Day13- Python基础13 生产者与消费者模型,进程
本节内容:
1:生产者与消费者
2:进程调用两种
3:进程Process的方法
4:进程间的通信1 queue 队列
5:进程间的通信2 Pipe 管道
6:进程间的数据共享 Managers
7:进程同步
8:进程池
9:协程
1.生产者与消费者
生产者消费者模型:
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这就像,在餐厅,厨师做好菜,不需要直接和客户交流,而是交给前台,而客户去饭菜也不需要不找厨师,直接去前台领取即可,这也是一个结耦的过程。
import queue
import threading
import time q = queue.Queue() class Producer(threading.Thread):
def __init__(self,name):
threading.Thread.__init__(self)
self.name = name def run(self):
for i in range(,):
print('making....')
print("priducer %s make %s 包子."%(self.name,i))
q.put(i) ## 放进队列之后
q.task_done() ##发送一个信号,通知q里面有数据了
time.sleep() class Customer(threading.Thread):
def __init__(self,name):
threading.Thread.__init__(self)
self.name = name def run(self):
while : ##一直在吃
q.join() ##当有信号来了我就去包子笼去取,
data = q.get()
print("customer %s eat %s baozi"%(self.name,data)) p = Producer("小当家")
c = Customer("B君")
p.start()
c.start()

2.进程的调用
进程的调用和线程的调用是一样的,有直接调用和类调用两种方式。
调用方式1:直接调用
from multiprocessing import Process
import time
def f(name):
time.sleep(1)
print('hello', name,time.ctime()) if __name__ == '__main__':
p_list=[]
for i in range(3):
p = Process(target=f, args=('alvin',))
p_list.append(p)
p.start()
for i in p_list:
p.join()
print('end')
调用方式2:类调用
from multiprocessing import Process
import time class MyProcess(Process):
def __init__(self):
super(MyProcess, self).__init__()
#self.name = name def run(self):
time.sleep(1)
print ('hello', self.name,time.ctime()) if __name__ == '__main__':
p_list=[]
for i in range(3):
p = MyProcess()
p.start()
p_list.append(p) for p in p_list:
p.join() print('end')
3.进程Process的方法
构造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
group: 线程组,目前还没有实现,库引用中提示必须是None;
target: 要执行的方法;
name: 进程名;
args/kwargs: 要传入方法的参数。
实例方法:
is_alive():返回进程是否在运行。
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。
terminate():不管任务是否完成,立即停止工作进程
属性:
daemon:和线程的setDeamon功能一样,不过就是进程的daemon的属性,使用方式:p.daemon = False
name:进程名字。
pid:进程号。
import time
from multiprocessing import Process def foo(i):
time.sleep(1)
print (p.is_alive(),i,p.pid)
time.sleep(1) if __name__ == '__main__':
p_list=[]
for i in range(10):
p = Process(target=foo, args=(i,))
#p.daemon=True
p_list.append(p) for p in p_list:
p.start()
# for p in p_list:
# p.join() print('main process end')
4:进程间的通信1 queue 队列
要实现的代码:子进程放数据 ,主线程取数据
import queue import multiprocessing def foo(q):
q.put(12)
# print('id q:',id(q)) if __name__ == '__main__':
# q = queue.Queue() ##这是一个线程队列,我要用进程队列
q = multiprocessing.Queue()
print('id q:', id(q))
p = multiprocessing.Process(target=foo,args=(q,)) ##创建的q是在主进程中,要想使用需要给子进程传过去;子进程复制了q的
p.start()
# p.join()
data = q.get() ##队列为空,就阻塞住
print(data)
5:进程间的通信2 Pipe 管道
Pipe有点类似socket的conn ;他是一个双向管道,parent_conn, child_conn = Pipe() 这样拿到了2个双向管道 ;
Pipe 一端给父亲 ,一端给儿子 ,然后父亲和儿子就可以进行通信了 ;
Pipe的send 和recv 和socket的接口类似,但是不走网络。所以不需要转字节;
import multiprocessing def foo(conn):
conn.send("{'name':'yhy','content':'爸爸你好'}")
data = conn.recv()
print(data) if __name__ == '__main__':
parent_conn,child_conn = multiprocessing.Pipe() ##创建了管道
p = multiprocessing.Process(target=foo,args=((child_conn,))) ##一端给儿子
p.start()
parent_conn.send('儿子在吗')
data = parent_conn.recv()
print(data)
6:进程间的数据共享 Managers
Queue和pipe只是实现了数据交互,并没实现数据共享,数据共享即一个进程去更改另一个进程的数据。
可以进程数据共享的数据结构有如下几种:但是要记住这些的数据结构都是要经过,manager封装过的数据类型。
types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array.
from multiprocessing import Process, Manager def f(d, l,n):
d[n] = ''
d[''] = 2
l.append(n)
# print("son process:",id(d),id(l)) if __name__ == '__main__': with Manager() as manager: ##类似文件操作的with操作,我们可以不必手动的colose d = manager.dict() ##字典是经过manager封装过的字典 l = manager.list(range(5)) # print("main process:",id(d),id(l)) p_list = [] for i in range(10):
p = Process(target=f, args=(d,l,i))
p.start()
p_list.append(p) for res in p_list:
res.join() print(d)
print(l)
# 输出:
# {0: '1', 1: '1', 2: '1', 3: '1', 4: '1', 5: '1', 6: '1', 7: '1', 8: '1', 9: '1', '2': 2}
# [0, 1, 2, 3, 4, 0, 1, 2, 3, 6, 4, 7, 8, 5, 9]
7:进程同步
需知:
什么是同步?
有资源在阻塞,处于一个阻塞的状态。 为什么有同步锁?
控制一次只允许一个线程对同一个数据进行操作 。 进程的数据是相互独立的,那我进程还用同步干什么?
说是这么多,但是多个进程,也会面临共用同一个资源的时候,比如说屏幕。
代码实现内容:开启十个进程依次打印print('hello world %s' % i)
from multiprocessing import Process, Lock def f(l, i):
# with l.acquire():
print('hello world %s' % i) if __name__ == '__main__':
lock = Lock() for num in range(10):
Process(target=f, args=(lock, num)).start()
输出:屏幕是共用的资源,进程0和进程1都想在屏幕打印信息,出现错乱 。
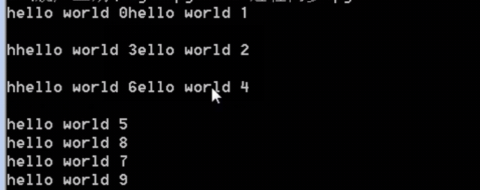
解决的办法:加锁,而锁是multiprocessing 下的Lock
from multiprocessing import Process, Lock def f(l, i):
with l: ##with之后 自动acquire 自动release
print('hello world %s' % i) if __name__ == '__main__':
lock = Lock() for num in range(10):
Process(target=f, args=(lock, num)).start()
8: 进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply 阻塞同步
- apply_async 异步状态
进程池,就是定义一个池了,我只开固定的几个进程去反复的执行某个动作。

from multiprocessing import Process,Pool
import time,os def Foo(i):
time.sleep(3)
print(i)
return i+100 def Bar(arg): ##回调函数必须要有一个形参去,接收foo的返回值
print(arg)
print('hello') if __name__ == '__main__': pool = Pool() ##这就是池,定义最大为5个,要是不定义 那么默认是按你cpu的核数去跑。 for i in range(100):
#pool.apply(func=Foo, args=(i,)) ##提供了同步接口,串行
#pool.apply_async(func=Foo, args=(i,))
##回调函数,callback 就是某个动作或者函数执行成功之后再去执行的函数,回调函数是主进程执行的
pool.apply_async(func=Foo, args=(i,),callback=Bar) pool.close() ##进程池的格式是死的,必须先close再join
pool.join()
print('end')
9:协程
协程,又称微线程,协程执行看起来有点像多线程,但是事实上协程就是只有一个线程,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显,此外因为只有一个线程,不需要多线程的锁机制,也不存在同时写变量冲突。协程的适用场景:当程序中存在大量不需要CPU的操作(IO)阻塞时。
默认线程和进程都是抢占式的,当我们开启多个的线程和进程时候,哪个会抢到cpu的执行,无法预料。
协程将cpu的执行流程交到了用户手上。
协程是也是多任务实现方式,它不需要多个进程或线程就可以实现多任务。
一、通过yield的简单实现:
import time
import queue def consumer(name):
print("--->ready to eat baozi...")
while True:
new_baozi = yield
print("[%s] is eating baozi %s" % (name,new_baozi))
#time.sleep(1) def producer(): r = con.__next__()
r = con2.__next__()
n = 0
while 1:
time.sleep(1)
print("\033[32;1m[producer]\033[0m is making baozi %s and %s" %(n,n+1) )
con.send(n)
con2.send(n+1) n +=2 if __name__ == '__main__':
con = consumer("c1")
con2 = consumer("c2")
p = producer()
yield能实现协程,不过实现过程不易于理解,greenlet是在这方面做了改进。
二、Greenlet
from greenlet import greenlet
import time def A():
while 1:
print('-------A-------')
time.sleep(0.5)
g2.switch() def B():
while 1:
print('-------B-------')
time.sleep(0.5)
g1.switch() g1 = greenlet(A) #创建协程g1
g2 = greenlet(B) g1.switch() #跳转至协程g1
输出:
-------A------- -
------B-------
-------A-------
-------B-------
-------A------- ···
三、gevent:
- greenlet可以实现协程,不过每一次都要人为的去指向下一个该执行的协程,显得太过麻烦。python还有一个比greenlet更强大的并且能够自动切换任务的模块gevent
- gevent每次遇到io操作,需要耗时等待时,会自动跳到下一个协程继续执行。
import gevent def A():
while 1:
print('-------A-------')
gevent.sleep(1) #用来模拟一个耗时操作,注意不是time模块中的sleep def B():
while 1:
print('-------B-------')
gevent.sleep(0.5) #每当碰到耗时操作,会自动跳转至其他协程 g1 = gevent.spawn(A) # 创建一个协程
g2 = gevent.spawn(B)
g1.join() #等待协程执行结束
g2.join()
输出:
-------A-------
-------B-------
-------B-------
-------A-------
-------B-------
-------B-------
-------A-------
-------B-------
-------B-------
···
Day13- Python基础13 生产者与消费者模型,进程的更多相关文章
- python queue和生产者和消费者模型
queue队列 当必须安全地在多个线程之间交换信息时,队列在线程编程中特别有用. class queue.Queue(maxsize=0) #先入先出 class queue.LifoQueue(ma ...
- python学习-40 生产者和消费者模型
import time def buy(name): # 消费者 print('%s上街去买蛋' %name) while True: eggs=yield print('%s买了%s' %(name ...
- Python 之并发编程之进程下(事件(Event())、队列(Queue)、生产者与消费者模型、JoinableQueue)
八:事件(Event()) # 阻塞事件: e = Event() 生成事件对象e e.wait() 动态给程序加阻塞,程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值 ...
- python多线程+生产者和消费者模型+queue使用
多线程简介 多线程:在一个进程内部,要同时干很多事情,就需要同时执行多个子任务,我们把进程内的这些子任务叫线程. 线程的内存空间是共享的,每个线程都共享同一个进程的资源 模块: 1._thread模块 ...
- Python之生产者&、消费者模型
多线程中的生产者和消费者模型: 生产者和消费者可以用多线程实现,它们通过Queue队列进行通信. import time,random import Queue,threading q = Queue ...
- python并发编程之守护进程、互斥锁以及生产者和消费者模型
一.守护进程 主进程创建守护进程 守护进程其实就是'子进程' 一.守护进程内无法在开启子进程,否则会报错二.进程之间代码是相互独立的,主进程代码运行完毕,守护进程也会随机结束 守护进程简单实例: fr ...
- 人生苦短之我用Python篇(队列、生产者和消费者模型)
队列: queue.Queue(maxsize=0) #先入先出 queue.LifoQueue(maxsize=0) #last in fisrt out queue.PriorityQueue( ...
- python:生产者与消费者模型
1,生产者与消费者模型的矛盾在于数据供需的不平衡 import time import random from multiprocessing import Queue from multiproce ...
- 【java线程系列】java线程系列之线程间的交互wait()/notify()/notifyAll()及生产者与消费者模型
关于线程,博主写过java线程详解基本上把java线程的基础知识都讲解到位了,但是那还远远不够,多线程的存在就是为了让多个线程去协作来完成某一具体任务,比如生产者与消费者模型,因此了解线程间的协作是非 ...
随机推荐
- Docker + WordPress搭建个人博客
WordPress是目前非常受欢迎的开源博客系统,今天使用Docker + WordPress搭建个人博客,整个过程非常丝滑. 搭博客先要准备域名和服务器,昨天在阿里云买了个.top的域名花了5块钱( ...
- 基于canvas二次贝塞尔曲线绘制鲜花
canvas中二次贝塞尔曲线参数说明: cp1x:控制点1横坐标 cp1y:控制点1纵坐标 x: 结束点1横坐标 y:结束点1纵坐标 cp2x:控制点2横坐标 cp2y:控制点2纵坐标 z:结束点2横 ...
- Dubbo学习系列之十二(Quartz任务调度)
Quartz词义为"石英"水晶,然后聪明的人类利用它发明了石英手表,因石英晶体在受到电流影响时,它会产生规律的振动,于是,这种时间上的规律,也被应用到了软件界,来命名了一款任务调度 ...
- 老师傅珍藏多年CAD常用快捷键合集,收藏,工作效率翻倍!
想要熟练操作CAD,做一名出色的CAD绘图员,少不了勤学苦练,还要掌握一些常用的绘图命令以及常用快捷键. 今天就来跟大家分享超全的CAD绘图命令,以及常用快捷键,学会涨工资! 常用快捷键: CTRL快 ...
- Angular(06)- 为什么数据变化,绑定的视图就会自动更新了?
这里提一点,前端三大框架(Angular,React,Vue)的数据驱动来更新视图的原理,即 MVVM 的实现. 为什么数据发生变化,绑定的视图就会刷新了呢? 以下是我的个人理解,仅供参考: 在还是 ...
- C lang:Array_Multidimensional arrays
#include<stdio.h> #include<windows.h> #define YEARS 5 #define MONTHS 12 void color(short ...
- 卡拉OK歌词原理和实现高仿Android网易云音乐
大家好,我们是爱学啊,继上一篇讲解了[LRC歌词原理和实现高仿Android网易云音乐],今天给大家带来一篇关于卡拉OK歌词原理和在Android上如何实现歌词逐字滚动的效果,本文来自[Android ...
- Android项目实战之高仿网易云音乐创建项目和配置
这一节我们来讲解创建项目:说道大家可能就会说了,创建项目还有谁不会啊,还需要讲吗,别急听我慢慢到来,肯定有你不知道的. 使用项目Android Studio创建项目我们这里就不讲解了,主要是讲解如何配 ...
- Vue之富文本tinymce爬坑录
前言 最近因业务需求在项目中嵌入了tinymce这个富文本编辑器,用于满足平台给用户编辑各类新闻内容什么的业务需求,前后也花了不少时间体验和对比了市面上各类开源编辑器. *案例demo版本:vue-t ...
- centos7中安装python3.6.4
1.在安装Python之前,需要先安装一些后面遇到的依赖问题(如果有依赖问题,按照提示安装): yum -y install zlib-devel bzip2-devel openssl-devel ...