MongoDB for OPS 03:分片 shard 集群
写在前面的话
上一节的复制集也就是主从能够解决我们高可用和数据安全性问题,但是无法解决我们的性能瓶颈问题。所以针对性能瓶颈,我们需要采用分布式架构,也就是分片集群,sharding cluster!
架构说明
架构规划:
我们这里准备了 4 台虚拟机:192.168.200.101-104
在分片集群中,mongodb 包含以下三个角色:mongos(router),config server,shard。
mongos 节点:用于服务连接,不存数据,有点像路由器。
config server 节点:保存集群相关配置以及数据到底存放在那个分片,所以数据非常重要,需要一主两从。
shard 节点:数据存储节点,由多个集群组成,每个集群可以为一主一从一arbiter。
端口设计:
shard 集群1:192.168.200.101-103:27001
shard 集群2:192.168.200.101-103:27002
config 集群:192.168.200.101-103:28001
mongos:192.168.200.104:29000
默认主尽量分开,这样能够避免压力都在一台机器上面。这只能算是一个简陋的集群。
架构如图:
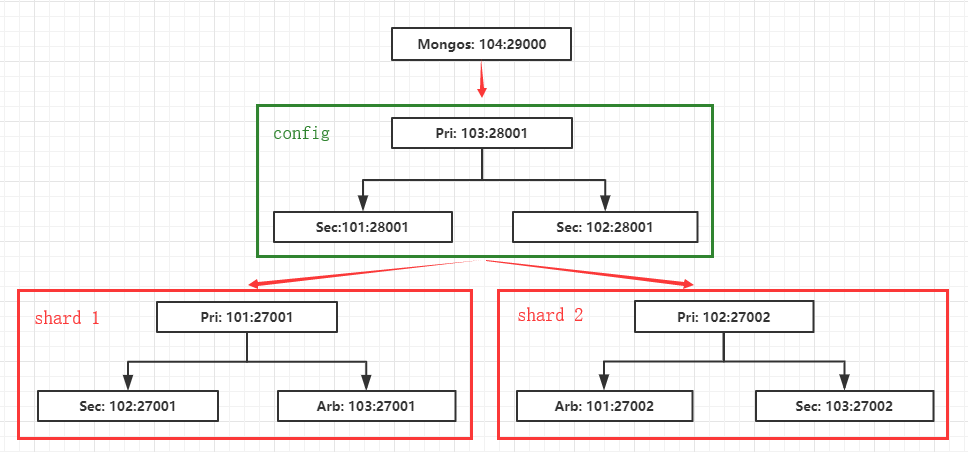
配置分片集群
1. 所有节点初始化安装:
# 关闭大页内存机制
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi # 查看设置结果
cat /sys/kernel/mm/transparent_hugepage/enabled
cat /sys/kernel/mm/transparent_hugepage/defrag # 初始化目录
mkdir -p /data/{backup,data,logs,packages,services}
mkdir -p /data/packages/mongodb # 将安装包上传到:/data/packages/mongodb 下 # 解压
cd /data/packages/mongodb
tar -zxf mongodb-linux-x86_64-rhel70-4.2.1.tgz
mv mongodb-linux-x86_64-rhel70-4.2.1 /data/services/mongodb # 配置基础目录
cd /data/services/mongodb
rm -f LICENSE-Community.txt MPL-2 README THIRD-PARTY-NOTICES THIRD-PARTY-NOTICES.gotools
2. 所有节点配置环境变量:
cat >> /etc/profile << EOF
# mongodb env
export MONGODB_HOME='/data/services/mongodb'
export PATH=\$PATH:\${MONGODB_HOME}/bin
EOF # 环境变量生效
source /etc/profile # 查看版本
mongo --version
3. 101-103 节点初始化目录设计:
cd /data/services
mkdir -p mongodb-shard1/{data,config,logs}
mkdir -p mongodb-shard2/{data,config,logs}
mkdir -p mongodb-config/{data,config,logs}
结构如下:
/data/services/
├── mongodb -- mongodb 安装目录
│ └── bin
├── mongodb-config -- config 节点根目录
│ ├── config
│ ├── data
│ └── logs
├── mongodb-shard1 -- shard 1 节点根目录
│ ├── config
│ ├── data
│ └── logs
└── mongodb-shard2 -- shard 2 节点根目录
├── config
├── data
└── logs
4. 101-103 节点构建 shard 1 集群:
添加配置:注意红色部分根据节点修改,蓝色部分为需要注意的
cat > /data/services/mongodb-shard1/config/shard.conf << EOF
# 系统相关
systemLog:
destination: file
path: "/data/services/mongodb-shard1/logs/shard.log"
logAppend: true # 存储相关
storage:
journal:
enabled: true
dbPath: "/data/services/mongodb-shard1/data"
directoryPerDB: true
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true # 网络相关
net:
bindIp: 192.168.200.101,127.0.0.1
port: 27001 # 复制相关
replication:
oplogSizeMB: 2048
replSetName: my_shard_1 # 分片相关
sharding:
clusterRole: shardsvr # 进程相关
processManagement:
fork: true
pidFilePath: "/data/services/mongodb-shard1/logs/shard.pid"
EOF
启动节点:
mongod -f /data/services/mongodb-shard1/config/shard.conf
在 上登录配置复制集:
mongo --port 27001
配置:注意蓝色部分为我们配置文件中定义的。
use admin
config = {_id: "my_shard_1", members:[
{_id: 0, host: '192.168.200.101:27001'},
{_id: 1, host: '192.168.200.102:27001'},
{_id: 2, host: '192.168.200.103:27001', "arbiterOnly": true}
]}
rs.initiate(config)
rs.status()
rs.isMaster()
结果如图:

5. 101-103 节点构建 shard 2 集群,和 1 大致相同,注意目录,my_shard_2 名字,端口就行。
config = {_id: "my_shard_2", members:[
{_id: 0, host: '192.168.200.101:27002', "arbiterOnly": true},
{_id: 1, host: '192.168.200.102:27002'},
{_id: 2, host: '192.168.200.103:27002'}
]}
在 102 上面登录初始化复制集,结果如下:

6. 101-103 节点配置 config:
配置文件:红色部分为不通节点需要修改的,蓝色部分为需要注意的
cat > /data/services/mongodb-config/config/config.conf << EOF
# 系统相关
systemLog:
destination: file
path: "/data/services/mongodb-config/logs/config.log"
logAppend: true # 存储相关
storage:
journal:
enabled: true
dbPath: "/data/services/mongodb-config/data"
directoryPerDB: true
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true # 网络相关
net:
bindIp: 192.168.200.101,127.0.0.1
port: 28001 # 复制相关
replication:
oplogSizeMB: 2048
replSetName: configReplSet # 分片相关
sharding:
clusterRole: configsvr # 进程相关
processManagement:
fork: true
pidFilePath: "/data/services/mongodb-config/logs/config.pid"
EOF
启动服务:
mongod -f /data/services/mongodb-config/config/config.conf
在 103 登录节点初始化:
mongo --port 28001 admin
配置:
config = {_id: "configReplSet", members:[
{_id: 0, host: '192.168.200.101:28001'},
{_id: 1, host: '192.168.200.102:28001'},
{_id: 2, host: '192.168.200.103:28001'}
]}
rs.initiate(config)
rs.isMaster()
结果如图:

7. 此时 101-103 三台服务器的服务运行如下:

8. 此时三个集群以及建立完成,但是它们是完全隔离的三个集群。所以需要另外一个东西把它们关联起来。
在 104 上面新增 mongos:
cd /data/services/
mkdir -p mongodb-mongos1/{data,logs,config}
添加配置文件:注意红色部分,名称,还有 config 集群各个节点的地址
cat > /data/services/mongodb-mongos1/config/mongos.conf << EOF
# 系统相关
systemLog:
destination: file
path: "/data/services/mongodb-mongos1/logs/mongos.log"
logAppend: true # 网络相关
net:
bindIp: 192.168.200.104,127.0.0.1
port: 29001 # 分片相关
sharding:
configDB: configReplSet/192.168.200.101:28001,192.168.200.102:28001,192.168.200.103:28001 # 进程相关
processManagement:
fork: true
pidFilePath: "/data/services/mongodb-mongos1/logs/mongos.pid"
EOF
启动节点:注意这里启动节点和启动 mongodb 不同
mongos -f /data/services/mongodb-mongos1/config/mongos.conf
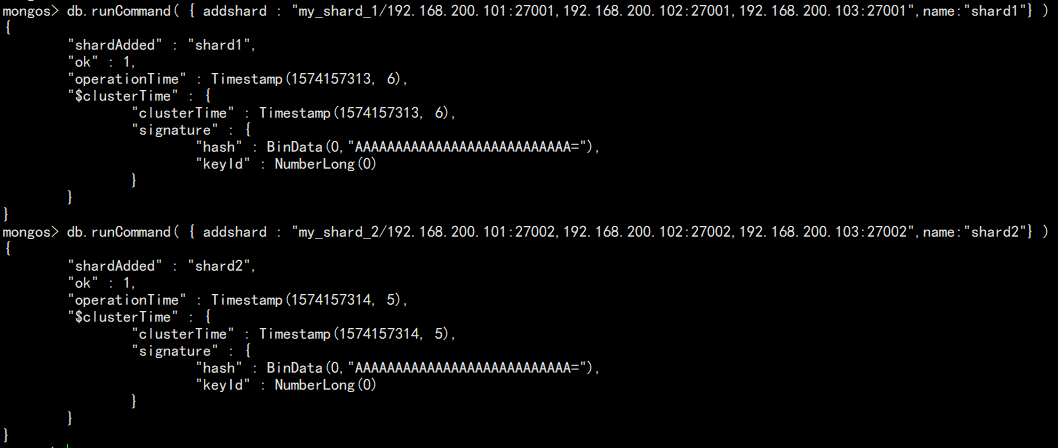
9. 连接 mongos 添加 shard:
mongo --port 29001 admin
配置:
db.runCommand( { addshard : "my_shard_1/192.168.200.101:27001,192.168.200.102:27001,192.168.200.103:27001",name:"shard1"} )
db.runCommand( { addshard : "my_shard_2/192.168.200.101:27002,192.168.200.102:27002,192.168.200.103:27002",name:"shard2"} )
如图:
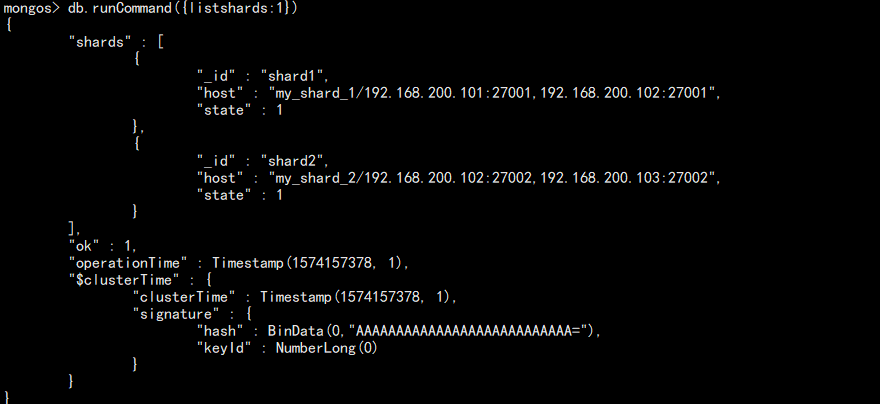
查看分片:
db.runCommand({listshards:1})
如图:
也可以查看分片集群状态:
sh.status()
至此,分片集群搭建完成!
使用集群
当我们在存数据的时候,加入一张表有一千万数据,按照系统自带的分片策略,可能导致多个 shard 集群数据不均,然后整个集群的性能得不到充分的利用。
针对这个问题,mongdb 目前提供了两种分片规则配置:Range 和 Hash。
Range:根据某个字段将某范围内的放到指定节点,如 id < 50000 的放到集群 1 这样。该分片方式存在一个问题,因为数据的热度可能不一样,有可能最新的数据访问频繁程度高一些,这样导致请求大多可能都落在数据比较新的集群,导致服务器忙的忙死,闲的闲死,无法做到负载的均衡。
Hash:通过一定的算法将数据存到某个集群,这样的数据是随机的,也不知道访问的数据到底在哪一个。这样数据量越多,那么服务器性能占用就越接近均衡。
Range 配置(mongos 节点):
1. 给指定库(hello)开启分片功能:
use admin
db.runCommand({enablesharding: "hello"})
2. 给指定库(hello)下面指定表(t1)创建索引和分片:
# 创建索引
use hello
db.t1.ensureIndex({id:1}) # 开启分片
use admin
db.runCommand({shardcollection: "hello.t1", key: {id:1}})
3. 录入100万数据:注意,如果数据量太少可能只会落在一个节点
use hello
for(i=1;i<=1000000;i++){db.t1.insert({"id":i,"name":"zhangsan","date":new Date()})}
查看记录数量:
db.t1.count()
4. 去分片节点查看数据:
注意,当数据量太小装满一个 chunk,所以最终数据还是在一个 shard 上。
Hash 分片配置(推荐使用):
1. 给指定库(world)开启分片功能:
use admin
db.runCommand({enablesharding: "world"})
2. 给指定库(world)下面指定表(t2)创建索引和分片:
# 创建索引
use world
db.t2.ensureIndex({id: "hashed"}) # 分片
use admin
sh.shardCollection("world.t2", {id: "hashed"})
3. 录入 10 万数据:
use world
for(i=1;i<100000;i++){db.t2.insert({"id":i,"name":"zhangsan","date":new Date()})}
4. 登录 shard 节点查看数据:
use world
db.t2.count()
shard 1:

shard 2:

可以看到,大致相当,几百条数据差异不用在意。
其它命令:
# 查看所有开启分片的库
db.databases.find( { "partitioned": true } ) # 查看分片的键
db.collections.find().pretty()
balancer
mongodb 会自动巡查所有 shard 节点上的 chunk 情况,并自动迁移。如节点删除的时候。
但是迁移存在一个问题,会产生大量的 IO,如果是在业务繁忙期间,会影响业务。
于是我们便需要 balancer 来对 chunk 迁移的时间进行调整。
设置方法:
use config # 查看状态
sh.getBalancerState() # 开启
sh.setBalancerState(true) # 设置时间
db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "3:00", stop : "5:00" } } }, true ) # 查看设置结果
sh.getBalancerWindow()
当然,也可以通过查看 shard 状态查看:
sh.status()
如图:
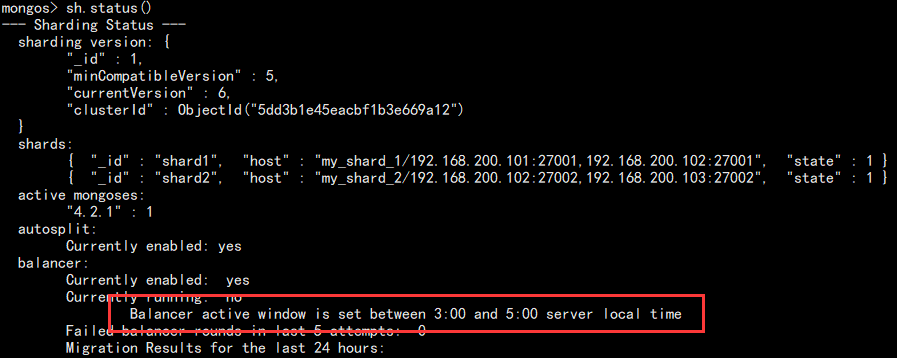
该操作需要避开备份和业务高峰期!至此,分破集群大致说到这里。
MongoDB for OPS 03:分片 shard 集群的更多相关文章
- Windows下Mongo分片及集群
这里简单介绍一下windows下mongodb的分片设置和集群搭建,希望能够为迷茫的新手起到一点点作用.其实windows下与linux下思路是一致的,只是绑定时的ip,与端口号不同,linux下可以 ...
- Redis基于客户端分片的集群案例(待实践)
说明: 下面的示例基本都是基于Linux去实现,目的是为了环境的统一,以便于把性能调整到最优.且基于Java.建议生产环境不要使用Windows/Mac OS这些. 在Java领域,基于客户端进行分片 ...
- (转)MongoDB分片实战 集群搭建
环境准备 Linux环境 主机 OS 备注 192.168.32.13 CentOS6.3 64位 普通PC 192.168.71.43 CentOS6.2 64位 服务器,NUMA CPU架构 Mo ...
- MongoDB集群搭建---副本和分片(伪集群)
参考地址:https://blog.csdn.net/weixin_43622131/article/details/105984032 已配置好的所有的配置文件下载地址:https://files. ...
- [原创]在Docker上部署mongodb分片副本集群。
一.安装docker. 请参考:http://www.cnblogs.com/hehexiaoxia/p/6150584.html 二.编写dockerfile. 1.在根目录下创建mongod的do ...
- MongoDB在单机上搭建分片副本集群(windows)
------------------------------1.安装MongoDB...... ------------------------------2.准备好文件夹 --config:配置文件 ...
- MongoDB 4.0 开发环境搭建集群
环境准备 Liunx 服务器一台 以下示例为单机版安装集群, 没有分片 MongoDB 安装 1.下载 MongoDB tgz 安装包: 可以从下载中心下载: https://www.mongodb. ...
- 关于MongoDb Replica Set的故障转移集群——实战篇
如果你还不了解Replica Set的相关理论,请猛戳传送门阅读笔者的上一篇博文. 因为Replica Set已经属于MongoDb的进阶应用,下文中关于MongoDb的基础知识笔者就不再赘述了,请参 ...
- 关于MongoDb Replica Set的故障转移集群——理论篇
自从10 gen用Replica Set取代Master/Slave方案后生活其实已经容易多了,但是真正实施起来还是会发现各种各样的小问题,如果不小心一样会栽跟头. 在跟Replica Set血拼几天 ...
随机推荐
- [考试反思]1113csp-s模拟测试114:一梦
自闭.不废话.写一下低错. T1:觉得信心赛T1不会很恶心一遍过样例直接没对拍(其实是想写完T2之后回来对拍的) 状态也不好,基本全机房都开始码了我还没想出来(skyh已经开T2了).想了40多分钟. ...
- 批量修改含空格的文件名「Linux」
1.问题:文件批量重命名和处理文件名中的空格 如果文件名中有空格,在执行以下shell脚本的时候会出错. shell 脚本 for filename in `ls` do echo $filename ...
- c博客06-结构体&文件
1.本章学习总结 1.1 学习内容总结 结构体的定义.成员的赋值: 结构体的一般定义形式(单独定义): struct 结构名 { 类型名 结构体成员名1; 类型名 结构体成员名2; ... 类型名 结 ...
- python - 操作excel表格
说明:由于公司oa暂缺,人事妹子在做考勤的时候,需要通过几个excel表格去交叉比对员工是否有旷工或迟到,工作量大而且容易出错. 这时候it屌丝的机会来啦,花了一天时间给妹子撸了一个自动化脚本. 1. ...
- 痞子衡嵌入式:飞思卡尔i.MX RT系列MCU量产神器RT-Flash常见问题
对于MCUBootUtility,RT-Flash工具,有任何使用上的问题,可以在本博客下留言,也可以扫码加入QQ交流群.
- python assert断言用法
作用:断言函数运行状态 语法:assert condition,判断condition运行状态,若condition状态为false,则上报错误:AssertionError
- IDEA提示找不到Mapper接口:Could not autowire.No beans of 'xxxMapper' type found
前言 相信大多数互联网公司的持久层框架都是使用 Mybatis 框架,而大家在 Service 层引入自己编写的 Mapper 接口时应该会遇到下面的情况: 我们可以看到,上面的红色警告在提示我们,找 ...
- 松软科技web课堂:SQLServer之NOW() 函数
NOW() 函数 NOW 函数返回当前的日期和时间. 提示:如果您在使用 Sql Server 数据库,请使用 getdate() 函数来获得当前的日期时间. SQL NOW() 语法 SELECT ...
- CSS学习笔记-盒子阴影及文字阴影
盒子阴影: 1.格式: box-shadow:h-shadow v-shadow blur spread color insert; box-shadow:水平偏移 ...
- 简单sql注入学到的延时盲注新式攻击
0x01 知识点 mysql_pconnect(server,user,pwd,clientflag) mysql_pconnect() 函数打开一个到 MySQL 服务器的持久连接. mysql_p ...