【转载】 机器学习数据可视化 (t-SNE 使用指南)—— Why You Are Using t-SNE Wrong
原文地址:
https://towardsdatascience.com/why-you-are-using-t-sne-wrong-502412aab0c0
=====================================
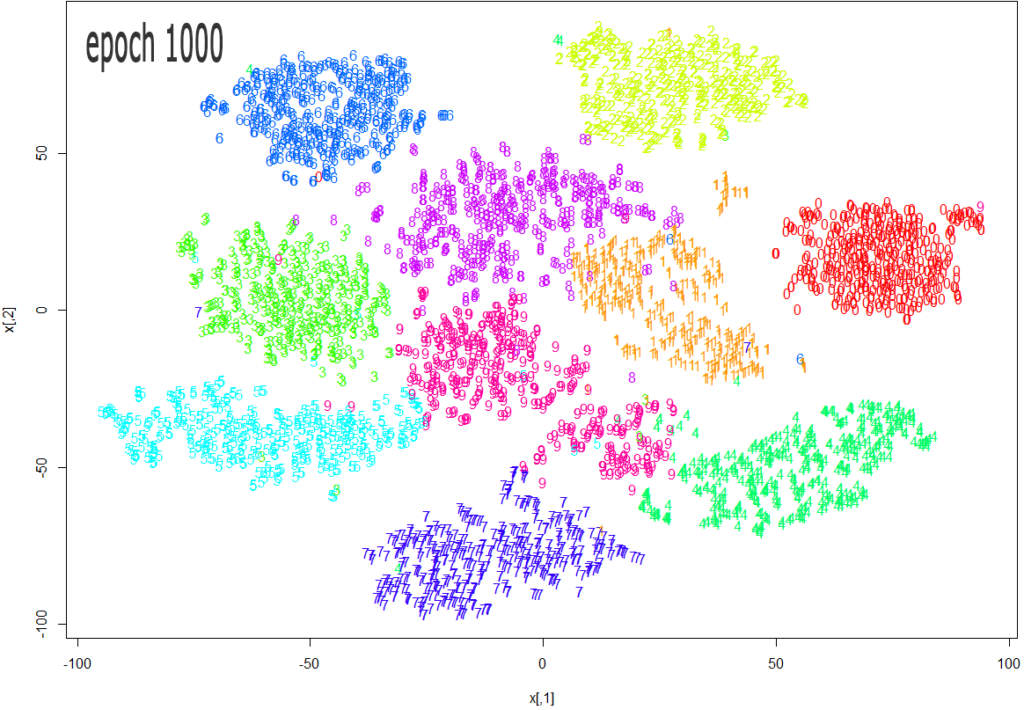
Source: https://datascienceplus.com/multi-dimensional-reduction-and-visualisation-with-t-sne/
t-SNE has become a very popular technique for visualizing high dimensional data. It’s extremely common to take the features from an inner layer of a deep learning model and plot them in 2-dimensions using t-SNE to reduce the dimensionality. Unfortunately, most people just use scikit-learn’s implementation without actually understanding the results and misinterpreting what they mean.
While t-SNE is a dimensionality reduction technique, it is mostly used for visualization and not data pre-processing (like you might with PCA). For this reason, you almost always reduce the dimensionality down to 2 with t-SNE, so that you can then plot the data in two dimensions.
The reason t-SNE is common for visualization is that the goal of the algorithm is to take your high dimensional data and represent it correctly in lower dimensions — thus points that are close in high dimensions should remain close in low dimensions. It does this in a non-linear and local way, so different regions of data could be transformed differently.
t-SNE has a hyper-parameter called perplexity. Perplexity balances the attention t-SNE gives to local and global aspects of the data and can have large effects on the resulting plot. A few notes on this parameter:
- It is roughly a guess of the number of close neighbors each point has. Thus, a denser dataset usually requires a higher perplexity value.
- It is recommended to be between 5 and 50.
- It should be smaller than the number of data points.
The biggest mistake people make with t-SNE is only using one value for perplexity and not testing how the results change with other values. If choosing different values between 5 and 50 significantly change your interpretation of the data, then you should consider other ways to visualize or validate your hypothesis.
It is also overlooked that since t-SNE uses gradient descent, you also have to tune appropriate values for your learning rate and the number of steps for the optimizer. The key is to make sure the algorithm runs long enough to stabilize.
There is an incredibly good article on t-SNE that discusses much of the above as well as the following points that you need to be aware of:
- You cannot see the relative sizes of clusters in a t-SNE plot. This point is crucial to understand as t-SNE naturally expands dense clusters and shrinks spares ones. I often see people draw inferences by comparing the relative sizes of clusters in the visualization. Don’t make this mistake.
- Distances between well-separated clusters in a t-SNE plot may mean nothing. Another common fallacy. So don’t necessarily be dismayed if your “beach” cluster is closer to your “city” cluster than your “lake” cluster.
- Clumps of points — especially with small perplexity values — might just be noise. It is important to be careful when using small perplexity values for this reason. And to remember to always test many perplexity values for robustness.
Now — as promised some code! A few things of note with this code:
- I first reduce the dimensionality to 50 using PCA before running t-SNE. I have found that to be good practice (when having over 50 features) because otherwise, t-SNE will take forever to run.
- I don’t show various values for perplexity as mentioned above. I will leave that as an exercise for the reader. Just run the t-SNE code a few more times with different perplexity values and compare visualizations.
from sklearn.datasets import fetch_mldata
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# get mnist data
mnist = fetch_mldata("MNIST original")
X = mnist.data / 255.0
y = mnist.target
# first reduce dimensionality before feeding to t-sne
pca = PCA(n_components=50)
X_pca = pca.fit_transform(X)
# randomly sample data to run quickly
rows = np.arange(70000)
np.random.shuffle(rows)
n_select = 10000
# reduce dimensionality with t-sne
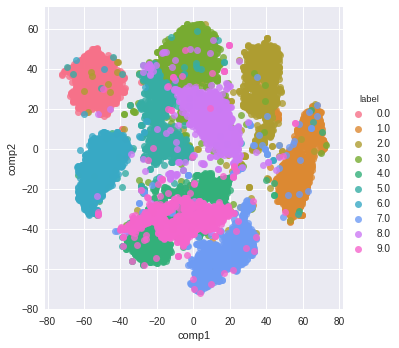
tsne = TSNE(n_components=2, verbose=1, perplexity=50, n_iter=1000, learning_rate=200)
tsne_results = tsne.fit_transform(X_pca[rows[:n_select],:])
# visualize
df_tsne = pd.DataFrame(tsne_results, columns=['comp1', 'comp2'])
df_tsne['label'] = y[rows[:n_select]]sns.lmplot(x='comp1', y='comp2', data=df_tsne, hue='label', fit_reg=False)
And here is the resulting visualization:
=========================================
【转载】 机器学习数据可视化 (t-SNE 使用指南)—— Why You Are Using t-SNE Wrong的更多相关文章
- 前端数据可视化echarts.js使用指南
一.开篇 首先这里要感谢一下我的公司,因为公司需求上面的新颖(奇葩)的需求,让我有幸可以学习到一些好玩有趣的前端技术,前端技术中好玩而且比较实用的我想应该要数前端的数据可视化这一方面,目前市面上的数据 ...
- 机器学习-数据可视化神器matplotlib学习之路(五)
这次准备做一下pandas在画图中的应用,要做数据分析的话这个更为实用,本次要用到的数据是pthon机器学习库sklearn中一组叫iris花的数据,里面组要有4个特征,分别是萼片长度.萼片宽度.花瓣 ...
- 机器学习-数据可视化神器matplotlib学习之路(四)
今天画一下3D图像,首先的另外引用一个包 from mpl_toolkits.mplot3d import Axes3D,接下来画一个球体,首先来看看球体的参数方程吧 (0≤θ≤2π,0≤φ≤π) 然 ...
- 机器学习-数据可视化神器matplotlib学习之路(三)
之前学习了一些通用的画图方法和技巧,这次就学一下其它各种不同类型的图.好了先从散点图开始,上代码: from matplotlib import pyplot as plt import numpy ...
- 机器学习-数据可视化神器matplotlib学习之路(二)
之前学习了matplotlib的一些基本画图方法(查看上一节),这次主要是学习在图中加一些文字和其其它有趣的东西. 先来个最简单的图 from matplotlib import pyplot as ...
- 机器学习-数据可视化神器matplotlib学习之路(一)
直接上代码吧,说明写在备注就好了,这次主要学习一下基本的画图方法和常用的图例图标等 from matplotlib import pyplot as plt import numpy as np #这 ...
- Python数据可视化编程实战pdf
Python数据可视化编程实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1vAvKwCry4P4QeofW-RqZ_A 提取码:9pcd 复制这段内容后打开百度 ...
- python数据可视化编程实战PDF高清电子书
点击获取提取码:3l5m 内容简介 <Python数据可视化编程实战>是一本使用Python实现数据可视化编程的实战指南,介绍了如何使用Python最流行的库,通过60余种方法创建美观的数 ...
- Python Seaborn综合指南,成为数据可视化专家
概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化 ...
- 机器学习PAL数据可视化
机器学习PAL数据可视化 本文以统计全表信息为例,介绍如何进行数据可视化. 前提条件 完成数据预处理,详情请参见数据预处理. 操作步骤 登录PAI控制台. 在左侧导航栏,选择模型开发和训练 > ...
随机推荐
- 手把手教你搭建Docker私有仓库Harbor
1.什么是Docker私有仓库 Docker私有仓库是用于存储和管理Docker镜像的私有存储库.Docker默认会有一个公共的仓库Docker Hub,而与Docker Hub不同,私有仓库是受限访 ...
- thinkpad t490触摸板失灵解决方法
笔记本电脑之前触摸板使用正常,可能在某次更新之后,发现失灵不可用. 解决方法: 更新或滚动触摸板驱动程序 当您在设备管理器中时,右键单击列表中的触摸板(可能称为Dell TouchPad,Lenovo ...
- Unity 利用Cache实现边下边玩
现在手机游戏的常规更新方案都是在启动时下载所有资源更新,游戏质量高的.用户粘性大的有底气,先安装2个G,启动再更新2个G,文件小了玩家还觉得品质不行不想玩. 最近在做微信.抖音小游戏,使用他们提供的资 ...
- POJ2247,hdu1058(Humble Numbers)
Problem Description A number whose only prime factors are 2,3,5 or 7 is called a humble number. The ...
- ARM+DSP异构多核——全志T113-i+玄铁HiFi4核心板规格书
核心板简介 创龙科技SOM-TLT113是一款基于全志科技T113-i双核ARM Cortex-A7 + 玄铁C906 RISC-V + HiFi4 DSP异构多核处理器设计的全国产工业核心板,ARM ...
- DAX 自动生成日期表-与订单表(业绩表)相同日期区间
日期表 = ADDCOLUMNS ( CALENDAR (MIN('业绩表'[日期]), MAX('业绩表'[日期])), //关键在于MIN函数和MAX函数的使用 "年度", Y ...
- AT_abc215F 题解
考虑二分答案. 假设当前二分的答案为 \(k\),那么对于每个点,距离大于等于 \(k\) 的点构成了平面上 \(4\) 个子平面. 那么只需查询子平面中是否存在点即可,类似于窗口的星星,把问题转换成 ...
- 如何查看Chrome内核版本
Blink Google chrome即谷歌浏览器原来采用的渲染引擎是Webkit,自chrome 28开始,谷歌浏览器放弃了Webkit,改用自主开发的渲染引擎Blink. 所以现在大多数喜欢尝鲜的 ...
- [项目自荐] 交叉编译njs并使用Nginx搭建自由的个人网盘:vList5
这个博客好久没有打理了,最近才想起来 这篇文章是以下 5 篇文章的组合,希望这个免费的项目能实现他的初衷吧 vList5:部署指南 vList5.3 全面加密,从我做起 njs 从入门(交叉编译)到入 ...
- Java实现快速快速排序算法
算法简介 快速排序(Quick Sort) 是由冒泡排序改进而得的.在冒泡排序过程中,只对相邻的两个记录进行比较,因此每次交换两个相邻记录时只能消除一个逆序.如果能通过两个(不相邻)记录的一次交换直接 ...