[转帖]《Linux性能优化实战》笔记(22)—— 网络丢包问题分析
所谓丢包,是指在网络数据的收发过程中,由于种种原因,数据包还没传输到应用程序中,就被丢弃了。这些被丢弃包的数量,除以总的传输包数,也就是我们常说的丢包率。丢包率是网络性能中最核心的指标之一。丢包通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传,进而还会导致网络延迟增大、吞吐降低。
一、 哪里可能丢包
接下来,我就以最常用的反向代理服务器 Nginx 为例,带你一起看看如何分析网络丢包的问题。执行下面的 hping3 命令,进一步验证 Nginx 是不是可以正常访问。这里我没有使用 ping,是因为 ping 基于 ICMP 协议,而 Nginx 使用的是 TCP 协议。
-
# -c表示发送10个请求,-S表示使用TCP SYN,-p指定端口为80
-
hping3 -c 10 -S -p 80 192.168.0.30
-
-
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=3 win=5120 rtt=7.5 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=4 win=5120 rtt=7.4 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=3.3 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=7 win=5120 rtt=3.0 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=3027.2 ms
-
-
--- 192.168.0.30 hping statistic ---
-
10 packets transmitted, 5 packets received, 50% packet loss
-
round-trip min/avg/max = 3.0/609.7/3027.2 ms
从 hping3 的输出中,我们可以发现,发送了 10 个请求包,却只收到了 5 个回复,50%的包都丢了。再观察每个请求的 RTT 可以发现,RTT 也有非常大的波动变化,小的时候只有 3ms,而大的时候则有 3s。根据这些输出,我们基本能判断,已经发生了丢包现象。可以猜测,3s 的 RTT ,很可能是因为丢包后重传导致的。
那到底是哪里发生了丢包呢?排查之前,我们可以回忆一下 Linux 的网络收发流程,先从理论上分析,哪里有可能会发
生丢包。你不妨拿出手边的笔和纸,边回忆边在纸上梳理,思考清楚再继续下面的内容。在这里,为了帮你理解网络丢包的原理,我画了一张图,你可以保存并打印出来使用
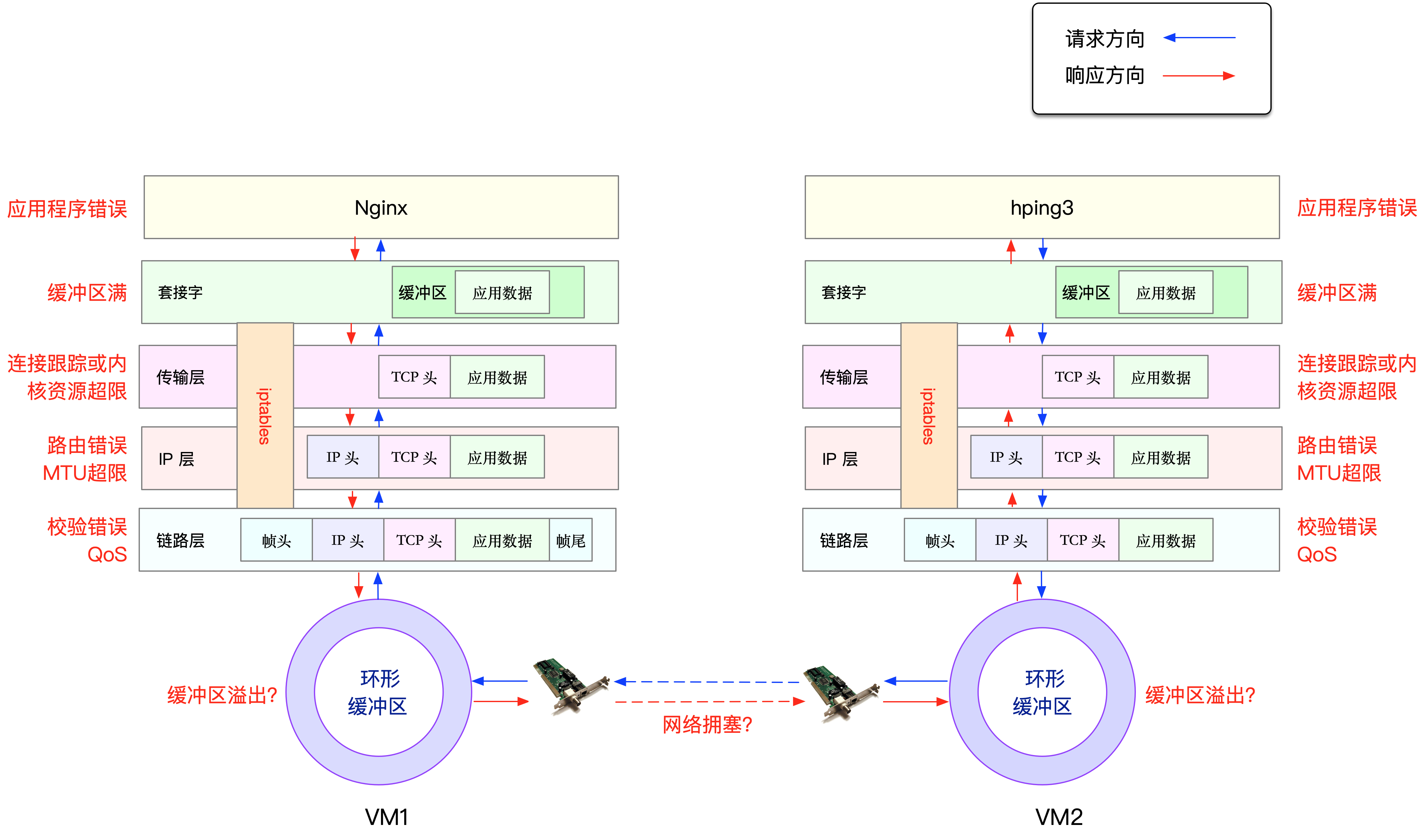
从图中你可以看出,可能发生丢包的位置,实际上贯穿了整个网络协议栈。换句话说,全程都有丢包的可能。
- 在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
- 在网卡收包后,环形缓冲区可能会因为溢出而丢包;
- 在链路层,可能会因为网络帧校验失败、QoS 等而丢包;
- 在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;
- 在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;
- 在套接字层,可能会因为套接字缓冲区溢出而丢包;
- 在应用层,可能会因为应用程序异常而丢包;
- 此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包
当然,上面这些问题,还有可能同时发生在通信的两台机器中。不过,由于我们没对 VM2做任何修改,并且 VM2 也只运行了一个最简单的 hping3 命令,这儿不妨假设它是没有问题的。为了简化整个排查过程,我们还可以进一步假设, VM1 的网络和内核配置也没问题。接下来,就可以从协议栈中,逐层排查丢包问题。
二、 链路层
当链路层由于缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中记录下收发错误的次数。可以通过 ethtool 或者 netstat ,来查看网卡的丢包记录。
-
netstat -i
-
-
Kernel Interface table
-
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
-
eth0 100 31 0 0 0 8 0 0 0 BMRU
-
lo 65536 0 0 0 0 0 0 0 0 LRU
RX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。
TX-OK、TX-ERR、TX-DRP、TX-OVR 也代表类似的含义,只不过是指发送时对应的各个指标。
这里我们没有发现任何错误,说明虚拟网卡没有丢包。不过要注意,如果用 tc 等工具配置了 QoS,那么 tc 规则导致的丢包,就不会包含在网卡的统计信息中。所以接下来,我们还要检查一下 eth0 上是否配置了 tc 规则,并查看有没有丢包。添加 -s 选项,以输出统计信息:
-
tc -s qdisc show dev eth0
-
-
qdisc netem 800d: root refcnt 2 limit 1000 loss 30%
-
Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0)
-
backlog 0b 0p requeues 0
可以看到, eth0 上配置了一个网络模拟排队规则(qdisc netem),并且配置了丢包率为 30%(loss 30%)。再看后面的统计信息,发送了 8 个包,但是丢了 4个。看来应该就是这里导致 Nginx 回复的响应包被 netem 模块给丢了。
既然发现了问题,解决方法也很简单,直接删掉 netem 模块就可以了。执行下面的命令,删除 tc 中的 netem 模块:
tc qdisc del dev eth0 root netem loss 30%
删除后,重新执行之前的 hping3 命令,看看现在还有没有问题:
-
hping3 -c 10 -S -p 80 192.168.0.30
-
-
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=7.9 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=2 win=5120 rtt=1003.8 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=7.6 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=7.4 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=3.0 ms
-
-
--- 192.168.0.30 hping statistic ---
-
10 packets transmitted, 5 packets received, 50% packet loss
-
round-trip min/avg/max = 3.0/205.9/1003.8 ms
不幸的是,从 hping3 的输出中可以看到还是 50% 的丢包,RTT 的波动也仍旧很大,从 3ms 到 1s。显然,问题还是没解决,丢包还在继续发生。不过,既然链路层已经排查完了,我们就继续向上层分析,看看网络层和传输层有没有问题。
三、 网络层和传输层
在网络层和传输层中,引发丢包的因素非常多。不过,其实想确认是否丢包,是非常简单的事,因为 Linux 已经为我们提供了各个协议的收发汇总情况。执行 netstat -s 命令,可以看到协议的收发汇总,以及错误信息:
-
netstat -s
-
#输出
-
Ip:
-
Forwarding: 1 //开启转发
-
31 total packets received //总收包数
-
0 forwarded //转发包数
-
0 incoming packets discarded //接收丢包数
-
25 incoming packets delivered //接收的数据包数
-
15 requests sent out //发出的数据包数
-
Icmp:
-
0 ICMP messages received //收到的ICMP包数
-
0 input ICMP message failed //收到ICMP失败数
-
ICMP input histogram:
-
0 ICMP messages sent //ICMP发送数
-
0 ICMP messages failed //ICMP失败数
-
ICMP output histogram:
-
Tcp:
-
0 active connection openings //主动连接数
-
0 passive connection openings //被动连接数
-
11 failed connection attempts //失败连接尝试数
-
0 connection resets received //接收的连接重置数
-
0 connections established //建立连接数
-
25 segments received //已接收报文数
-
21 segments sent out //已发送报文数
-
4 segments retransmitted //重传报文数
-
0 bad segments received //错误报文数
-
0 resets sent //发出的连接重置数
-
Udp:
-
0 packets received
-
...
-
TcpExt:
-
11 resets received for embryonic SYN_RECV sockets //半连接重置数
-
0 packet headers predicted
-
TCPTimeouts: 7 //超时数
-
TCPSynRetrans: 4 //SYN重传数
-
...
netstat 汇总了 IP、ICMP、TCP、UDP 等各种协议的收发统计信息。不过,我们的目的是排查丢包问题,所以这里主要观察的是错误数、丢包数以及重传数。可以看到,只有 TCP 协议发生了丢包和重传,分别是:
- 11 次连接失败重试(11 failed connection attempts)
- 4 次重传(4 segments retransmitted)
- 11 次半连接重置(11 resets received for embryonic SYN_RECV sockets)
- 4 次 SYN 重传(TCPSynRetrans)
- 7 次超时(TCPTimeouts)
这个结果告诉我们,TCP 协议有多次超时和失败重试,并且主要错误是半连接重置。换句话说,主要的失败,都是三次握手失败。不过,虽然在这儿看到了这么多失败,但具体失败的根源还是无法确定。所以,我们还需要继续顺着协议栈来分析。接下来的几层又该如何分析呢?
四、 iptables
首先,除了网络层和传输层的各种协议,iptables 和内核的连接跟踪机制也可能会导致丢包。所以,这也是发生丢包问题时我们必须要排查的一个因素。
先来看看连接跟踪,要确认是不是连接跟踪导致的问题,只需要对比当前的连接跟踪数和最大连接跟踪数即可。
-
# 主机终端中查询内核配置
-
$ sysctl net.netfilter.nf_conntrack_max
-
net.netfilter.nf_conntrack_max = 262144
-
$ sysctl net.netfilter.nf_conntrack_count
-
net.netfilter.nf_conntrack_count = 182
可以看到,连接跟踪数只有 182,而最大连接跟踪数则是 262144。显然,这里的丢包,不可能是连接跟踪导致的。
接着,再来看 iptables。回顾一下 iptables 的原理,它基于 Netfilter 框架,通过一系列的规则,对网络数据包进行过滤(如防火墙)和修改(如 NAT)。这些 iptables 规则,统一管理在一系列的表中,包括 filter、nat、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。而每张表又可以包括一系列的链,用于对 iptables 规则进行分组管理。
对于丢包问题来说,最大的可能就是被 filter 表中的规则给丢弃了。要弄清楚这一点,就需要我们确认,那些目标为 DROP 和 REJECT 等会弃包的规则,有没有被执行到。可以直接查询 DROP 和 REJECT 等规则的统计信息,看看是否为0。如果不是 0 ,再把相关的规则拎出来进行分析。
-
iptables -t filter -nvL
-
#输出
-
Chain INPUT (policy ACCEPT 25 packets, 1000 bytes)
-
pkts bytes target prot opt in out source destination
-
6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
-
-
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
-
pkts bytes target prot opt in out source destination
-
-
Chain OUTPUT (policy ACCEPT 15 packets, 660 bytes)
-
pkts bytes target prot opt in out source destination
-
6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
从 iptables 的输出中,你可以看到,两条 DROP 规则的统计数值不是 0,它们分别在INPUT 和 OUTPUT 链中。这两条规则实际上是一样的,指的是使用 statistic 模块,进行随机 30% 的丢包。0.0.0.0/0 表示匹配所有的源 IP 和目的 IP,也就是会对所有包都进行随机 30% 的丢包。看起来,这应该就是导致部分丢包的“罪魁祸首”了。
执行下面的两条 iptables 命令,删除这两条 DROP 规则。
-
-
root@nginx:/# iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP
-
root@nginx:/# iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP
再次执行刚才的 hping3 命令,看看现在是否正常
-
hping3 -c 10 -S -p 80 192.168.0.30
-
#输出
-
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=11.9 ms
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=1 win=5120 rtt=7.8 ms
-
...
-
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=15.0 ms
-
-
--- 192.168.0.30 hping statistic ---
-
10 packets transmitted, 10 packets received, 0% packet loss
-
round-trip min/avg/max = 3.3/7.9/15.0 ms
这次输出你可以看到,现在已经没有丢包了,并且延迟的波动变化也很小。看来,丢包问题应该已经解决了。
不过,到目前为止,我们一直使用的 hping3 工具,只能验证案例 Nginx 的 80 端口处于正常监听状态,却还没有访问 Nginx 的 HTTP 服务。所以,不要匆忙下结论结束这次优化,我们还需要进一步确认,Nginx 能不能正常响应 HTTP 请求。我们继续在终端二中,执行如下的 curl 命令,检查 Nginx 对 HTTP 请求的响应:
-
$ curl --max-time 3 http://192.168.0.30
-
curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received
奇怪,hping3 的结果显示Nginx 的 80 端口是正常状态,为什么还是不能正常响应 HTTP 请求呢?别忘了,我们还有个大杀器——抓包操作。看来有必要抓包看看了。
五、 tcpdump
执行下面的 tcpdump 命令,抓取 80 端口的包
-
tcpdump -i eth0 -nn port 80
-
#输出
-
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
-
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
然后,切换到终端二中,再次执行前面的 curl 命令:
-
curl --max-time 3 http://192.168.0.30
-
curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received
等到 curl 命令结束后,再次切换回终端一,查看 tcpdump 的输出:
-
14:40:00.589235 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [S], seq 332257715, win 29200, options [mss 1418,sackOK,TS val 486800541 ecr 0,nop,wscale 7], length 0
-
14:40:00.589277 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [S.], seq 1630206251, ack 332257716, win 4880, options [mss 256,sackOK,TS val 2509376001 ecr 486800541,nop,wscale 7], length 0
-
14:40:00.589894 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 486800541 ecr 2509376001], length 0
-
14:40:03.589352 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [F.], seq 76, ack 1, win 229, options [nop,nop,TS val 486803541 ecr 2509376001], length 0
-
14:40:03.589417 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [.], ack 1, win 40, options [nop,nop,TS val 2509379001 ecr 486800541,nop,nop,sack 1 {76:77}], length 0
从 tcpdump 的输出中,我们就可以看到:
- 前三个包是正常的 TCP 三次握手,这没问题;
- 但第四个包却是在 3 秒以后了,并且还是客户端(VM2)发送过来的 FIN 包,说明客户端的连接关闭了
根据 curl 设置的 3 秒超时选项,你应该能猜到,这是因为 curl 命令超时后退出了。用 Wireshark 的 Flow Graph 来表示,
你可以更清楚地看到上面这个问题:

这里比较奇怪的是,我们并没有抓取到 curl 发来的 HTTP GET 请求。那究竟是网卡丢包了,还是客户端就没发过来呢?
可以重新执行 netstat -i 命令,确认一下网卡有没有丢包问题:
-
netstat -i
-
-
Kernel Interface table
-
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
-
eth0 100 157 0 344 0 94 0 0 0 BMRU
-
lo 65536 0 0 0 0 0 0 0 0 LRU
从 netstat 的输出中,你可以看到,接收丢包数(RX-DRP)是 344,果然是在网卡接收时丢包了。不过问题也来了,为什么刚才用 hping3 时不丢包,现在换成 GET 就收不到了呢?还是那句话,遇到搞不懂的现象,不妨先去查查工具和方法的原理。我们可以对比一下这两个工具:
- hping3 实际上只发送了 SYN 包;
- curl 在发送 SYN 包后,还会发送 HTTP GET 请求。HTTP GET本质上也是一个 TCP 包,但跟 SYN 包相比,它还携带了 HTTP GET 的数据。
通过这个对比,你应该想到了,这可能是 MTU 配置错误导致的。为什么呢?
其实,仔细观察上面 netstat 的输出界面,第二列正是每个网卡的 MTU 值。eth0 的 MTU只有 100,而以太网的 MTU 默认值是 1500,这个 100 就显得太小了。当然,MTU 问题是很好解决的,把它改成 1500 就可以了。
ifconfig eth0 mtu 1500
修改完成后,再切换到终端二中,再次执行 curl 命令,确认问题是否真的解决了:
-
curl --max-time 3 http://192.168.0.30/
-
#输出
-
<!DOCTYPE html>
-
<html>
-
...
-
<p><em>Thank you for using nginx.</em></p>
-
</body>
-
</html>
非常不容易呀,这次终于看到了熟悉的 Nginx 响应,说明丢包的问题终于彻底解决了。
[转帖]《Linux性能优化实战》笔记(22)—— 网络丢包问题分析的更多相关文章
- 深挖计算机基础:Linux性能优化学习笔记
参考极客时间专栏<Linux性能优化实战>学习笔记 一.CPU性能:13讲 Linux性能优化实战学习笔记:第二讲 Linux性能优化实战学习笔记:第三讲 Linux性能优化实战学习笔记: ...
- Linux性能优化实战学习笔记:第四十八讲
一.上节回顾 上一节,我们一起学习了如何分析网络丢包的问题,特别是从链路层.网络层以及传输层等主要的协议栈中进行分析. 不过,通过前面这几层的分析,我们还是没有找出最终的性能瓶颈.看来,还是要继续深挖 ...
- Linux性能优化实战学习笔记:第三十八讲
一.上节回顾 上一节,我们学习了 DNS 性能问题的分析和优化方法.简单回顾一下,DNS 可以提供域名和 IP 地址的映射关系,也是一种常用的全局负载均衡(GSLB)实现方法. 通常,需要暴露到公网的 ...
- Linux性能优化实战学习笔记:第四十七讲
一.上节回顾 上一节,我们梳理了,应用程序容器化后性能下降的分析方法.一起先简单回顾下.容器利用 Linux 内核提供的命名空间技术,将不同应用程序的运行隔离起来,并用统一的镜像,来管理应用程序的依赖 ...
- Linux性能优化实战学习笔记:第四十九讲
一.上节回顾 上一期,我们一起梳理了,网络时不时丢包的分析定位和优化方法.先简单回顾一下.网络丢包,通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传,进而会导致网络延迟增 ...
- 《Linux 性能优化实战—倪朋飞 》学习笔记 CPU 篇
平均负载 指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数 可运行状态:正在使用CPU或者正在等待CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态 (Run ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第三十七讲
一.上节回顾 上一节,我带你一起学习了网络性能的评估方法.简单回顾一下,Linux 网络基于 TCP/IP协议栈构建,而在协议栈的不同层,我们所关注的网络性能也不尽相同. 在应用层,我们关注的是应用程 ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
随机推荐
- 五菱宝骏车机升级教程【嘟嘟桌面或ES文件管理器】
文章来源:https://www.djww.net/607.html 简介 越来越多的汽车厂商自研车机系统,其实就是在原来安卓的基础上加入自己的元素,然后禁用某些功能从而实现禁止用户安装第三方app. ...
- 玩转Sermant开发,开发者能力机制解析
本文分享自华为云社区<开发者能力机制解析,玩转Sermant开发>,作者:华为云开源 . 前言: 在<Sermant框架下的服务治理插件快速开发及使用指南>中带大家一起体验了S ...
- 4种Python中基于字段的不使用元类的ORM实现方法
本文分享自华为云社区<Python中基于字段的不使用元类的ORM实现>,作者: 柠檬味拥抱 . 不使用元类的简单ORM实现 在 Python 中,ORM(Object-Relational ...
- 案例解析丨 Spark Hive 自定义函数应用
摘要:Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数. 1. 简介 Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数.UDF使用场景:输入一行,返回一个结果,一对一, ...
- 数据湖探索DLI新功能:基于openLooKeng的交互式分析
摘要:基于华为开源openLooKeng引擎的交互式分析功能,将重磅发布便于用户构建轻量级流.批.交互式全场景数据湖. 在这个"信息爆炸"的时代,大数据已经成为这个时代的关键词之一 ...
- 测试攻城狮必备技能点!一文带你解读DevOps下的测试技术
[摘要]本文将从DevOps模式下对测试人员的活动的变化,以及常用的测试技术层面进行解读. 项目的软件开发模式主要经历瀑布模型.敏捷开发和DevOps这几个阶段,其中DevOps主要解决开发和运维.运 ...
- WebKit三件套(2):WebKit之JavaScriptCore/V8
WebKit作为一个浏览器引擎,其中Javascript实现包括JavaScriptCore和V8,为了能更全面的了解WebKit,我们需要深入的了解Javascript实现的基本原理.其在WebKi ...
- PNG文件解读(2):PNG格式文件结构与数据结构解读—解码PNG数据
PNG文件识别 之前写过<JPEG/Exif/TIFF格式解读(1):JEPG图片压缩与存储原理分析>,JPEG文件是以,FFD8开头,FFD9结尾,中间存储着以0xFFE0~0xFFEF ...
- DevOps 团队如何防御 API 攻击
在过去,勒索软件是 DevOps 团队常常担心的主要安全威胁.尽管现在勒索软件攻击仍在发生,但随着企业安全防护能力与意识增强,勒索软件造成的安全威胁已不如从前.然而,根据 Gartner 调查显示,A ...
- 火山引擎DataLeap数据血缘技术建设实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap是火山引擎数智平台VeDI旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理 ...