008.MongoDB分片群集概念及原理
一 MongoDB分片介绍
1.1 分片
1.2 为什么使用分片
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
1.3 分片的优势
- 使用分片减少了每个分片需要处理的请求数:通过水平扩展,群集可以提高自己的存储容量。比如,当插入一条数据时,应用只需要访问存储这条数据的分片。
- 使用分片减少了每个分片存储的数据:分片的优势在于提供类似线性增长的架构,提高数据可用性,提高大型数据库查询服务器的性能。当MongoDB单点数据库服务器存储成为瓶颈、单点数据库服务器的性能成为瓶颈或需要部署大型应用以充分利用内存时,可以使用分片技术。
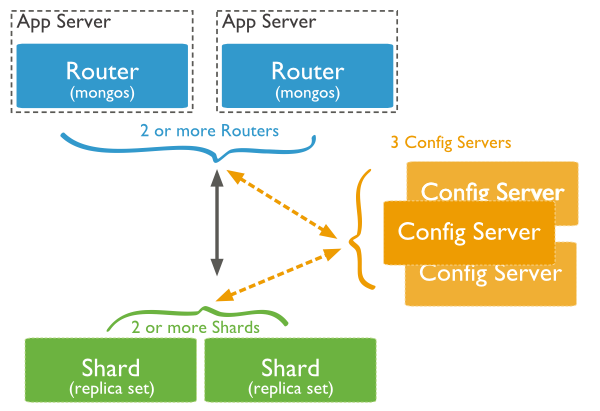
二 MongoDB分片架构
2.1 主要组件

2.2 shard key
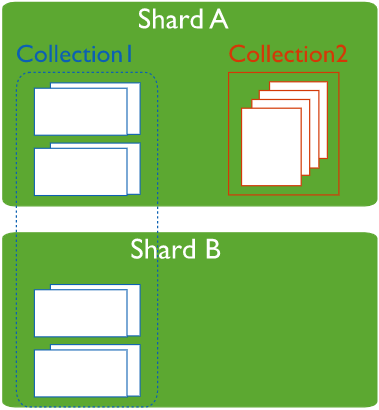
2.3 分片集和非分片集
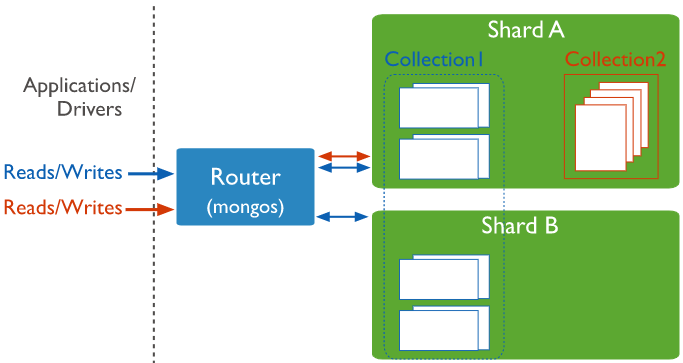
2.4 分片集连接
三 分片策略
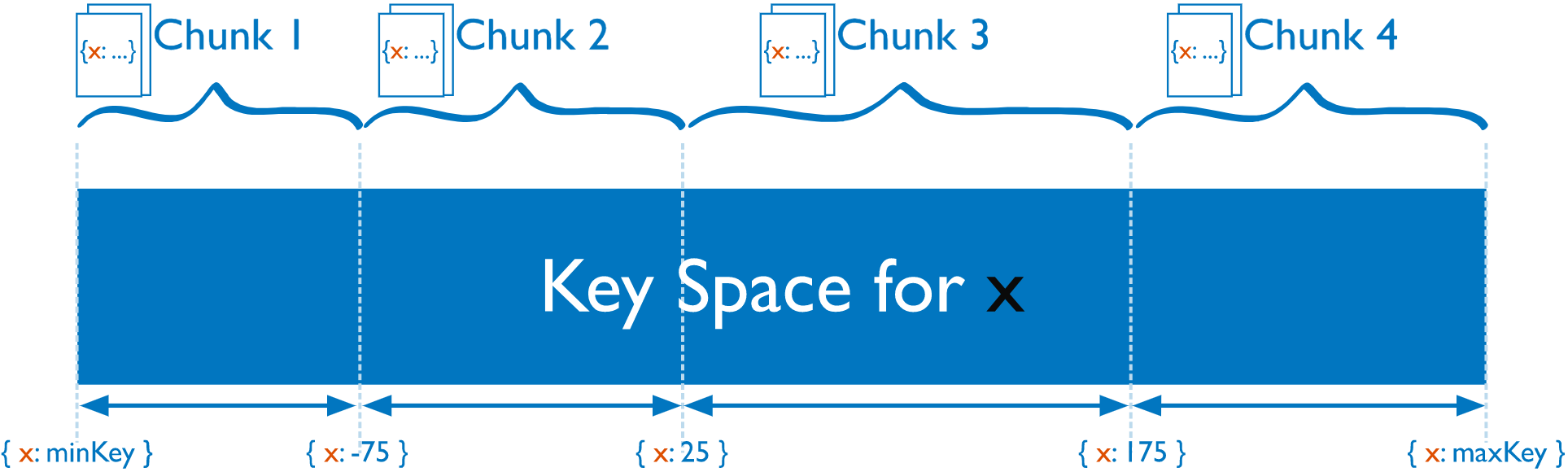
3.1 基于范围划分
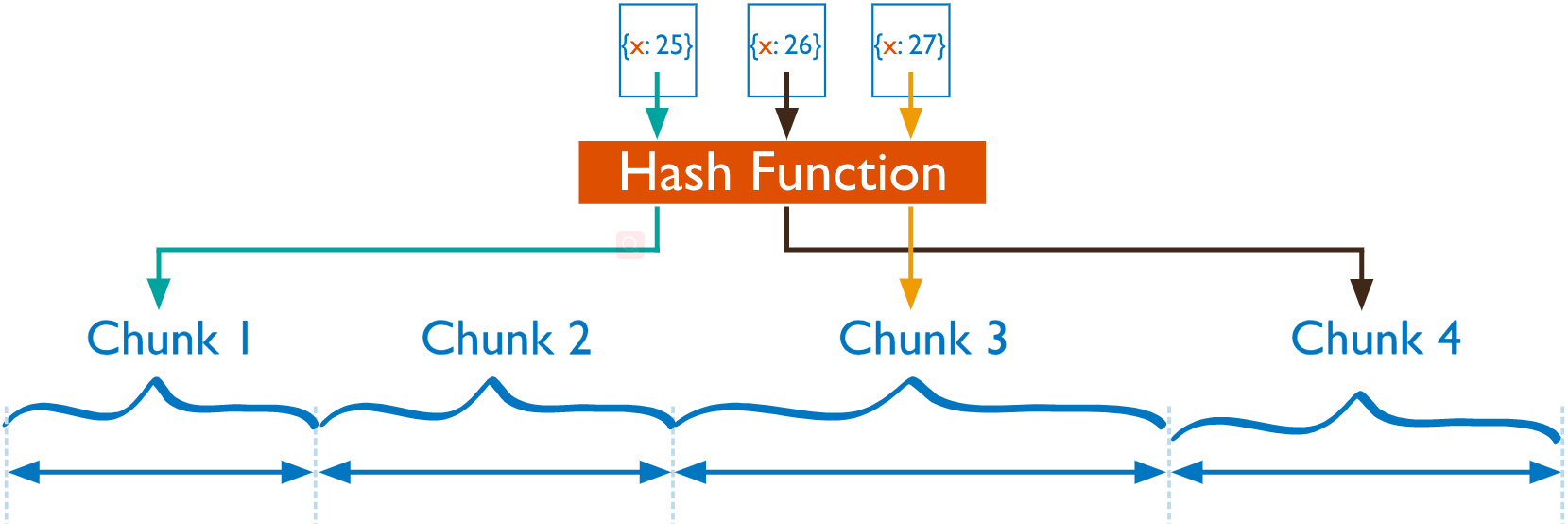
3.2 基于散列划分
3.3 自定义标签划分
四 数据均衡
4.1 拆分
4.2 平衡
4.3 从集群中增加和删除分片
008.MongoDB分片群集概念及原理的更多相关文章
- MongoDB分片群集的部署(用心描述,详细易懂)!!
概念: MongoDB分片是使用多个服务器存储数据的方法,以支持巨大的数据存储和对数据进行存储 优势: 1.减少了每个分片需啊哟处理的请求数,群集可以提高自己的存储容量和吞吐量 2.减少了每个分片存储 ...
- 【MangoDB分片】配置mongodb分片群集(sharding cluster)
配置mongodb分片群集(sharding cluster) Sharding cluster介绍 这是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建monod ...
- 009.MongoDB分片群集部署
一 前期准备 1.1 组件说明 MongoDB分片群集包含以下组件: shard:每个分片是分片数据的子集.从MongoDB 3.6开始,必须将分片部署为副本集. mongos:mongos充当查询路 ...
- mongodb 分片群集(sharding cluster)
实际环境架构 分别在3台机器运行一个mongod实例(称为mongod shard11,mongod shard12,mongod shard13)组织replica set1,作为cluster的s ...
- Mongodb分片集群技术+用户验证
随着数据量持续增多,后续迟早会出现一台机器硬件瓶颈问题的.而mongodb主打的就是海量数据架构,“分片”就用这个来解决这个问题. 从图中可以看到有四个组件:mongos.config server. ...
- MongoDB 分片集群
每日一句 Medalist don't grow on trees, you have to nurture them with love, with hard work, with dedicati ...
- MongoDB分片集群-Sharded Cluster
分片概念 分片(sharding)是一种跨多台机器分布数据的方法, MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署. 换句话说:分片(sharding)是指将数据拆分,将其分散存在 ...
- MySQL Cluster 与 MongoDB 复制群集分片设计及原理
分布式数据库计算涉及到分布式事务.数据分布.数据收敛计算等等要求 分布式数据库能实现高安全.高性能.高可用等特征,当然也带来了高成本(固定成本及运营成本),我们通过MongoDB及MySQL Clus ...
- MongoDB 分片的原理、搭建、应用
一.概念: 分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程.将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载.基本思想就是将集合切成小块,这 ...
随机推荐
- VisualStudio编译不生成xml、pdb文件的方法
我们为了减少发布/Release时项目的体积,希望在编译时不生成xml注释文档(包括引用的其他类库),和pdb调试文件 用你喜欢的文本编辑器打开项目.csproj文件,找到PropertyGroup节 ...
- YII2数据库操作出现类似Database Exception – yii\db\Exception SQLSTATE[HY000] [2002] No such file or director
参考文章:https://blog.csdn.net/zqtsx/article/details/41845511 我的系统时Ubuntu18使用上面的方法时发现,没有MySQL.socket,然后谷 ...
- How to: Supply Initial Data for the Entity Framework Data Model 如何:为EF数据模型提供初始数据
After you have introduced a data model, you may need to have the application populate the database w ...
- Git实战指南----跟着haibiscuit学Git(第八篇)
笔名: haibiscuit 博客园: https://www.cnblogs.com/haibiscuit/ Git地址: https://github.com/haibiscuit?tab=re ...
- 程序结构设计理论(Android)
程序结构设计理论(Android) 作者:邓能财 2019年9月24日 个人简介 姓名:邓能财 年龄:26 毕业学校:东华理工大学 院系:理学院 专业:信息与计算科学 邮箱:2420987186@qq ...
- python快速导出sql语句(mssql)的查询结果到Excel,解决SSMS无法加载大字段的问题
遇到一个尴尬的问题,SSMS的GridView对于大字段的(varchar(max),text之类的),支持不太友好的,超过8000个长度之外的字符,SSMS的表格是显示不出来的(当然也就看不到了), ...
- Python中列表乘法需注意的问题/
前几天看到一个关于Python的面试题 lst = [1, 2, [3]] lst1 = lst * 2 # [1, 2, [3], 1, 2, [3]] lst1[2].append(4) # ...
- socket简单介绍
一 三种类型的套接字: 1.流式套接字(SOCKET_STREAM) 提供面向连接的可靠的数据传输服务.数据被看作是字节流,无长度限制.例如FTP协议就采用这种. 2.数据报式套接字(SOCK ...
- 关于controller层用实体类接收参数为null的问题
如果你的表单标签中包含enctype="multipart/form-data"属性,那么请将它删掉<form action="xxxxxxx" id=& ...
- jvaa之初始化块
1.初始化块的作用:对java对象进行初始化: 2.程序的执行顺序:声明成员变量的默认值-->显示初始化,多个初始化块依次被执行(同级别下按先后顺序执行)-->构造器在对成员进行赋值操作. ...