ElasticSearch(一):基本概念
ElasticSearch(一):基本概念
## 基本概念示意图
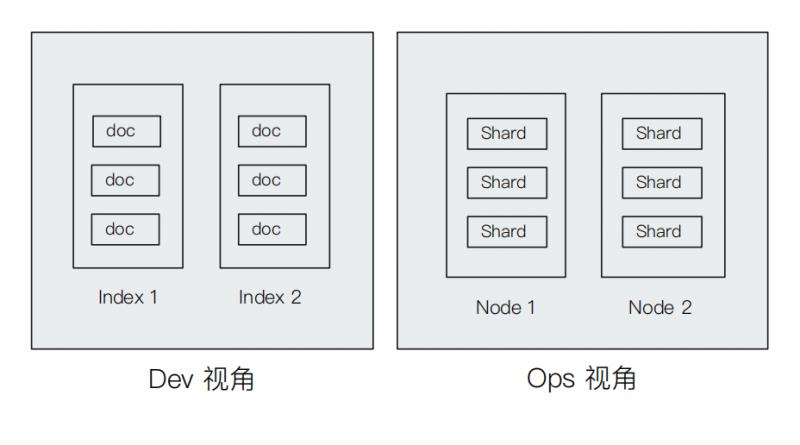
索引与文档更偏向于开发人员的视角,属于逻辑上的一种概念;节点与分片更偏向于运维人员的视角,属于物理上的一种概念。
## 索引
* Index——索引是文档的容器,是一类文档的集合
- Index体现了逻辑空间的概念:每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型
- Shard体现了物理空间的概念:索引中的数据分散在Shard上
* 索引的Mapping与Settings
- Mapping定义文档字段的类型
- Setting定义不同的数据分布
* 索引的不同语意
- 名词:一个Elasticsearch集群中,可以创建很多个不同的索引
- 动词:保存一个文档到Elasticsearch的过程也叫索引(indexing);索引(动词)文档到ElasticSearch的索引(名词)中
- 名词:一个B树索引,一个倒排索引
## 文档(Document)
* Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位。
- 日志文件中的日志项
- 一部电影的具体信息/一张唱片的详细信息
- MP3播放器里的一首歌/一篇PDF文档中的具体内容
* 文档会被序列化成JSON格式,保存在Elasticsearch中
- JSON对象由字段组成
- 每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
* 每个文档都有一个唯一的ID
- 你可以自己指定ID
- 或者通过Elasticsearch自动生成
* 文档的元数据
- `_index`——文档所属的索引名
- `_type`——文档所属的类型名
- `_id`——文档唯一ID
- `_version`——文档的版本信息
- `_scope`——相关性打分
- `_source`——文档的原始JSON数据
## 集群
* ElasticSearch集群实际上是一个分布式系统,而分布式系统需要具备两个特性:
- 高可用性: 服务可用性:允许有节点停止服务;数据可用性:部分节点丢失,不会丢失数据。
- 可扩展性:随着请求量的不断提升,数据量的不断增长,系统可以将数据分布到其他节点,实现水平扩展。
- Elasticsearch的分布式架构
- 不同的集群通过不同的名字来区分,默认名字
elasticsearch - 通过配置文件修改,或者在命令行中
-E cluster.name=geektime进行设定 - 一个集群可以有一个或者多个节点
- 不同的集群通过不同的名字来区分,默认名字
## 节点
* 节点是一个Elasticsearch的实例,本质上就是一个Java进程。
* 每个节点都有名字,可以通过配置文件进行配置,也可以通过命令行进行指定,如:-E node.name=node1。
* 每个节点在启动之后,会被分配一个UID,保存在data目录下。
## 节点类型
* Master-Eligible Node与Master Node
- 每个节点启动之后,默认就是一个Master Eligible节点,当然可以在配置文件中将其禁止,node.master:false。
- Master-Eligible Node可以参加选主流程,成为Master Node。
- 当第一个节点启动时,它会将其选举为Master Node。
- 每个节点都保存了集群状态,但只有Master Node才能修改集群的状态。
* Data Node
- 可以保存数据的节点,负责保存分片数据,在数据扩展上起到至关重要的作用。
* Coordinating Node
- 它通过接受Rest Client的请求,会将请求分发到合适的节点,最终将结果汇集到一起。
- 每个节点都默认起到Coordinating Node的职责
* Hot &Warm Node
- 不同硬件配置的Data Node,来实现Hot &Warm架构,降低集群部署的成本。
* Machine Learning Node
- 负责机器学习的节点,常用来做异常检测。
## 节点类型配置
* 开发环境中一个节点可以承担多种角色。
* 生成环境中,应该设置单一的节点角色
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | 无 | 设置其他类型全部为false |
| machine learning | node.ml | true |
## 分片
* 主分片用于解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点之上。
- 一个主分片是一个运行的Lucene的实例
- 主分片数是在索引创建时指定,后续不允许修改,除非Reindex
* 副本用于解决数据高可用的问题,它是主分片的拷贝。
- 副本分片数可以动态调整
- 增加副本数,在一定程度上可以提高服务的可用性
## 分片的设定
对于生产环境中分片的设定,需要提前做好容量规划,因为主分片数是在索引创建时预先设定的,后续无法修改。
* 分片数设置过小
- 导致后续无法增加节点进行水平扩展。
- 导致分片的数据量太大,数据在重新分配时耗时;
* 分片数设置过大
- 影响搜索结果的相关性打分,影响统计结果的准确性;
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能;
## Index 相关 API
```
#查看索引相关信息
GET kibana_sample_data_ecommerce
查看索引的文档总数
GET kibana_sample_data_ecommerce/_count
查看前10条文档,了解文档格式
POST kibana_sample_data_ecommerce/_search
{
}
_cat indices API
查看indices
GET /_cat/indices/kibana*?v&s=index
查看状态为绿的索引
GET /_cat/indices?v&health=green
按照文档个数排序
GET /_cat/indices?v&s=docs.count:desc
查看具体的字段
GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt
How much memory is used per index?
GET /_cat/indices?v&h=i,tm&s=tm:desc
<br/>
## Cluster相关API
GET _cat/nodes?v
GET /_nodes/es7_01,es7_02
GET /_cat/nodes?v
GET /_cat/nodes?v&h=id,ip,port,v,m
GET _cluster/health
GET _cluster/health?level=shards
GET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flights
GET /_cluster/health/kibana_sample_data_flights?level=shards
cluster state
GET /_cluster/state
cluster get settings
GET /_cluster/settings
GET /_cluster/settings?include_defaults=true
GET _cat/shards
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
ElasticSearch(一):基本概念的更多相关文章
- elasticsearch的核心概念
1.elasticsearch的核心概念 (1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒):基于es执行搜索和分析可以达到秒级 (2) ...
- Elasticsearch系列---Elasticsearch的基本概念及工作原理
基本概念 Elasticsearch有几个核心的概念,花几分钟时间了解一下,有助于后面章节的学习. NRT Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索 ...
- 写给大忙人的Elasticsearch架构与概念(未完待续)
最新版本官方文档https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html文档增删改参考https://www ...
- 图解Elasticsearch的核心概念
本文讲解大纲,分8个核心概念讲解说明: NRT Cluster Node Document&Field Index Type Shard Replica Near Realtime(NRT)近 ...
- 了解一下Elasticsearch的基本概念
一.前文介绍 Elasticsearch(简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进.性能最好的.功能最全的 ...
- ElasticSearch入门-基本概念介绍以及安装
Elasticsearch基本概念 Elasticsearch是基于Lucene的全文检索库,本质也是存储数据,很多概念与传统关系型数据库类似. 传统关系型数据库与Elasticsearch进行概念对 ...
- elasticsearch常用的概念整理
节点node 节点(node)是一个运行着的Elasticsearch实例 集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更,例如新建或删除索引.增加或移除节点等.主节点 ...
- elasticsearch中的概念简述
Near Realtime(NRT) Elasticsearch接近实时.从为一个文档建立索引到可被搜索,正常情况下有1秒延迟. Cluster 一个集群有一个唯一的名字,默认是"elast ...
- Elasticsearch的基本概念和指标
背景 在13年的时候,我开始负责整个公司的搜索引擎.嗯……,不是很牛的那种大项目负责人.而是整个搜索就我一个人做.哈哈. 后来跳槽之后,所经历的团队都用Elasticsearch,基本上和缓存一样,是 ...
- 【elasticsearch】关于elasticSearch的基础概念了解【转载】
转载原文:https://www.cnblogs.com/chenmc/p/9516100.html 该作者本系列文章,写的很详尽 ================================== ...
随机推荐
- 分库分表(5) ---SpringBoot + ShardingSphere 实现分库分表
分库分表(5)--- ShardingSphere实现分库分表 有关分库分表前面写了四篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3. ...
- mapper插入时显示中文
可能是jdbc url需要加characterEncoding=utf-8,例 jdbc:mysql://localhost:3306/smbms?characterEncoding=utf8
- iOS 设备数据管理工具 iMazing v2.10.3 绿色便携版
iMazing 是一款可以帮助用户管理 iOS 设备的软件,功能远远超出 iTunes.iMazing 连接你的 iOS 设备(iPhone. iPad 或 iPod)相连,使用起来也非常的方便.你可 ...
- A Deep Neural Network Approach To Speech Bandwidth Expansion
题名:一种用于语音带宽扩展的深度神经网络方法 作者:Kehuang Li:Chin-Hui Lee 2015年出来的 摘要 本文提出了一种基于深度神经网络(DNN)的语音带宽扩展(BWE)方法.利用对 ...
- Python高级核心技术97讲 ☝☝☝
Python高级核心技术97讲 ☝☝☝ Python高级核心技术97讲 系列教程 学习 教程 Python的标准整数类型是最通用的数字类型.在大多数32位机器上,标准整数类型的取值范围是-2**31 ...
- Java8新特性之Lambda
为什么要Lambda Java8应该是目前最大的一次更新了,更新后我们迎来了很多新特性,其中便包括Lambda表达式,函数式编程的思想正式进入Java,让我们看一个经典案例. 例1 按照两个人的年龄排 ...
- 2019年高级Java程序员面试题汇总
目录 JDK Dubbo Zookeeper Strut2 Spring系列 Redis系列 Mysql系列 Java多线程 消息中间件 线程池 事物 JVM 设计模式 其他 程序设计 基础知识 编程 ...
- fread优化读入
inline char nc() { static const int BS = 1 << 22; static unsigned char buf[BS],*st,*ed; if(st ...
- vue——同一局域网内访问项目
1.想要在手机上访问本地的vue项目,首先要保证手机和电脑处在同一局域网内(连着同一个无线网) 2.将你电脑的ip设置为固定ip(ipconfig查找本地的ip,然后修改它,改为你想变的数字) 3.在 ...
- vue实现简易计算器
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...