OpenStack 初探(一) -- All-In-One模式部署(初学OpenStack必备)
OpenStack 初探(一) -- All-In-One模式部署(初学OpenStack必备)
一、操作前需了解:
1. OpenStack提供IaaS(基础设施即服务)服务,它是开源的云计算平台。(个人理解:将多台硬件设备虚拟化成一个池,然后在池子里放虚拟机,放存储(对象和块)集群,所有整合一起提供云计算基础服务,会想到VMWARE的ESX(i))
2. 通常OpenStack是由许多硬件节点组合而成的,包括控制节点Controller,计算节点Compute,网络节点Network,块存储节点ceph,对象存储节点swift等。
AllInOne是Openstack最基本的模式,即将所有必要组件都安装到一台硬件节点上。这种模式不包含块存储和对象存储模块。
3. 组件服务名词(红色部分为必要服务组件)
| Service | Project Name | Description |
|---|---|---|
| Dashboard | Horizon | Provides a web-based self-service portal to interact with underlying OpenStack services, such as launching an instance, assigning IP addresses and configuring access controls. |
| Compute service | Nova | Manages the lifecycle of compute instances in an OpenStack environment. Responsibilities include spawning, scheduling and decommissioning of virtual machines on demand. |
| Networking service | Neutron | Enables Network-Connectivity-as-a-Service for other OpenStack services, such as OpenStack Compute. Provides an API for users to define networks and the attachments into them. Has a pluggable architecture that supports many popular networking vendors and technologies. |
| Object Storage service | Swift | Stores and retrieves arbitrary unstructured data objects via a RESTful, HTTP based API. It is highly fault tolerant with its data replication and scale-out architecture. Its implementation is not like a file server with mountable directories. In this case, it writes objects and files to multiple drives, ensuring the data is replicated across a server cluster. |
| Block Storage service | Cinder | Provides persistent block storage to running instances. Its pluggable driver architecture facilitates the creation and management of block storage devices. |
| Identity service | Keystone | Provides an authentication and authorization service for other OpenStack services. Provides a catalog of endpoints for all OpenStack services. |
| Image service | Glance | Stores and retrieves virtual machine disk images. OpenStack Compute makes use of this during instance provisioning. |
| Telemetry service | Ceilometer | Monitors and meters the OpenStack cloud for billing, benchmarking, scalability, and statistical purposes. |
| Orchestration service | Heat | Orchestrates multiple composite cloud applications by using either the native HOT template format or the AWS CloudFormation template format, through both an OpenStack-native REST API and a CloudFormation-compatible Query API. |
| Database service | Trove | Provides scalable and reliable Cloud Database-as-a-Service functionality for both relational and non-relational database engines. |
| Data Processing service | Sahara | Provides capabilities to provision and scale Hadoop clusters in OpenStack by specifying parameters like Hadoop version, cluster topology and nodes hardware details. |
4.
本文会搭建一个AllInOne的OpenStack,并登陆Dashboard,创建project,搭建网络,上传image,launch一个虚拟机(虚拟机在OpenStack上专业术语叫instance),最后会给出调用OpenStack
Restful API来获取host主机信息,列出instance的代码实例。
5.
补充说明:使用AllInOne来搭建OpenStack是最简单直接的方法,因为基本上都是自动化的,无需手动配置各个组件。网上很多OpenStack
deploy的教程是多节点的部署,需要一个组件一个组件的安装和配置,由于操作系统版本的差异,以及OpenStack版本的差异,很容易出错。比如,很多教程是在CentOs
7.1上的,并且安装的是OpenStack的liberty版本,由于liberty版本现在已经不是最新的OpenStack版本,所以在安装时会出现无法从CentOS的repository里找到liberty版本的OpenStack
rpm错误。
二、搭建AllInOne模式的OpenStack
真实环境下的OpenStack是搭建在真实硬件上的,出于研究目的,本文将会在VMWARE虚拟机(目前最新的CentOs
7.4.1708
minimal)上搭建OpenStack。由于过程中有一些步骤容易出错,所以建议在安装之前给操作系统打好快照,以便后续出现莫名错误时能回退操作系统。
OpenStack all-in-one模式会将OpenStack的控制节点、计算节点和网络节点同时安装在一个机器上。这种模式可以快速配置,非常方便用于测试和开发。
接下来我们会使用RDO repository来安装OpenStack
all-in-one。这里简单介绍一下RDO:RDO是一个组织,这群人在CentOS和RedHat上使用和开发OpenStack。RDO提供了OpenStack安装的Repository,使用RDO方式来安装OpenStack会非常简单,因为几乎所有都是自动化的,一键式的。
请将虚拟机内存设置为>=8GB,安装过程中对内存的消耗比较大,当小于这个内存时,安装会失败,报错为:fork() failing with Out of memory (一般会在已经花费了半个多小时,安装快要结束时报这个错,会让人很奔溃)。
建议的虚拟机配置:
CPU:8核(大于等于4核,条件允许越大越好,因为OpenStack组件运行会消耗系统资源,你launch的instance也会消耗,作为基础平台,硬件要给力才行)
内存:16GB(大于等于8G)
硬盘:60GB(保险起见,建议>=100G)
网络:能surf the Internet(因为安装过程会从RDO repository下载按照包)
开始安装:
安装前,先看看当前的网络和系统信息(CentOS 7没有ifconfig,使用ip命令替代,若要使用ifconfig,需要安装:yum install net-tools.x86_64)
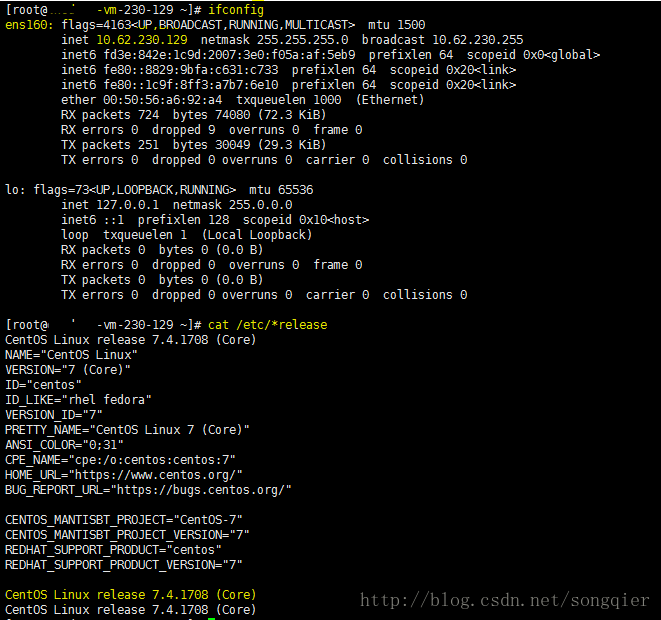
请切换到root用户,全程使用root用户来进行安装
1、 更新系统
1.1 命令行:yum update
更新过程中,如果更新了kernel,建议重启系统,如下:
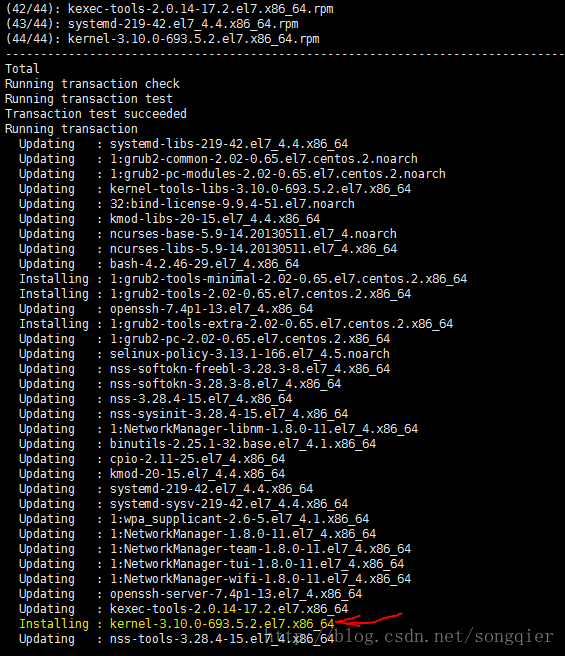
1.2 修改hostname(可选)
这个步骤在all-in-one模式下不是必须的,但是建议进行修改,如果后续需要将all-in-one扩展成多节点时,配置节点间通信,都会用到这个hostname。并且all-in-one的机器节点将会作为多节点中的controller节点,这里我们将hostname更改为controller-node。
(1)命令行:hostnamectl set-hostname controller-node
(2)将/etc/hosts手动更改为:
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 controller-node
::1 controller-node
注销当前登录,重新登录系统
2、 安装RDO库
安装前的yum repository:
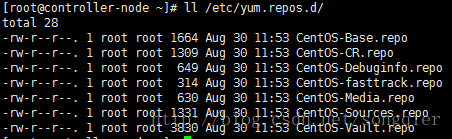
运行命令:yum install https://www.rdoproject.org/repos/rdo-release.rpm
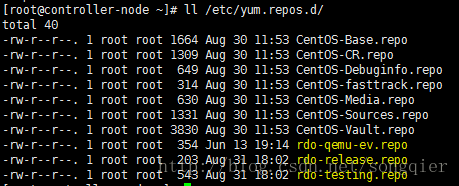
安装后的yum repository,多了RDO的三个库:
3、 安装packstack(自动化的OpenStack安装程序)
命令行:yum install openstack-packstack
4、 关掉NetworkManager并disable掉,防止这个服务更改我们的网络配置。
systemctl stop NetworkManager && systemctl disable NetworkManager
下面两个操作关掉SElinux和firewall是可选的,不关的话all-in-one也能成功。出于排除不必要干扰的考虑,建议将他们关掉。
(1)关掉SELinux
setenforce 0
修改/etc/selinux/config中:SELINUX=disabled
(2)关掉firewall
systemctl stop firewalld&& systemctl disable firewalld
5、 运行packstack开始自动化安装
Packstack安装有两种模式,一种是使用answer
file进行组件配置,另一种是直接进行all-in-one安装。前者可以通过packstack命令生成一个answer
file,在这个文件里自定义配置安装和不安装哪些组件,后者直接使用默认的allinone配置来安装。建议初次安装时使用后者。详细的answer
file模式,直接google:RDO packstack answer file
安装命令:packstack –allinone –provision-demo=n
–provision-demo=n的含义是不安装OpenStack的demo
project,否则安装完以后,登录Dashboard会看到已经存在一个叫demo的工程。后续我们会自己配置OpenStack的网络,再launch一个实例,出于排除掉这个demo的干扰的考虑,这里建议不安装它。(实际上,安装了,也不会影响我们后续的任何操作,这里只是为了简化而已)
整个安装过程可能会花费一个小时左右,这取决于你这台机器的配置。并且中途会到repository下载安装包,所以这个机器surf the Internet的速度也会大大影响安装时间。
整个安装过程会很消耗内存,这也是建议将虚拟机配置为>=8GB内存的原因所在,使用top可以看到,packstack在触发nova,glance,keystone等组件的逐个安装和check
available。并且内存使用量在蹭蹭的上涨,很快就会达到5G以上,峰值会逼近8G。
安装成功以后是这样的显示:
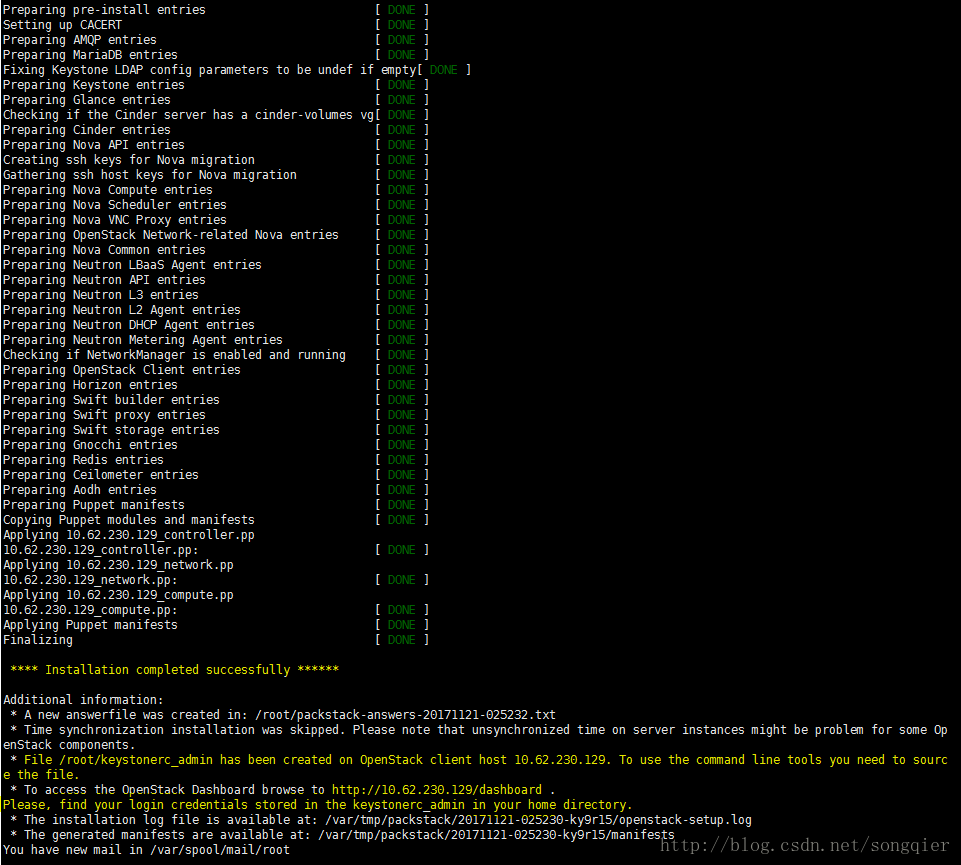
我的这次安装耗费了40分钟,请留意上面截图黄色高亮部分的内容。
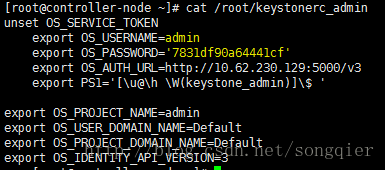
现在可以先登录Dashboard大致浏览一下OpenStack长啥样。登录的用户名和密码在CentOS系统/root/keystonerc_admin文件里。
登录后可以看到默认存在的project admin
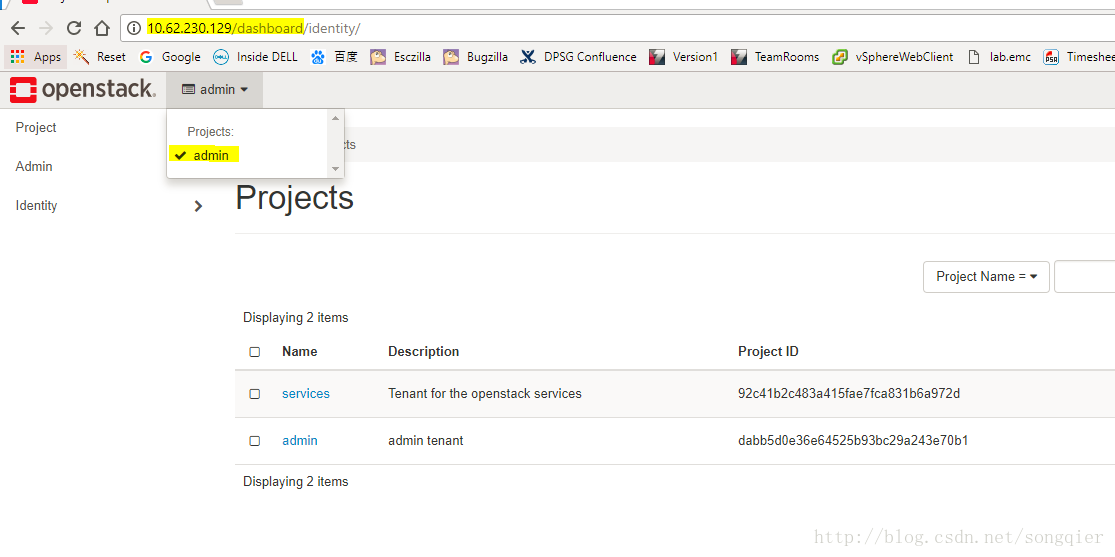
这是OpenStack最高权限的project,在这个project里可以看到compute
node的机器信息,可以查看所有project launch的instance等,而其他非admin的project是无法查看compute
node机器信息的(默认不允许,也许可以通过修改policy来给权限,目前简单查过方法,未果)。后面Restful
API的测试会通过admin来进行,当使用非admin的project时,会报错:ERROR: Policy doesn’t allow
os_compute_api:os-hypervisors to be performed. (HTTP 403)。
下一篇《在OpenStack中launch一个虚拟机实例》将讲解如何在OpenStack中配置和创建一个实例(instance,即虚拟机)
OpenStack 初探(一) -- All-In-One模式部署(初学OpenStack必备)的更多相关文章
- OpenStack三个节点icehouse-gre模式部署
一.环境准备 1.架构 创建3台虚拟机,分别作为controll节点.network节点和compute1节点. Controller节点:1processor,2G memory,5G storag ...
- 沉淀再出发:OpenStack初探
沉淀再出发:OpenStack初探 一.前言 OpenStack是IaaS的一种平台,通过各种虚拟化来提供服务.我们主要看一下OpenStack的基本概念和相应的使用方式. 二.OpenStack的框 ...
- openstack pike 集群高可用 安装 部署 目录汇总
# openstack pike 集群高可用 安装部署#安装环境 centos 7 史上最详细的openstack pike版 部署文档欢迎经验分享,欢迎笔记分享欢迎留言,或加QQ群663105353 ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- Apache Hadoop 2.9.2 的YARN High Available 模式部署
Apache Hadoop 2.9.2 的YARN High Available 模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.环境准备 1>.官方文档(htt ...
- Apache Hadoop 2.9.2 的HDFS High Available模式部署
Apache Hadoop 2.9.2 的HDFS High Available 模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道,当NameNode进程挂掉后,可 ...
- openstack项目【day24】:keystone部署及操作
阅读目录 一 前言 二 版本信息 三 部署keystone 四 keystone操作 五 验证 六 创建脚本 七 keystone使用套路总结 一 前言 任何软件的部署都是没有技术含量的,任何就部署讲 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
随机推荐
- 【spring boot】application.properties官方完整文档
官方地址: https://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/ 进入搜索: Appendice ...
- orm单表操作
二.orm简介 ORM:object relation mapping (ORM是“对象-关系-映射”的简称) MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦, ...
- Kafka笔记3
向Kafka写入消息从创建一个ProducerRecord对象开始,ProducerRecord需要包含目标主题和要发送的内容,我们还可以指定键或分区,在发送ProducerRecord对象时,生产者 ...
- 跟我学SpringCloud | 第一篇:介绍
首先讲一下我为什么要写这一系列的文章,现在网上大量的springcloud相关的文章,使用的springboot和springcloud的版本都相对比较老,很多还是在使用springboot1.x的版 ...
- MAC电脑修改Terminal以及vim高亮显示
1. Terminal高亮显示 编辑~/.bash_profile文件,在末尾增加两行: export CLICOLOR= export LSCOLORS=exfxcxdxcxegedabagacad ...
- springboot 集成完整的swagger2
springboot 在集成swagger中会不会遇到各种问题: 1.swagger 进行接口鉴权(比如设置header的token,接口进行拦截处理). 2.swagger 进行实体属性解析(po ...
- Spring Boot:使用Rabbit MQ消息队列
综合概述 消息队列 消息队列就是一个消息的链表,可以把消息看作一个记录,具有特定的格式以及特定的优先级.对消息队列有写权限的进程可以向消息队列中按照一定的规则添加新消息,对消息队列有读权限的进程则可以 ...
- selenium3+python3自动化测试学习之模拟事件处理
自动化测试实战之ActionChains模拟用户行为 需要模拟鼠标操作才能进行的情况,比如单击.双击.点击鼠标右键.拖拽 解决:selenium提供了一个类来处理这类事件 selenium.webdr ...
- denied: requested access to the resource is denied
1.vim /etc/docker/daemon.json 增加一个daemon.json文件 { "insecure-registries":["192.168 ...
- CSU 1811: Tree Intersection(线段树启发式合并||map启发式合并)
http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1811 题意:给出一棵树,每一个结点有一个颜色,然后依次删除树边,问每次删除树边之后,分开的两个 ...