【python爬虫案例】用python爬取百度的搜索结果!2023.3发布
一、爬取目标
本次爬取目标是,百度搜索结果数据。以搜索”马哥python说“为例:
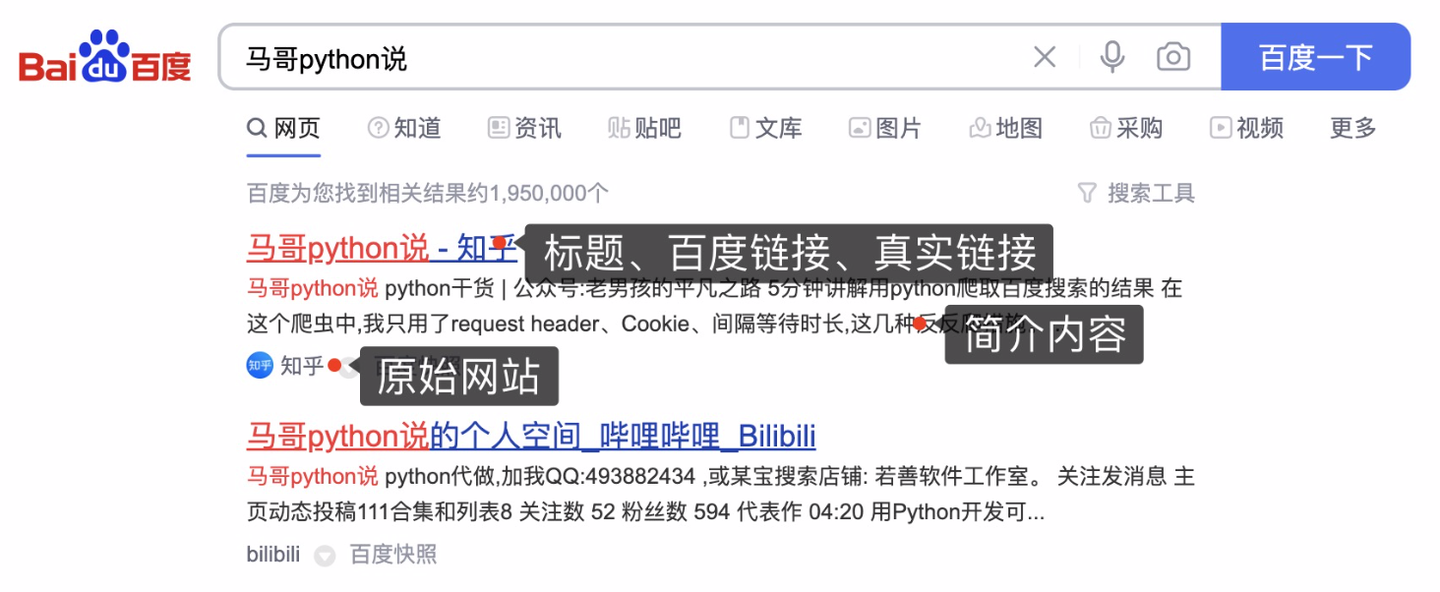
爬取字段,含:
页码、标题、百度链接、真实链接、简介、网站名称。
二、展示结果数据
爬取结果如下:

三、编写爬虫代码
3.1 请求头和cookie
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析页面
import pandas as pd # 存入csv数据
import os # 判断文件存在
from time import sleep # 等待间隔
import random # 随机
import re # 用正则表达式提取url
定义一个请求头:
# 伪装浏览器请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"Connection": "keep-alive",
"Accept-Encoding": "gzip, deflate, br",
"Host": "www.baidu.com",
# 需要更换Cookie
"Cookie": "BIDUPSID=729E480F1B8CEB5347D8572AE6495CFA; PSTM=1645237046; BAIDUID=729E480F1B8CEB53DEEB6344B7C88A22:FG=1; BD_UPN=123253; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; __yjs_duid=1_695315baa9a328fc73db6db6ba9ee8781645357087938; MSA_WH=1324_311; H_PS_PSSID=35106_31660_35765_34584_35872_35818_35948_35954_35315_26350_22159; H_PS_645EC=ab89Uk1B6EQVOEBnfF64C5jyWp40Rge9HGeQ8Q2fEodX81kjh6WtOKBhR2A; BAIDUID_BFESS=729E480F1B8CEB53DEEB6344B7C88A22:FG=1; BA_HECTOR=2g8g040k818g0l21a31h1g5g60r; baikeVisitId=9a933a90-dc5c-4192-93d2-10526d401267; WWW_ST=1645745708722"
}
Cookie是个关键,如果不加Cookie,响应码可能不是200,获取不到数据,而且Cookie值是有有效期的,需要定期更换,如果发现返回无数据或响应码非200,尝试替换最新的Cookie。
怎么获取到Cookie呢?打开Chrome浏览器,访问百度页面,按F12进入开发者模式:
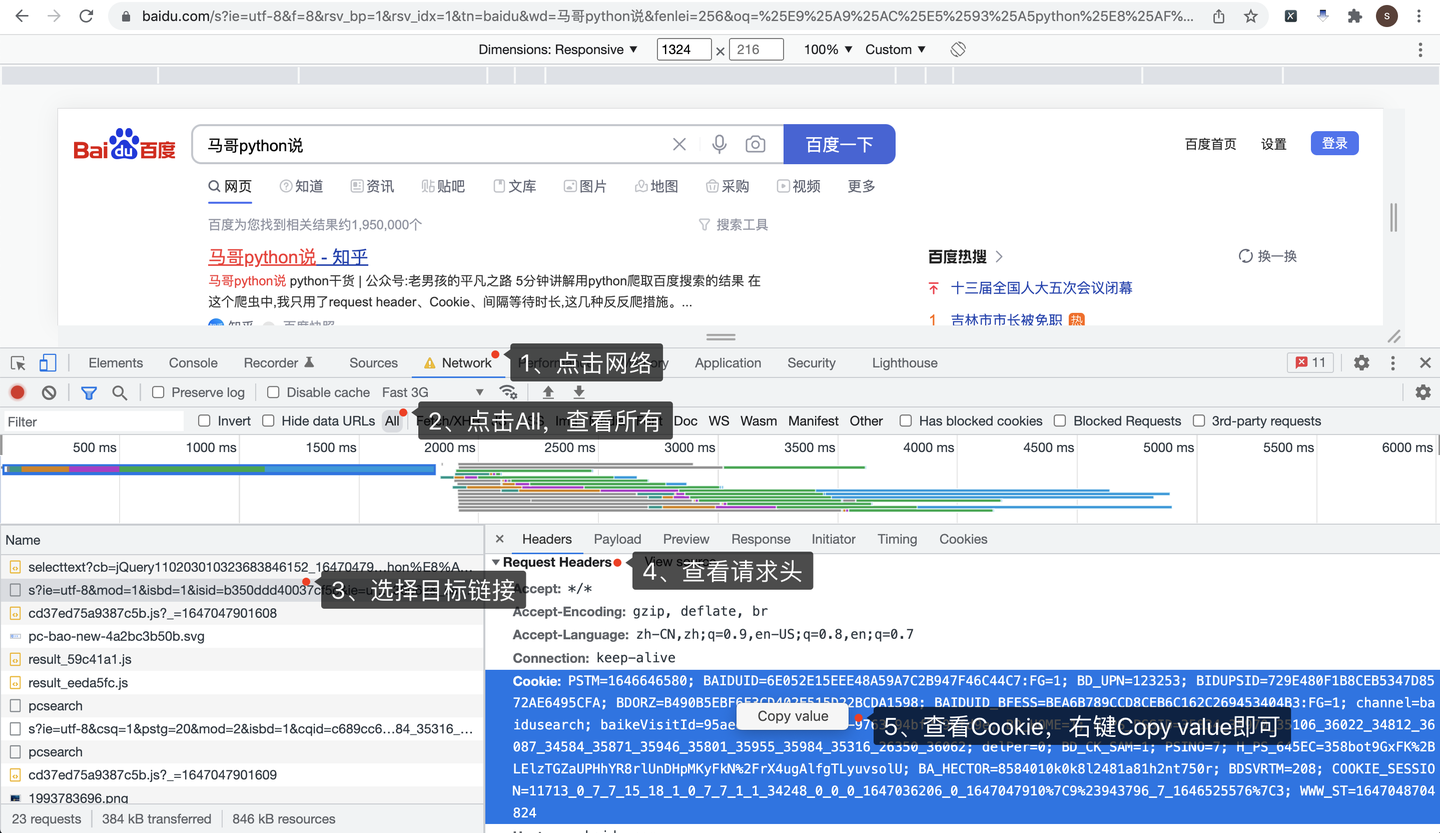
按照图示顺序,依次:
- 点击Network,进入网络页
- 点击All,查看所有网络请求
- 选择目标链接,和地址栏里的地址一致
- 查看Request Headers请求头
- 查看请求头里的Cookie,直接右键,Copy value,粘贴到代码里
3.2 分析请求地址
然后,分析页面请求地址:

wd=后面是搜索关键字"马哥python说",pn=后面是10(规律:第一页是0,第二页是10,第三页是20,以此类推),其他URL参数可以忽略。
3.3 分析页面元素
然后,分析页面元素,以搜索结果标题为例:
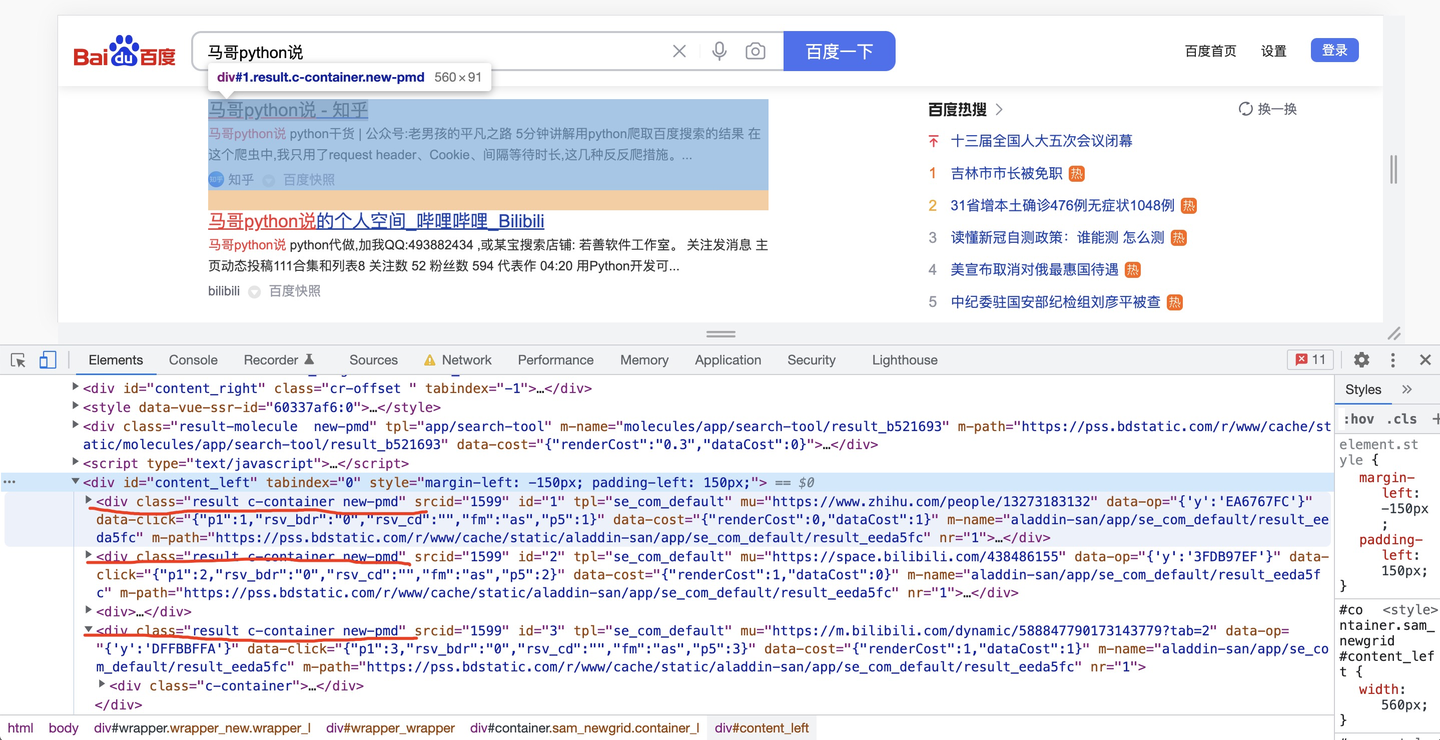
每一条搜索结果,都是class="result c-container new-pmd",下层结构里有简介、链接等内容,解析内部子元素不再赘述。
所以根据这个逻辑,开发爬虫代码。
# 获得每页搜索结果
for page in range(v_max_page):
print('开始爬取第{}页'.format(page + 1))
wait_seconds = random.uniform(1, 2) # 等待时长秒
print('开始等待{}秒'.format(wait_seconds))
sleep(wait_seconds) # 随机等待
url = 'https://www.baidu.com/s?wd=' + v_keyword + '&pn=' + str(page * 10)
r = requests.get(url, headers=headers)
html = r.text
print('响应码是:{}'.format(r.status_code))
soup = BeautifulSoup(html, 'html.parser')
result_list = soup.find_all(class_='result c-container new-pmd')
print('正在爬取:{},共查询到{}个结果'.format(url, len(result_list)))
3.4 获取真实地址
其中,获取到的标题链接,一般是这种结构:
这显然是百度的一个跳转前的地址,不是目标地址,怎么获取它背后的真实地址呢?
向这个跳转前地址,发送一个请求,然后逻辑处理下:
def get_real_url(v_url):
"""
获取百度链接真实地址
:param v_url: 百度链接地址
:return: 真实地址
"""
r = requests.get(v_url, headers=headers, allow_redirects=False) # 不允许重定向
if r.status_code == 302: # 如果返回302,就从响应头获取真实地址
real_url = r.headers.get('Location')
else: # 否则从返回内容中用正则表达式提取出来真实地址
real_url = re.findall("URL='(.*?)'", r.text)[0]
print('real_url is:', real_url)
return real_url
如果响应码是302,就从响应头中的Location参数获取真实地址。
如果是其他响应码,就从响应内容中用正则表达式提取出URL真实地址。
3.5 保存结果数据
把爬取到的数据,保存到csv文件:
df = pd.DataFrame(
{
'关键词': kw_list,
'页码': page_list,
'标题': title_list,
'百度链接': href_list,
'真实链接': real_url_list,
'简介': desc_list,
'网站名称': site_list,
}
)
if os.path.exists(v_result_file):
header = None
else:
header = ['关键词', '页码', '标题', '百度链接', '真实链接', '简介', '网站名称'] # csv文件标头
df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('结果保存成功:{}'.format(v_result_file))
to_csv的时候需加上选项(encoding='utf_8_sig'),否则存入数据会产生乱码,尤其是windows用户!
四、同步讲解视频
讲解视频:https://www.bilibili.com/video/BV1ob4y1W7qj
五、附完整源码
完整源码获取:【python爬虫案例】用python爬取百度的搜索结果!2023.3发布
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬取百度的搜索结果!2023.3发布的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- CornerNet-Lite:CornerNet粗暴优化,加速6倍还提点了 | BMVC 2020
论文对CornerNet进行了性能优化,提出了CornerNet-Saccade和CornerNet-Squeeze两个优化的CornerNet变种,优化的手段具有很高的针对性和局限性,不过依然有很多 ...
- KingbaseES查找慢查询语句和阻塞会话
在处理数据库性能问题时,识别和分析慢查询及阻塞会话是至关重要的步骤.数据库管理员和开发人员常常需要依赖特定的工具和查询语句来追踪这些性能瓶颈. 当数据库响应变慢或出现处理延迟时,第一步通常是查找那些执 ...
- windows系统命令行cmd查看显卡驱动版本号CUDA
Win+R 输入cmd 进入命令行 输入 nvidia-smi
- wordpress自建博客站,在页脚添加网站总访问次数
wordpress自建博客站,在页脚添加网站总访问次数 笔者使用的主题是 GeneratePress 版本:3.1.3 打开footer.php编辑 <div style="text- ...
- yml和properties打印SQL日志信息
1.配置文件里面配置 第一种是properties类型如下 logging.level.com.datayes.mdi.dao.rdb.mommp.**=debug其中 com.datayes.mdi ...
- #线性基,差分,线段树#洛谷 5607 [Ynoi2013] 无力回天 NOI2017
题目 分析 考虑区间修改比较难操作,将数组差分一下,转化成两次单点修改. 这样查询前缀的异或值就是该位置的异或值,线性基可以用线段树维护, 那么取出 \((l,r]\) 所在的线性基,再将 \(a[l ...
- #数学期望,高斯消元#洛谷 3232 [HNOI2013]游走
题目 分析 如果计算出边的期望经过次数那就可以算出来答案 首先转换成点的期望经过次数,设\(dp[x]\)表示点\(x\)的期望经过次数 那么\(dp[x]=\sum_{y\in son}\frac{ ...
- 手撸jdk源码分析类加载机制
我们一般写的java文件jvm是识别不了的,因此需要编译,编译后会变成.class文件,而要执行代码,jvm首先会去加载.class文件到内存中,那么他的流程是什么样的呢: 1.首先肯定创建java虚 ...
- DS-Net:可落地的动态网络,实际加速1.62倍,快改造起来 | CVPR 2021 Oral
论文提出能够适配硬件加速的动态网络DS-Net,通过提出的double-headed动态门控来实现动态路由.基于论文提出的高性能网络设计和IEB.SGS训练策略,仅用1/2-1/4的计算量就能达到静态 ...
- 高可用之战:Redis Sentinal(哨兵模式)
★ Redis24篇集合 1 背景 在我们的<Redis高可用之战:主从架构>篇章中,介绍了Redis的主从架构模式,可以有效的提升Redis服务的可用性,减少甚至避免Redis服务发生完 ...