【2024最新】4000字搞懂sora!一张脑图贯穿!
话不多说,上图!
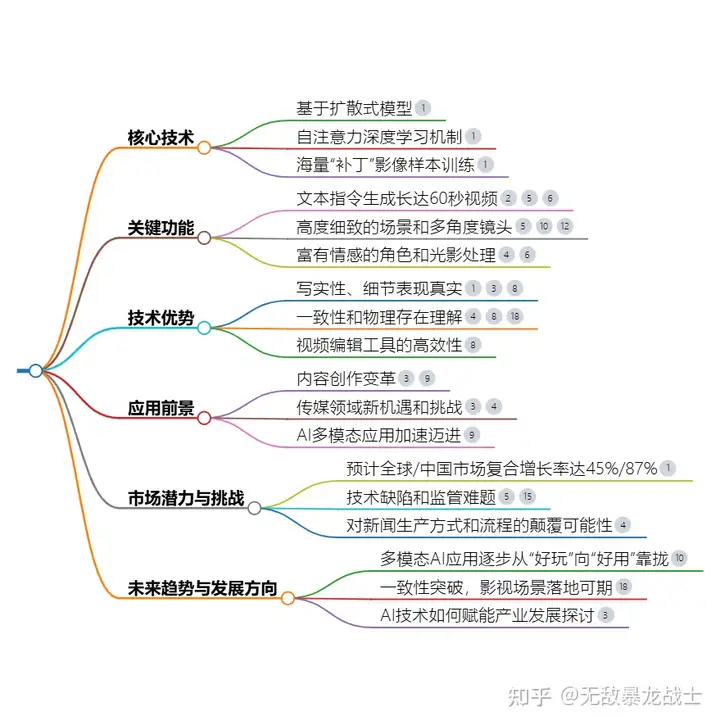
下面就是对sora的具体阐释:
Sora是OpenAI推出的一款革命性的视频生成模型,能够根据文本指令、静态图像或视频生成长达60秒的完整视频。这一模型基于扩散式模型和自注意力深度学习机制,通过将视频片段转换为静态图像并去除噪音以达到清晰效果。
核心技术与功能
技术架构:
- Sora结合了Diffusion和Transformer技术,并融合了Google的MAGViT和DeepMind的NaViT等方案,应用了OpenAI DALL-E 3图像描述方案。
- 使用独特的CLIP模型架构,能够生成高质量的视频描述。
- 基于Transformer架构的扩散模型,可以灵活地扩展视频内容,改变风格和背景环境。
视频生成能力:
- 能够生成高度细致的场景、复杂的多角度镜头以及富有情感的角色。
- 具备3D一致性、远距离相干性和物体持久性等模拟功能。
- 可以实现对复杂物理运动和逻辑关系的准确捕捉,尽管目前仍存在一些局限性。
应用范围:
- Sora在短视频、宣传片、动画电影等领域具有广泛的应用前景。
- 对广告业、电影预告片和短视频行业带来巨大影响,甚至可能颠覆这些行业。
- 在传媒领域推动智媒的发展,丰富元宇宙、长短视频和MR应用生态。
商业潜力与挑战
商业化潜力:
- Sora展现出明确的商业化潜力与应用路线,预计到2030年,全球/中国相关市场复合增长率将达45%/87%。
- 将进一步加深和拓宽OpenAI的护城河,少数巨头将占据底层算法和模型的主导地位。
技术缺陷与挑战:
- 目前Sora在处理复杂物理运动或逻辑关系时可能存在局限性,例如混淆文字表达或不符合现实世界的物理关系认知等。
- 需要更丰富的数据和更强的算力来优化其性能。
- 存在监管难题和版权、隐私等问题,需要与各方合作确保安全使用。
行业影响与未来趋势
行业影响:
- Sora的出现为视频领域带来了巨大的想象空间,突破了人类在专业能力上的限制,被誉为“世界模拟器”。
- 对于没有成熟运营、设计、策划团队的中小商家来说,Sora的智能生成可以实现内容生产的低成本化。
未来趋势:
- 随着业内追赶态势,市场上可能会出现更多类似Sora的模型和产品,促进用户采用率和需求的进一步增长。
- Sora有望撬动AI多模态应用新热度,对传媒领域带来存量提质增效和新增应用场景。
Sora作为一款先进的视频生成模型,在技术架构、视频生成能力和应用范围等方面都展现了强大的潜力和优势。然而,它也面临着一些技术和监管上的挑战,需要持续优化和改进以实现更广泛的应用和更大的商业价值。
Sora视频生成模型的技术细节和原理是什么?
Sora视频生成模型是OpenAI于2024年2月16日发布的一项革命性技术,旨在通过文本提示、静态图像或现有视频生成或扩展高质量的视频内容。该模型在多个方面展现了显著的技术优势和创新。
技术细节与原理
1. 扩散模型与Transformer架构
Sora基于扩散模型(Diffusion Model),其核心机制是从一个看起来像静态噪声的视频开始,逐步去除噪声,最终生成清晰的视频。这种模型能够处理视频和图片中时空片段的潜在代码,并利用Transformer架构来捕捉前后文全局关系,从而实现每一帧图像的精确生成以及前后时空的一致性。
2. 视频补丁(Patch)
Sora使用了“视频补丁”(Patch)这一高度可扩展且有效的表示形式。视频补丁将视频数据转化为较小的数据单元,类似于GPT中的token,这使得模型能够在不同类型的视频和图像上进行训练。这些补丁作为数据的有效提示,帮助模型更好地理解和生成复杂的视觉场景。
3. 大规模训练与语言理解
Sora采用了大规模训练的方法,并结合了DALL·E 3中的重述技术和ChatGPT的大语言模型,以提高模型的语言理解能力。具体来说,Sora利用重新字幕技术生成高度描述性的字幕,并将简短的用户提示转换为详细的描述,从而生成与提示更匹配的高质量视频。
4. DiT模型与解码器
Sora的核心技术之一是DiT(Denoising Diffusion Transformer)模型。该模型将视频压缩到低维潜在空间中,并将其分解为补丁,然后在低维空间中进行训练。通过逐步添加高斯噪声并学习如何逆向去除噪声,DiT模型能够生成新数据。最后,模型通过对应的解码器,将生成的元素映射回像素空间,完成视频生成任务。
5. 功能特点
- 长时长视频生成:Sora可以一次性生成长达60秒的高保真视频,这在当前的AI视频生成领域中是一个重大突破。
- 复杂场景与细节:Sora能够生成包含精细复杂场景、生动角色表情以及复杂镜头运动的视频,确保三维空间中的人物和场景元素保持一致性。
- 多模态输入:除了文本提示外,Sora还支持根据静态图像或现有视频进行扩展和生成。
- 灵活采样与全分辨率输出:Sora具有灵活采样和全分辨率输出的功能,可以快速创建不同设备的原始宽高比内容。

总结
Sora视频生成模型通过结合扩散模型、Transformer架构、视频补丁技术、大规模训练和语言理解能力等先进技术,实现了在视频生成领域的多项突破。
Sora在处理复杂物理运动和逻辑关系时的具体局限性有哪些?
Sora在处理复杂物理运动和逻辑关系时存在以下具体局限性:
- 无法准确模拟复杂物理现象:尽管Sora能够理解用户指令并生成视频,但其在模拟复杂场景中的物理特性方面仍存在困难。例如,它可能难以准确模拟玻璃杯倾倒、食物咬痕等复杂的物理运动,并且无法推演时间变化。
- 混淆因果关系和空间细节:Sora有时会创造出不符合现实世界物理关系认知的画面,特别是在处理复杂、繁琐的物理运动时,可能无法准确模拟因果关系或推演时间变化。此外,该模型还存在混淆部分画面中文字表达的可能性,如广告牌标语不合逻辑或不成文字。
- 难以精确描述随时间变化的事件:Sora可能无法准确模拟复杂场景的物理原理,并且可能无法理解因果关系,混淆提示的空间细节,难以精确描述随着时间推移发生的事件。
- 对牛顿定律等物理规律的掌握不足:一些外部专家猜测,Sora很难将物理世界中的牛顿定律、湍流方程和量子学定理等规律一条一条在模型中显式罗列出来,这可能是由于神经网络模型的涌现之力所限。
- 视频时长限制:Sora生成的视频时长有限制,最长只能生成60秒的视频,对于更长的视频片段,Sora会使用预训练模型进行处理。
目前OpenAI如何解决Sora模型在数据隐私和版权方面的挑战?
目前,OpenAI在解决Sora模型在数据隐私和版权方面的挑战方面采取了多种措施。首先,尽管有报道指出Sora模型的数据集可能包括未经许可获取的大量书籍及其他版权材料,引发了关于是否遵守知识产权法和数据采集伦理标准的争议,但OpenAI声称在训练Sora时使用了“公开可用”和“已许可”的内容。
为了应对这些挑战,OpenAI采取了一系列安全措施和对抗性测试。例如,在产品中使用Sora前,OpenAI承诺将由专家对模型进行对抗性测试,以评估其危害或风险,并核查并拒绝包含极端暴力、性骚扰、歧视、恐怖主义、仇恨图像、他人IP等文本输出的内容。此外,Sora内置的文本提示过滤器可以筛选发送给模型的所有提示,阻止对暴力、色情、仇恨言论以及名人肖像等敏感或不适当内容的请求。视频内容过滤器也能检查生成的视频帧,屏蔽违反OpenAI安全政策的内容。
虽然OpenAI已经采取了一些措施来缓解数据隐私和版权方面的挑战,但仍有公众对其处理敏感数据问题上的透明度和有效性表示担忧。
Sora对广告业、电影预告片和短视频行业的具体影响有哪些实例?
Sora对广告业、电影预告片和短视频行业的具体影响主要体现在以下几个方面:
- 降低视频制作成本和门槛:Sora能够帮助直播卖家高效地从长达数小时的直播中剪辑出亮点,并进行混剪和配音等处理,实现内容生产的低成本化。此外,Sora降低了视频制作的门槛和成本,将颠覆广告业、电影预告片、短视频行业和游戏等领域。
- 提高内容创作质量和效率:Sora的出现极大地提升了短视频的内容供给和创作质量,可能使短剧重心回归高质量剧本创作。它还能快速、准确地生成生动的现场视频,提高新闻报道的时效性。
- 个性化广告推送:在广告推送方面,Sora可以通过收集特定用户的偏好和兴趣来定制专属广告内容,提高顾客购买欲望和品牌忠诚度。
- 电影预告片和社交媒体宣传视频的制作:对于即将上映的电影或电视节目,使用Sora可以简化预告片或社交媒体宣传视频的制作过程,只需输入关键情节或场景的简短描述便能渲染出精选内容汇编的短视频,缩短制作周期的同时还能节省一定的制作成本。
- 促进技术创新和应用想象:Sora代表了AI赋能的新阶段,将为自学发展、人才培训、科学研究、产品研发等多个领域带来技术革新和应用想象。
- 改变内容产业的成本结构和资源支撑体系:短期内,Sora将直接改变很多内容产业的成本结构以及资源支撑体系,长期来看,其构建的基于三维物理世界来创造数字原型的强大引擎,将给一些产业带来深远影响。
- 可能引发行业内的就业变化:虽然Sora的问世可能会导致设计师、摄影师和后期制作岗位需求的大量减少,但对于拥有自身风格和调性的创作者来说,Sora只能起到辅助作用。同时,也有观点认为,尽管Sora带来了效率上的提升,但并不是说不需要人了,视频行业还有很多的环节不能被替代,比如创意。
未来市场上类似Sora的视频生成模型有哪些,它们的主要区别和优势是什么?
未来市场上类似Sora的视频生成模型主要有以下几款:Runway和Pika。这些模型与Sora的主要区别和优势如下:
视频时长:
- Sora:能够生成长达60秒的视频,这是目前市场上其他模型难以匹敌的。
- Runway和Pika:虽然具体时长未明确提及,但它们在视频时长方面可能不如Sora长,通常只能生成5秒以内的短视频。
场景复杂度和逼真度:
- Sora:可以生成主题精确、背景细节复杂的场景,并且视频效果逼真。此外,Sora还能够实现多角度镜头切换,保持前后一致性。
- Runway和Pika:相比之下,它们在处理复杂场景和多角度镜头方面的能力可能较弱,无法生成如此高质量和细节丰富的视频。
物理规律的掌握:
- Sora:在对物理规律的掌握方面表现不俗,例如在汽车行驶视频中,汽车影子与车身始终契合。
- Runway和Pika:这方面的能力可能不如Sora强,因为它们缺乏足够的数据标注和清洗工作量,导致模型在逻辑性和连续性方面的表现不如Sora。
多模态能力:
- Sora:不仅支持文本生成视频,还具备图像生成视频等能力,并能执行各种图像和视频编辑任务。
- Runway和Pika:虽然也具备一定的多模态能力,但在综合应用和扩展性方面可能不如Sora全面。
技术架构:
- Sora:采用转化器架构上的扩散模型,能够自主提取信息之间的关联并进行统一化重组,从而实现对文本信息的精准捕捉和渲染。
- Runway和Pika:具体的技术架构未详细说明,但可能没有像Sora那样先进的技术支撑。
安全性和伦理风险:
- Sora:尽管存在安全伦理风险,但其领先优势难以被打破,促使社交及内容平台与OpenAI更加紧密地合作。
- Runway和Pika:同样面临安全性和伦理风险的问题,但可能在应对措施和风险管理方面不如Sora成熟。
Sora在视频时长、场景复杂度、物理规律掌握、多模态能力和技术架构等方面均具有显著优势,而Runway和Pika则在这些方面略显不足。
以上内容就是我的看法,欢迎对ai前沿感兴趣的朋友看看博主其他文章博主的宝藏小站
【2024最新】4000字搞懂sora!一张脑图贯穿!的更多相关文章
- 真正“搞”懂HTTP协议05之What's HTTP?
前面几篇文章,我从纵向的空间到横向的时间,再到一个具体的小栗子,可以说是全方位,无死角的覆盖了HTTP的大部分基本框架,但是我聊的都太宽泛了,很多内容都是一笔带过,再加上一句后面再说就草草结束了.并且 ...
- 一文带你搞懂java中的变量的定义是什么意思
前言 在之前的文章中,壹哥给大家讲解了Java的第一个案例HelloWorld,并详细给大家介绍了Java的标识符,而且现在我们也已经知道该使用什么样的工具进行Java开发.那么接下来,壹哥会集中精力 ...
- 不想再被鄙视?那就看进来! 一文搞懂Python2字符编码
程序员都自视清高,觉得自己是创造者,经常鄙视不太懂技术的产品或者QA.可悲的是,程序员之间也相互鄙视,程序员的鄙视链流传甚广,作为一个Python程序员,自然最关心的是下面这幅图啦 我们项目组一值使用 ...
- 彻底搞懂字符编码(unicode,mbcs,utf-8,utf-16,utf-32,big endian,little endian...)[转]
最近有一些朋友常问我一些乱码的问题,和他们交流过程中,发现这个编码的相关知识还真是杂乱不堪,不少人对一些知识理解似乎也有些偏差,网上百度, google的内容,也有不少以讹传讹,根本就是错误的(例如说 ...
- 彻底搞懂JavaScript中的继承
你应该知道,JavaScript是一门基于原型链的语言,而我们今天的主题 -- "继承"就和"原型链"这一概念息息相关.甚至可以说,所谓的"原型链&q ...
- 搞懂分布式技术12:分布式ID生成方案
搞懂分布式技术12:分布式ID生成方案 ## 转自: 58沈剑 架构师之路 2017-06-25 一.需求缘起 几乎所有的业务系统,都有生成一个唯一记录标识的需求,例如: 消息标识:message-i ...
- 搞懂分布式技术10:LVS实现负载均衡的原理与实践
搞懂分布式技术10:LVS实现负载均衡的原理与实践 浅析负载均衡及LVS实现 原创: fireflyc 写程序的康德 2017-09-19 负载均衡 负载均衡(Load Balance,缩写LB)是一 ...
- 搞懂分布式技术5:Zookeeper的配置与集群管理实战
搞懂分布式技术5:Zookeeper的配置与集群管理实战 4.1 配置文件 ZooKeeper安装好之后,在安装目录的conf文件夹下可以找到一个名为“zoo_sample.cfg”的文件,是ZooK ...
- 搞懂分布式技术6:Zookeeper典型应用场景及实践
搞懂分布式技术6:Zookeeper典型应用场景及实践 一.ZooKeeper典型应用场景实践 ZooKeeper是一个高可用的分布式数据管理与系统协调框架.基于对Paxos算法的实现,使该框架保证了 ...
- 搞懂分布式技术3:初探分布式协调服务zookeeper
搞懂分布式技术3:初探分布式协调服务zookeeper 1.Zookeepr是什么 Zookeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅,负载均衡, ...
随机推荐
- kubernets之横向伸缩pod与集群节点
一 pod的自动伸缩容的应用背景 在面对负载并发过高的时候,我们或许希望能够提高RS,RC以及Deployment等的replicas的参数来增加pod的cpu,mem等,或者是通过提高每个容器的r ...
- Asp-Net-Core开发笔记:使用原生的接口限流功能
前言 之前介绍过使用 AspNetCoreRateLimit 组件来实现接口限流 从 .Net7 开始,AspNetCore 开始内置限流组件,当时我们的项目还在 .Net6 所以只能用第三方的 现在 ...
- Windows Server 2022 NTP服务器
一.配置NTP服务器 配置NTP服务器,为客户端提供时间同步服务. 如果计算机是Active Directory域控制器,则NTP服务器功能已自动启动. 因此,下面的示例是计算机在工作组环境中启用NT ...
- Qt-qrencode开发-生成、显示二维码📀
Qt-qrencode开发-生成二维码 目录 Qt-qrencode开发-生成二维码 1.概述 2.实现效果 3.编译qrencode 4.在QT中引入编译为静态库的QRencode 5.在Qt中直接 ...
- 查看CentOS版本的方法
1.以下命令对于Linux发行版是通用的: root@MyMail ~ # uname Linux root@MyMail ~ # uname -r 2.6.18-164.el5 [root@loca ...
- Yii 实现数据库SUM操作
方法一:这种方法有个坑儿,就是as 后面的别名,必须是属性范围内的名字. $criteria = new CDbCriteria(); $criteria->select = 'sum(amou ...
- JavaSE 关键字和标识符
目录 关键字 标识符 标识符命名规则 标识符命名规范 字面值 关键字 具有特殊含义的 命名时不可以与关键字重名 标识符 也就是名字,对类名,变量名称,方法名称,参数名称等修饰 标识符命名规则 以字母, ...
- Easysearch 容量规划建议
基于容量估算 主要问题: 每天将索引多少原始数据(GB)?保留数据多少天? 原始数据膨胀率 您将强制执行多少个副本分片? 您将为每个数据节点分配多少内存? 您的内存:数据比例是多少? 原则 保留 +1 ...
- 如何解决系统报错:nf_conntrack: table full, dropping packets
问题 在系统日志中(/var/log/messages),有时会看到大面积的下面的报错: nf_conntrack: table full, dropping packet 这说明系统接到了大量的连接 ...
- Maven常用命令有哪些?
a.install 本地安装, 包含编译,打包,安装到本地仓库编译 - javac 打包 - jar, 将java代码打包为jar文件 安装到本地仓库 - 将打包的jar文件,保存到本地仓库目录中. ...