复习-java集合简记
1.集合概述
ava集合类存放于 java.util 包中,是一个用来存放对象的容器。
集合只能保存对象(实际上也是保存对象的引用变量),Java主要由两个接口派生而出:Collection和Map,继承树如下:

Map体系结构树
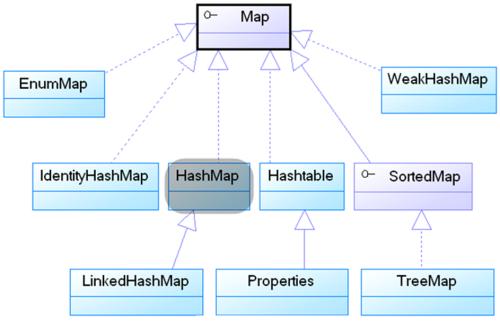
2 Collection集合常用方法:
//我们这里将 ArrayList集合作为 Collection 的实现类
Collection collection = new ArrayList(); //添加元素
collection.add("Tom");
collection.add("Bob"); //删除指定元素
collection.remove("Tom"); //删除所有元素
Collection c = new ArrayList();
c.add("Bob");
collection.removeAll(c); //检测是否存在某个元素
collection.contains("Tom"); //判断是否为空
collection.isEmpty(); //利用增强for循环遍历集合
for(Object obj : collection){
System.out.println(obj);
}
//利用迭代器 Iterator
Iterator iterator = collection.iterator();
while(iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
遍历集合可以通过Iterator或者foreach遍历集合
3 Set接口
hashset是最常用的实现类
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
Set treeSet = new TreeSet();
treeSet.add(1); //添加一个 Integer 类型的数据 treeSet.add("a"); //添加一个 String 类型的数据 System.out.println(treeSet); //会报类型转换异常的错误* 自动排序:添加自定义对象的时候,必须要实现 Comparable 接口,并要覆盖 compareTo(Object obj) 方法来自定义比较规则
如果 this > obj,返回正数 1
如果 this < obj,返回负数 -1
如果 this = obj,返回 0 ,则认为这两个对象相等
* 定制排序: 创建 TreeSet 对象时, 传入 Comparator 接口的实现类. 要求: Comparator 接口的 compare 方法的返回值和 两个元素的 equals() 方法具有一致的返回值
public class TreeSetTest {
public static void main(String[] args) { Person p1 = new Person(1); Person p2 = new Person(2); Person p3 = new Person(3); Set<Person> set = new TreeSet<>(new Person()); set.add(p1); set.add(p2); set.add(p3); System.out.println(set); //结果为[1, 2, 3] }}class Person implements Comparator<Person>{ public int age; public Person(){} public Person(int age){ this.age = age; } @Override /*** * 根据年龄大小进行排序 */ public int compare(Person o1, Person o2) { // TODO Auto-generated method stub if(o1.age > o2.age){ return 1; }else if(o1.age < o2.age){ return -1; }else{ return 0; } } @Override public String toString() { // TODO Auto-generated method stub return ""+this.age; }}EnumSet类
enum Season {
SPRING, SUMMER, FALL, WINTER
}
public class EnumSetTest {
public static void main(String[] args) {
//创建一个EnumSet集合,集合元素就是Season枚举类的全部枚举值
EnumSet es1 = EnumSet.allOf(Season.class);
//输出[SPRING, SUMMER, FALL, WINTER]
System.out.println(es1);
//创建一个EnumSet空集合,指定其集合元素是Season类的枚举值
EnumSet es2 = EnumSet.noneOf(Season.class);
//输出[]
System.out.println(es2);
//手动添加两个元素
es2.add(Season.WINTER);
es2.add(Season.SPRING);
//输出[Spring, WINTER]
System.out.println(es2);
//以指定枚举值创建EnumSet集合
EnumSet es3 = EnumSet.of(Season.SUMMER, Season.WINTER);
//输出[SUMMER, WINTER]
System.out.println(es3);
//创建一个包含两个枚举值范围内所有枚举值的EnumSet集合
EnumSet es4 = EnumSet.range(Season.SUMMER, Season.WINTER);
//输出[SUMMER, FALL, WINTER]s
System.out.println(es4);
//新创建的EnumSet集合元素和es4集合元素有相同的类型
//es5集合元素 + es4集合元素=Season枚举类的全部枚举值
EnumSet es5 = EnumSet.complementOf(es4);
System.out.println(es5);
//创建一个集合
Collection c = new HashSet();
c.clear();
c.add(Season.SPRING);
c.add(Season.WINTER);
//复制Collection集合中的所有元素来创建EnumSet集合
EnumSet es = EnumSet.copyOf(c);
//输出es
System.out.println(es);
c.add("111");
c.add("222");
//下面代码出现异常,因为c集合里的元素不是全部都为枚举值
es = EnumSet.copyOf(c);
}
}
4 List接口
由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高
怎么记呢?我们可以想象:
数组就像身上编了号站成一排的人,要找第10个人很容易,根据人身上的编号很快就能找到。但插入、删除慢,要望某个位置插入或删除一个人时,后面的人身上的编号都要变。当然,加入或删除的人始终末尾的也快。
链表就像手牵着手站成一圈的人,要找第10个人不容易,必须从第一个人一个个数过去。但插入、删除快。插入时只要解开两个人的手,并重新牵上新加进来的人的手就可以。删除一样的道理。
2、除此之外,List 接口遍历还可以使用普通 for 循环进行遍历,指定位置添加元素,替换元素等等。
//产生一个 List 集合,典型实现为 ArrayList
List list = new ArrayList();
//添加三个元素
list.add("Tom");
list.add("Bob");
list.add("Marry");
//构造 List 的迭代器
Iterator it = list.iterator();
//通过迭代器遍历元素
while(it.hasNext()){
Object obj = it.next();
//System.out.println(obj);
} //在指定地方添加元素
list.add(2, 0); //在指定地方替换元素
list.set(2, 1); //获得指定对象的索引
int i=list.indexOf(1);
System.out.println("索引为:"+i); //遍历:普通for循环
for(int j=0;j<list.size();j++){
System.out.println(list.get(j));
}
5 Map
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
复习-java集合简记的更多相关文章
- 复习java基础第三天(集合:Collection、Set、HashSet、LinkedHashSet、TreeSet)
一.Collection常用的方法: Java 集合可分为 Set.List 和 Map 三种体系: Set:无序.不可重复的集合. List:有序,可重复的集合. Map:具有映射关系的集合. Co ...
- 【java集合框架源码剖析系列】java源码剖析之java集合中的折半插入排序算法
注:关于排序算法,博主写过[数据结构排序算法系列]数据结构八大排序算法,基本上把所有的排序算法都详细的讲解过,而之所以单独将java集合中的排序算法拿出来讲解,是因为在阿里巴巴内推面试的时候面试官问过 ...
- Java集合必会14问(精选面试题整理)
前言:把这段时间复习的关于集合类的东西整理出来,特别是HashMap相关的一些东西,之前都没有很注意1.7 ->> 1.8的变化问题,但后来发现这其实变化挺大的,而且很多整理的面试资料都没 ...
- Java 集合系列(一)
Java集合系列文章将以思维导图为主要形式来展示知识点,让零碎的知识形成体系. 这篇文章主要介绍的是[Java 集合的基本知识],即Java 集合简介. 毕业出来一直使用 PHP 进行开发,对于大学所 ...
- 第二十六节:复习Java语言基础-Java的概述,匿名对象,封装,构造函数
Java基础 Java语言概述 Java语言 语言 描述 javaee 企业版 javase 标准版 javame 小型版 JDK JDK(Java开发工具包) Java语言 语言 Java语言 Ja ...
- Java集合详解4:一文读懂HashMap和HashTable的区别以及常见面试题
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java 集合 | 红黑树 | 前置知识
一.前言 0tnv1e.png 为啥要学红黑树吖? 因为笔者最近在赶项目的时候,不忘抽出时间来复习 Java 基础知识,现在准备看集合的源码啦啦.听闻,HashMap 在 jdk 1.8 的时候,底层 ...
- 入职大厂,齐姐精选的 9 道 Java 集合面试题
Java 集合框架其实都讲过了,有一篇讲 Collection 的,有一篇讲 HashMap 的,那没有看过的小伙伴快去补下啦,文末也都有链接:看过的小伙伴,那本文就是检测学习成果的时候啦 今天这篇文 ...
- Java 集合看这一篇就够了
大家好,这里是<齐姐聊数据结构>系列之大集合. 话不多说,直接上图: Java 集合,也称作容器,主要是由两大接口 (Interface) 派生出来的: Collection 和 Map ...
随机推荐
- Newtonsoft—Json.NET常用方法简述
Json.NET常用方法汇总(可解决日常百分之90的需求) 0.Json.NET基础用法 首先去官网下载最新的Newtonsoft.Json.dll(也可以使用VS自带的NuGet搜索Json.NET ...
- 解决SpringBatch/Cloud Task的SafeMode下的报错问题
问题描述 一般公司都有DBA,DBA极有可能开启了Safe mode,也就是不支持不带索引条件过滤的update操作. 而Spring Batch /Cloud Task就有一张表 JOB_SEQ或者 ...
- 委托事件(jQuery)
<div class="content"> <ul> <li>1</li> <li>2</li> <l ...
- Python环境的搭建(windows系统)
1.首先访问http://www.python.org/download/去下载最新的python版本. 2.安装下载包,一路next. 3.为计算机添加安装目录搭到环境变量,如图把python的安装 ...
- Method Not Allowed (GET): /boxuegos/index/ 错误
1,Method Not Allowed (GET) 请求方法不被允许, 错误原因:我调用的是index这个方法,但是我上面定义了一个空的子路由,所以页面加载不了,控制台出现Method Not Al ...
- Java 生成在线二维码 以Base64返回前端、或者写入到本地磁盘
思路 现阶段遇到这样一个问题,在原有的产品上加入线下优惠券模式,用户领取优惠券以后,获取到一个唯一的ID作为领取凭证,但是在线下用扫码枪进行扫码的时候,总不能让人手动输入吧 于是乎就想出了一个办法,后 ...
- 明解C语言 入门篇 第四章答案
练习4-1 #include <stdio.h> int main(void) { int no; int x; do{ printf("请输入一个整数:"); sca ...
- maven项目部署到tomcat方法
今天记录下,maven项目部署到服务器的过程 1.首先在ide中里将自己的maven项目打包 mvn clean install 2. 看是否需要修改war包的名字,如果要修改,就用命令 mv xxx ...
- 记 Maven 本地仓库埋坑之依赖包为何不能用
记一次 Maven 本地仓库埋坑之 Verifying Availability 背景 某 Java 后端项目使用 maven 构建,因为某些原因,某些依赖库下载不了,直接找其它人索要了他电脑上的 m ...
- Nginx 的请求处理流程,你了解吗?
之前我们已经讲解了 Nginx 的基础内容,接下来我们开始介绍 Nginx 的架构基础. 为什么我们要讨论 Nginx 的架构基础? 因为 Nginx 运行在企业内网的最外层也就是边缘节点,那么他处理 ...