linux机制
cpu Cache 工作原理:文中对Cache的一致性提出了两种策略:基于监听的和基于目录的。前者是所有Cache均监听各个Cache的写操作,当一个Cache中的数据被写了,其处理方式有:写更新协议(某个Cache发生写了,就索性把所有Cache都给更新了)和写失效协议(某个Cache发生写了,就把其他Cache中的该数据块置为无效),该策略由于监听起来成本比较大,所以只应用于极简单的系统中;后者用于在主存处维护一张表,记录各数据块都被写到了哪些Cache, 从而更新相应的状态,一般采用该策略,有如下处理方式:
- SI: 对于一个数据块来讲,有share和invalid两种状态。如果是share状态,直接通知其他Cache, 将对应的块置为无效。
- MSI:对于一个数据块来讲,有share和invalid,modified三种状态。其中modified状态表表示该数据只属于这个Cache, 被修改过了。当这个数据被逐出Cache时更新主存。这么做的好处是避免了大量的主从写入。同时,如果是invalid时写该数据,就要保证其他所有Cache里该数据的标志位不为M,负责要先写回主存储。
- MESI:对于一个数据来讲,有4个状态。modified, invalid, shared, exclusive。其中exclusive状态用于标识该数据与其他Cache不依赖。要写的时候直接将该Cache状态改成M即可。
linux的close-on-exec:在fork子进程后,子进程会继承父进程的文件描述符,即增加了文件的"打开文件计数"(参见这里),当使用exec执行新的程序时,会使用新程序会替换子进程的正文,数据,堆和栈等,此时保存文件描述符的变量当然也不存在了,也就无法关闭子进程中的文件,导致文件描述符泄露。可以使用close-on-exec,在执行exec时关闭本进程中打开的文件描述符。参考例子。这里的文件包括系统文件描述符(open函数使用O_CLOEXEC)和socket文件描述符(socket函数使用SOCK_CLOEXEC)。
socket操作函数read/write和recv/send用法基本相同,后者比前者多了一个flag参数。详见套接字I/O函数。如果是阻塞socket,执行读操作时,如果socket接收缓存区没有数据会阻塞等待数据;执行写操作时,如果socket发送缓存区没有足够的空间存放此次写入的数据,则会阻塞等待缓存区释放。读/写数据到缓存区成功后会立即返回,但写入socket缓存区并不代表数据会成功发送到对端,例如接收到TCP RST报文会导致TCP断链并清空缓存区数据。如果是非阻塞socket,在执行读操作时,如果socket接收缓存区没有数据,则直接返回EWOULDBLOCK错误;在执行写操作时,如果socket发送缓冲区中有足够空间或者是不足以拷贝所有待发送数据的空间的话,则拷贝前面N个能够容纳的数据,返回实际拷贝的字节数,socket发送缓存区没有空间时会返回EWOULDBLOCK错误。可以使用fcntl函数为文件描述符设置O_NONBLOCK标记来实现非阻塞socket。
阻塞/非阻塞socket是相对一条连接来说的。使用非阻塞可以防止读写线程阻塞,一般用于服务端。golang的read/write是阻塞的,但底层是非阻塞的,可以使用多协程实现非阻塞。
参考:
IO复用主要是服务端通过select(),poll(),epoll()等方式,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪,就是这个文件描述符进行读写操作之前),能够通知程序进行相应的读写操作。但它们本质上还是同步IO。
参考:
零拷贝主要是减少用户空间到内核空间的拷贝次数。零拷贝通常使用mmap,sendfile,FileChannel,DMA等技术实现。使用sendfile时用户无法对文件进行修改,但使用mmap时可以修改文件。从Linux 2.4版本开始,操作系统底层提供了scatter/gather这种DMA的方式来从内核空间缓冲区中将数据直接读取到协议引擎中,而无需将内核空间缓冲区中的数据再拷贝一份到内核空间socket相关联的缓冲区中,此时只有外设缓存区满时写操作才会阻塞。
参考:
TCP
TCP的TIME_WAIT有两个作用:
- 防止前一个TCP连接的残留数据(在序列号恰好正确的情况下)进入后续的TCP连接中
- 防止TCP挥手过程发出去的最后一个ACK报文丢弃,此时需要重传该ACK报文
fase sharing:字节对齐的原理
Linux网络队列:IP栈的报文提交会直接到QDisc队列,QDisc可以使用一定的策略来管控流量
BQL通过自动调节到driver queue的数据长度,来防止driver queue中的数据过大造成Bufferbloat而产生延迟。TSO, GSO, UFO和GRO可能会导致驱动队列中数据的增加,因此为了提高吞吐量的延迟,可以关闭这些功能。
QDisc(Queuing Disciplines)位于IP栈和driver queue之间,实现了流量分类,优先级划分和速率管控等。可以使用
tc命令配置。QDisc有三个关键概念:QDiscs,classes和filter
QDisc用于流量队列。Linux实现了大量QDisc来满足各个QDisc对应的的报文队列和行为。该接口允许QDisc可以在没有IP栈和NIC驱动修改的前提下实现队列管理。默认情况下,每个网卡都会分配一个pfifo_fast类型的QDisc 。
第二个是与QDisc紧密相关的class。独立的QDisc 可能会实现class来处理其不同的流量。
Filters用于按照QDisc 或class来区分流量。

TCP rtt和rto
TCP拥塞避免算法,目前主流Linux的默认拥塞避免算法为cubic,可以使用ss -i命令查看。tcp有滑动窗口,拥塞窗口,滑动窗口为接收端可接收的数据大小,等于window_size*(2^tcp_window_scaling),可接收数据的缓存大小通过ACK报文通知对端;拥塞窗口可以通过ss -i的cwnd字段获得,发送端发送的数据不能超过cwnd和接收方通告窗口的大小。
滑动窗口本质上是描述接受方的TCP数据报缓冲区大小的数据,发送方根据这个数据来计算自己最多能发送多长的数据。如果发送方收到接受方的窗口大小为0的TCP数据报,那么发送方将停止发送数据,等到接受方发送窗口大小不为0的数据报的到来。
关于滑动窗口协议,还有三个术语,分别是: 窗口合拢:当窗口从左边向右边靠近的时候,这种现象发生在数据被发送和确认的时候。
窗口张开:当窗口的右边沿向右边移动的时候,这种现象发生在接受端处理了数据以后。
窗口收缩:当窗口的右边沿向左边移动的时候,这种现象不常发生。
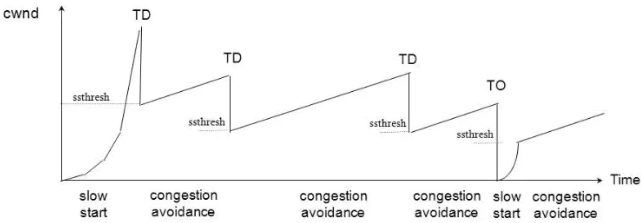
下面看下tahoe算法,reno算法(快速重传和快速恢复)和cubic算法的拥塞图,这三个算法在慢启动阶段相同,基于超时或重复确认来确认是否切换到拥塞避免阶段。不同点在拥塞避免阶段。tahos算法的描为(来自TCP-IP详解-卷1):
1) 对一个给定的连接,初始化cwnd为1个报文段, ssthresh为65535个字节。
2) TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。
3) 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)。
4) 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候才停止(因为我们记录了在步骤2中给我们制造麻烦的窗口大小的一半),然后转为执行拥塞避免。慢启动算法初始设置cwnd为1个报文段,此后每收到一个确认就加1。这会使窗口按指数方式增长:发送1个报文段,然后是2个,接着是4个⋯⋯。拥塞避免算法要求每次收到一个确认时将cwnd增加1 /cwnd。与慢启动的指数增加比起来,这是一种加性增长(additive increase)。我们希望在一个往返时间内最多为cwnd增加1个报文段(不管在这个RTT中收到了多少个ACK),然而慢启动将根据这个往返时间中所收到的确认的个数增加cwnd。
下图来自CSDN,可以看到tahoe算法在产生拥塞时会将cwnd设置为1,大大降低了传输效率
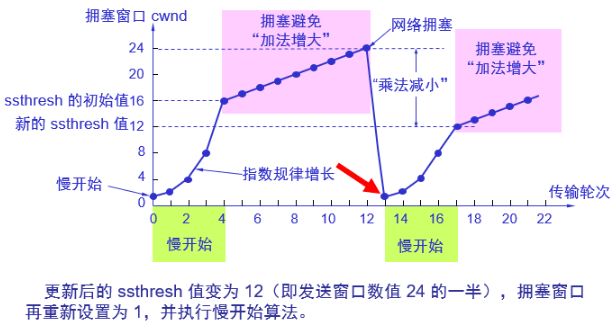
reno使用快速重传和快速恢复改进了tahoe算法:
快重传
快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时才进行捎带确认。
接收方收到了M1和M2后都分别发出了确认。现在假定接收方没有收到M3但接着收到了M4。显然,接收方不能确认M4,因为M4是收到的失序报文段。根据可靠传输原理,接收方可以什么都不做,也可以在适当时机发送一次对M2的确认。但按照快重传算法的规定,接收方应及时发送对M2的重复确认,这样做可以让发送方及早知道报文段M3没有到达接收方。发送方接着发送了M5和M6。接收方收到这两个报文后,也还要再次发出对M2的重复确认。这样,发送方共收到了接收方的四个对M2的确认,其中后三个都是重复确认。快重传算法还规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段M3,而不必继续等待M3设置的重传计时器到期。由于发送方尽早重传未被确认的报文段,因此采用快重传后可以使整个网络吞吐量提高约20%。 快恢复
与快重传配合使用的还有快恢复算法,其过程有以下两个要点: 当发送方连续收到三个重复确认,就执行“乘法减小”算法,把慢开始门限ssthresh减半。这是为了预防网络发生拥塞。请注意:接下去不执行慢开始算法。
由于发送方现在认为网络很可能没有发生拥塞,因此与慢开始不同之处是现在不执行慢开始算法(即拥塞窗口cwnd现在不设置为1),而是把cwnd值设置为慢开始门限ssthresh减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
可以看到reno算法在发生拥塞避免时不会将cwnd变为1,这样提高了传输效率,快速重传和快速恢复机制也有利于更快探测到拥塞。
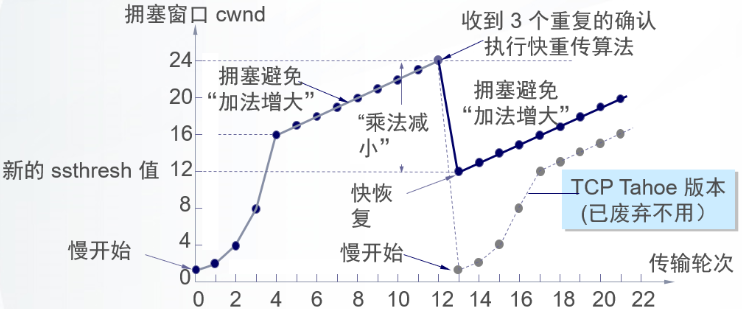
reno算法在拥塞避免阶段仍然是线性递增的,而cubic源于BIC算法,在拥塞避免阶段采用二分法查找最佳拥塞窗口,相比线性增加又增加了速率。下图来自该paper
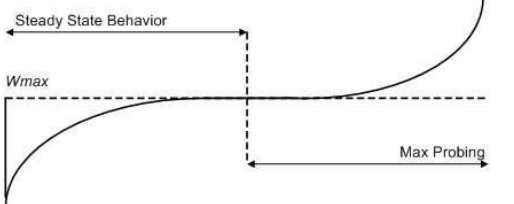
下面2张图,第一张为reno算法下的拥塞避免,第二张为cubic算法下的拥塞避免,可以看到cubic的拥塞窗口逼近速度更快
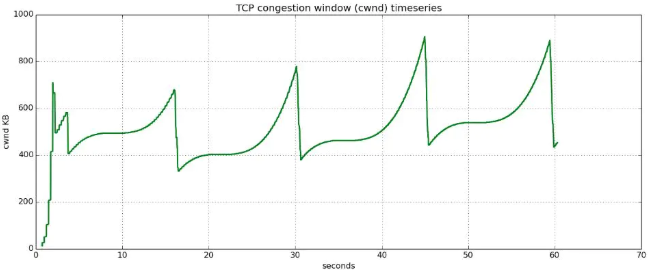
同主机进行TCP通信时,可能使用jumbo报文,导致MSS远大于一般的1460字节。为了方式这种情况下导致创建和传输大量符合MTU要求的报文,Linux实现了TSO,USO和GSO,参见下面描述
In order to avoid the overhead associated with a large number of packets on the transmit path, the Linux kernel implements several optimizations: TCP segmentation offload (TSO),
UDP fragmentation offload (UFO) and generic segmentation offload (GSO). All of these optimizations allow the IP stack to create packets which are larger than the MTU of the outgoing NIC.
For IPv4, packets as large as the IPv4 maximum of 65,536 bytes can be created and queued to the driver queue.
In the case of TSO and UFO, the NIC hardware takes responsibility for breaking the single large packet into packets small enough to be transmitted on the physical interface. For NICs without hardware support,
GSO performs the same operation in software immediately before queueing to the driver queue.
Linux 命名空间:
- mount命名空间:通过隔离
/proc/[pid]/mounts,/proc/[pid]/mountinfo和/proc/[pid]/mountstats文件,使得通过mount命令仅能查看到容器的挂载信息 - Pid命名空间:通过挂载一个/proc命令使得在容器中使用ps -ef命令可以查看仅容器内部的进程
- cgroup命名空间:容器所在的cgroup可以通过容器的进程查看
/proc/$pid/cgroup,进而知道其对应的cgroup所在目录 - network命名空间:如果两个进程属于不同的命名空间,则它们的
/proc/pid/net的信息不同;如果两个进程属于相同的命名空间,则它们的/proc/pid/net的信息相同。除/proc/$pid/net目录外,网络命名空间还隔离了/sys/class/net,/proc/sys/net,socket等。
- mount命名空间:通过隔离
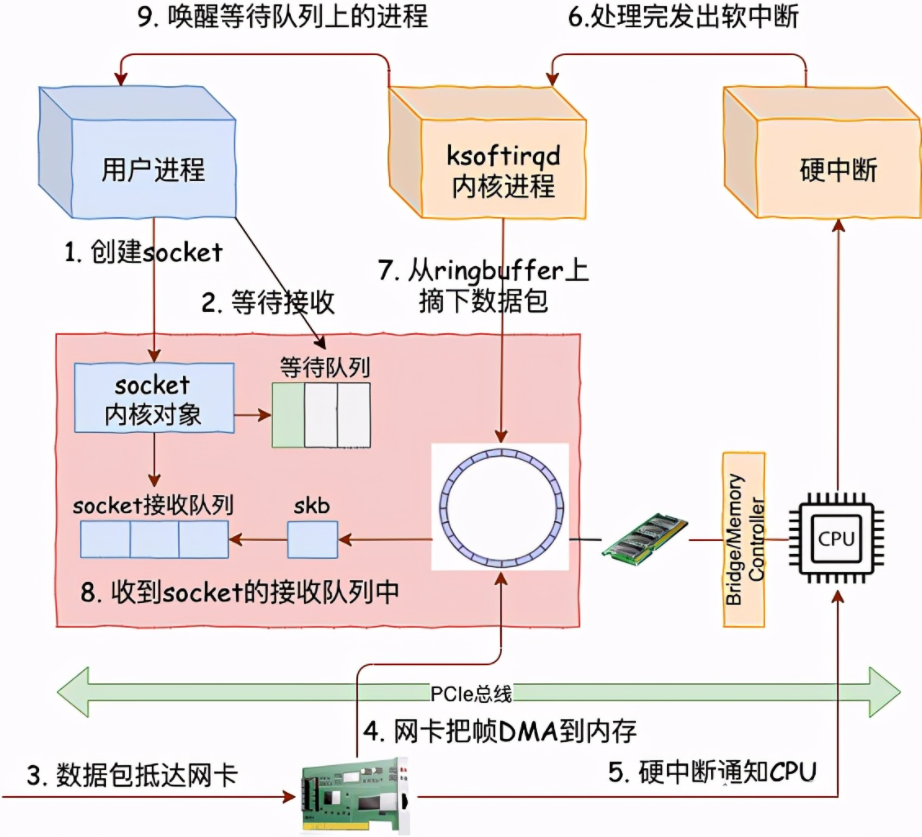
linux收包过程图如下:
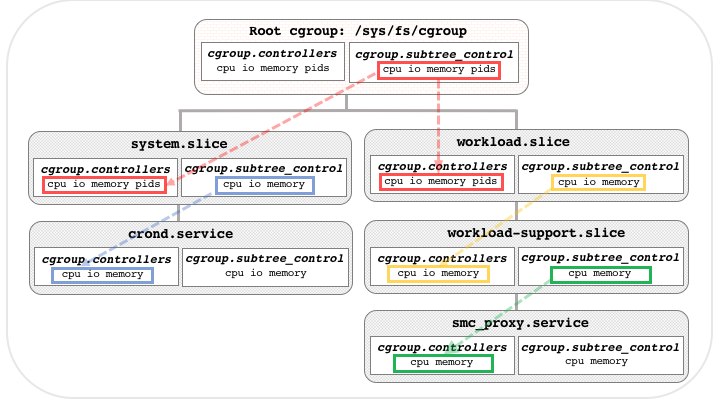
cgroup:相比cgroup1,cgroup2将所有的controllers放到了同一个目录中,称为unified hierarchy,通过cgroup.subtree_control参数来控制子cgroup中的controllers。
# Cgroup v1 挂载方式
> mount -t tmpfs /sys/fs/cgroup
> mkdir /sys/fs/cgroup/{pids,memory}
> mount -t cgroup -o pids cgroup /sys/fs/cgroup/pids
> mount -t cgroup -o memory cgroup /sys/fs/cgroup/memory
# Rest of the mount for all controllers # Cgroup v2 挂载方式
> mount -t cgroup2 cgroup2 /sys/fs/cgroup
cgroup2的控制器的层级关系由如下两个参数控制:
cgroup.controllers:列出了当前的cgroup中的controllers。在root cgroup中,列出了系统中允许的所有controllers,子cgroup中的controllers为父cgroup.subtree_control文件中的内容。
cgroup.subtree_control:列出cgroup的子树中允许的controllers。可以使用如下方式添加删除控制器
echo "+memory" > /sys/fs/cgroup2/cgroup.subtree_control
echo "-memory" > /sys/fs/cgroup2/cgroup.subtree_control
其关系图如下:
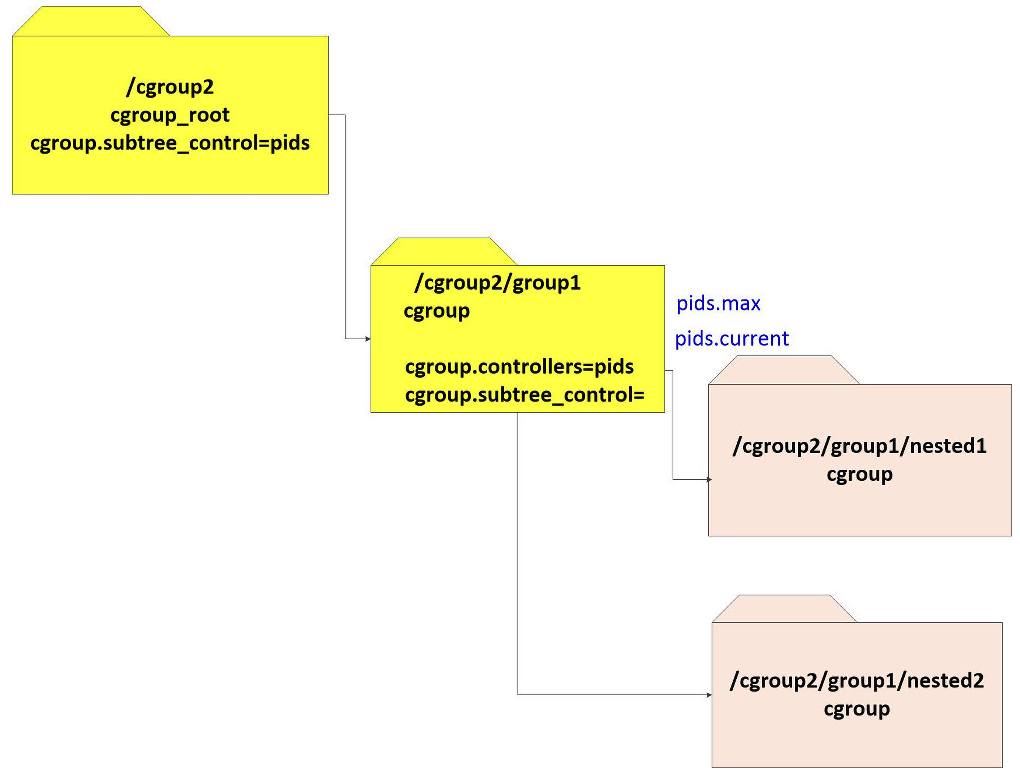
cgroup2中创建子cgroup的方式比较简单,只需要在当前cgroup中创建目录即可,新的cgroup会继承父cgroup的cgroup.subtree_control文件中定义的controllers。在cgroup.subtree_control中添加新的controller之后,会在子cgroup中创建对应的controller文件,例如在cgroup.subtree_control中添加
pids之后,就会在子cgroup中创建对应的controller文件:pids.current,pids.events,pids.max。mount -t cgroup2 nodev /cgroup2
mkdir /cgroup2/group1
mkdir /cgroup2/group1/nested1
mkdir /cgroup2/group1/nested2
echo +pids > /cgroup2/cgroup.subtree_control
cgroup.procs中包含了cgroup管理的PID,新创建的cgroup中,该文件是空的。当一个cgroup没有子cgroup且cgroup.procs中没有活动的进程时,可以使用如下命令移除该cgroup。当cgroup.procs中存在活动的进程时,可以先将该进程转移到其他cgroup,再使用命令删除当前cgroup。# rmdir $CGROUP_NAME
可以使用cgroup-tools来管理cgroup,使用
apt install cgroup-tools安装。使用如下命令创建一个类型为
memory,名为memhog-limiter的cgroup,如果不指定路径,则cgroup2下新创建的cgroup默认位于/sys/fs/cgroup/memhog-limiter,如果指定cgcreate -g memory:/test/memhog-limiter,则新创建的cgroup位于/sys/fs/cgroup/test/memhog-limitercgcreate -g memory:memhog-limiter
使用如下命令设置cgroup的参数:
cgset -r memory.max=50M memhog-limiter
使用如下命令指定在哪个cgroup中执行命令:
cgexec -g memory:memhog-limiter ./memhogtest.sh
memory
- memory.current:展示了当前cgroup中使用的内存
- memory.high:用于控制cgroup的内存使用,当cgroup使用的内存超过该阈值之后,cgroup中的进程会被抑制,并面临着内存回收的压力,默认是max,即没有限制
- memory.max:内存的硬限制,当cgroup的内存使用达到该阈值后,会触发OOM,默认是max。
- memory.low:当cgroup使用的内存小于该值时,尽量保证cgroup中的内存不会被回收
- memory.min:指定了给cgroup预留的最小内存,这部分内存不会被系统回收。
参考:
linux机制的更多相关文章
- Linux系统真正的优势以及学习方法
作为一名Linux爱好者,在Linux的世界中也算是半个老司机了,从桌面玩到服务器.从ubuntu到centos.从计算机到路由器,各种Linux的花俏玩法都略有体验.作者并非职业Linux选手,我仅 ...
- Linux内核分析:页回收导致的cpu load瞬间飙高的问题分析与思考--------------蘑菇街技术博客
http://mogu.io/156-156 摘要 本文一是为了讨论在Linux系统出现问题时我们能够借助哪些工具去协助分析,二是讨论出现问题时大致的可能点以及思路,三是希望能给应用层开发团队介绍一些 ...
- Linux 驱动开发
linux驱动开发总结(一) 基础性总结 1, linux驱动一般分为3大类: * 字符设备 * 块设备 * 网络设备 2, 开发环境构建: * 交叉工具链构建 * NFS和tftp服务器安装 3, ...
- cached过高导致内存溢出 java head space
最近公司线上遇到老是内存溢出检查后发现cached过高 命令:free -m 命令:sync //将缓存写入硬盘 cat /etc/redhat-release 这个是查看系统版本的命令c ...
- Android开发指南-框架主题-安全和许可
概述:Android操作系统是一个安全便捷的Linux系统,遵循Linux系统机制,允许多进程.为了进程间的数据共享和交互共用,设计"权限"这个名词,声明权限代表可使用此权限,未声 ...
- ZooKeeper的学习与应用
近期大概学习了一下ZooKeeper,本身并没有深入.LGG尝试着在虚拟机里面搭了平台,看了看一些教材,从网上到处看别人的博文并引用之,还请各位大牛们谅解我的剽窃.现总结例如以下. 1. ZooKee ...
- [转]ZooKeeper的学习与应用
[转]ZooKeeper的学习与应用 http://blog.csdn.net/rengq126/article/details/7393227 1. ZooKeeper的学习与应用 1.1. 概述 ...
- CM记录-CDH大数据平台实施经验总结2016(转载)
CDH大数据平台实施经验总结2016(转载) 2016年负责实施了一个生产环境的大数据平台,用的CDH平台+docker容器的方式,过了快半年了,现在把总结发出来. 1. 平台规划注意事项 1.1 业 ...
- 如何提高docker容器的安全性
一. 概述 Docker 容器一直是开发人员工具箱的重要组成部分,使开发人员能够以标准化的方式构建.分发和部署他们的应用程序.毫无疑问,这种吸引力的增加伴随着容器化技术的相关安全问题.他们可以很容易地 ...
- 在 Linux 中安装 Oracle JDK 8 以及 JVM 的类加载机制
参考资料 该文中的内容来源于 Oracle 的官方文档 Java SE Tools Reference .Oracle 在 Java 方面的文档是非常完善的.对 Java 8 感兴趣的朋友,可以直接找 ...
随机推荐
- THOR:MindSpore 自研高阶优化器源码分析和实践应用
摘要:这篇文章跟大家分享下THOR的实践应用.THOR算法的部分内容当前已经在MindSpore中开源 本文分享自华为云社区<MindSpore 自研高阶优化器源码分析和实践应用>,原文作 ...
- 在低代码开发平台 ILLA Cloud 中使用 Hugging Face 上的模型
ILLA Cloud 是一个面向开发者的开源低代码开发平台,平台专注于帮助开发者快速建立企业内部应用,为开发者节约数据调用与页面设计的时间.平台具有面向开发者.数据整合.协同开发.灵活部署等功能与特点 ...
- AtCoder ABC 164 (D~E)
比赛链接:Here ABC水题, D - Multiple of 2019 (DP + 分析) 题意: 给定数字串S,计算有多少个子串 \(S[L,R]\) ,满足 \(S[L,R]\) 是 \(2 ...
- 0x69 图论-二分图的覆盖与独立集
A:Machine Schedule 输入 5 5 10 0 1 1 1 1 2 2 1 3 3 1 4 4 2 1 5 2 2 6 2 3 7 2 4 8 3 3 9 4 3 0 输出 3 在二分图 ...
- Codeforce:Good Bye 2020 个人题解
题面链接:Here 代码提交:Here 年终彩蛋 1466A. Bovine Dilemma 题意是:给定一个固定点(0,1),然后给定n个在x轴的点,求面积不同的三角形个数 简单思考一下就容易发现这 ...
- Hbase结构和原理
Hbase是什么? HBase是一种构建在Hadoop HDFS之上的分布式.面向列的存储系统.在需要实时读写.随机访问超大规模数据集时,可以使用HBase. HBase依赖Zookeeper,默认 ...
- 写SAE评测,获 Airpods 2大奖【集结令】!
Serverless 应用引擎 SAE 开启测评有奖!名额有限,先到先得! Serverless应用引擎SAE是一款极简易用.自适应弹性的容器化应用平台.现面向所有用户发出诚挚邀请,参与一分钟部署在线 ...
- windows不安装虚拟机如何使用Linux系统作为开发工具?
哈喽,大家好,我是仲一.作为嵌入式开发程序员,常常需要在Linux环境下编译一些代码.安装虚拟机比较方便,但是,太占用内存了.性能不好的电脑开了一台虚拟机后,可能就干不了其他事情了.安装双系统也比较麻 ...
- threejs第一个案例
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5 < ...
- vue路由模块化
https://www.bilibili.com/video/BV1Tg411u7oy?from=search&seid=5098139115981575542&spm_id_from ...