Bert不完全手册4. 绕开BERT的MASK策略?XLNET & ELECTRA
基于随机token MASK是Bert能实现双向上下文信息编码的核心。但是MASK策略本身存在一些问题
- MASK的不一致性:MASK只在预训练任务中存在,在微调中不存在,Bert只是通过替换部分的随机MASK来降低不一致性的影响
- 独立性假设:对MASK的预测是基于独立概率而不是联合概率,模型并不会考虑MASK之间的条件关联
- MASK训练低效:每次只遮盖15%的token,每个batch的模型更新只基于这15%的input,导致模型训练效率较低
MASK有这么多的问题,那能否绕过MASK策略来捕捉双向上下文信息呢?下面介绍两种方案XLNET,Electra,它们使用两种截然不同的方案实现了在下游迁移的Encoder中完全抛弃MASK来学习双向上下文信息。正在施工中的代码库也接入了这两种预训练模型,同时支持半监督,领域迁移,降噪loss等模型优化项,感兴趣的戳这里>>SimpleClassification
XLNET
XLNET主要的创新在于通过排列组合的乱序语言模型,在不依赖MASK的情况下捕捉双向上下文信息,从而避免了MASK存在带来的不一致性。
乱序语言模型
常规语言模型的目标是按输入顺序进行因式分解,把文本联合概率拆分成条件概率的乘积
\]
而其实对于长度为T的序列,总共有T!种不同的排列组合方式,语言模型只是使用了输入顺序对应的一种分解顺序。而XLNET为了捕捉双向的上下文信息,把目标调整为最大化所有排列组合的以上概率。

以下\(Z_T\)来指代不同的排列组合,\(z \lt t\)是指在z的排列组合中t之前的元素
\]
为了控制计算量,XLNET并不会计算所有排列组合而是只采样一部分进行计算。因为不同的排列组合共用一套参数,也就隐形实现了双向上下文信息的获取。
这里需要注意的是所谓的乱序,并不是对输入样本进行打乱,输入样本会保持原始顺序,而乱序的计算是通过Attention MASK来实现。例如用‘1->3->2’的顺序,生成第3个token会先mask第2个token只使用1个token的信息。这个实现是非常必要,一方面对输入保序,保证了预训练和下游迁移时文本输入是一致的都是正常顺序。另一方面,如果对输入进行直接打乱,会丢失文本的正常顺序,导致模型不知道正常的文本是什么样子的。
从信息传递的角度来看,BERT在还原每个MASK token时都使用了全部的上下文信息,而XLNET的每一种排列组合在预测当前token时只采样了当前排列组合下的部分信息,从这个角度来讲乱序语言模型应该要比MLM更加稳健以及更容易学到更丰富的文本语义
双流机制
但以上的乱序AR存在一个问题,也就是当顺序是‘3->2->4’时预测4用到的信息,和‘3->2->1’预测1时的信息是一样的。也就是模型无法区分4和1不同位置带来信息差异。为什么只有XLNET会存在这个问题,GPT和BERT就不存在这个问题呢?
在BERT之中是通过MASK来标注哪些位置是需要AE预测的位置,而MASK只修改了对应位置的token embedding,而position embedding是保留了原始位置的信息的,这样在进行self-attention计算时,模型只是不能有效获取MAS
K位置的token信息但是可以获取位置信息。不过其实我对BERT的底层位置信息在经过多层transfromer block之后MASK部分的位置信息是否还能都得到有效的保留,个人感觉是存疑的
而在GPT中因为默认了向前递归,对于所有文本在预训练任务和下游迁移中这个顺序都没有发生改变,所以模型对位置信息的依赖只在x<t的部分,因为向前递归预测的永远是下一个位置,所以位置信息被隐含在了向前递归中。
但是在XLNET中,它既没有按照固定的向前传递顺序,也同时没有像Bert一样保留预测位置的的position embedding,这就导致模型无法知道下一个要预测的位置和已有信息间的关系。
为了解决这个问题XLNET引入了双流机制,其实就是在原始的transformer中加入一个额外的流,这个流不包含当前token的内容信息但是包含当前token的位置信息。
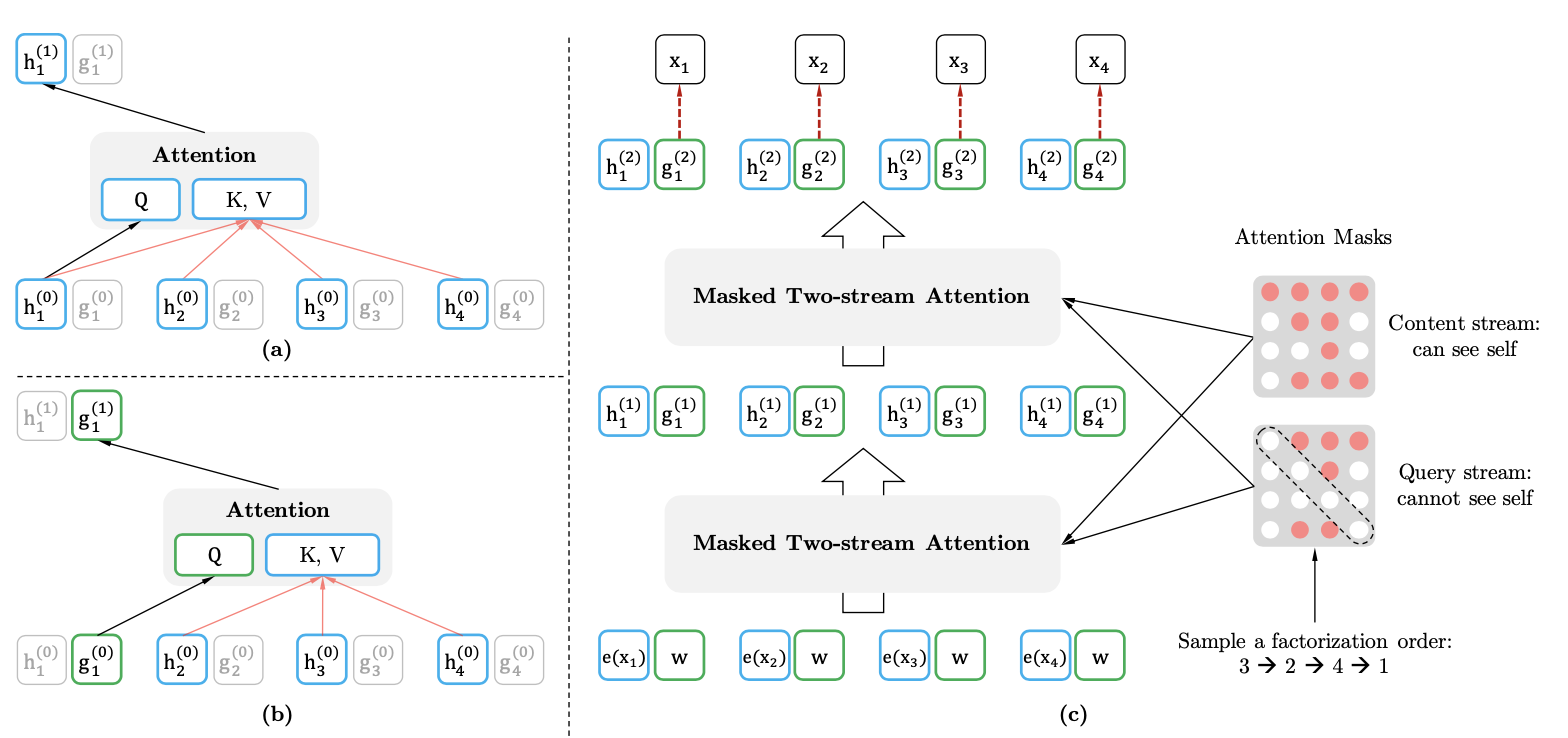
- \(h_{z_t}\)是content流,这部分和原始的transformer更新方式相同。只不过是在self-attention的基础上按当前的分解顺序,只使用包含当前<=t的所有信息
- \(g_{z_t}\)是query流,这部分包含<=t的位置信息,以及<t的内容信息。实现方式就是在attention计算时用\(h_{z \lt t}\)做K&V,保证内容信息不包含当前位置,而用\(g_{z_t}\)做Q来引入当前位置信息,最终模型的预测依赖query流的输出结果。所以XLNET其实是引入了在下游迁移中可以抛弃的\(g_{z_t}\),来代替MASK,在保留位置信息的同时避免token本身的文本信息泄露。
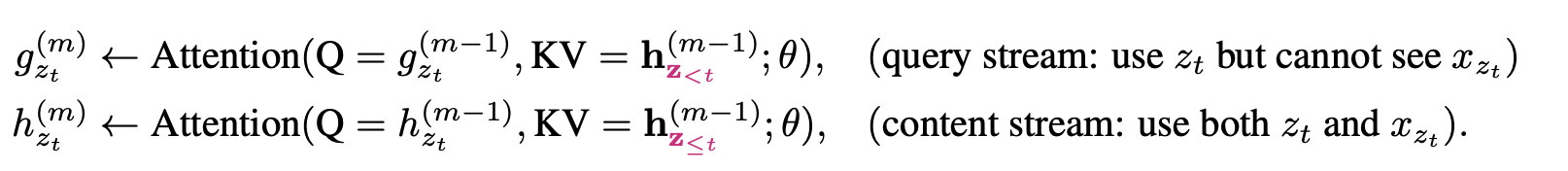
以上初始化\(h_{z_t}\)是用word embedding进行初始化,而\(g_{z_t}\)是随机初始化的。
XLNET的位置编码沿用了Transformer-XL提出的相对位置编码,不熟悉的同学戳这里中文NER的那些事儿5. Transformer相对位置编码&TENER代码实现,不过这部分提升主要针对长文本,和乱序语言模型没有必然的绑定关系,所以后面一起放到长文本建模中再说吧~
由于以上的乱序语言模型的拟合难度较高,如果对全文本都进行拟合,会导致模型难以收敛。所以XLNET引入了hyperparams K,每次只对当前排列组合下最后的\(1/K\)个token进行拟合。所以这里k越小训练难度越高。最终作者选择的K在6~7附近,所以和BERT 15%MASK的训练效率相似,每次只能对15%左右的token进行训练。
下游迁移
XLNET在下游任务迁移中的使用方式和Bert基本是完全一样的,以上的双流机制和乱序语言模型只使用在预训练阶段,来帮助模型参数学习到上下文信息。而在迁移到下游时,只有content流被使用,迁移方式也和Bert一致。XLNET在GLUE评估中基本全面超越BERT
和RoBERTa。
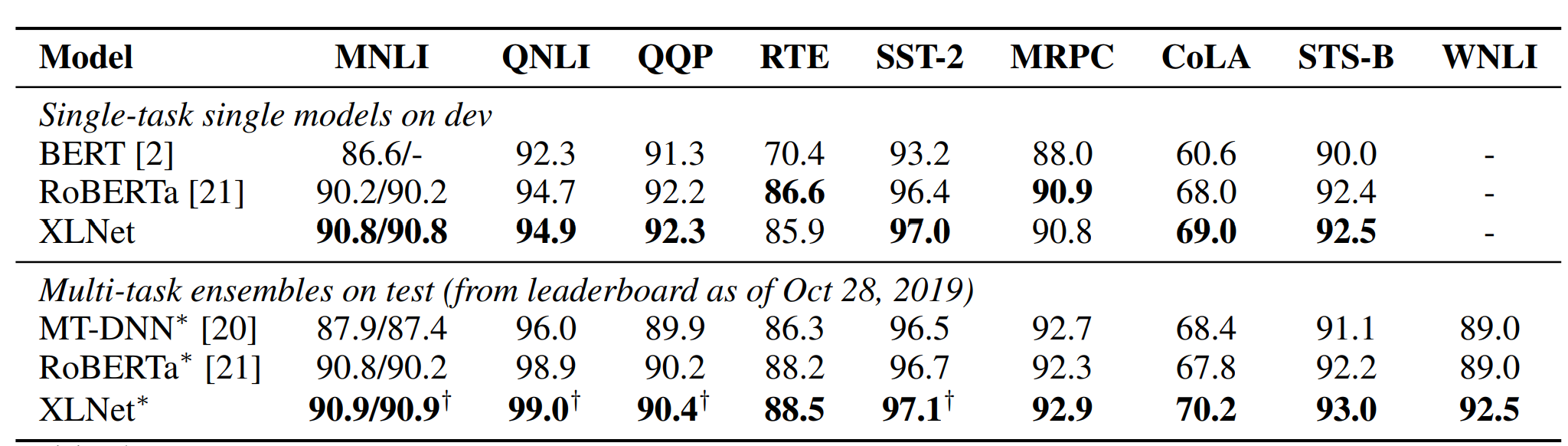
当然以上效果增益部分来自XLNET的乱序语言模型,部分来自Transformer-XL相对位置编码对长文本的效果,部分来自XLNET借鉴了Roberta用了比Roberta略小但远大于BERT的训练数据。不过文中作者做很严谨的对比实验,在相同数据量下XLNET依旧超越BERT和DAE+Transformer-XL。顺便也跟着Roberta验证了NSP对于XLNET任务也是没有效果的...不过我继续持保留意见嘿嘿~
ELECTRA
Electra主要针对MLM只对15%MASK的token进行训练导致训练低效的问题,通过两段式的训练,也实现了在下游任务中和MASK解耦,按论文的效果是只用1/4的时间就可以媲美Bert。
预训练
Eletra的预训练模块由以下两部分构成,分别是生成replace token的Generator,以及判别每个token是否是原始token的Descriminator,我们分别看下各自的实现
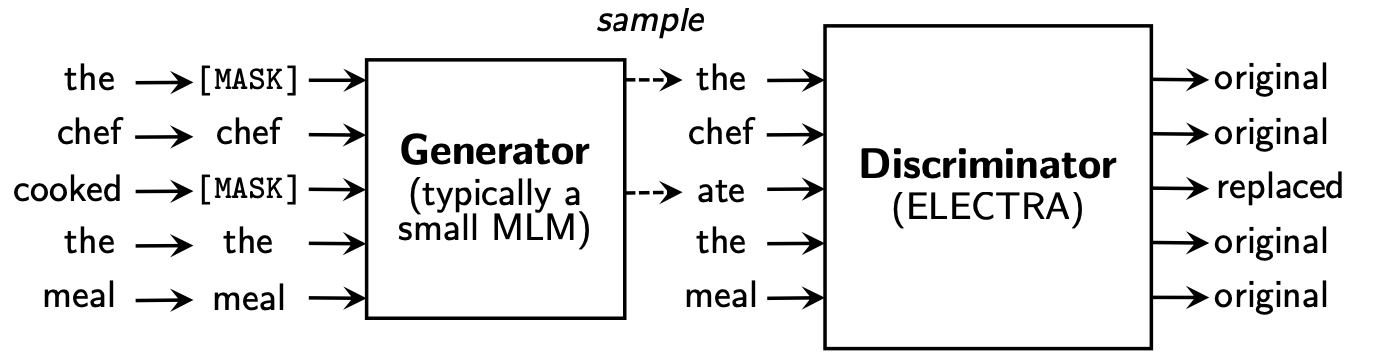
Generator的部分和Bert是基本一致,每次随机MASK15%的token,然后Generator去预测可能的原始token,所以Generator部分就是Bert的MLM任务。
x^{masked} &= REPLACE(x, m, [MASK])\\
\hat{x}_i &\sim p_G(x_i|x^{masked})\\
L_{MLM}(x, \theta_G) &= E(\sum_{i \in m } P_G(x_i|x^{masked}))
\end{align}
\]
Descriminator的输入是Generator的预测结果,判别器负责判断每个token是否是原始的token,注意如果generator预测正确,则该token也是原始token,所以是一个二分类的判别任务
x^{corrupt} &= REPLACE(x, m, \hat{x}) \\
L_{Disc}(x, \theta_D) &= E(\sum_{i=1}^n -I(x^{corrupt}_t = x_t)logD(x^{corrupt},t) - I(x^{corrupt}_t \neq x_t)log(1-D(x^{corrupt},t))
\end{align}
\]
最终的Loss是Generator和Descriminator Loss的结合
\]
看上模型实现很简单,但细节里全是魔鬼。。。我们来细数下Electra实现过程的细节,以及可能的问题
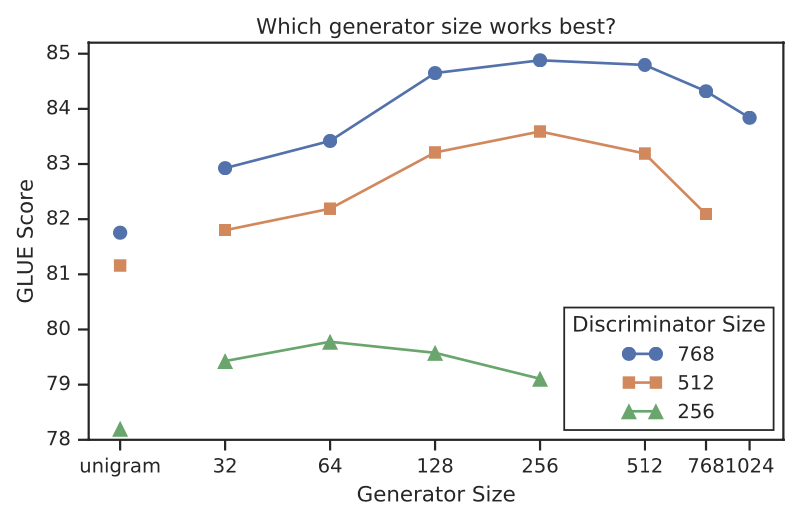
模型大小
作者对比了生成器和判别器之间模型大小对效果的影响,整体上生成器大小在判别器的[1/4,1/2]之间最优,虽然size选择有点玄学,不过部分逻辑是讲的通的,节省空间的目的咱就不提了,无论如何预训练内存都是Bert的一倍多,除此之外
- 生成器的大小决定了判别器的任务难度,感觉一部分Electra能快速拟合的收益,来自生成器生成了更加hard的样本来训练判别器,但是生成器太强就会导致判别器难以拟合
- 生成器决定了判别器输入部分的正负样本比,生成器太强会导致负样本太少
参数共享
生成器和判别器因为以上Size差异的原因,没有共享全部参数,而是共享了Embedding部分,包括token和position embedding的权重。这里共享权重是必要的,因为只有生成器的部分因为要预测token所以会对全Vocab embedding进行更新,而判别器只会对输入部分的token进行更新,考虑下游使用只使用判别器,如果不共享权重,部分低频token可能会存在训练不足的问题。
训练方式
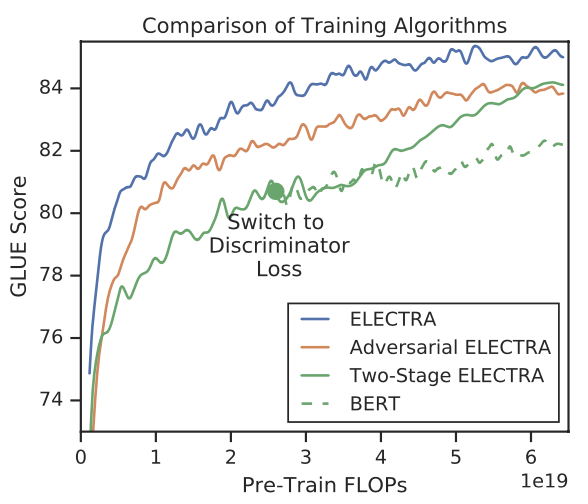
作者对比了几种生成器和判别器的训练方式
- Electra:两个模型一同训练,但是梯度隔离,既判别器的梯度不会回传到生成器
- GAN:用GAN的方式进行训练
- 两阶段:先训练生成器再Freeze生成器训练判别器
效果如下图是Electra>GAN>两阶段。不过后两种训练方式都还有进一步探索的空间,例如两阶段训练的核心是让生成器先训练一段时间来生成更加Hard的样本,但是会和以上模型size选择存在相同的问题就是生成器太强会导致判别器难以拟合,所以什么时候交换到判别任务的时间点可能很关键。而GAN的部分如果只是让生成器最大化判别器的Loss则难以保证生成器生成的样本多样性,不过我对GAN并不太了解这块就先不展开了。
消融实验
作者通过对比不同的训练策略,对Electra的效果进行了归因,大头的效果提升来自于在判别器阶段对所有token进行训练
- Electra 15%:在判别器部分只针对生成器MASK的15%的token进行训练,确实效果大幅下降,这个对比很solid的指出Electra效果的提升大部分来自判别器对all token的训练
- Replace MLM:在Electra15%的基础上把判别器换成MLM,其实也就是把Bert MASK的策略换成了生成器。作者是想通过Replace MLM>Bert来说明MASK的不一致性对Bert存在一定影响,但感觉这到训练后期随着生成器的效果越来越好,MLM似乎还是会存在直接copy输入的feature leakage?
- All-Tokens MLM:在以上Replace MLM的基础上对所有token进行预测,也就是把Electra的二分类变回Vocab的多分类。为了避免在拟合未被替换的token时模型学到直接copy输入这种feature leakage,输出有p的概率是输入的拷贝,有1-p的概率是预测概率。作者想通过这个说明二分类判别器的效果更好,但感觉随机copy避免信息泄漏的方案并不像MASK这样solid?

下游迁移
Electra在下游迁移的时候只使用判别器的部分,因此和MASK实现了解耦。但Electra的判别器也是质疑声音最大的地方,Bert的Embedding Output有丰富的上下文语义的一个前提是每个token的预测都是在全Vocab上做softmax,所以Embedding需要包含相对复杂&多样的信息才能完成这个任务,而Electra只是简单的二分类任务,对Embedding表征信息的要求要低的多。所以实践中被吐槽在NER这类对输入Embedding信息量有高要求的任务,以及更加复杂的文本理解任务上Electra表现并不好。
整体上Electra两段式的训练方式去和MASK解耦,对全token进行训练提高训练效率,以及用生成器做进行类似数据增强的操作是相对有亮点的地方,不过把MLM替换成二分类的判别器的选择,以及Electra的训练方式还是值得再进一步深入研究的~
BERT手册相关论文和博客详见BertManual
Reference
- XLNet: Generalized Autoregressive Pretraining for Language Understanding
- ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
- 李Rumor,谈谈我对ELECTRA源码放出的看法,https://zhuanlan.zhihu.com/p/112813856
- 苏剑林. (Oct. 29, 2020). 《用ALBERT和ELECTRA之前,请确认你真的了解它们 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7846
Bert不完全手册4. 绕开BERT的MASK策略?XLNET & ELECTRA的更多相关文章
- Bert不完全手册7. 为Bert注入知识的力量 Baidu-ERNIE & THU-ERNIE & KBert
借着ACL2022一篇知识增强Tutorial的东风,我们来聊聊如何在预训练模型中融入知识.Tutorial分别针对NLU和NLG方向对一些经典方案进行了分类汇总,感兴趣的可以去细看下.这一章我们只针 ...
- Bert不完全手册6. Bert在中文领域的尝试 Bert-WWM & MacBert & ChineseBert
一章我们来聊聊在中文领域都有哪些预训练模型的改良方案.Bert-WWM,MacBert,ChineseBert主要从3个方向在预训练中补充中文文本的信息:词粒度信息,中文笔画信息,拼音信息.与其说是推 ...
- Bert不完全手册1. 推理太慢?模型蒸馏
模型蒸馏的目标主要用于模型的线上部署,解决Bert太大,推理太慢的问题.因此用一个小模型去逼近大模型的效果,实现的方式一般是Teacher-Stuent框架,先用大模型(Teacher)去对样本进行拟 ...
- Bert不完全手册2. Bert不能做NLG?MASS/UNILM/BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场 ...
- Bert不完全手册3. Bert训练策略优化!RoBERTa & SpanBERT
之前看过一条评论说Bert提出了很好的双向语言模型的预训练以及下游迁移的框架,但是它提出的各种训练方式槽点较多,或多或少都有优化的空间.这一章就训练方案的改良,我们来聊聊RoBERTa和SpanBER ...
- Bert不完全手册5. 推理提速?训练提速!内存压缩!Albert
Albert是A Lite Bert的缩写,确实Albert通过词向量矩阵分解,以及transformer block的参数共享,大大降低了Bert的参数量级.在我读Albert论文之前,因为Albe ...
- Bert不完全手册8. 预训练不要停!Continue Pretraining
paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks GitHub: https://github.com ...
- Bert不完全手册9. 长文本建模 BigBird & Longformer & Reformer & Performer
这一章我们来唠唠如何优化BERT对文本长度的限制.BERT使用的Transformer结构核心在于注意力机制强大的交互和记忆能力.不过Attention本身O(n^2)的计算和内存复杂度,也限制了Tr ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- BERT总结:最先进的NLP预训练技术
BERT(Bidirectional Encoder Representations from Transformers)是谷歌AI研究人员最近发表的一篇论文:BERT: Pre-training o ...
随机推荐
- java笔记——面向对象
1.概述:面向对象是基于面向过程的编程思想 举例:把大象装进冰箱 2.开发:不断的创建对象,使用对象,指挥对象做事情 3.面向对象特征:封装 , 继承 , 多态 4.类和对象的关系: 类是一组相关的属 ...
- 每天5分钟复习OpenStack(十)Ceph 架构
在很多关于Ceph的文章中,通常会介绍一堆概念.虽然这些概念很重要,但是对于一个新手来说,同时接受太多的概念实际上很难消化.因此,在阅读本章节时要保持轻松的心情,只需要对所有的概念有个了解就可以了,因 ...
- Excel表格函数公式出现溢出怎么办?
Excel是一款广泛使用的电子表格软件,它可以帮助我们进行各种计算.数据分析与处理等操作.在使用Excel时,我们通常需要使用到各种函数公式来完成不同的任务.然而,在使用函数公式时有时会出现" ...
- The request is not allowed by the user agent or the platform in the current context, possibly because the user denied permission,iphone手机video标签报错
The request is not allowed by the user agent or the platform in the current context, possibly becaus ...
- AtCoder_abc328
A - Not Too Hard 题目链接 题目大意 给出\(N\)个数(\(S_1\) \(S_2\)...\(S_n\))和一个\(X\),输出所有小于等于\(X\)的\(S_i\)之和 解题思路 ...
- nacos 安装和使用
Nacos 是阿里巴巴开源项目,用于构建微服务应用的服务发现.配置管理和服务管理. 在微服务项目中不同模块之间服务调用时,实现服务注册与发现. Nacos 使用: Nacos 是java开发的,依赖 ...
- 初始OpenGL
OpenGL到底是什么? 一般它被认为是一个API,包含一系列操作图形,图像的函数.然而,它并不是一个API,而是Khronos组织制定并维护的规范. OpenGL规定了每个函数如何执行,以及它们的输 ...
- 江西财经大学第一届程序设计竞赛 I 题 小P和小Q
题目链接:https://www.nowcoder.com/acm/contest/115/I 这题目要注意的是!!!pow函数前强制类型转换一定要float !!!一定要是float,double不 ...
- EEPROM M24C64替换AT24C64出现读取数据为0xff情况解决办法
EEPROM M24C64替换AT24C64出现读取数据为0xff情况解决办法 硬件情况 STM32F103CBT6+模拟IIC,主频72MHz,IIC上拉电阻3.3kΩ 出现原因 在IIC停止信号上 ...
- selenium之三种等待,强制等待、隐式等待和显式等待
显式等待 presence_of_element_locatedpresence_of_all_elements_locatedvisibility_of_any_elements_located ...