LLM并行训练7-混合并行总结
概述
根据前面的系列文章, 对预训练大模型里用到的主要并行加速技术做了一系列拆分分析. 但是在实际的训练里往往是多种并行混合训练. 我们要怎么配置这些并行策略才能让训练框架尽可能的减少通信瓶颈, 提升GPU计算利用率呢? 这里的变量太多了, 以最简单的3D并行为例:
- 硬件层面有: 单台机器的卡数/卡间带宽/网卡带宽, 机器间通信时的网络拓扑构建.
- 并行策略上有: 张量并行数/流水线并行数/数据并行数
- 训练超参有: batch_size / AttnHeads / seq_len / hidden_size
如果靠脑补来调整这些参数, 会存在一个非常巨大的搜索空间, 很难找到最优于计算效率的方法, 所以需要先通过理论分析确定各个参数的大致范围. 最后再通过有限次尝试找到较优的方案. 本章参考nvidia的调参实践GTC演讲, 对GPT-3训练尝试进行理论调参分析.
并行方法适用场景分析
后文的标记备注:
- \((p, t, d)\) : 3D 并行维度. \(p\) 代表流水并行数, \(t\) 代表张量并行数, \(d\) 代表数据并行数
- \(n\): 总共的 GPU 数量. 要求 \(p\cdot t \cdot d = n\).
- \(B\): Global batch size.
- \(b\): Microbatch size.
- \(b^{'}\): 一个流水线要处理的 batch size 大小, 等于 \(B/d\).
- \(m = \frac{1}{b} \cdot \frac{B}{d}\): 一个 batch 在每个 pipeline 的 microbatch 的数量.
- \(s\): seq_len.
- \(h\): hidden_size = emb_size * attention_head_size
- \(a\): attention_head_size
张量并行(TP)
TP开销
| 模式 | Normal | ColParallel | ratio |
|---|---|---|---|
| flops | (n次乘法 + n次加法)* n^2 = 2n^3 | 2n^3/t | 1/t |
| Bandwidth | (n^2)【n*n 矩阵的读或写】 * 2(fp16)) * 3(读 X、读A,写 Y) = 6n^2 | 2n^2 + 4n^2/t(A,Y切分) | (1+2/t)/3 |
| Intensity(flops/bandwidth) | n/3 | n/(2+p) | 3/(2+t) |
当并行度\(t\)增长的时候, 可以看到intensity也处于一个增长的趋势. 需要权衡通信和计算成本的平衡, 由于TP需要在结束时进行一次激活的AllReduce, 在多机通信上会导致较高的通信成本. 所以TP一般只考虑在单机卡间通信时使用. TP在LLM里主要有两个使用场景:
- MLP先列再行, 这块前后一般会和SP结合进行将AllReduce拆分为allGather和reduceScatter

- attention处多头切分并行 每个头之间的计算各自独立, 所以可以进行切分计算.

流水线并行(PP)
流水线主要是将一个batch的数据切分为多个mirco-batch, 在micro-batch之间做异步并行. 因为通信内容只包含切分stage的输出, 而且是点对点通信, 不需要多点集合通信. 通信数据量小, 因此比较适合在多台机器间通信的场景. LLM里一般把一个transformLayer作为一个stage, 在多个stage之间构建pipeline, 如下图:

混合并行
当网络结构确定后, 一般TP和PP就能估算到比较合理的区间, 最后根据显存容量的计算来估计DP需设置的值.

TP与PP的策略分析
数据并行度\(d=1\)时, \(p * t = n\), 会有以下计算公式:
流水线bubble_time: \(\frac{(p-1)}{m}=\frac{n/t-1}{m}\), 提高TP并行度时会减少气泡占比, 但会增大单机内部的通信量, tp内部一个microbatch需要4个allReduce(fp/bp各两个)
单机单次allReduce通信量: \(2bsh(\frac{t-1}{t})\), (layer激活为\(bsh\), allReduce通信量为数据量2倍)
流水线并行时单个micro-batch机器间通信量为: \(C_{inter} = 2bsh\) (fp/bp各一次)
设一个pipeline内有\(l^{stage}\)个transformLayer, 则在1F1B非交错调度的情况下单个stage单机内部通信量为:
\]
所以机器间和机器内的通信量关系为:
\]
因为机器间通信速率远小(IB 200GB/s)于卡间通信(NVLink 600GB/s), 所以我们如果希望优化吞吐, 那么应该尽量降低机器间通信比率.
[!TIP]
也就是在不会导致TP产生机器间通信的前提下让t尽可能的大. 如果这样还放不下模型,再使用流水线并行来切分模型。

micro-batch设置
在固定其他参数的前提下. 只调整micro_batch数, 单个batch的执行时间: \((\frac{b^{'}}{b}+(p-1))\cdot(t_{f} + t_{b})\) , 如果增大b, 单个pipeline内数量减少但执行时间会变长, 计算耗时和b是非线性的关系. 而且调整micro-batch后, 通信耗时也会变化, 所以mirco-batch调整需要实验尝试才能找到最优解. megatron在论文中尝试gpt训练的mirco-batch设置4比较合适

DP的策略分析
便于分析设\(t=1, d * p = n\), 在这种情况下的流水线bubble占比为 \(\frac{p-1}{m} = \frac{n/d - 1}{B/b/d} = \frac{b(n - d)}{B}\)
PP和DP关系: 对于d单调递减, 也从下图可以看到, 当流水线并行的数量越小, 数据并行度越大的时候训练速度越快. 所以我们可以在PP满足显存占用的情况下尽可能的提升DP并行度.
和Batch_size关系: bubble和B成反比, B越大吞吐越高. 但是过大的B和数据并行度会导致模型不收敛. 需要在不影响效果的前提下调整B

DP和TP关系: 在TP内每个batch 需要进行4次allReduce, 而DP只需要对梯度做一次allReduce, 另外在TP的时候如果W比较小也会影响矩阵乘法计算效率. 下图可以看到TP并行度越小, DP并行度越大吞吐越高. 调整策略是只要TP满足显存需求, 就尽可能的增大DP来提升吞吐.

[!TIP]
如果模型比较大,需要先组合模型并行和流水并行,\(M=t \cdot p\) 的组合用来满足模型和模型相关的数据的显存需求,但是要让 M 尽量小。之后使用数据并行来扩展训练规模(扩大数据并行度、扩大 Global batch size)
GPT-3例子分析
以如下的超参GPT-3训练为例:

显存分析
ModelMemory
单卡存储模型参数主要包含4个部分(由于流水线并行, 单卡一般只存储1-2个transformLayer): attention参数 / FC参数 / token_emb / Positional encoding

以\(N_p\)代表一份全量参数, 则单卡上包含的参数量如下:
+ \frac{v}{t} *h(token) + s*\frac{h}{t}(positional) \approx 1.73B\approx \frac{175B}{p*t} (单卡上单份DP参数量)
\]
在混合精度训练中, 总共的数据量包扩1份fp16的w和grad, 1份fp32的optimizer_state(\(w+grad+momentum+variance\))
\]
Activation
在nvidia分享里, 看着activation只存了过token前的emb激活和进fc前的激活, 剩下的全部都是bp时重计算的..因为也没使用SP, 这里每张卡的激活都存了TP并行数的冗余数据
\]
\]
Extra
包含在fp时所需分配的临时显存 & 通信需要的临时显存 & allocator导致的显存碎片
这块在上一章-激活优化里其实已经分析过, 这里忽略不表
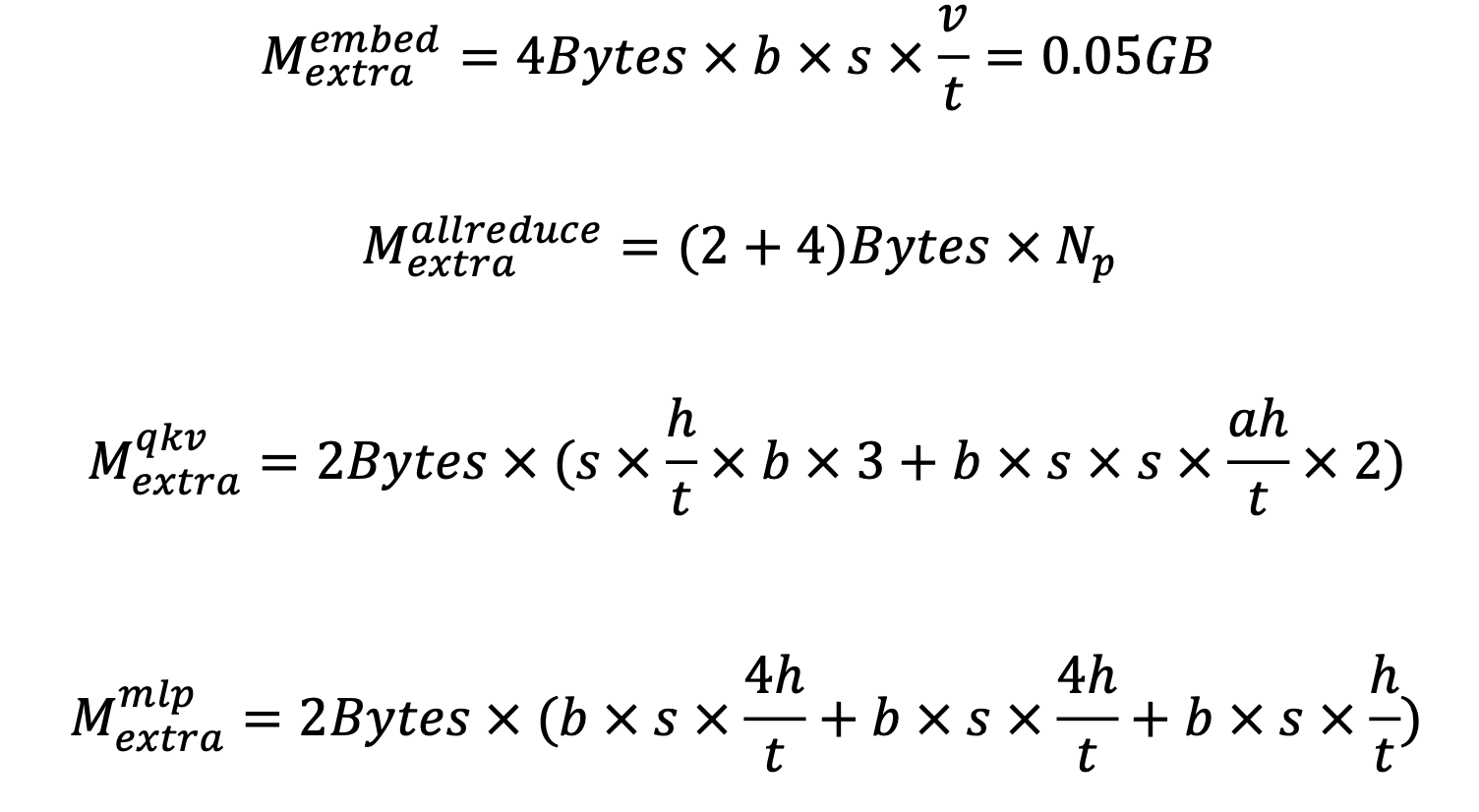
显存使用可能出现峰值的地方有三个地方: 1. fp完成时, 这里主要变化量是存在大量的extra. 2. bp完成时, 这里因为把大量的act释放后重计算,相对消耗不多. 3.更新optimizer_state时, 这是由于很多临时显存用于梯度allReduce, 所以出现显存峰值.

通信分析
BW: bus bandwidth(单次通信的数据长度)
TP: 每个mlp和attention 在fp /bp / bp时的fp重计算 三个阶段各需要一次allReduce
\]
DP: 在optimizer更新时需要对各个数据副本进行一次allReduce
\]
PP(1F1B交错式): 在机器间通信的点对点方式和在机器内通信的allGather(TODO: 这里没太看懂)
\]
从实际实验上也能看到TP占了主要的通信成本.

总结
3d并行的调优经验:
- 如果模型比较大,需要先组合模型并行和流水并行,\(M=t \cdot p\) 的组合用来满足模型和模型相关的数据的显存需求,但是要让 M 尽量小。之后使用数据并行来扩展训练规模(扩大数据并行度、扩大 Global batch size)
- 在不会导致TP产生机器间通信的前提下让t尽可能的大. 如果这样还放不下模型,再使用流水线并行来切分模型。
megatron-LM复杂度分析论文: https://arxiv.org/pdf/2104.04473
nvidia GTC演讲: https://developer.nvidia.com/gtc/2020/video/s21496
[nvidia GTC GPT-3调参分析](链接: https://pan.baidu.com/s/190TFeOI9SALaaH9CVMWH7Q?pwd=chux 提取码: chux)
megatron代码解读博客: https://www.cnblogs.com/rossiXYZ/p/15876714.html
LLM并行训练7-混合并行总结的更多相关文章
- ML2021 | (腾讯)PatrickStar:通过基于块的内存管理实现预训练模型的并行训练
前言 目前比较常见的并行训练是数据并行,这是基于模型能够在一个GPU上存储的前提,而当这个前提无法满足时,则需要将模型放在多个GPU上.现有的一些模型并行方案仍存在许多问题,本文提出了一种名为 ...
- PyTorch如何加速数据并行训练?分布式秘籍大揭秘
PyTorch 在学术圈里已经成为最为流行的深度学习框架,如何在使用 PyTorch 时实现高效的并行化? 在芯片性能提升有限的今天,分布式训练成为了应对超大规模数据集和模型的主要方法.本文将向你介绍 ...
- Pytorch:单卡多进程并行训练
1 导引 我们在博客<Python:多进程并行编程与进程池>中介绍了如何使用Python的multiprocessing模块进行并行编程.不过在深度学习的项目中,我们进行单机多进程编程时一 ...
- [Pytorch框架] 4.5 多GPU并行训练
文章目录 4.5 多GPU并行训练 4.5.1 torch.nn.DataParalle 4.5.2 torch.distributed 4.5.3 torch.utils.checkpoint im ...
- tensorflow 13:多gpu 并行训练
多卡训练模式: 进行深度学习模型训练的时候,一般使用GPU来进行加速,当训练样本只有百万级别的时候,单卡GPU通常就能满足我们的需求,但是当训练样本量达到上千万,上亿级别之后,单卡训练耗时很长,这个时 ...
- C#并行编程--命令式数据并行(Parallel.Invoke)---与匿名函数一起理解(转载整理)
命令式数据并行 Visual C# 2010和.NETFramework4.0提供了很多令人激动的新特性,这些特性是为应对多核处理器和多处理器的复杂性设计的.然而,因为他们包括了完整的新的特性,开 ...
- C#并行编程--命令式数据并行(Parallel.Invoke)
命令式数据并行 Visual C# 2010和.NETFramework4.0提供了很多令人激动的新特性,这些特性是为应对多核处理器和多处理器的复杂性设计的.然而,因为他们包括了完整的新的特性,开 ...
- C#并行编程之数据并行
所谓的数据并行的条件是: 1.拥有大量的数据. 2.对数据的逻辑操作都是一致的. 3.数据之间没有顺序依赖. 运行并行编程可以充分的利用现在多核计算机的优势.记录代码如下: public class ...
- 五 浅谈CPU 并行编程和 GPU 并行编程的区别
前言 CPU 的并行编程技术,也是高性能计算中的热点,也是今后要努力学习的方向.那么它和 GPU 并行编程有何区别呢? 本文将做出详细的对比,分析各自的特点,为将来深入学习 CPU 并行编程技术打下铺 ...
- 第五篇:浅谈CPU 并行编程和 GPU 并行编程的区别
前言 CPU 的并行编程技术,也是高性能计算中的热点,也是今后要努力学习的方向.那么它和 GPU 并行编程有何区别呢? 本文将做出详细的对比,分析各自的特点,为将来深入学习 CPU 并行编程技术打下铺 ...
随机推荐
- Flask学习记录:在w3cschool资料的基础上的个人摘录、实践与总结
学习与转载自w3cschool,在w3cschool资料的基础上的个人摘录.实践与总结,如有错误望留言. 一.Flask 概述 2021-08-25 14:01 更新 1.1 什么是Web Frame ...
- Ceph对象网关,多区域网关
目录 Ceph对象网关,多区域网关 1. 文件系统与对象存储的区别 1.1 对象存储使用场景 1.2 对象存储的接口标准 1.3 桶(bucket) 2. rgw 2.1 对象存储认证 2.2 对象网 ...
- 阿里bxet逆向
声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 目标网站 x82y 分析过 ...
- 机器学习算法(一):1. numpy从零实现线性回归
系列文章目录 机器学习算法(一):1. numpy从零实现线性回归 机器学习算法(一):2. 线性回归之多项式回归(特征选取) @ 目录 系列文章目录 前言 一.理论介绍 二.代码实现 1.导入库 2 ...
- 关于 Linux 中模拟鼠标
问题的背景是我想用自动化脚本来玩 Stardew Valley 的小游戏,刷钱,但是遇到了一系列问题,这里记录我的一些历程. pyautogui/pydirectinput pyautogui 是我第 ...
- Easysearch:语义搜索、知识图和向量数据库概述
什么是语义搜索? 语义搜索是一种使用自然语言处理算法来理解单词和短语的含义和上下文以提供更准确的搜索结果的搜索技术.旨在更好地理解用户的意图和查询内容,而不仅仅是根据关键词匹配,还通过分析查询的语义和 ...
- Scrapy框架(四)--五大核心组件
scrapy的基本使用我们已经掌握,但是各位心中一定会有些许的疑问,我们在编写scrapy工程的时候,我们只是在定义相关类中的属性或者方法, 但是我们并没有手动的对类进行实例化或者手动调用过相关的方法 ...
- Spring源码——AOP实现原理
引言 Spring AOP(Aspect Orient Programming),AOP翻译过来就是面向切面编程,它体现的是一种编程思想,是对面向对象编程(OOP)的一种补充. 在实际业务开发过程中, ...
- python3读csv文件,出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid con
使用csv.reader(file)读csv文件时,出现如下错误:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in positio ...
- 关于error: failed to push some refs to如何解决
Smiling & Weeping ---- 在你的门前,我堆起一个雪人,代表笨拙的我,把你久等 常见的错误报错内容基本都是error: failed to push some refsto' ...