Scrapy的下载中间件
下载中间件
简介
下载器,无法执行js代码,本身不支持代理
下载中间件用来hooks进Scrapy的request/response处理过程的框架,一个轻量级的底层系统,用来全局修改scrapy的request和response
scrapy框架中的下载中间件,是实现了特殊方法的类,scrapy系统自带的中间件被放在DOWNLOADER_MIDDLEWARES_BASE设置中
用户自定义的中间件需要在DOWNLOADER_MIDDLEWARES中进行设置,该设置是一个dict,键是中间件类路径,值是中间件的顺序,是一个正整数0-1000.越小越靠近引擎

API
每个中间件都是Python的一个类,它定义了以下一个或多个方法
process_request(request,spider) 处理请求,对于通过中间件的每个请求调用此方法
process_response(request, response, spider) 处理响应,对于通过中间件的每个响应,调用此方法
process_exception(request, exception, spider) 处理请求时发生了异常调用
from_crawler(cls,crawler )
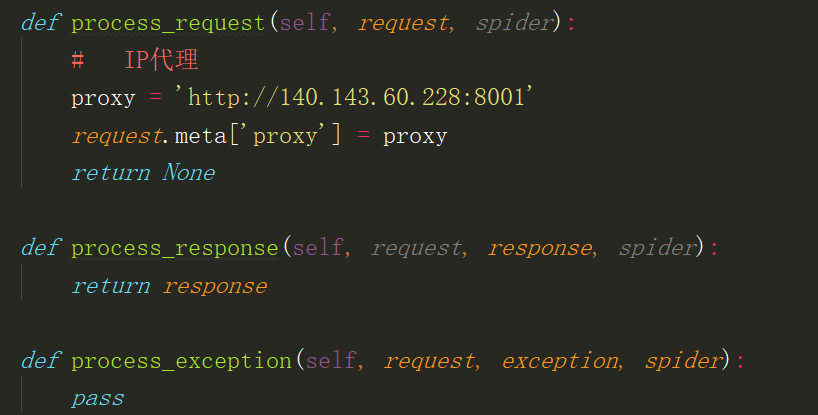
常用内置中间件
CookieMiddleware 支持cookie,通过设置COOKIES_ENABLED 来开启和关闭
HttpProxyMiddleware HTTP代理,通过设置request.meta['proxy']的值来设置
UserAgentMiddleware 与用户代理中间件
其它中间件参见官方文档:https://docs.scrapy.org/en/latest/topics/downloader-middleware.html

常用设置
设置的优先级
命令行选项(优先级最高)
设置per-spider
项目设置模块
各命令默认设置
默认全局设置(低优先级)
常用项目设置
BOT_NAME 项目名称
CONCURRENT_ITEMS item 处理最大并发数,默认100
CONCURRENT_REQUESTS 下载最大并发数
CONCURRENT_REQUESTS_PER_DOMAIN 单个域名最大并发数
CONCURRENT_REQUESTS_PER_IP 单个ip最大并发数

Scrapy的下载中间件的更多相关文章
- Scrapy——5 下载中间件常用函数、scrapy怎么对接selenium、常用的Setting内置设置有哪些
Scrapy——5 下载中间件常用的函数 Scrapy怎样对接selenium 常用的setting内置设置 对接selenium实战 (Downloader Middleware)下载中间件常用函数 ...
- UA池 代理IP池 scrapy的下载中间件
# 一些概念 - 在scrapy中如何给所有的请求对象尽可能多的设置不一样的请求载体身份标识 - UA池,process_request(request) - 在scrapy中如何给发生异常的请求设置 ...
- python之scrapy模块下载中间件
知识点 使用方法: 编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启 Downloader Middlewares默认的方 ...
- 爬虫2.5-scrapy框架-下载中间件
目录 scrapy框架-下载中间件 scrapy框架-下载中间件 middlewares.py中有两个类,一个是xxSpiderMiddleware类 一个是xxDownloaderMiddlewar ...
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- python 全栈开发,Day138(scrapy框架的下载中间件,settings配置)
昨日内容拾遗 打开昨天写的DianShang项目,查看items.py class AmazonItem(scrapy.Item): name = scrapy.Field() # 商品名 price ...
- Python爬虫框架Scrapy实例(四)下载中间件设置
还是豆瓣top250爬虫的例子,添加下载中间件,主要是设置动态Uesr-Agent和代理IP Scrapy代理IP.Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控 ...
- scrapy下载中间件,UA池和代理池
一.下载中间件 框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请 ...
- scrapy基础知识之下载中间件使用案例:
1. 创建middlewares.py文件. Scrapy代理IP.Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控制,我们在settings.py同级目录下创建m ...
随机推荐
- js的动态表格的增删改查思路
1. 首先我们要知道,动态添加,肯定不是 在页面上写死得,而是通过js调用循环放入到页面上的,我们在写动态表格的时候不要先着急写,我们第一步要做的就是构思,要把自己的逻辑先弄清楚,不然的话,前面是好写 ...
- webpack动态加载打包chunk命名
最近,遇到复杂h5页面开发,为了优化H5首屏加载速度,想到使用按需加载的方式,减少首次加载的JavaScript文件体积,于是将处理过程在这里记录一下,涉及到的主要是以下三点: 使用Webpack如何 ...
- Mysql的安装、配置、优化
Mysql的安装.配置.优化 安装步骤 1.先单击中的安装文件,如果是win7系统,请选择以管理员的方式运行. 2.大概需要30秒的时间,开始进入安装界面.请先把标红的打勾,好进行下一步的动作. 3. ...
- Apollo 分布式配置中心(补充)
1. Namespace 1.1. 什么是Namespace Namespace是配置项的集合,类似于一个配置文件的概念. Apollo在创建项目的时候,都会默认创建一个“application ...
- What happened when new an object in JVM ?
原文链接:https://www.javaspring.net/java/what-happened-when-new-an-object-in-jvm I. Introduction As you ...
- 深入浅出 PHP SPL(PHP 标准库)(转)
一.什么是spl库? SPL是用于解决典型问题(standard problems)的一组接口与类的集合. 此扩展只能在php 5.0以后使用,从PHP 5.3.0 不再被关闭,会一直有效.成为php ...
- How to: Use Both Entity Framework and XPO in a Single Application 如何:在单个应用程序中同时使用实体框架和 XPO
This topic demonstrates how to create a simple XAF application that uses both the Entity Framework ( ...
- 基于titanic数据集预测titanic号旅客生还率
数据清洗及可视化 实验内容 数据清洗是数据分析中非常重要的一部分,也最繁琐,做好这一步需要大量的经验和耐心.这门课程中,我将和大家一起,一步步完成这项工作.大家可以从这门课程中学习数据清洗的基本思路以 ...
- Abusing SUDO Advance for Linux Privilege Escalation
Index What is SUDO? Scenario. Sudoer FIle Syntax. Exploiting SUDO zip tar strace tcpdump nmap scp ex ...
- Linux学习入门-------------------------VMvare与镜像的安装与配置
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_39038465/article/d ...