Learning Markov Clustering Networks for Scene Text Detection
Learning Markov Clustering Networks for Scene Text Detection

论文下载:https://arxiv.org/pdf/1805.08365v1.pdf
1方法概述
1.1主要思路
这篇提出了一种新的框架 - 马尔可夫聚类网络(MCN),用于任意大小和方向的文本对象。MCN通过首先将图像转换为随机流图(SFG),随机流图对目标的局部相关性和语义信息进行编码,然后在该图上执行马尔可夫聚类来预测实例级边界框。
1.2文章亮点
·提出了一种自底向上的场景文本检测方法,通过在随机流程图上执行马尔可夫聚类将局部预测组合成对象边界框
·马尔可夫聚类被认为是一组特殊的可微分神经网络层,并且从图像数据开发了用于学习图簇的端到端训练方法
·所提出的推断过程与GPU完全并行,并实现了帧速率为34 FPS的实时处理能力
1.3主要流程
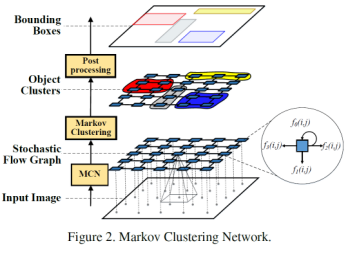
·整个网络训练流程如下:
·输入图像进入马尔科夫网络后,得到一张原图的1/16随机流图。
·这个流图是由节点和流值组成。每一个节点都与f0、f1、f2、f3四个流值相连。f1、f2、f3是输出流,表示节点之间的连接强度,f0是自环流,表示背景区域。这四个值都是正数且和为1。由于节点在原始图像中具有对应的空间关系,所以目标的大小和方向可以由节点和流值表示,且对目标的大小和方向的变化不敏感。
·接着在这张随机流图上进行科尔科夫聚类操作,得到每一簇代表一个区域,这个目标簇通过后处理得到bbox。
2 方法细节
·MC
·马尔科夫聚类算法具体可以参考这两个博客:
https://blog.csdn.net/u010376788/article/details/50187321
https://www.cnblogs.com/magle/p/7672957.html
·这篇文章的MC过程如下面两图所示
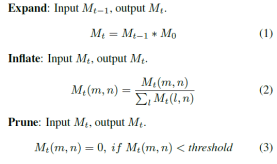

·Flow Labels
上述得到的是输入图像如何进行图聚类,下面介绍在GT上是如何标记簇。
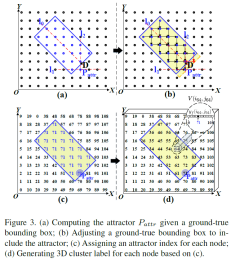
·给定一个GT边界框,将相同边界框内的节点定义为一个簇,我们根据GT边界框的几何结构计算该簇的吸引子。:
·首先计算D的坐标,D是边界框长轴和下边短边之间的交点。
·其次,绘制一条水平线l1,它穿过边界框区域中具有最低Y坐标的节点,以及l2从D经过最近节点的垂直线。最后,l1和l2之间的交点节点被确定为吸引子。为了确保吸引子在边界框中,我们调整边界框的大小,这可能会引入新的节点。
·接着为这张图中的每个节点分配一个索引,在边界框内的索引值把他替换成他们吸引子的索引,图中吸引子的索引是71,所以这个框内的所有节点的索引都是71。其他背景区域的吸引子就是他们本身。
·然后再将这个二维分布矩阵变成三维分布矩阵。它的第三维是一个one-hot向量,吸引子的位置标记为1,其他为0。比如节点64,因为它的吸引子是71,所以one-hot向量的下标为71的地方标记为1,其他为0。背景区域的吸引子就是他们本身。最终这个矩阵yf就是簇label。
·Pipeline
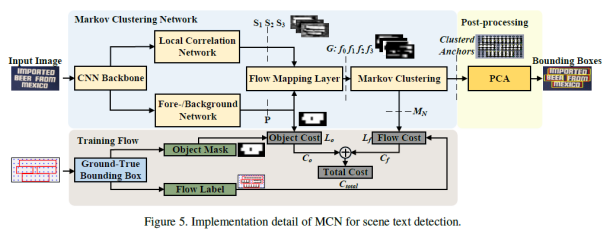
·整个推理过程的结构如上图所示:MCN的主干是由预训练好的VGG16,最后一层是conv5_3,输出一张原图1/16的特征图。接着一个分支经过LCN得到局部相关测量S1,S2,S3,这三个特征图表示的是当前图像块和它的底部、左侧、右侧之间的关联。所以LCN预测的是相邻图像块之间的空间和语义信息。另外一个分支进入FBN,得到的是对象存在的概率P。然后将这四张图输入到FML,转换为带有四个流值得随机流图。接下来在随机流图上进行马尔科夫聚类操作得到簇,再经过后处理之后得到bbox。下面的输入是GT,经过这两个处理后将GT边界框分别转换为节点的对象掩码y0和流标签yf,随后进行Loss的计算。LCN、FBN、FML、PCA、Training Flow下文会详细介绍。
·LCN
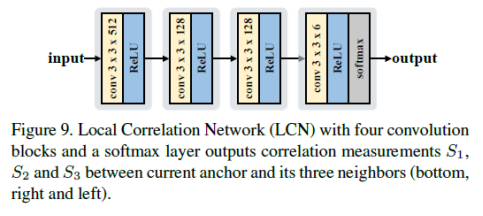
·LCN如上图所示:网络比较简单,是四个卷积块和一个softmax组成的网络,得到的是三个相关性测量值S1,S2,S3,表示当前点与其相邻点的语义和空间相关性。
·FBN

·FBN如上图所示:它是由特征金字塔、二维RNN以及一个分类器组成。输入图像经过四个带有2*2池化层的卷积块处理,分辨率变成1/32,1/64,1/128,1/256。这些特征图经过解卷积操作后和输入一起进行层加法运算。FPN的输出被送到二维递归神经网络。这个二维RNN是由两个双向RNN组成,分别对特征图的行和列进行操作后再合并,最后输入一个具有两层卷积层和softmax层得到最后的区域分类结果P。
·FMN
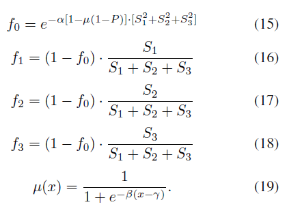
·上面两个网络得到的P和S1,2,3经过流映射层,得到f0,f1,f2,f3四个流值。映射公式如上图所示,这个μ是一个开关函数,通过控制f0来控制其他相关强度,这里的α,β,γ三个参数可以通过训练学习到。
·PCA

·经过流映射层之后,得到一张随机流图,进行马尔科夫聚类操作后,得到簇聚类,这些簇聚类需要经过后处理,映射回原图,并得到bbox。给定簇内的点坐标im,jm,计算原图的坐标ωm,然后得到一个簇的坐标集,计算他们的特征向量θ1、θ2和特征值λ1,λ2,计算边界框的四个顶点坐标c1,c2,c3,c4。Φ是簇的中心,A是缩放因子,等于1.75,μstride为16,μoffset为8。
·Loss Function
·计算过程如图所示:,将groundtruth边界框转换为节点方式对象掩码y0和流标签yf,用于计算对象损失L0和对象成本C0,流损失Lf 和流成本Cf。总成本Ctotal = Co + Cf
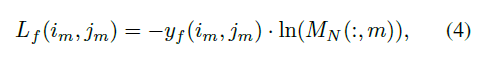
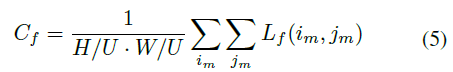
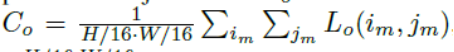

·
·Gradient of MC
·上图中每个节点表示Markov聚类中的一个操作,并且有向边显示整个聚类过程中的数据流以进行N次迭代。操作的输出数据标记在边缘的上方,相应的梯度g(· )标记如下。从计算图中,随机流的成本函数Cf的梯度在M0中通过使用下面的链式法则推导出来:
3 实验结果


·在ICDAR15的数据集效果不是很好,文章分析是因为这个数据集大多数文本的尺寸小于节点密度16*16,所以这些对象预测的流较弱,导致检测不准确。

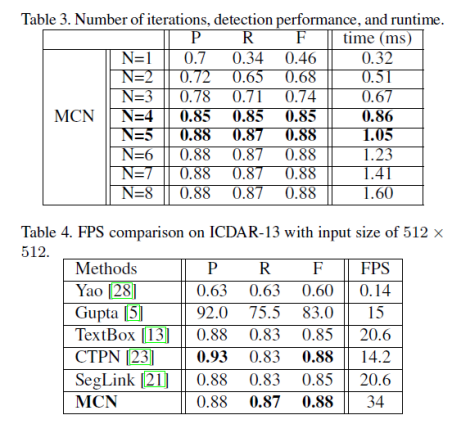
·MCN通过N=5达到最佳性能,并且仅需0.86 ms即可计算出簇。与整个推理时间超过25毫秒相比,这个计算时间可以忽略不计。
·文章中还将FPS中的推理速度与ICDAR13数据集上最近提出的场景文本检测方法进行比较。如表4所示,本文方法得到了最先进的性能,并且使用1.5×速度方法优于现有的方法。
4 总结和收获
·将图聚类用到网络模型当中
·马尔科夫聚类是一种可微的神经网络层
·不使用NMS,可以达到34FPS的实时处理速度
Learning Markov Clustering Networks for Scene Text Detection的更多相关文章
- 【论文速读】XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection
XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection 作者和代码 caffe代码 关键词 ...
- 【论文速读】Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrappi ...
- XiangBai——【CVPR2018】Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
XiangBai——[CVPR2018]Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentat ...
- 论文阅读(Xiang Bai——【arXiv2016】Scene Text Detection via Holistic, Multi-Channel Prediction)
Xiang Bai--[arXiv2016]Scene Text Detection via Holistic, Multi-Channel Prediction 目录 作者和相关链接 方法概括 创新 ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- 论文速读(Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection)
Chuhui Xue--[arxiv2019]MSR_Multi-Scale Shape Regression for Scene Text Detection 论文 Chuhui Xue--[arx ...
- 【论文速读】Fangfang Wang_CVPR2018_Geometry-Aware Scene Text Detection With Instance Transformation Network
Han Hu--[ICCV2017]WordSup_Exploiting Word Annotations for Character based Text Detection 作者和代码 caffe ...
- 【论文速读】Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation[2018-CPVR]
方法概述 该方法用一个端到端网络完成文字检测整个过程——除了基础卷积网络(backbone)外,包括两个并行分支和一个后处理.第一个分支是通过一个DSSD网络进行角点检测来提取候选文字区域,第二个分支 ...
- Scene Text Detection(场景文本检测)论文思路总结
任意角度的场景文本检测论文思路总结共同点:重新添加分支的创新更突出场景文本检测基于分割的检测方法 spcnet(mask_rcnn+tcm+rescore) psenet(渐进扩展) mask tex ...
随机推荐
- webStrom快捷键快速创建React组件
1. rcc + tab键 - - 用ES6模块系统创建一个React组件类 2. rccp + tab键 - - 创建一个带有PropTypes和ES6模块系统的React组件类 3. rcfc + ...
- 你的 Java 并发程序 Bug,100% 是这几个原因造成的
可见性问题 可见性是指一个线程对共享变量进行了修改,其他线程能够立马看到该共享变量更新后的值,这视乎是一个合情合理的要求,但是在多线程的情况下,可能就要让你失望了,由于每个 CPU 都有自己的缓存,每 ...
- 五分钟后,你将学会在SpringBoot项目中如何集成CAT调用链
买买买结算系统 一年一度的双十一购物狂欢节就要到了,又到剁手党们开始表演的时刻了.当我们把种草很久的商品放入购物车以后,点击"结算"按钮时,就来到了买买买必不可少的结算页面了.让我 ...
- 轻量级CNN模型mobilenet v1
mobilenet v1 论文解读 论文地址:https://arxiv.org/abs/1704.04861 核心思想就是通过depthwise conv替代普通conv. 有关depthwise ...
- iOS开发高级分享 - Unread的下拉式选单
解构革命的演变 背景 2013年中期,RSS世界遭受了沉重打击.谷歌宣布,他们(*的*)RSS订阅服务,[谷歌阅读器],是被关闭了.有了它,数以百万计的声音突然惊恐地大叫,并突然保持沉默. 使用量下降 ...
- 你真的了解java序列化吗
问:可是我这个实体类,没有实现序列化那个接口,也能存到数据库,这是为什么呢? 想不通!我是用的注解和hibernate框架弄的! 难道说不实现序列化接口也能保存数据?不应该啊. @Entity pub ...
- django-模板之for标签(十)
- (二)django--带APP的网站
1.打开终端,进入到django项目,创建APP应用:python manage.py startapp news 2.在settings.py中进行注册 3.在news下新建views.py,和ur ...
- 设计模式C++描述----19.命令(Command)模式
一. 举例说明 我们知道,在多线程程序中,多个用户都给系统发 Read 和 Write 命令.这里有几点需要说明: 1. 首先明确一点,所有的这些 Read 和 Write 命令都是调用一个库函数. ...
- DRF框架(django rest framework)
1,DRF框架? Django REST framework 框架是一个用于构建Web API 的强大而又灵活的工具.通常简称为DRF框架 或 REST framework. Django REST ...