基于bert-base-chinese训练bert模型(最后附上整体代码)
目录:
一、bert-base-chinese模型下载
二、数据集的介绍
三、完成类的代码
四、写训练方法
五、总源码及源码参考出处
一、bert-base-chinese模型下载
对于已经预训练好的模型bert-base-chinese的下载可以去Hugging face下载,网址是:Hugging Face – The AI community building the future.
打开网址后,选择上面的Model

然后在右下的搜索框输入bert

接着下载自己所需要的模型就可以了,uncase是指不区分大小写。这里作者下载的是bert-base-chinese,用于处理中文。
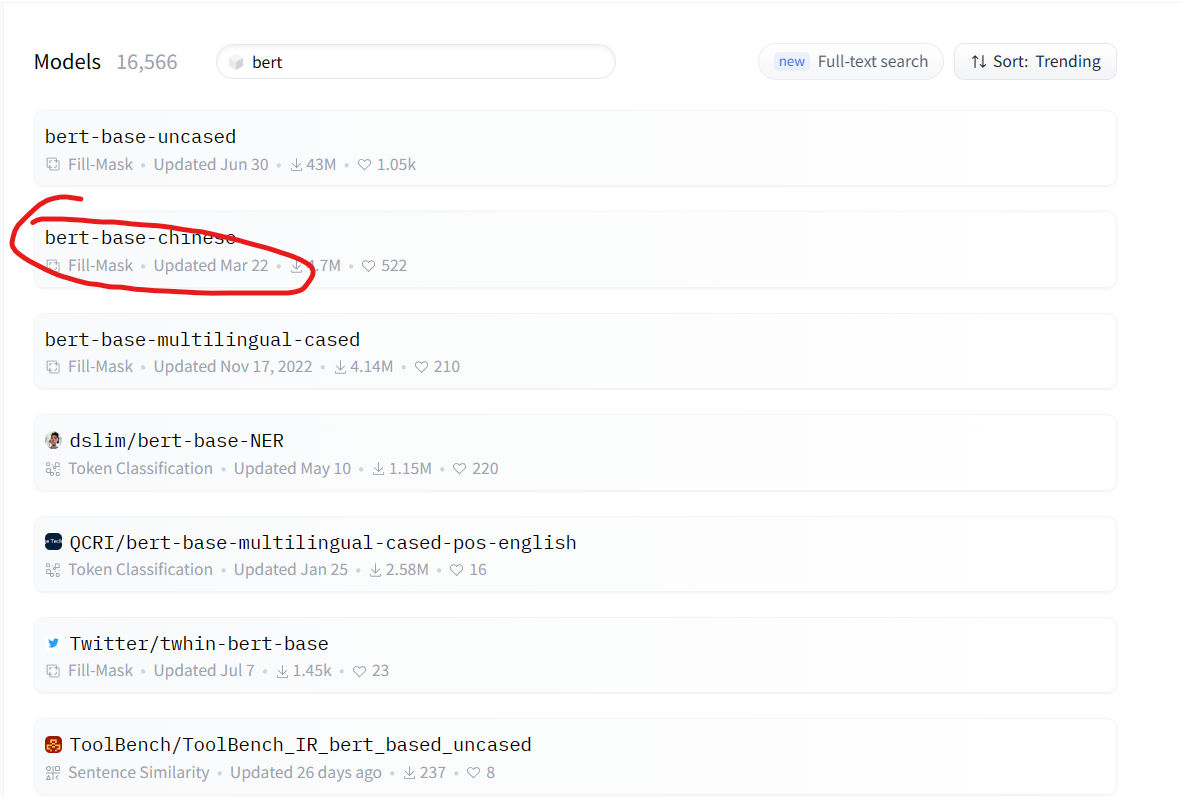
打开后,选择如下图

然后下载下图对应名字的文件即可

二、对于数据集的介绍
我使用的数据集是从DataWhale下载的,我也忘了叫啥[手动滑稽],好像是根据评论来决定是否推荐该店家给访问者
我在这留下我的数据集吧,用百度网盘的
链接:https://pan.baidu.com/s/1AW3CMzuRHD3WQToxL7v0fw
提取码:eq1p
在数据集里面,它是把数据一个一个文本分开的
这里作者给读者提供一代码,可以实现把分散.txt文件合并为一个.txt文本,其实也不难,也可以自己写
import os meragefiledir = '替换成对应文件夹的绝对路径' #获取当前文件夹中的文件名称列表
filenames=os.listdir(meragefiledir) #打开当前目录下的result.txt文件,如果没有则创建
file=open('这就是合并后的文件名','+w', encoding='utf8') #向文件中写入字符
#先遍历文件名
for filename in filenames:
filepath=meragefiledir+'\\'
filepath=filepath+filename
#遍历单个文件,读取行数
for line in open(filepath, encoding='utf8'):
file.writelines(line)
file.write('\n')
#关闭文件
file.close()
然后把文件后缀改为.csv,千万别忘了在数据集的头部加上索引,这个是自己决定的,你可以随意取,只不过下面的代码对应的地方也要改而已,记得是英文符号的逗号哦


前面的1 0代表的是是否推荐该店,后面的是每一家的顾客评论
对于数据集的划分,作者是在写代码前手动划分的,毕竟数据集并不大[狗头]
作者把数据集划分为以下(随便划分即可,毕竟作者不可能用一台小笔记本就跑完所有数据集的,保证每个数据集不少于500个即可,因为作者在后续代码中会取每个数据集的前五百个来训练模型)
三、完成类的代码
注:代码中的地址按自己的实际情况更改
一共要实现两个类,一个是Dataset类,另一个是BertClassifier
接下来实现Dataset,总体来说代码是这样的
from torch.utils.data import DataLoader, Dataset # 先准备分词器和标签
tokenizer = BertTokenizer.from_pretrained('bert-chinese') # 重写Dataset
class Dataset(Dataset):
def __init__(self, df):
self.labels = df['YN']
self.texts = [tokenizer(text,
padding='max_length',
max_length = 512,
truncation=True,
return_tensors="pt")
for text in df['V']] def __len__(self):
return len(self.labels) def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y def classes(self):
# 返回文本标签
return self.labels def get_batch_labels(self, idx):
# 获取标签
return np.array(self.labels[idx]) def get_batch_texts(self, idx):
# 获取inputs
return self.texts[idx]
这个类的主要作用就是把主要数据和标签存入这个类的对象里,然后用这个类的属性和方法去描述这个数据集,例如labels是所有的标签,_len_()是获取数据集长度的方法
在该类里面,_init_(),_len_(),_getiem_()是魔术方法,分别用来构造类的对象的属性,得到Dataset类的对象里面的数据量,取得idx对应的数据的信息,classes()用来获取数据的所有标签,get_batch_labels()和get_batch_texts()分别是用来获取idx对应的标签或主要数据
对于BertClassifier类的重写代码如下
1 from torch import nn
2 from transformers import BertModel
3
4 # 构建实际模型
5 class BertClassifier(nn.Module):
6 def __init__(self, dropout=0.5):
7 super(BertClassifier, self).__init__()
8 self.bert = BertModel.from_pretrained('bert-chinese')
9 self.dropout = nn.Dropout(dropout)
10 self.linear = nn.Linear(768, 5)
11 self.relu = nn.ReLU()
12
13 def forward(self, input_id, mask):
14 _, pooled_output = self.bert(input_ids= input_id,
15 attention_mask=mask,
16 return_dict=False)
17 dropout_output = self.dropout(pooled_output)
18 linear_output = self.linear(dropout_output)
19 final_layer = self.relu(linear_output)
20 return final_layer
在该类里面,其继承自torch.model
写了_init_()魔术方法和forward()
_init_()方法:
第7行,其里面的super是指在创建 BertClassifier 类的新实例时,首先调用其父类的构造函数,需要继承其父类的构造函数的原因是,其父类的构造函数可以默认设定一些值,这样就不用我们自己去把写含有所 有参数的构造函数。
第8行,其代码的作用是从预训练模型库中加载中文BERT模型,并将其赋值给self.bert,也就是导入前文在Huggingface下载预训练模型,里面填的是路径。
第9行,该行代码的作用是为模型添加一个Dropout层,其中dropout是丢弃率,表示在训练过程中随机丢弃神经元的概率。Dropout层通常用于防止过拟合。
第10行,这行代码定义了一个全连接层(线性层),输入特征数为768,输出特征数为5。全连接层通常用于将前一层的输出映射到更复杂的空间。
第11行,这行代码定义了一个ReLU激活函数层。ReLU函数的特征是,小于零的输入,会得到输出为0,如若输入大于零,者输出输入。
forward()方法:
第14行,input_ids是输入序列的ID,attention_mask是用于遮盖输入序列中的填充符号的掩码(例子:“[CLS] 你好,世界! 这个序列包含了一个填充符号。 [MASK]”,[MASK]就是掩码,需要掩码的原因是在输入数据时,数据长短不一,通常会填充一些符号来使所有输入长度一致),return_dict是一个布尔值,表示是否返回每个标记的隐藏状态。函数的第一个返回值是每个输入标记的隐藏状态,第二个返回值是整个句子的隐藏状态。如果return_dict为True,则还返回每个标记的隐藏状态。该行代码的主要是接受整个句子的状态,以便用于句子分类。
第17行,是使用dropout()来把pooled_output正则化,以防止过拟合。
第18行,是把正则化后的数据放入全连接层
第19行,是把全连接层的输出通过ReLU函数进行转化
四、写训练函数
代码如下
1 from torch.optim import Adam
2 from tqdm import tqdm
3
4 def train(model, train_data, val_data, learning_rate, epochs):
5 # 处理数据
6 # 通过Dataset类获取训练和验证集
7 train, val = Dataset(train_data), Dataset(val_data)
8 # DataLoader根据batch_size获取数据,训练时选择打乱样本
9 train_dataloader = DataLoader(train, batch_size=2,shuffle=True)
10 val_dataloader = DataLoader(val, batch_size=2)
11
12 # 判断是否使用GPU
13 use_cuda = torch.cuda.is_available()
14 device = torch.device("cuda" if use_cuda else "cpu")
15
16 # 定义损失函数和优化器
17 criterion = nn.CrossEntropyLoss()
18 optimizer = Adam(model.parameters(), lr=learning_rate)
19
20 if use_cuda:
21 model = model.cuda()
22 criterion = criterion.cuda()
23
24 # 开始进入训练循环
25 for epoch_num in range(epochs):
26 # 定义两个变量,用于存储训练集的准确率和损失
27 total_acc_train = 0
28 total_loss_train = 0
29 # 进度条函数tqdm
30 for train_input, train_label in tqdm(train_dataloader):
31
32 train_label = train_label.to(device)
33 mask = train_input['attention_mask'].to(device)
34 input_id = train_input['input_ids'].squeeze(1).to(device)
35 # 通过模型得到输出
36 output = model(input_id, mask)
37 # 计算损失
38 batch_loss = criterion(output, train_label)
39 total_loss_train += batch_loss.item()
40 # 计算精度
41 acc = (output.argmax(dim=1) == train_label).sum().item()
42 total_acc_train += acc
43 # 模型更新
44 model.zero_grad()
45 batch_loss.backward()
46 optimizer.step()
47 # ------ 验证模型 -----------
48 # 定义两个变量,用于存储验证集的准确率和损失
49 total_acc_val = 0
50 total_loss_val = 0
51 # 不需要计算梯度
52 with torch.no_grad():
53 # 循环获取数据集,并用训练好的模型进行验证
54 for val_input, val_label in val_dataloader:
55 # 如果有GPU,则使用GPU,接下来的操作同训练
56 val_label = val_label.to(device)
57 mask = val_input['attention_mask'].to(device)
58 input_id = val_input['input_ids'].squeeze(1).to(device)
59
60 output = model(input_id, mask)
61
62 batch_loss = criterion(output, val_label)
63 total_loss_val += batch_loss.item()
64
65 acc = (output.argmax(dim=1) == val_label).sum().item()
66 total_acc_val += acc
67
68 print(
69 f'''Epochs: {epoch_num + 1}
70 | Train Loss: {total_loss_train / len(train_data): .3f}
71 | Train Accuracy: {total_acc_train / len(train_data): .3f}
72 | Val Loss: {total_loss_val / len(val_data): .3f}
73 | Val Accuracy: {total_acc_val / len(val_data): .3f}''')
在这个方法里面有五个参数,分别是:预训练好的模型,训练集,测试集,学习率(一般的级数都是十的负五次方)和训练次数。
而方法有三个大块:数据处理,调用GPU或CPU,训练模型。
首先是数据处理。先把传进来的dataframe类型数据转成dataset类型,也就是我们在上文写的第一个类。然后把dataset类型的数据作为参数传入dataloader的实例里面,dataloader的作用是把传入的数据自动分成一个个batch(即将数据分成多个小组,每个小组里面有batch_size个数据,在使用时,它会每次抛出一组数据,直到抛完。用dataloader是因为可以很方便的生成迭代数据)。
其次是是否使用GPU。13行是查看电脑是否有可用的GPU,如果有则返回True,反之就是False。14行是决定张量是放在GPU还是CPU,optimizer = Adam(model.parameters(), lr=learning_rate)创建了一个Adam优化器对象,其中model.parameters()返回一个迭代器,里面包含了模型中所有可训练的参数,也就是要在后续训练中不断迭代的数据。20、21、22行是实现把模型和损失函数移到GPU上面(如果存在)
最后也是最重要的训练模型时间了。这里把代码拿出来来讲
1 # 开始进入训练循环
2 for epoch_num in range(epochs):
3 # 定义两个变量,用于存储训练集的准确率和损失
4 total_acc_train = 0
5 total_loss_train = 0
6 # 进度条函数tqdm
7 for train_input, train_label in tqdm(train_dataloader):
8
9 train_label = train_label.to(device)
10 mask = train_input['attention_mask'].to(device)
11 input_id = train_input['input_ids'].squeeze(1).to(device)
12 # 通过模型得到输出
13 output = model(input_id, mask)
14 # 计算损失
15 batch_loss = criterion(output, train_label)
16 total_loss_train += batch_loss.item()
17 # 计算精度
18 acc = (output.argmax(dim=1) == train_label).sum().item()
19 total_acc_train += acc
20 # 模型更新
21 model.zero_grad()
22 batch_loss.backward()
23 optimizer.step()
24 # ------ 验证模型 -----------
25 # 定义两个变量,用于存储验证集的准确率和损失
26 total_acc_val = 0
27 total_loss_val = 0
28 # 不需要计算梯度
29 with torch.no_grad():
30 # 循环获取数据集,并用训练好的模型进行验证
31 for val_input, val_label in val_dataloader:
32 # 如果有GPU,则使用GPU,接下来的操作同训练
33 val_label = val_label.to(device)
34 mask = val_input['attention_mask'].to(device)
35 input_id = val_input['input_ids'].squeeze(1).to(device)
36
37 output = model(input_id, mask)
38
39 batch_loss = criterion(output, val_label)
40 total_loss_val += batch_loss.item()
41
42 acc = (output.argmax(dim=1) == val_label).sum().item()
43 total_acc_val += acc
44
45 print(
46 f'''Epochs: {epoch_num + 1}
47 | Train Loss: {total_loss_train / len(train_data): .3f}
48 | Train Accuracy: {total_acc_train / len(train_data): .3f}
49 | Val Loss: {total_loss_val / len(val_data): .3f}
50 | Val Accuracy: {total_acc_val / len(val_data): .3f}''')
首先是把控制训练次数也就是模型迭代次数的epochs设为循环次数,控制模型训练的次数(过低过高都会造成过拟合)。
第一个步骤没什么好说的
然后是用训练集来训练模型
tqdm进度条函数怎么用可以上网搜,主要是用来实现把训练进度可视化,to(device)是把数据传到指定设备(CPU或GPU)。
1、得到输出
想要通过模型得到输出的话是直接传入input_id和mask即可,input_id代表的是经过分词器处理后得到的数据。
2、获取损失值和精确值
计算损失是用前面定义的损失函数criterion()来计算的,然后下一行的.item()是用来把包含一个张量数据提取出标量来。计算精确度中,output,argmax(dim=0)会返回预测值,判断是否与原标签相等后,sum()会把True和False相加起来。他们都是通过累加来把每一小组的损失值和精确值加入到总损失值和总精确值。
3、更新模型
model.zero_grad()将模型中的梯度缓存清零,以便开始新的一轮反向传播。
batch_loss.backward()对损失函数进行反向传播,计算每个参数的梯度。
optimizer.step()根据计算出的梯度更新模型参数。在每个参数上调用该函数会将该参数向其最优值移动一步。
当进度条函数的循环完成后,就来到了验证模型的代码了
同样,定义变量没什么好说的
不需要计算梯度是因为这是验证集用来验证模型的,不用更新模型什么的,接下来的思路与什么训练集训练模型的一样
最后就是输出这个模型在训练集和验证集上面的精确值和损失值
EPOCHS = 3
model = BertClassifier()
LR = 1e-5
train(model, _train, _val, LR, EPOCHS)
最后的最后 ,我们的长征已经来到最后了,直接设参数,调用train方法,最后模型训练王成!!!!
注意,本文并未实现模型的保存!!!
五、总源码及源码参考出处
我参考了这位大佬的代码:保姆级教程,用PyTorch和BERT进行文本分类 - 知乎 (zhihu.com)
# 导入所需库
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import DataLoader, Dataset
from transformers import BertTokenizer, BertForSequenceClassification, AdamW # 准备数据集 # 先准备分词器和标签
tokenizer = BertTokenizer.from_pretrained('bert-chinese') #定义一个类
class Dataset(Dataset):
def __init__(self, df):
self.labels = df['YN']
self.texts = [tokenizer(text,
padding='max_length',
max_length = 512,
truncation=True,
return_tensors="pt")
for text in df['V']] def __len__(self):
return len(self.labels) def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y def classes(self):
# 返回文本标签
return self.labels def get_batch_labels(self, idx):
# 获取一批标签
return np.array(self.labels[idx]) def get_batch_texts(self, idx):
# 获取一批inputs
return self.texts[idx] from torch import nn
from transformers import BertModel # 构建实际模型
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-chinese')
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, 5)
self.relu = nn.ReLU() def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id,
attention_mask=mask,
return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer from torch.optim import Adam
from tqdm import tqdm def train(model, train_data, val_data, learning_rate, epochs):
##处理数据
# 通过Dataset类获取训练和验证集
train, val = Dataset(train_data), Dataset(val_data)
# DataLoader根据batch_size获取数据,训练时选择打乱样本
train_dataloader = DataLoader(train,
batch_size=2,
shuffle=True)
val_dataloader = DataLoader(val, batch_size=2) # 判断是否使用GPU
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu") # 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate) if use_cuda:
model = model.cuda()
criterion = criterion.cuda() # 开始进入训练循环
for epoch_num in range(epochs):
# 定义两个变量,用于存储训练集的准确率和损失
total_acc_train = 0
total_loss_train = 0
# 进度条函数tqdm
for train_input, train_label in tqdm(train_dataloader): train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
# 通过模型得到输出
output = model(input_id, mask)
# 计算损失
batch_loss = criterion(output, train_label)
total_loss_train += batch_loss.item()
# 计算精度
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
# 模型更新
model.zero_grad()
batch_loss.backward()
optimizer.step()
# ------ 验证模型 -----------
# 定义两个变量,用于存储验证集的准确率和损失
total_acc_val = 0
total_loss_val = 0
# 不需要计算梯度
with torch.no_grad():
# 循环获取数据集,并用训练好的模型进行验证
for val_input, val_label in val_dataloader:
# 如果有GPU,则使用GPU,接下来的操作同训练
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device) output = model(input_id, mask) batch_loss = criterion(output, val_label)
total_loss_val += batch_loss.item() acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc print(
f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train_data): .3f}
| Train Accuracy: {total_acc_train / len(train_data): .3f}
| Val Loss: {total_loss_val / len(val_data): .3f}
| Val Accuracy: {total_acc_val / len(val_data): .3f}''') # 获得数据集,并拆分为训练集和测试集
_train = pd.read_csv(
'C:\\Users\\xie zhou yao\\bert\\data\\train.csv')
_val = pd.read_csv(
'C:\\Users\\xie zhou yao\\bert\\data\\val.csv')
_test = pd.read_csv(
'C:\\Users\\xie zhou yao\\bert\\data\\test.csv')
_test_handout = pd.read_csv(
'C:\\Users\\xie zhou yao\\bert\\data\\test_handout.csv') _train = _train[0:500]
_val = _val[0:500]
_test = _test[0:500]
_test_handout = _test_handout[0:500]
# 训练模型
EPOCHS = 3
model = BertClassifier()
LR = 1e-5
train(model, _train, _val, LR, EPOCHS)
(ps:该随笔是作者一边学习一边写的,里面有一些自己的拙见,如果有错误或者哪里可以改正的话,还请大家指出并批评改正!)
基于bert-base-chinese训练bert模型(最后附上整体代码)的更多相关文章
- 机器学习02-(损失函数loss、梯度下降、线性回归、评估训练、模型加载、岭回归、多项式回归)
机器学习-02 回归模型 线性回归 评估训练结果误差(metrics) 模型的保存和加载 岭回归 多项式回归 代码总结 线性回归 绘制图像,观察w0.w1.loss的变化过程 以等高线的方式绘制梯度下 ...
- 我爱自然语言处理bert ner chinese
BERT相关论文.文章和代码资源汇总 4条回复 BERT最近太火,蹭个热点,整理一下相关的资源,包括Paper, 代码和文章解读. 1.Google官方: 1) BERT: Pre-training ...
- 基于Caffe训练AlexNet模型
数据集 1.准备数据集 1)下载训练和验证图片 ImageNet官网地址:http://www.image-net.org/signup.php?next=download-images (需用邮箱注 ...
- PocketSphinx语音识别系统语言模型的训练和声学模型的改进
PocketSphinx语音识别系统语言模型的训练和声学模型的改进 zouxy09@qq.com http://blog.csdn.net/zouxy09 关于语音识别的基础知识和sphinx的知识, ...
- 转:从头开始编写基于隐含马尔可夫模型HMM的中文分词器
http://blog.csdn.net/guixunlong/article/details/8925990 从头开始编写基于隐含马尔可夫模型HMM的中文分词器之一 - 资源篇 首先感谢52nlp的 ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 在Java Web中使用Spark MLlib训练的模型
PMML是一种通用的配置文件,只要遵循标准的配置文件,就可以在Spark中训练机器学习模型,然后再web接口端去使用.目前应用最广的就是基于Jpmml来加载模型在javaweb中应用,这样就可以实现跨 ...
- 基于.net的分布式系统限流组件 C# DataGridView绑定List对象时,利用BindingList来实现增删查改 .net中ThreadPool与Task的认识总结 C# 排序技术研究与对比 基于.net的通用内存缓存模型组件 Scala学习笔记:重要语法特性
基于.net的分布式系统限流组件 在互联网应用中,流量洪峰是常有的事情.在应对流量洪峰时,通用的处理模式一般有排队.限流,这样可以非常直接有效的保护系统,防止系统被打爆.另外,通过限流技术手段,可 ...
- 基于word2vec的文档向量模型的应用
基于word2vec的文档向量模型的应用 word2vec的原理以及训练过程具体细节就不介绍了,推荐两篇文档:<word2vec parameter learning explained> ...
- 【模型压缩】MetaPruning:基于元学习和AutoML的模型压缩新方法
论文名称:MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning 论文地址:https://arxiv.org/ ...
随机推荐
- P8933 [JRKSJ R7] 技巧性的块速递推 题解
题目传送门 题意: 简单来说就是一个涂色游戏. 有一个 n×m 的棋盘需要涂色. 每格只能涂黑色或白色两种颜色. 横.竖.斜连续 3 格颜色不能相同. 横.竖.斜连续 4 格颜色不能有 3 个相同颜色 ...
- element-ui中Select 选择器异步加载下一页
场景 当我们使用 Select 选择器存放大量数据的时候. 会发现存在这么2个问题. 1.接口响应时间较长.(因为数据量较多,一次查询的所有)甚至有可能超时. 2.前端下拉框滑动卡顿. 这个时候们如何 ...
- C++调用tensorflow模型
C++ 和python的混合编程 windows + vs 新建一个工程,在工程属性中添加如下的几个 C:\Users\[user_name]\Anaconda3\include C:\Users\[ ...
- WPF 入门笔记 - 04 - 数据绑定 - 补充内容:资源基础
宇宙很大,生活更大,也许以后还有缘相见. --三体 该篇作为[WPF 入门笔记 - 04 - 数据绑定] - Additional Content 章节的补充内容 前言 XAML 资源概述 (WPF ...
- iota简介
当声明枚举类型或定义一组相关常量时,Go语言中的iota关键字可以帮助我们简化代码并自动生成递增的值.本文档将详细介绍iota的用法和行为. iota关键字 iota是Go语言中的一个预定义标识符,它 ...
- 【Java】并行执行任务
在实际的应用上,我们平时需要调用第三方的接口,可能会调用多个接口,串行执行的话, 就需要等待所有的接口调用完成之后才获取到结果,那我们有没有并行的方法的呢? 串行执行 以下是三个接口,假设他们额的执行 ...
- SDK 接入|游戏语音之“范围语音”接入实践
语音是线上游戏用户的主要交流方式,大多数用户会通过游戏中的内置语音功能与其他玩家沟通,而一些用户在游戏没有内置语音功能的情况下,通过其他语音软件与玩家沟通. 并且,游戏语音在玩家开黑时承担着至关重要的 ...
- NumPy(1)-常用的初始化方法
一.NumPy介绍 NumPy是Python中科学计算的基础包,它是一个Python库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,有包括数学.逻辑.形状操作 ...
- GaussDB技术解读丨高级压缩
本文作者|华为云数据库GaussDB首席架构师 冯柯 [背景介绍] 数据压缩与关系数据库的结合,早已不是一个新鲜的话题,当前我们已经看到了各种各样数据库压缩的产品和解决方案.对于GaussDB来说,在 ...
- C语言变量常量
目录 前言 一.数据类型 1.整形 2.浮点型 3.字符型 二.变量的操作 1.变量的创建 2.变量的使用 2.1 变量的赋值 2.2 变量的加减 2.3 变量的隐式类型转换 2.4 强制类型转换 3 ...