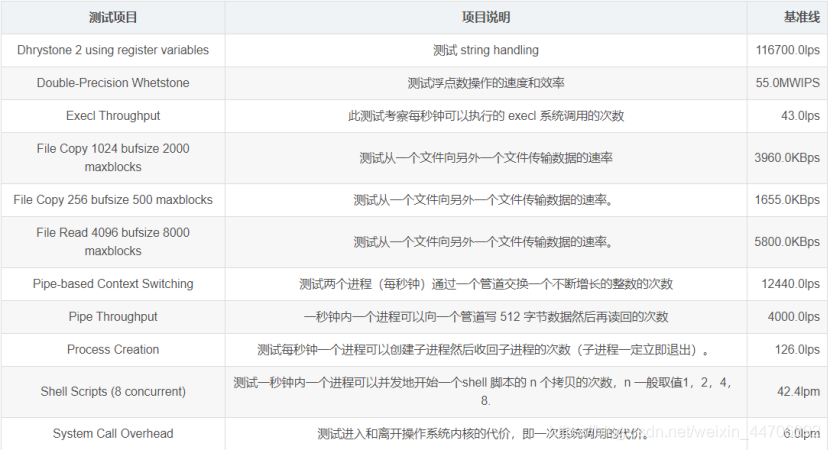
简单参数介绍文字版
Unixbench做了哪些性能测试
Dhrystone 2 using register variables
这里有比较详细的dhrystone介绍,这个主要是测整数性能,对应的浮点数测试是:Double-Precision Whetstone。
那绕开里面一坨计算,说下输出:默认就是在10秒内,那一坨计算能计算次数,算出分数后,参考前面篇UnixBench算分介绍,算出Index分数。
Double-Precision Whetstone
既然有整数运算的CPU性能,那么浮点数运算性能也希望有,于是就有了:whets.c
Execl Throughput
除了前面介绍的那两个比较复杂,UnixBench其他的运算都比较简单,Execl它的实际就是递归调用,它主要利用的是execl函数。
本身execl.c编译出来后的执行文件是execl的二进制文件,execl函数执行的时候记录参数:开始时间,执行次数,耗时(一般都是10秒)。
当本次总执行时间耗时超过10秒时,输出执行次数,然后根据算分规则算分,这个思想还是很巧妙的。
File Copy
这个主要是测试的write和read两个函数,测试30秒。实现很简单,先写入一个文件2秒(循环写入),再读2秒,
然后从刚刚写入的文件读取数据,写入到另一个文件,循环写入,在30秒的读写次数。
不同的参数测试测的是不同块大小,不同块数的性能,如果测试磁盘建议用FIO测试。
Pipe Throughput
打开一个管道,往管道写入512个bytes,再读出来,测试10秒,总共读写次数
Pipe-based Context Switching
打开两个管道,开启两个进程,其中一个进程往管道1写,往管道2读,另一个进程往管道2写,往管道2读,
一个进程完成一次读写,计数+1。其中一个很有意思的事情:如果这两个进程在同一个CPU和不同的CPU有完全不同的性能,
在同一个CPU下性能会好很多。这里有篇很细致的分析,值得大家评阅:Unixbench 测试套件缺陷深度分析
Process Creation
就是不停调用fork函数,创建进程,并立马退出,成功一次计数+1。
Shell Scripts
通过fork函数,创建进程,不停地执行一个脚本, 执行成功一次+1.
所谓Shell Scripts (1 concurrent) 一个并发是指传递给脚本:pgms/multi.sh 参数是1,
同样Shell Scripts (8 concurrent) ,传递给脚本的参数是8,同时8个子任务并发执行。
System Call Overhead
本意是想计算进入离开操作系统的开销,进入离开一次计数+1,
在10秒内的执行次数. 实际执行的效果是fork子进程,waitpid函数后退出,计数+1
部分机器的配置与结果
- Intel(R) Xeon(R) Gold 6150 CPU @ 2.70GHz * 18 *4 1T内存
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 45321616.5 3883.6
Double-Precision Whetstone 55.0 3994.4 726.3
Execl Throughput 43.0 990.5 230.3
File Copy 1024 bufsize 2000 maxblocks 3960.0 653004.6 1649.0
File Copy 256 bufsize 500 maxblocks 1655.0 170341.0 1029.3
File Copy 4096 bufsize 8000 maxblocks 5800.0 1991790.6 3434.1
Pipe Throughput 12440.0 812102.4 652.8
Pipe-based Context Switching 4000.0 129430.3 323.6
Process Creation 126.0 2688.8 213.4
Shell Scripts (1 concurrent) 42.4 2276.7 536.9
Shell Scripts (8 concurrent) 6.0 1225.2 2042.0
System Call Overhead 15000.0 656542.4 437.7
========
System Benchmarks Index Score 811.8
------------------------------------------------------------------------
Benchmark Run: 日 9月 25 2022 17:19:07 - 17:19:07
144 CPUs in system; running 144 parallel copies of tests
- Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz62 32G内存
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 26845867.5 2300.4
Double-Precision Whetstone 55.0 3161.6 574.8
Execl Throughput 43.0 1477.6 343.6
File Copy 1024 bufsize 2000 maxblocks 3960.0 253582.3 640.4
File Copy 256 bufsize 500 maxblocks 1655.0 67713.4 409.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 731087.8 1260.5
Pipe Throughput 12440.0 322218.7 259.0
Pipe-based Context Switching 4000.0 95001.7 237.5
Process Creation 126.0 5645.1 448.0
Shell Scripts (1 concurrent) 42.4 3719.6 877.3
Shell Scripts (8 concurrent) 6.0 1646.3 2743.9
System Call Overhead 15000.0 211672.9 141.1
========
System Benchmarks Index Score 578.5
------------------------------------------------------------------------
Benchmark Run: 日 9月 25 2022 17:25:56 - 17:25:56
24 CPUs in system; running 24 parallel copies of tests
- FT-2000+/64 2.0Ghz * 64core * 1 128G内存
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 22368348.8 1916.7
Double-Precision Whetstone 55.0 3631.2 660.2
Execl Throughput 43.0 2535.4 589.6
File Copy 1024 bufsize 2000 maxblocks 3960.0 403977.6 1020.1
File Copy 256 bufsize 500 maxblocks 1655.0 123146.9 744.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 1059038.5 1825.9
Pipe Throughput 12440.0 731953.9 588.4
Pipe-based Context Switching 4000.0 128939.1 322.3
Process Creation 126.0 5281.5 419.2
Shell Scripts (1 concurrent) 42.4 3729.0 879.5
Shell Scripts (8 concurrent) 6.0 1687.8 2813.0
System Call Overhead 15000.0 512275.3 341.5
========
System Benchmarks Index Score 800.7
------------------------------------------------------------------------
Benchmark Run: 日 9月 25 2022 17:27:32 - 17:27:32
64 CPUs in system; running 64 parallel copies of tests
- 虚拟机 Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz *8vCPU 16G内存
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 211612119.4 18133.0
Double-Precision Whetstone 55.0 35513.7 6457.0
Execl Throughput 43.0 7928.8 1843.9
File Copy 1024 bufsize 2000 maxblocks 3960.0 1008598.8 2547.0
File Copy 256 bufsize 500 maxblocks 1655.0 280047.4 1692.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 3083540.8 5316.4
Pipe Throughput 12440.0 6476970.5 5206.6
Pipe-based Context Switching 4000.0 1522650.6 3806.6
Process Creation 126.0 29679.7 2355.5
Shell Scripts (1 concurrent) 42.4 21083.6 4972.6
Shell Scripts (8 concurrent) 6.0 3255.8 5426.4
System Call Overhead 15000.0 4443744.9 2962.5
========
System Benchmarks Index Score 4032.0
只进行一个copy的性能为: Run -c 1
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 34026972.9 2915.8
Double-Precision Whetstone 55.0 4072.9 740.5
Execl Throughput 43.0 2797.2 650.5
File Copy 1024 bufsize 2000 maxblocks 3960.0 747208.9 1886.9
File Copy 256 bufsize 500 maxblocks 1655.0 208899.4 1262.2
File Copy 4096 bufsize 8000 maxblocks 5800.0 1819202.2 3136.6
Pipe Throughput 12440.0 1148215.4 923.0
Pipe-based Context Switching 4000.0 132960.3 332.4
Process Creation 126.0 7724.1 613.0
Shell Scripts (1 concurrent) 42.4 6659.2 1570.6
Shell Scripts (8 concurrent) 6.0 2005.4 3342.3
System Call Overhead 15000.0 2023562.5 1349.0
========
System Benchmarks Index Score 1245.8
- KVM虚拟机 FT-2000+/64 *12 32G内存
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 230828135.7 19779.6
Double-Precision Whetstone 55.0 43293.8 7871.6
Execl Throughput 43.0 12516.6 2910.8
File Copy 1024 bufsize 2000 maxblocks 3960.0 337653.1 852.7
File Copy 256 bufsize 500 maxblocks 1655.0 88730.2 536.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 1151598.8 1985.5
Pipe Throughput 12440.0 6932899.9 5573.1
Pipe-based Context Switching 4000.0 839878.7 2099.7
Process Creation 126.0 14315.2 1136.1
Shell Scripts (1 concurrent) 42.4 14834.8 3498.8
Shell Scripts (8 concurrent) 6.0 2267.5 3779.1
System Call Overhead 15000.0 1072451.9 715.0
========
System Benchmarks Index Score 2470.5
只进行一个copy的性能为:
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 22350448.1 1915.2
Double-Precision Whetstone 55.0 3610.6 656.5
Execl Throughput 43.0 2140.6 497.8
File Copy 1024 bufsize 2000 maxblocks 3960.0 361175.9 912.1
File Copy 256 bufsize 500 maxblocks 1655.0 107413.0 649.0
File Copy 4096 bufsize 8000 maxblocks 5800.0 998342.8 1721.3
Pipe Throughput 12440.0 689464.3 554.2
Pipe-based Context Switching 4000.0 45415.8 113.5
Process Creation 126.0 3255.5 258.4
Shell Scripts (1 concurrent) 42.4 3168.9 747.4
Shell Scripts (8 concurrent) 6.0 1299.4 2165.6
System Call Overhead 15000.0 472585.1 315.1
========
System Benchmarks Index Score 646.1
部分结论1
这次测试感觉非常反常识.. 我的服务器甚至不如部分云主机的结果好..
而且很奇怪的是 物理机器的测试结果都不如虚拟机..所以感觉很诡异.
猜测物理机的性能结果有损耗, 可能只能用来评估虚拟机的性能.
但是感觉自己的部分项目经验. 能够得出部分浅显的结论2
部分结论2
- 只是自己最近学到的和简单的总结. 不是很准确.
CPU的速度主频仅是其中一个变量.
不同指令集, 不同架构, 不同厂商的CPU完全不具备横向对比的基础.
引申出来比较重要的概念是IPC, instruction per cycle.
但是这个概念意义也不是很大, 通过整数和浮点计算出来的结果其实与现实生产差距巨大
但是可以这样理解. 跑分高了性能不一定好, 但是跑分低了性能一定很差.
SPEC2006和SPEC2017可以对CPU进行简单的度量, 但是结果具有一定的欺骗性
GCC和ICC不同编译器以及不通的编译优化会导致结果天差地别.
CPU的指令集对性能有影响,但是不是最大的变量.VIA的x86的CPU就不如安培的ARM架构的CPU
架构和制程非常重要. 架构会决定流水线深度和多发射的条数,以及uos的数量和编译器前后端的优化程度.
制程会决定CPU的体质, 能不能支撑大量的计算和生产的压力.
可以理解 架构就是技术 支撑就是体力. 想打好球 两者缺一不可. 并且是相辅相成的.
流水线深度和多发射的数量对性能影响很大.
并且指令预取.以及分支判断的算法对性能影响也很大. 分支判断对了. L1I就会更好发挥做用.
然后缓存对CPU的影响更体现在生产上. 科学计算可能可以不太考虑缓存. 但是生产服务器必须要考虑.
不管是L1 L2 L3 还是TLB 还是寄存器. 他的性能和容量决定了很大一部分CPU的性能也很考验CPU厂商的技术功底
在满足上面的情况下. CPU对中断和上下文切换的效率也会影响性能表现.
尤其是多线程情况时的处理.
CPU终归是要将数据从内存中取出,计算完再写入到内存的. 所以内存带宽和内存时延 就是除了CPU本身之外最大的性能参数
CPU的带宽很好理解. 一般就是比如DDR4-2933 然后乘以系统内的激活通道数再乘以(根据配置和插入的内存可能不乘) 2 进行计算.
现在来说带宽一把还可以喂饱CPU,但是时延是非常重要的. 他决定了计算的响应时间. 时延一方面跟内存体质有关系.
另一方面也跟CPU的总线结构, 以及Core之间的互连结构有关系.
其他像是PCI-E以及ACHI接口对性能的影响主要体现在数据库和文件系统落盘上面.
应用环境一般不会考虑这个. 但是数据库会考虑的更多,
其实不管是网络还是存储. 都可以理解为是IO.都需要关注带宽以及延时.
UnixBench的简单测试与验证的更多相关文章
- shiro 简单的身份验证 案例
Apache Shiro是Java的一个安全框架,Shiro可以帮助我们完成:认证.授权.加密.会话管理.与Web集成.缓存等. 简单的身份验证 项目目录: 首先,在shiro.ini里配置了用户名和 ...
- jQuery结合Ajax实现简单的前端验证和服务端查询
上篇文章写了简单的前端验证由传统的JavaScript转向流畅的jQuery滑动验证,现在拓展一下,使用Ajax实现用户体验比较好的异步查询,同样还是从建立一个简单的表单开始 <form nam ...
- struts2+hibernate+spring注解版框架搭建以及简单测试(方便脑补)
为了之后学习的日子里加深对框架的理解和使用,这里将搭建步奏简单写一下,目的主要是方便以后自己回来脑补: 1:File--->New--->Other--->Maven--->M ...
- ASP.NET Core 项目简单实现身份验证及鉴权
ASP.NET Core 身份验证及鉴权 目录 项目准备 身份验证 定义基本类型和接口 编写验证处理器 实现用户身份验证 权限鉴定 思路 编写过滤器类及相关接口 实现属性注入 实现用户权限鉴定 测试 ...
- [20190211]简单测试端口是否打开.txt
[20190211]简单测试端口是否打开.txt --//昨天看一个链接,提到如果判断一个端口是否打开可以简单执行如下:--//参考链接:https://dba010.com/2019/02/04/c ...
- MongoDB 副本集和C#交互,简单测试
MongoDB 副本集和C#交互,简单测试 primary节点宕机: 模拟primary节点宕机的情况,这时查看监控: 可以看到37018已经成了primary节点.主界面宕机导致了整个集群发生一次e ...
- 技术分享 | 简单测试MySQL 8.0.26 vs GreatSQL 8.0.25的MGR稳定性表现
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. M ...
- TODO:Golang UDP连接简单测试慎用Deadline
TODO:Golang UDP连接简单测试慎用Deadline UDP 是User Datagram Protocol的简称, 中文名是用户数据报协议,是OSI(Open System Interco ...
- jQuery validate 根据 asp.net MVC的验证提取简单快捷的验证方式(jquery.validate.unobtrusive.js)
最近在学习asp.netMVC,发现其中的验证方式书写方便快捷,应用简单,易学好懂. 验证方式基于jQuery的validate 验证方式,也可以说是对jQuery validate的验证方式的扩展, ...
- .net orm比较之dapper和Entity Framework6的简单测试比较
.net orm比较之dapper和Entity Framework6的简单测试比较
随机推荐
- xcode打包导出ipa
xcode打包导出ipa 众所周知,在开发苹果应用时需要使用签名(证书)才能进行打包安装苹果IPA,作为刚接触ios开发的同学,只是学习ios app开发内测,并没有上架appstore需求,对于苹果 ...
- PPT 动画入门
元素动画 进入动画 元素从无到有的过程 退出动画 元素从有到无的过程 退出动画和进入动画,一对一 强调动画 在元素上变化的过程(如放大) 动作路径 3D动画 三维动画 低版本不支持 组合动画 切换动画 ...
- MySQL 数据库中的数据类型
整数类型 标准 SQL 中支持 INTEGER 和 SMALLINT 这两种类型,MySQL 数据库除了支持这两种类型以外,还扩展支持了 TINYINT.MEDIUMINT 和 BIGINT 整数类型 ...
- 认证,权限,频率源码分析 自定义频率类 SimpleRateThrottle缓存频率类 基于APIView编写分页
目录 昨日回顾 三种位置的token获取 三种权限校验方式 原生django的cookie+session认证底层原理 断点调试使用 认证,权限,频率源码分析(了解) 权限源码分析 认证源码分析 频率 ...
- 阿里云视频云vPaaS低代码音视频工厂:极速智造,万象空间
当下音视频技术越来越广泛地应用于更多行各业中,但因开发成本高.难度系数大等问题,掣肘了很多企业业务的第二增长需求.阿里云视频云基于云原生.音视频.人工智能等先进技术,提供易接入.强拓展.高效部署和覆盖 ...
- 你不知道的vue3:使用runWithContext实现在非 setup 期间使用inject
前言 日常开发时有些特殊的场景需要在非 setup 期间调用inject函数,比如app中使用provide注入的配置信息需要在发送http请求时带上传给后端.对此我们希望不在每个发起请求的地方去修改 ...
- 探究Presto SQL引擎(2)-浅析Join
作者:vivo互联网技术-Shuai Guangying 在<探究Presto SQL引擎(1)-巧用Antlr>中,我们介绍了Antlr的基本用法以及如何使用Antlr4实现解析SQL查 ...
- 【驱动】以太网扫盲(二)phy寄存器简介
PHY 寄存器的地址空间为 5 位,从 0 到 31 最多可以定义 32 个寄存器(随着芯片功能不断增加,很多 PHY 芯片采用分页技术来扩展地址空间以定义更多的寄存器),IEEE802.3 定义了地 ...
- @Conditional注解使用及@ConditionalOnXXX各注解的作用
本文为博主原创,转载请注明 出处: 一.@Conditional注解作用: 必须是 @Conditional 注解指定的条件成立,才会在容器中添加组件,配置类里面的所有配置才会生效 二.@Condit ...
- 如何使用单纯的`WebAssembly`
一般来说在.net core使用WebAssembly 都是Blazor ,但是Blazor渲染界面,.net core也提供单纯的WebAssembly这篇博客我将讲解如何使用单纯的WebAssem ...