CitusDB Multi-node Install and Test
Multi-node setup on CentOS
参考官网:https://docs.citusdata.com/en/v6.2/installation/production_rhel.html
Test Environments
CentOS Linux release 7.2.1511 (Core)
Three nodes(citus1,citus2,citus3)
Steps to be executed on all nodes
1. Add repository
curl https://install.citusdata.com/community/rpm.sh | sudo bash
2. Install PostgreSQL + Citus and initialize a database
sudo yum install -y citus62_96
sudo service postgresql-9.6 initdb || sudo /usr/pgsql-9.6/bin/postgresql96-setup initdb
echo "shared_preload_libraries = 'citus'" | sudo tee -a /var/lib/pgsql/9.6/data/postgresql.conf
3. Configure connection and authentication
sudo vi /var/lib/pgsql/9.6/data/postgresql.conf

sudo vi /var/lib/pgsql/9.6/data/pg_hba.conf
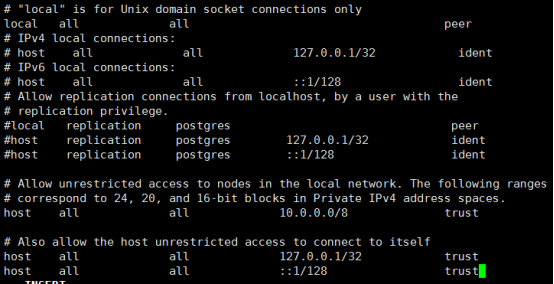
Note:Your DNS settings may differ. Also these settings are too permissive for some environments.The configuration is shown below:
https://www.postgresql.org/docs/9.6/static/auth-pg-hba-conf.html
4. Start database servers, create Citus extension
sudo service postgresql-9.6 restart
sudo chkconfig postgresql-9.6 on
You must add the Citus extension to every database you would like to use in a cluster. The following example adds the extension to the default database which is named postgres.
sudo -i -u postgres psql -c "CREATE EXTENSION citus;"
Steps to be executed only on the coordinator node
1. Add worker node
sudo -i -u postgres psql -c "SELECT * from master_add_node('citus2', 5432);"
sudo -i -u postgres psql -c "SELECT * from master_add_node('citus3', 5432);"
2. Verify
sudo -i -u postgres psql -c "SELECT * FROM master_get_active_worker_nodes();"
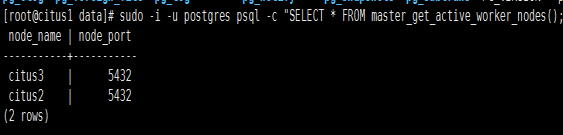
Succeeded!
Notes:Remove worker node command(If you add a node wrong)
sudo -i -u postgres psql -c "SELECT * from master_remove_node('work', 5432);"
See the details below:
https://docs.citusdata.com/en/v6.2/reference/user_defined_functions.html
Test
Download sample data
curl https://examples.citusdata.com/tutorial/companies.csv > /var/lib/pgsql/companies.csv
curl https://examples.citusdata.com/tutorial/campaigns.csv > /var/lib/pgsql/campaigns.csv
curl https://examples.citusdata.com/tutorial/ads.csv > /var/lib/pgsql/ads.csv
Creating tables
To start, you can first connect to the Citus co-ordinator(citus1) using psql.
# sudo -i -u postgres psql
CREATE TABLE companies ( id bigint NOT NULL, name text NOT NULL, image_url text, created_at timestamp without time zone NOT NULL, updated_at timestamp without time zone NOT NULL ); CREATE TABLE campaigns ( id bigint NOT NULL, company_id bigint NOT NULL, name text NOT NULL, cost_model text NOT NULL, state text NOT NULL, monthly_budget bigint, blacklisted_site_urls text[], created_at timestamp without time zone NOT NULL, updated_at timestamp without time zone NOT NULL ); CREATE TABLE ads ( id bigint NOT NULL, company_id bigint NOT NULL, campaign_id bigint NOT NULL, name text NOT NULL, image_url text, target_url text, impressions_count bigint DEFAULT 0, clicks_count bigint DEFAULT 0, created_at timestamp without time zone NOT NULL, updated_at timestamp without time zone NOT NULL );
Next, you can create primary key indexes on each of the tables just like you would do in PostgreSQL
ALTER TABLE companies ADD PRIMARY KEY (id);
ALTER TABLE campaigns ADD PRIMARY KEY (id, company_id);
ALTER TABLE ads ADD PRIMARY KEY (id, company_id);
Distributing tables and loading data
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
Load the data
postgres=# \copy companies from '/var/lib/pgsql/companies.csv' with csv;
COPY 100
postgres=# \copy campaigns from '/var/lib/pgsql/campaigns.csv' with csv;
COPY 978
postgres=# \copy ads from '/var/lib/pgsql/ads.csv' with csv;
COPY 7364
Running queries
postgres=# INSERT INTO companies VALUES (5000, 'New Company', 'https://randomurl/image.png', now(), now());
INSERT 0 1
postgres=# UPDATE campaigns
postgres-# SET monthly_budget = monthly_budget*2
postgres-# WHERE company_id = 5;
UPDATE 12
postgres=# BEGIN;
BEGIN
postgres=# DELETE from campaigns where id = 46 AND company_id = 5;
DELETE 1
postgres=# DELETE from ads where campaign_id = 46 AND company_id = 5;
DELETE 7
postgres=# COMMIT;
COMMIT
postgres=# SELECT name, cost_model, state, monthly_budget
postgres-# FROM campaigns
postgres-# WHERE company_id = 5
postgres-# ORDER BY monthly_budget DESC
postgres-# LIMIT 10;
name | cost_model | state | monthly_budget
-------------------------+---------------------+----------+----------------
Wondra | cost_per_impression | running | 16732
Quicksilver | cost_per_click | paused | 12664
Cyborg | cost_per_impression | running | 8198
Agent Hancock | cost_per_impression | running | 6996
Mr Cyclops I | cost_per_click | paused | 6122
Sasquatch Eyes | cost_per_impression | archived | 5828
Ultra Namor | cost_per_impression | paused | 5554
Carnage | cost_per_impression | paused | 4300
Cyborg Two-Face Machine | cost_per_click | archived | 4086
Binary | cost_per_impression | paused | 3620
(10 rows)
CitusDB Multi-node Install and Test的更多相关文章
- phantomjs-prebuilt@2.1.14 install: `node install.js`
在用vue-cli构建项目时,npm install 安装包的时候报错了. 错误信息: npm ERR! Failed at the phantomjs-prebuilt@2.1.14 install ...
- vue安装之后的报错处理---chromedriver@2.35.0 install: `node install.js`
报错:chromedriver@2.35.0 install: `node install.js` 这个错误的解决方法就是在你创建的项目目录,比如你创建的项目叫myVue,然后你就要在myVue这个目 ...
- npm ERR! errno 1 npm ERR! chromedriver@2.35.0 install: `node install.js`
在使用webpack+vue-cli进行vue项目构建时可能会出现一下错误,webpack@3.10.0及以上版本和vue-cli@2.9.2及以上版本会自动安装依赖(我在自己电脑上测试是这样的)不用 ...
- How to set an Apache Kafka multi node – multi broker cluster【z】
Set a multi node Apache ZooKeeper cluster On every node of the cluster add the following lines to th ...
- npm install报错:chromedriver@2.27.2 install: node install.js
报错: 刚开始以为是 node 或 npm 版本问题,前前后后折腾了好久,终于解决了 解决: 如果执行过npm install,先删除 node_modules 文件夹,不然运行的时候可能会报错 执行 ...
- 报错---“node install.js”
如图 解决方案: 目录中执行 npm install chromedriver --chromedriver_cdnurl=http://cdn.npm.taobao.org/dist/chromed ...
- phantomjs-prebuilt@2.1.16 install: `node install.js`
今天运行vue项目安装项目依赖(npm install)的时候,报这个错误: 解决办法: npm -g install phantomjs-prebuilt@2.1.16 --ignore-scrip ...
- npm 安装vue 报错Failed at the chromedriver@2.46.0 install script 'node install.js'
原因一般是下载源被封了,我们连接淘宝的下载源下载: npm install chromedriver --chromedriver_cdnurl=http://cdn.npm.taobao.org/d ...
- npm 安装vue 报错Failed at the chromedriver@2.34.0 install script 'node install.js'
提示版本不够,后来百度到,在你的vue项目包下执行: npm install chromedriver --chromedriver_cdnurl=http://cdn.npm.taobao.org/ ...
- vue 环境报错 chromedriver@2.44.1 install: `node install.js`
解决办法: 1. yarn add chromedriver -g 2.yarn add chromedriver --chromedriver_cdnurl=http://cdn.npm.taoba ...
随机推荐
- win10 uwp ApplicationView
原文:win10 uwp ApplicationView 本文和大家介绍一个重要的类,他可以用来设置窗口,如设置启动大小,设置是否允许截图,是否进入全屏,所有和窗口有关的,都可以在他这里设置. 可以使 ...
- UWP ListView
ListViewItem项填充整个宽度最大化<ListView.ItemContainerStyle> <Style TargetType="ListViewItem&qu ...
- 职业规划 - DREAM START
前言 最近面试了好多公司,得出一个结论:做一份详细的计划.一个程序员,不只是写写代码这么简单的事,一种更高的境界则是在代码中.系统的设计中,能找到人生的意义,简单说就是生活的道理.我一直认为:当你在一 ...
- 什么是 MEF?
什么是 MEF? Managed Extensibility Framework 即 MEF 是用于创建轻量.可扩展应用程序的库. 它让应用程序开发人员得以发现和使用扩展且无需配置. 它还让扩展开发人 ...
- MySql5.7.11 for Windows 安装精简版(一)
原文:MySql5.7.11 for Windows 安装精简版(一) 从官网下载压缩包,我下载的是64位的.解压. 精简: -Bin下只保留 mysqladmin.exe mysqld.exe my ...
- CentOS7 firewall与iptables防火墙的使用与开放端口
如何关闭firewall并开启iptables防火墙 如何使用firewall防火墙 如何关闭firewall并开启iptables防火墙 1.停止firewall systemctl stop fi ...
- c#与JAVA利用SOCKET实现异步通信的SanNiuSignal.DLL已开源
大家好,前段时间C#的SanNiuSignal.DLL已开源;因部分用户特需要JAVA版的SanNiuSignal;现在只能把半成品先拿出来暂时给他们用了,以后再慢慢改进; JAVA版目前已实现跟C# ...
- UItableView UIcollectionView下拉刷新会跳动?看了此篇就能解决这个Bug了
顺序如下: 1.数组添加: for (id model in modellist.list) { IDSCommentWeplayList *commentListModel = [I ...
- php生成html静态文件
现在的动态网站存在很多性能上的弊端,seo优化会存在一定的瓶颈,现在将动态的网站代码转换为html静态文件,是浏览器通过html间接的读取动态网站源文件,这对其网站加载速度还是seo优化有着举足轻重的 ...
- 获取原生DOM,diy脚手架,vue-clide使用,element-ui的使用
一.获取原生DOM的方式 给标签或者属性添加ref属性 //1.添加属性 <div ref='shy'><div> <Home ref='home'></Ho ...