scrapy的CrawlSpider类
了解CrawlSpider
踏实爬取一般网站的常用spider,其中定义了一些规则(rule)来提供跟进link的方便机制,也许该spider不适合你的目标网站,但是对于大多数情况是可以使用的。因此,可以以此为七点,根据需求修改部分方法,当然也可以实现自己的spider。
官方文档:http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/spiders.html#crawlspider
CrawlSpider的使用
简单使用
创建爬虫文件:scrapy genspider -t crawl "spider_name" "url"
得到如下目录:
其中spider文件夹中的爬虫文件下的内容如下所示:
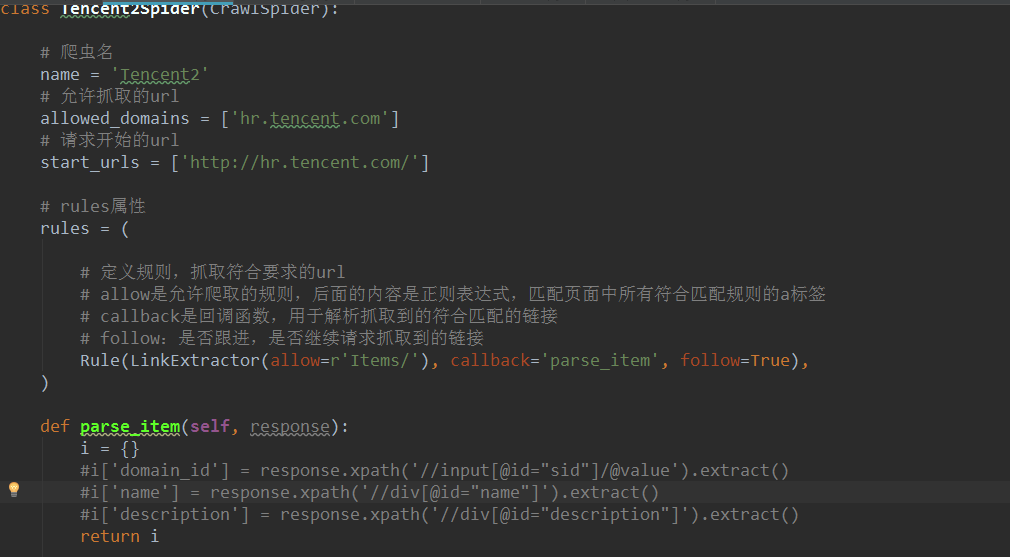
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类中定义了一些规则(rule)来提取跟进link的方便机制,从而爬取的网页中获取link并继续爬取。
方法属性
Name:定义spider的名字
allow_domains:包含了spider允许抓起去的域名列表。
start_url:初始化url列表,当没有指定的url时,spider将从该列表中开始进行爬取。
start_requests(self):该方法返回一个可迭代对象,该对象包含了spider用于抓取的第一个request。
parse(self, resposne):默认的Request对象回调函数,用来处理返回的response,以及生成Items或者Request对象。
使用CralwSpider抓取数据
编写CrawlSpider,抓取腾讯招聘的信息,具体网页分析,见:
http://www.cnblogs.com/pythoner6833/p/9018782.html
具体代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from tencent2.items import Tencent2Item, DetailsItem class Tencent2Spider(CrawlSpider): # 爬虫名
name = 'Tencent2'
# 允许抓取的url
allowed_domains = ['hr.tencent.com']
# 请求开始的url
start_urls = ['https://hr.tencent.com/position.php?'] # rules属性
rules = ( # 定义规则,抓取符合要求的url
# allow是允许爬取的规则,后面的内容是正则表达式,匹配页面中所有符合匹配规则的a标签
# callback是回调函数,用于解析抓取到的符合匹配的链接
# follow:是否跟进,是否继续请求抓取到的链接
Rule(LinkExtractor(allow=r'start=\d+'), callback='parse_tencent', follow=True), #编写匹配详情页的规则,抓取到详情页的链接后不用跟进
Rule(LinkExtractor(allow=r'position_detail\.php\?id=\d+'), callback='parse_detail', follow=False),
) def parse_tencent(self, response):
# 获取页面中招聘信息在网页中位置节点
node_list = response.xpath('//tr[@class="even"] | //tr[@class="odd"]') # 遍历节点,进入详情页,获取其他信息
for node in node_list:
# 实例化,填写数据
item = Tencent2Item() item['position_name'] = node.xpath('./td[1]/a/text()').extract_first()
item['position_link'] = node.xpath('./td[1]/a/@href').extract_first()
item['position_type'] = node.xpath('./td[2]/text()').extract_first()
item['wanted_number'] = node.xpath('./td[3]/text()').extract_first()
item['work_location'] = node.xpath('./td[4]/text()').extract_first()
item['publish_time'] = node.xpath('./td[5]/text()').extract_first() yield item def parse_detail(self, response):
"""
解析详情页数据
:param response:
:return:
"""
item = DetailsItem()
# 从详情页获取工作责任和工作技能两个字段名
item['work_duties'] = ''.join(response.xpath('//ul[@class="squareli"]')[0].xpath('./li/text()').extract())
item['work_skills'] = ''.join(response.xpath('//ul[@class="squareli"]')[1].xpath('./li/text()').extract())
yield item
其他部分,包括items.py和数据保存的pipelines.py里的代码编写和上文中链接里的已解释。
scrapy的CrawlSpider类的更多相关文章
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
- python爬虫入门(八)Scrapy框架之CrawlSpider类
CrawlSpider类 通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl tencent tencent.com CrawSpid ...
- Scrapy的Spider类和CrawlSpider类
Scrapy shell 用来调试Scrapy 项目代码的 命令行工具,启动的时候预定义了Scrapy的一些对象 设置 shell Scrapy 的shell是基于运行环境中的python 解释器sh ...
- scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取: 项目结构与项目3中相同如下图,唯一不同的为book.py文件 crawlspider类的爬虫文件book的 ...
- Scrapy框架-CrawlSpider
目录 1.CrawlSpider介绍 2.CrawlSpider源代码 3. LinkExtractors:提取Response中的链接 4. Rules 5.重写Tencent爬虫 6. Spide ...
- 13.CrawlSpider类爬虫
1.CrawlSpider介绍 Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spider类的设 ...
- 全栈爬取-Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- Scrapy框架——CrawlSpider爬取某招聘信息网站
CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页, 而Craw ...
- python爬虫之Scrapy框架(CrawlSpider)
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpi ...
随机推荐
- Java开发中的23中设计模式详解(一)工厂方法模式和抽象工厂模式
一.设计模式的分类 总体来说设计模式分为三大类: 创建型模式,共五种:工厂方法模式.抽象工厂模式.单例模式.建造者模式.原型模式. 结构型模式,共七种:适配器模式.装饰器模式.代理模式.外观模式.桥接 ...
- egg-sequelize --- nodejs
项目 egg + sequelize + mysql2 项目结构 配置 安装模块 npm install --save egg-sequelize npm install --save egg-cor ...
- 再整理:Visual Studio Code(vscode)下的通用C语言环境搭建
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://www.cnblogs.com/czlhxm/p/11794743.ht ...
- 闯缸鱼:看懂python如何实现整数加和,再决定是否自学编程
玩鱼缸的新手都知道有一种鱼叫"闯缸鱼",皮实好养,帮助新手判断鱼缸环境是否准备好.这篇笔记,最初用来解答一个编程新手的疑问,后来我发现,整理一下也可当做有兴趣自学python 编程 ...
- Netty学习篇④-心跳机制及断线重连
心跳检测 前言 客户端和服务端的连接属于socket连接,也属于长连接,往往会存在客户端在连接了服务端之后就没有任何操作了,但还是占用了一个连接:当越来越多类似的客户端出现就会浪费很多连接,netty ...
- MongoDB 谨防索引seek的效率问题
目录 背景 初步分析 索引seeks的原因 优化思路 小结 声明:本文同步发表于 MongoDB 中文社区,传送门: http://www.mongoing.com/archives/27310 背景 ...
- js 将base64转为图片
var imgurl = response.data; $(".codeimg").attr('src','data:image/png;base64,'+imgurl); var ...
- 如何学习python,个人的一些简单见解
什么是重要的东西 思考学习是一个什么样的过程 我们每个人都学习过数学,肯定都知道数学的学习过程是什么,我们刚开始学习数学的时候会学习一些简单的公式和概念,比如加减乘除,随着学习的深入,我们发现在大学之 ...
- 关于Python中的yield的理解
生成器:yield表达式构成的函数就是生成器:每一个生成器都是一个迭代器(但是迭代器不一定是生成器).return就是迭代器: yield的功能类似于return,不同之处在于它返回的是生成器. 什么 ...
- JavaScript文档对象模型(DOM)——DOM核心操作
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标记语言(HTML或XML)的标准编程接口. W3C已经定义了一系列DOM接口,通过这些DOM接口可 ...