重构 改善既有代码的设计 (Martin Fowler 著)
3.4 Long Parameter List (过长参数列)
3.9 Primitive Obsession (基本类型偏执)
3.10 Switch Statement (switch 惊悚现身)
3.11 Parallel InheritanceHierarchies (平行继承体系)
3.13 Speculative Generality (夸夸其谈未来性)
3.14 Temporary Field (令人迷惑的暂时字段)
3.15 Message Chains (过渡耦合的消息链)
3.17 Inappropriate Intimacy (狎昵关系)
3.18 Alternative Classes with Different Interfaces (易曲同工的类)
3.19 Incomplete Library Class (不完美的库类)
第6章 重新组织函数 (已看)
6.4 Replace Temp with Query (以查询取代临时变量)
6.5 Introduce Explaining Variable (引入解释性变量)
6.6 Split Temporary Variable (分解临时变量)
6.7 Remove Assignments to Parameters (移除对参数的赋值)
6.8 Replace Method with Method Object (以函数对象取代函数)
6.9 Substitute Algorithm (替换算法)
第7章 在对象之间搬移特性 (已看)
7.7 Introduce Foreign Method (引入外加函数)
7.8 Introduce Local Extension (引入本地扩展)
第8章 重新组织数据 (已看)
8.1 Self Encapsulate Field (自封装字段)
8.2 Replace Data Value with Object (以对象取代数据值)
8.3 Change Value to Reference (将值对象改为引用对象)
8.4 Change Reference to Value (将引用对象改为值对象)
8.5 Replace Array with Object (以对象取代数组)
8.6 Duplicate Observered Data (复制"被监视数据")
8.7 Change Unidirectional Association to Bidirectional (将单向关联改为双向关联)
8.8 Change Bidirectional Association to Unidirectional (将双向关联改为单向关联)
8.9 Replace Magic Number with Symbolic Constant (以字面常亮取代魔法数)
8.11 Encapsulate Collection (封装集合)
8.12 Replace Record with Data Class (以数据类取代记录)
8.13 Replace Type Code with Class (以类取代类型码)
8.14 Replace Type Code with Subclass (以子类取代类型码)
8.15 Replace Type Code with State/Strategy (以 State/Strategy 取代类型码)
8.16 Replace Subclass with Fields (以字段取代子类)
9.1 Decompose Conditional (分解条件表达式)
9.2 Consolidate Conditional Expression (合并条件表达式)
9.3 Consolidate Duplicate Conditional Fragments (合并重复的条件片段)
9.4 Remove Control Flag (移除控制标记)
9.5 Replace Nested Conditional with Guard Clauses (以卫语句取代嵌套条件表达式)
9.6 Replace Conditional with Polymorphism (以多态取代条件表达式)
9.7 Introduce Null Object (引入Null 对象)
9.8 Introduce Assertion (引入断言)
10.4 Separate Query from Modifier (将查询函数和修改函数分离)
10.5 Parameterize Method (令函数携带参数)
10.6 Replace Parameter with Explicit Methods (以明确函数取代参数)
10.7 Preserve Whole Object (保持对象完整)
10.8 Replace Parameter with Methods (以函数取代参数)
10.9 Introduce Parameter Object (引入参数对象)
10.10 Remove Setting Method (移除设值函数)
10.12 Replace Constructor with Factory Method (以工厂函数取代构造函数)
10.13 Encapsulate Downcast (封装向下转型)
10.14 Replace Error Code with Exception (以异常取代错误码)
10.15 Replace Exception with Test (以测试取代异常)
第11章 处理概括关系 (已看)
11.3 Pull Up Constructor Body (构造函数本体上移)
11.7 Extract Superclass (提炼超类)
11.9 Collapse Hierarchy (折叠继承体系)
11.10 Form Template Method (塑造模板函数)
11.11 Replace Inheritance with Delegation (以委托取代继承)
11.12 Replace Delegation with Inheritance (以继承取代委托)
12.1 Tease Apart Inheritance (梳理并分解继承体系)
12.2 Convert Procedural Design to Objects (将过程化设计转化为对象设计)
12.3 Separate Domain from Presentation (将领域和表达/显示分离)
12.4 Extract Hierarchy (提炼继承体系)
第1章 重构, 第一个案例
1.1 起点
1.2 重构的第一步
1.3 分解并重组 statement()
1.4 运用多态取代与价格相关的条件逻辑
1.5 结语
第2章 重构原则
2.1 何谓重构
2.2 为何重构
2.3 何时重构
2.4 怎么对经理说
2.5 重构的难题
2.6 重构与设计
2.7 重构与性能
2.8 重构与性能
2.9 重构起源何处
第3章 代码的坏味道
3.1 Duplicated Code (重复代码)
3.2 Long Method (过长函数)
3.3 Large Class (过大的类)
3.4 Long Parameter List (过长参数列)
3.5 Divergent Change (发散式变化)
3.6 Shotgun Surgery (霰弹式修改)
3.7 Feature Envy (依恋情结)
3.8 Data Clumps (数据泥团)
3.9 Primitive Obsession (基本类型偏执)
3.10 Switch Statement (switch 惊悚现身)
3.11 Parallel InheritanceHierarchies (平行继承体系)
3.12 Lazy Class (冗赘类)
3.13 Speculative Generality (夸夸其谈未来性)
3.14 Temporary Field (令人迷惑的暂时字段)
3.15 Message Chains (过渡耦合的消息链)
3.16 Middle Man (中间人)
3.17 Inappropriate Intimacy (狎昵关系)
3.18 Alternative Classes with Different Interfaces (易曲同工的类)
3.19 Incomplete Library Class (不完美的库类)
3.20 Data Class (纯稚的数据类)
3.21 Refused Bequest (被拒绝的遗赠)
3.22 Comments (过多的注释)
第4章 构筑测试体系
4.1 自测试代码的价值
4.2 JUnit测试框架
4.3 添加更多测试
第5章 重构列表
5.1 重构的记录格式
5.2 寻找引用点
5.3 这些重构手法有多成熟
第6章 重新组织函数
6.1 Extract Method (提炼函数)
你有一段代码可以被组织在一起并独立出来
将这段代码放进一个独立函数中, 并然函数名称解释该函数的用途
动机
Extract Method 是我最常用的重构方法之一. 当我看见一个过长的函数或者一段需要注释才能让人理解用途的代码, 我就会将这段代码放进一个独立函数中
有几个原因造成我喜欢简短而命名良好的函数. 首先, 如果每个函数的粒度都很小, 那么函数被复用的机会就更大; 其次, 这会使高层函数读起来就像一系列注释; 再次, 如果函数都是细粒度, 那么函数的覆写也会更容易些
的确, 如果你习惯看大型函数, 恐怕需要一段时间才能适应这种新风格. 而且只有当你能给小型函数很好地命名时, 它们才能真正起作用, 所以你需要在函数名称上下点功夫. 人们有时会问我, 一个函数多长才算合适?在我看来, 长度不是问题, 关键在于函数名称和函数本体之间的语义距离. 如果提炼可以强化代码的清晰度, 那就去做, 就算函数名称比提炼出来的代码还长也无所谓
范例: 无局部变量
void printOwing() {
Enumeration e = _orders.elements();
double outstanding = 0.0;
// print banner
System.out.println("********************");
System.out.println("**** Customer Owes ****");
System.out.println("*********************");
// calculate outstanding
while (e.hasMoreElements()) {
Order each = (Order)e.nextElement();
outstanding += each.getAmount();
}
// print details
System.out.println("name:" + _name);
System.out.println("amount:" + _outstanding);
}
范例: 有局部变量
void printOwing() {
Enumeration e = _orders.elements();
double outstanding = 0.0;
printBanner();
// calculate outstanding
while (e.hasMoreElements()) {
Order each = (Order)e.nextElement();
outstanding += each.getAmount();
}
// print details
System.out.println("name:" + _name);
System.out.println("amount:" + outstanding);
}
void printBanner() {
// print banner
System.out.println("********************");
System.out.println("**** Customer Owes ****");
System.out.println("********************");
}
范例: 对局部变量再赋值
void printOwing() {
Enumeration e = _orders.elements();
double outstanding = 0.0;
printBanner();
// calculate outstanding
while (e.hasMoreElements()) {
Order each = (Order)e.nextElement();
outstanding += each.getAmount();
}
// print details
System.out.println("name:" + _name);
System.out.println("amout:" + outstanding);
}
void printOwing() {
Enumeration e = _orders.elements();
double outstanding = 0.0;
printBanner();
// calculate outstanding
while (e.hasMoreElements()) {
Order each = (Order)e.nextElements();
outstanding += each.getAmount();
}
printDetails(outstanding);
}
void printDetails(double outstanding) {
System.out.println("name:" + _name);
System.out.println("amount:" + outstanding);
}
6.2 Inline Method (内联函数)
一个函数的本体与名称同样清楚易懂
在函数调用点插入函数本体, 然后移除该函数
int getRating() {
: ;
}
boolean moreThanFiveLateDeliveries() {
;
}
int getRating() {
) ? : ;
}
动机
本书经常以简短的函数表现动作意图, 这样会使代码 更清晰易懂. 但有时候你会遇到某些函数, 其内部代码和函数名称同样清晰易读. 也可能你重构了该函数, 使得其内容和其名称变得同样清晰. 果真如此, 你就应该去掉这个函数, 直接使用其中的代码. 间接性可能带来帮助, 但非必要的间接性总是让人不舒服
另一种需要使用 Inline Method 的情况是: 你手上有一群组织不甚合理的函数. 你可以将它们都内联到一个大型函数中, 再从中提炼出组织合理的小型函数. Kent Beck发现, 实施 Replace Method with Method Object 之前先这么做, 往往可以获得不错的效果. 你可以把所要的函数(有着你要的行为)的所有调用对象的函数内容都内联到函数对象中. 比起既要移动一个函数, 又要移动它所调用的其他所有函数, 将整个大型函数作为整体来移动会比较简单
如果别人使用了太多间接层, 使得系统中的所有函数都似乎只是对另一个函数的简单委托, 造成我在这些委托动作之间晕头转向, 那么我通常都会使用 Inline Method. 当然, 间接层有其价值, 但不是所有间接层都有价值. 试着使用内联手法, 我可以找出那些有用的间接层, 同时将那些无用的间接层去除
6.3 Inline Temp (内联临时变量)
你有一个临时变量, 只被一个简单表达式赋值一次, 而它妨碍了其他重构方法
将所有对该变量的引用动作, 替换为对它赋值的那个表达式自身
double basePrice = anOrder.basePrice(); ) )
动机
Inline Temp 多半是作为 Replace Temp with Query 的一部分使用的, 所以真正的动机出现在后者那儿. 唯一单独使用 Inline Temp 的情况是: 你发现某个临时变量被赋予某个函数调用的返回值. 一般来说, 这样的临时变量不会有任何危害, 可以放心地把它留在那儿. 但如果这个临时变量妨碍了其他的重构手法,例如 Extract Method, 你就应该将它内联化
6.4 Replace Temp with Query (以查询取代临时变量)
你的程序以一个临时变量保存某一表达式的运算结果
将这个表达式提炼到一个独立函数中. 将这个临时变量的所有引用点替换为对新函数的调用. 此后, 新函数就可被其他函数使用
double basePrice = _quantity * _itemPrice;
) {
return basePrice * 0.95;
} else {
return basePrice * 0.98;
}
) {
return basePrice() * 0.95;
} else {
return basePrice() * 0.98;
}
...
double basePrice() {
return _quantity * _itemPrice;
}
动机
临时变量的问题在于: 它们是暂时的, 而且只能在所属函数内使用. 由于临时变量只在所属函数内可见, 所以它们会驱使你写出更长的函数, 因为只有这样才能访问到需要的临时变量. 如果把临时变量替换为一个查询, 那么同一个类中的所有函数都将可以获得这份信息. 这将带给你极大帮助, 使你能够为这个类编写更清晰的代码
Replace Temp with Query 往往是你运用 Extract Method 之前必不可少的一个步骤. 局部变量会使代码难以被提炼, 所以你应该尽可能把它们替换为查询式.
这个重构手法较为简单的情况是: 临时变量只被赋值一次, 或者赋值给临时变量的表达式不受其他条件影响. 其他情况比较棘手, 但也有可能发生. 你可能需要先运用 Split Temporary Variable 或 Separate Query from Modifier 使情况变得简单一些, 然后再替换临时变量. 如果你想替换的临时变量是用来收集结果的(例如循环中的累加值),就需要将某些程序逻辑(如循环)复制到查询函数去.
范例
double getPrice() {
int basePrice = _quantity * _itemPrice;
double discountFactor;
) discountFactor = 0.95;
else discountFactor = 0.98;
return basePrice * discountFactor;
}
private int basePrice() {
return _quantity * _itemPrice;
}
private double discountFactor() {
) return 0.95;
else return 0.98;
}
double getPrice() {
return basePrice() * discountFactor();
}
6.5 Introduce Explaining Variable (引入解释性变量)
你有一个复杂的表达式
将该复杂表达式(或其中一部分)的结果放进一个临时变量, 以此变量名称来解释表达式用途
) &&
(browser.toUpperCase().indexOf() &&
wasInitialized() && resize > ) {
// do something
}
final boolean isMacOs = platform.toUpperCase().indexOf(;
final boolean isIEBrowser = browser.toUpperCase().indexOf(;
final boolean wasResized = resize > ;
if (isMacOs && isIEBrowser && wasInitialized() && wasResized) {
// do something
}
动机
表达式有可能非常复杂而难以阅读. 这种情况下, 临时变量可以帮助你将表达式分解为比较容易管理的形式
在条件逻辑中, Introduce Explaining Variable 特别有价值: 你可以用这项重构将每个条件子句提炼出来, 以一个良好命名的临时变量来解释对应条件子句的意义. 使用这项重构的另一种情况是, 在较长算法中, 可以运用临时变量来解释每一步运算的意义
Introduce Explaining Variable 是一个很常见的重构手法, 但我得承认, 我并不常用它. 我几乎总是尽量使用 Extract Method 来解释一段代码的意义. 毕竟临时变量只在它所处的那个函数中才有意义, 局限性较大, 函数则可以在对象的整个生命中都有用, 并且可被其他对象使用. 但有时候, 当局部变量使用 Extract Method 难以进行时, 我就使用 Introduce Explaining Variable
6.6 Split Temporary Variable (分解临时变量)
你的程序有某个临时变量被赋值超过一次, 它既不是循环变量, 也不被用于收集计算结果
针对每次赋值, 创造一个独立, 对应的临时变量
* (_height + _width); System.out.println(temp); temp = _height * _width; System.out.println(temp); final * (_height + _width); System.out.println(perimeter); final double area = _height * _width; System.out.println(area);
动机
临时变量有各种不同用途, 其中某些用途会很自然地导致临时变量被多次赋值. "循环变量"和"结果收集变量"就是两个典型例子: 循环变量(loop variable)[Beck]会随循环的每次运行而改变(例如 for(int i = 0; i < 10; i++) 语句中的i); 结果收集变量(collecting temporary variable)[Beck]负责将"通过整个函数的运算"而构成的某个值收集起来
除了这两种情况, 还有很多临时变量用于保存一段冗长代码的运算结果, 以便稍后使用. 这种临时变量应该只被赋值一次. 如果它们被赋值超过一次, 就意味着它们在函数中承担了一个以上的责任. 如果临时变量承担多个责任, 它就应该被替换(分解)为多个临时变量, 每个变量只承担一个责任. 同一个临时变量承担两件不同的事情, 会令代码阅读者糊涂
6.7 Remove Assignments to Parameters (移除对参数的赋值)
代码对一个参数进行赋值
以一个临时变量取代该参数的位置
int discount(int inputVal, int quantity, int yearToDate) {
) inputVal -= ;
int discount(int inputVal, int quantity, int yearToDate) {
int result = inputVal;
) result -= ;
6.8 Replace Method with Method Object (以函数对象取代函数)
你有一个大型函数, 其中对局部变量的使用使你无法采用 Extract Method
将这个函数放进一个单独对象中, 如此一来局部变量就成了对象内的字段. 然后你可以在同一个对象中将这个大型函数分解为多个小型函数
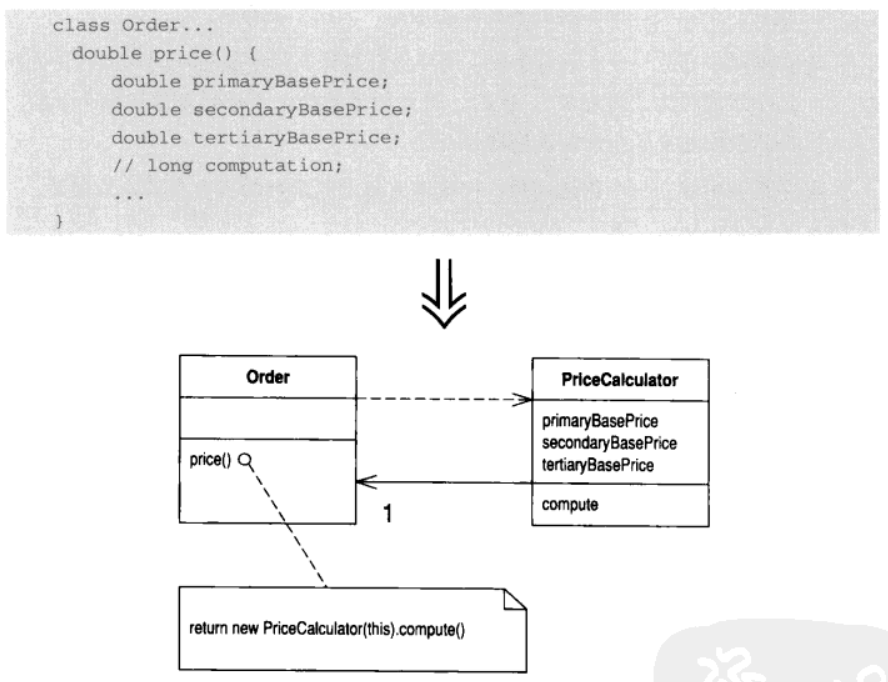
动机
我在本书中不断向读者强调小型函数的优美动人. 只要将相对独立的代码从大型函数中提炼出来, 就可以大大提高代码的可读性
但是, 局部变量的存在会增加函数分解难度, 如果一个函数之中局部变量泛滥成灾, 那么想分解这个函数是非常困难的. Replace Temp with Query 可以助你减轻这一负担, 但有时候你会发现根本无法拆解一个需要拆解的函数. 这种情况下, 你应该把手伸进工具箱的深处, 祭出函数对象(method object)[Beck]这件法宝
Replace Method with Method Object 会将所有局部变量都变成函数对象的字段. 然后你就可以对这个新对象使用 Extract Method 创造出新函数, 从而将原本的大型函数拆解变短
6.9 Substitute Algorithm (替换算法)
你想要把某个算法替换为另一个更清晰的算法
将函数本体替换为另一个算法
String foundPerson(String[] people) {
; i < people.length; i++) {
if (people[i].equals("Don")) {
return "Don";
}
if (people[i].equals("John")) {
return "John";
}
if (people[i].equals("Kent")) {
return "Kent";
}
}
return "";
}
String foundPerson(String[] people) {
List candidates = Arrays.asList(new String[] { "Don", "John", "Kent" }};
; i < people.length; i++) {
if (candidates.contains(people[i])) {
return people[i];
}
}
return "";
}
第7章 在对象之间搬移特性
7.1 Move Method (搬移函数)
你的程序中, 有个函数与其所驻类之外的另一个类进行更多交流: 调用后者, 或被后者调用
在该函数最常用引用的类中建立一个有着类似行为的新函数. 将旧函数变成一个单纯的委托函数, 或是将旧函数完全移除
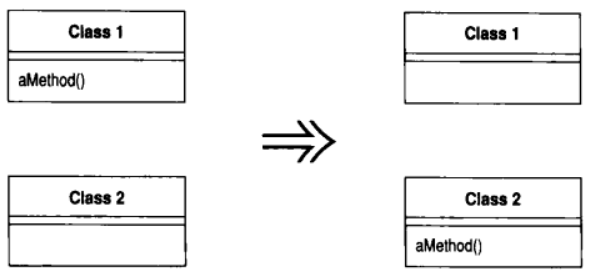
动机
"搬移函数"是重构理论的支柱, 如果一个类有太多行为, 或如果一个类与另一个类有太多合作而形成高度耦合, 我就会搬移函数. 通过这种手段, 可以使系统中的类更简单, 这些类最终也将更干净利落地实现系统交付的任务.
我常常会浏览类的所有函数, 从中寻找这样的函数: 使用另一个对象的次数比使用自己所驻对象的次数还多. 一旦我移动了一些字段, 就该做这样的检查, 一旦发现有可能搬移的函数, 我就会观察调用它的那一端, 它调用的那一端, 以及继承体系中它的任何一个重定义函数. 然后, 会根据"这个函数与哪个对象的交流比较多", 决定其移动路径
这往往不是容易做出的决定. 如果不能肯定是否应该移动一个函数, 我就会继续观察其他函数. 移动其他函数往往会让这项决定变得容易一些. 有时候, 即使你移动了其他函数, 还是很难对眼下这个函数做出决定. 其实这也没什么大不了的. 如果真地很难做出决定, 那么或许"移动这个函数与否"并不那么重要. 所以, 我会凭本能去做, 反正以后总是可以修改的
7.2 Move Field (搬移字段)
你的程序中, 某个字段被其所驻类之外的另一个类更多地用到
在目标类新建一个字段, 修改源字段的所有用户, 令它们改用新字段
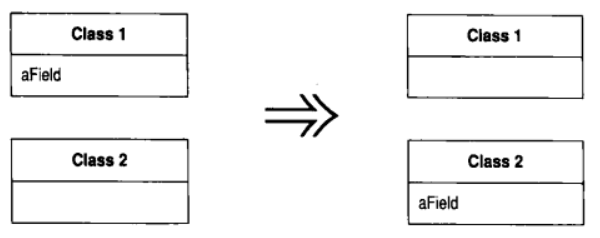
动机
在类之间移动状态和行为, 是重构过程中必不可少的措施. 随着系统发展, 你会发现自己需要新的类, 并需要将现有的工作责任拖到新的类中. 在这个星期看似合理而正确的设计决策, 到了下个星期可能不再正确. 这没问题. 如果你从来没遇到这种情况, 那才有问题
如果我发现, 对于一个字段, 在其所驻类之外的另一个类中有更多函数使用了它, 我就会考虑搬移这个字段. 上述所谓"使用"可能是通过设值/取值函数间接进行的. 我也可能移动该字段的用户(某个函数), 这取决于是否需要保持接口不受变化. 如果这些函数看上去很适合待在原地, 我就选择搬移字段
使用 Extract Class 时, 我也可能需要搬移字段. 此时我会先搬移字段, 然后再搬移函数
7.3 Extract Class (提炼类)
某个类做了应该由两个类做的事
建立一个新类, 将相关的字段和函数从旧类搬移到新类
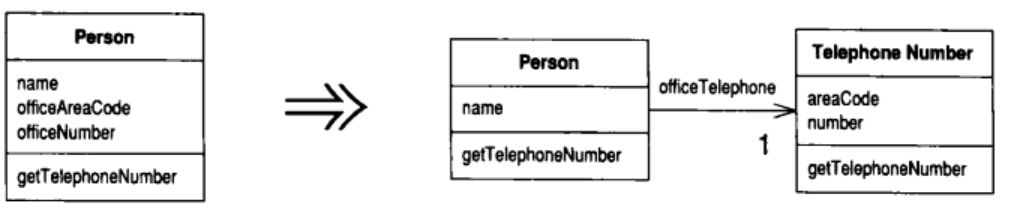
动机
你也许听过类似这样的教诲: 一个类应该是一个清楚的抽象, 处理一些明确的责任. 但是在实际工作中, 类会不断成长扩展. 你会在这儿加入一些功能, 在那儿加入一些数据. 给某个类给添加一项新责任时, 你会觉得不值得为这项责任分离出一个单独的类. 于是, 随着责任不断增加, 这个类会变得过分复杂. 很快, 你的类就会变成一团乱麻
这样的类往往含有大量函数和数据. 这样的类往往太大而不易理解. 此时你需要考虑哪些部分可以分离出去, 并将它们分离到一个单独的类中. 如果某些数据和某些函数总是一起出现, 某些数据经常同时变化甚至彼此相依, 这就表示你应该将它们分离出去. 一个有用的测试就是问你自己, 如果你搬移了某些字段和函数, 会发生什么事?其他字段和函数是否因此变得无意义?
另一个往往在开发后期出现的信号是类的子类化方式. 如果你发现子类化只影响类的部分特性, 或如果你发现某些特性需要以一种方式来子类化, 某些特性则需要以另一种方式子类化, 这就意味你需要分解原来的类
7.4 Inline Class (将类内联化)
某个类没有做太多事情
将这个类的所有特性搬移到另一个类中, 然后移除原类

动机
Inline Class 正好与 Extract Class 相反. 如果一个类不再承担足够责任, 不再有单独存在的理由(这通常是因为此前的重构动作移走了这个类的责任), 我就会挑选这一"萎缩类"的最频繁用户(也是个类), 以 Inline Class 手法将"萎缩类"塞进另一个类中.
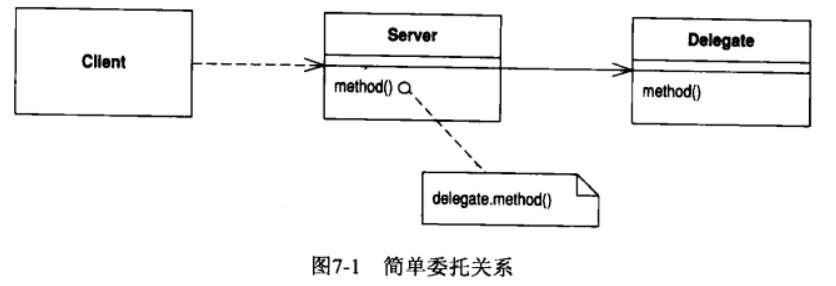
7.5 Hide Delegate (隐藏"委托关系")
客户通过一个委托类来调用另一个对象
在服务类上建立客户所需的所有函数, 用以隐藏委托关系

动机
"封装"即使不是对象的最关键特征, 也是最关键特征之一. "封装"意味每个对象都应该尽可能少了解系统的其他部分. 如此一来, 一旦发生了变化, 需要了解这一变化的对象就会比较少----这会使变化比较容易进行
任何学过对象技术的人都知道, 虽然Java允许将字段声明为public, 但你还是应该隐藏对象的字段. 随着经验日渐丰富, 你会发现, 有更多可以(而且值得)封装的东西
如果某个客户先通过服务对象的字段得到另一个对象, 然后调用后者的函数, 那么客户就必须知晓这一层委托关系. 万一委托关系发生变化, 客户也得相应变化. 你可以在服务对象上放置一个简单的委托关系, 将委托关系隐藏起来, 从而去除这种依赖. 这么一来, 即便将来发生委托关系上的变化, 变化也将被限制在服务对象中, 不会波及客户
对于某些或全部客户, 你可能会发现, 有必要先使用 Extract Class , 一旦你对所有客户都隐藏了委托关系, 就不再需要在服务对象的接口中公开被委托对象了.
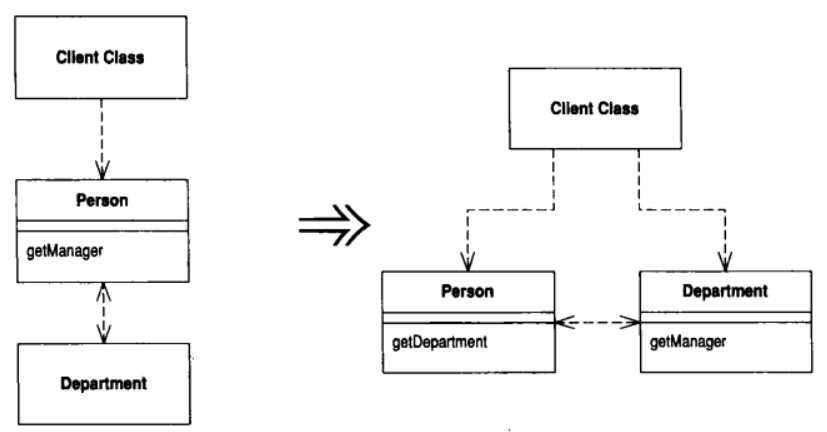
7.6 Remove Middle Man (移除中间人)
某个类做了过多的简单委托动作
让客户直接调用受托类
动机
在 Hide Delegate 的"动机"一节中, 我谈到了"封装受托对象"的好处. 但是这层封装也是要付出代价的, 它的代价就是: 每当客户要使用受托类的新特性时, 你就必须在服务端添加一个简单委托函数, 随着受托类的特性(功能)越来越多, 这一过程会让你痛苦不已. 服务类完全变成了一个"中间人", 此时你就应该让客户直接调用受托类
很难说什么程度的隐藏才是合适的. 还好, 有了 Hide Delegate 和 Remove Middle Man , 你大可不必操心这个问题, 因为你可以在系统运行过程中不断进行调整. 随着系统的变化, "合适的隐藏程度"这个尺度也相应改变. 6个月前恰如其分的封装, 现今可能就显得笨拙. 重构的意义就在于: 你永远不必说对不起----只要把出问题的地方修补好就行了
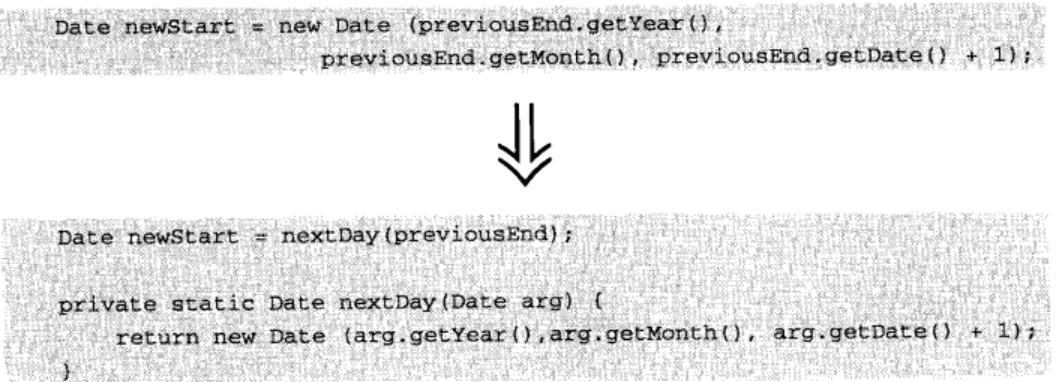
7.7 Introduce Foreign Method (引入外加函数)
你需要为提供服务的增加一个函数, 但你无法修改这个类
在客户类中建立一个函数, 并以第一参数形式传入一个服务类实例
动机
这种事情发生过太多次了: 你正在使用一个类, 它真的很好, 为你提供了需要的所有服务. 而后, 你又需要一项新服务, 这个类却无法供应. 于是你开始咒骂: "为什么不能做这件事?" 如果可以修改源码, 你便可以自行添加一个新函数; 如果不能, 你就得在客户端编码, 补足你要的那个函数
如果客户端只使用这项功能一次, 那么额外编码工作没什么大不了, 甚至可能根本不需要原本提供服务的那个类. 然而, 如果你需要多次使用这个函数, 就得不断重复这些代码. 还记得吗, 重复代码是软件万恶之源. 这些重复代码应该被抽出来放进同一个函数中. 进行本项重构时, 如果你以外加函数实现一项功能, 那就是一个明确信号: 这个函数原本应该在提供服务的类中实现
如果你发现自己为一个服务类建立了大量外加函数, 或者发现有许多类都需要同样的外加函数, 就不应该再使用本项重构, 而应该使用 Introduce Local Extension
但是不要忘记: 外加函数终归是权宜之计. 如果有可能, 你仍然应该将这些函数搬移到它们的理想家园. 如果由于代码所有权的原因使你无法做这样的搬移, 就把外加函数交给服务类的拥有者, 请他帮你在服务类中实现这个函数
7.8 Introduce Local Extension (引入本地扩展)
你需要为服务类提供一些额外函数, 但你无法修改这个类
建立一个新类, 使它包含这些额外函数. 让这个扩展品成为源类的子类或包装类

动机
很遗憾, 类的作者无法预知未来, 他们常常没能为你预先准备一些有用的函数, 如果你可以修改源码, 最好的办法就是直接加入自己需要的函数. 但你经常无法修改源码. 如果只需要一两个函数, 你可以使用 Introduce Foreign Method. 但如果你需要的额外函数超过两个, 外加函数就很难控制它们了. 所以, 你需要将这些函数组织在一起. 放到一个恰当地方去.要达到这一目的, 两种标准对象技术--- 子类化(subclassing) 和包装(wrapping)----是显而易见的办法. 这种情况下, 我把子类或包装类统称为本地扩展(local extension)
所谓本地扩展是一个独立的类, 但也是被扩展类的子类型: 它提供源类的一切特性, 同时额外添加新特性. 在任何使用源类的地方, 你都可以使用本地扩展取而代之
使用本地扩展使得你得以坚持"函数和数据应该被统一封装"的原则. 如果你一直把本该放在扩展类中的代码零散地放置于其他类中, 最终只会让其他这些类变得过分复杂, 并使得其中函数难以被复用
在子类和包装类之间做选择时, 我通常首选子类, 因为这样的工作量比较少. 制作子类的最大障碍在于, 它必须在对象创建期实施. 如果我可以接管对象创建过程, 那当然没问题; 但如果你想在对象创建之后再使用本地扩展, 就有问题了. 此外, 子类化方案还必须产生一个子类对象, 这种情况下, 如果有其他对象引用了旧对象, 我们就同时有两个对象保存了原数据! 如果原数据是不可修改的, 那也没问题, 我可以放心进行复制; 但如果原数据允许被修改, 问题就来了, 因为一个修改动作无法同时改变两份副本. 这时候我就必须改用包装类. 使用包装类时, 对本地扩展的修改会波及原对象, 反之亦然
第8章 重新组织数据
8.1 Self Encapsulate Field (自封装字段)
你直接访问了一个字段,但与字段之间的耦合关系逐渐变得笨拙
为这个字段建立取值/设值函数,并且只以这些函数来访问字段
private int _low, _high;
boolean includes(int arg) {
return arg >= _low && arg <= _high;
}
private int _low, _high;
boolean includes(int arg) {
return arg >= getLow() && arg <= getHigh();
}
int getLow() { return _low; }
int getHigh() { return _high; }
动机
在"字段访问方式"这个问题上, 存在两种截然不同的观点: 其中一派认为, 在该变量定义所在的类中, 你可以自由访问它; 另一派认为, 即使在这个类中你也应该只使用访问函数间接访问.两派之间的争论可以说是如火如荼
归根结底, 间接访问变量的好处是, 子类可以通过覆写一个函数而改变获取数据的途径, 它还支持更灵活的数据管理方式, 例如延迟初始化(意思是: 只有在需要用到某值时, 才对它初始化)
直接访问变量的好处则是: 代码比较容易阅读. 阅读代码的时候, 你不需要停下来说: "啊, 这只是个取值函数"
面临选择时, 我总是做两手准备. 通常情况下我会很乐意按照团队中其他人的意愿来做. 就我自己而言, 我比较喜欢先使用直接访问方式, 直到这种方式给我带来麻烦为止,此时我就会转而使用间接访问方式.重构给了我改变注意的自由
如果你想访问超类中的一个字段, 却又想在子类中将对这个变量的访问改为一个计算后的值,这就是最该使用 SelfEncapsulate Field 的时候. "字段自我封装"只是第一步. 完成自我封装之后, 你可以在子类中根据自己的需要随意覆写取值/设置函数
范例
class IntRange {
boolean includes(int arg) {
return arg >= getLow() && arg <= getHigh();
}
void grow(int factor) {
setHigh(getHigh() * factor);
}
private int _low, _high;
int getLow() {
return _low;
}
int getHigh() {
return _high;
}
void setLow(int arg) {
_low =arg;
}
void setHigh(int arg) {
_high = arg;
}
}
class CappedRange extends IntRange {
CappedRange(int low, int high, int cap) {
super(low, high);
_cap = cap;
}
int getCap() {
return _cap;
}
int getHigh() {
return Math.min(super.getHigh(), getCap());
}
}
8.2 Replace Data Value with Object (以对象取代数据值)
你有一个数据项, 需要与其他数据和行为一起使用才有意义
将数据项变成对象
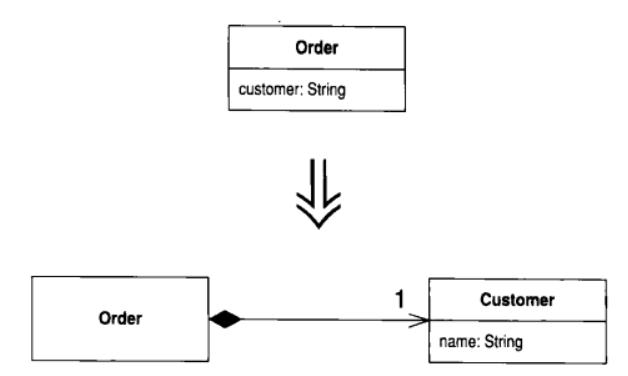
动机
开发初期, 你往往决定以简单的数据项表示简单的情况.但是, 随着开发的进行, 你可能会发现, 这些简单数据项不再那么简单了.比如说, 一开始你可能会用一个字符串来表示"电话号码"概念, 但是随后你就会发现, 电话号码需要"格式化", "抽取区号"之类的特殊行为.如果这样的数据项只有一两个, 你还可以把相关函数放进数据项所属的对象里; 但是Duplicate Code坏味道和Feature Envy坏味道很快就会从代码中散发出来. 当这些坏味道开始出现, 你就应该将数据值变成对象
范例
class Order...
public Order(String customer) {
_customer = customer;
}
public String getCustomer() {
return _customer;
}
public void setCustomer(String arg) {
_customer = arg;
}
private String _customer;
private static int numberOfOrdersFor(Collection orders, String customer) {
;
Iterator iter = orders.iterator();
while (iter.hasNext()) {
Order each = (Order)iter.next();
if (each.getCustoerm().equals(custoerm)) result++;
}
return result;
}
class Customer {
public Customer(String name) {
_name = name;
}
public String getName() {
return _name;
}
private final Stirng _name;
}
class Order...
public Order(String customer) {
_customer = new Customer(customer);
}
public String getCustomer() {
return _customer.getName();
}
private Customer _customer;
public void setCustomer(String arg) {
_customer = new Customer(arg);
}
8.3 Change Value to Reference (将值对象改为引用对象)
你从一个类衍生出许多彼此相等的实例, 希望将它们替换为同一个对象
将这个值对象变成引用对象
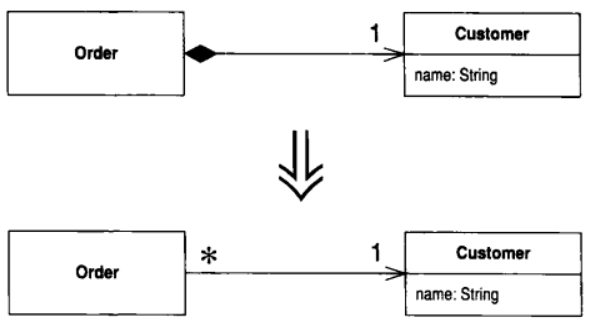
动机
在许多系统中, 你都可以对对象做一个有用的分类: 引用对象和值对象. 前者就像"客户", "账户" 这样的东西, 每个对象都代表真实世界中的一个实物, 你可以直接以相等操作符(==, 用来检验对象同一性)检查两个对象是否相等. 后者则是像"日期","钱"这样的东西, 它们完全由其所含的数据值来定义, 你并不在意副本的存在, 系统中或许存在成百上千个内容为"1/1/2000"的"日期"对象. 当然, 你也需要知道两个值对象是否相等, 所以你需要覆写equals()(以及hashCode())
要在引用对象和值对象之间做选择有时并不容易. 有时候, 你会从一个简单的值对象开始, 在其中保存少量不可修改的数据. 而后, 你可能会希望给这个对象加入一些可修改数据, 并确保对任何一个对象的修改都能影响到所有引用此一对象的地方. 这时候你就需要将这个对象变成一个引用对象
范例
class Customer {
public Customer(String name) {
_name = name;
}
public String getName() {
return _name;
}
private final String _name;
}
class Order...
public Order(String customerName) {
_customer = new Customer(customerName);
}
public void setCustomer(String customerName) {
_customer = new Customer(customerName);
}
public String getCustomerName() {
return _customer.getName();
}
private Customer _customer;
private static int numberOfOrdersFor(Collection orders, String customer) {
;
Iterator iter = orders.iterator();
while (iter.hasNext()) {
Order each = (Order)iter.next();
if (each.getCustomerName().equals(customer)) {
result++;
}
}
return result;
}
class Customer {
private Customer(String name) {
_name = name;
}
public static Customer create(String name) {
return new Customer(name);
}
}
class Order {
public Order(String customer) {
_customer = Customer.create(customer);
}
class Customer...
private static Dictionary _instances = new Hashtable();
static void loadCustomers() {
new Customer("Lemon Car Hire").store();
new Customer("Associated Coffee Machines").store();
new Customer("Bilston Gasworks").store();
}
private void store() {
_instances.put(this.getName(), this);
}
public static Customer create(String name) {
return (Customer)_instances.get(name);
}
public static Customer getNamed(Stirng name) {
return (Customer)_instances.get(name);
}
8.4 Change Reference to Value (将引用对象改为值对象)
你有一个引用对象, 很小且不可变, 而且不易管理
将它变成一个值对象
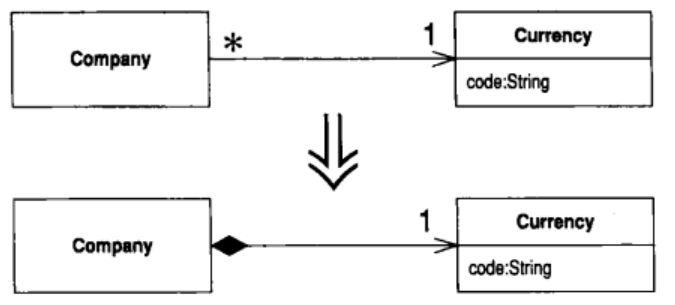
动机
正如我在 Change Value to Reference 中所说, 要在引用对象和值对象之间做选择, 有时并不容易. 做出选择后, 你常会需要一条回头路
如果引用对象开始变得难以使用, 也许就应该将它改为值对象. 引用对象必须被某种方式控制, 你总是必须向其控制者请求适当的引用对象. 它们可能造成内存区域之间错综复杂的关联. 在分布系统和并发系统中, 不可变的值对象特别有用. 因为你无需考虑它们的同步问题
值对象有一个非常重要的特性: 它们应该是不可变的. 无论何时, 只要你调用同一对象的同一个查询函数, 都应该得到同样结果. 如果保证了这一点, 就可以放心地以多个对象表示同一个事物. 如果值对象是可变的, 你就必须确保对某一对象的修改会自动更新其他"代表相同事物"的对象. 这太痛苦了, 与其如此还不如把它变成引用对象
这里有必要澄清一下"不可变"(immutable)的意思. 如果你以Money类表示"钱"的概念, 其中有"币种"和"金额"两条信息, 那么Money对象通常是一个不可变的值对象. 这并非意味你的薪资不能改变, 而是意味: 如果要改变你的薪资, 就需要使用另一个Money对象来取代现有的Money对象, 而不是在现有的Money对象上修改. 你和Money对象之间的关系可以改变, 但Money对象自身不能改变
范例
class Currency...
private String _code;
public String getCode() {
return _code;
}
private Currency(String code) {
_code = code;
}
Currency usd = Currency.get("USD");
new Currency("USD").equals(new Currency("USD"))
public boolean equals(Object arg) {
if (!(arg instanceof Currency)) return false;
Currency other = (Currency)arg;
return (_code.equals(other._code));
}
public int hashCode() {
return _code.hashCode();
}
new Currency("USD").equals(new Currency("USD"))
8.5 Replace Array with Object (以对象取代数组)
你有一个数组, 其中的元素各自代表不同的东西
以对象替换数组. 对于数组中的每个元素, 以一个字段来表示

动机
数组是一种常见的用以组织数据的结构. 不过, 它们应该只用于"以某种顺序容纳一组相似对象".有时候你会发现, 一个数组容纳了多种不同对象, 这会给用户带来麻烦, 因为他们很难记住像"数组的第一个元素是人名"这样的约定. 对象就不同了, 你可以运用字段名称和函数名称来传达这样的信息, 因此你无需死记它, 也无需依赖注释. 而且如果使用对象, 你还可以将信息封装起来, 并使用 Move Method 为它加上相关行为
8.6 Duplicate Observered Data (复制"被监视数据")
8.7 Change Unidirectional Association to Bidirectional (将单向关联改为双向关联)
两个类都需要使用对方特性, 但其间只有一条单向连接
添加一个反向指针, 并使修改函数能够同时更新两条连接
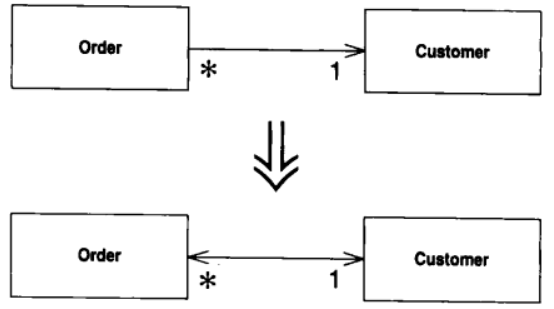
动机
开发初期, 你可能会在两个类之间建立一条单向连接, 使其中一个类可以引用另一个类. 随着时间推移, 你可能发现被引用类需要得到其引用者以便进行某些处理. 也就是说它需要一个反向指针. 但指针是一种单向连接, 你不可能反向操作它. 通常你可以绕道而行, 虽然会耗费一些计算时间, 成本还算合理, 然后你可以在被引用类中建立一个函数专门负责此一行为. 但是, 有时候向绕过这个问题并不容易, 此时就需要建立双向引用关系, 或称为反向指针. 如果使用不当, 反向指针很容易造成混乱; 但只要你习惯了这种手法, 它们其实并不是太复杂.
"反向指针" 手法有点棘手, 所以在你能够自如运用之前, 应该有相应的测试. 通常我不花心思去测试访问函数, 因为普通访问函数的风险没有高到需要测试的地步, 但本重构要求测试访问函数, 所以它是极少数需要添加测试的重构手法之一
本重构运用反向指针实现双向关联. 其他技术(例如连接对象)需要其他重构手法
范例
class Order...
Customer getCustomer() {
return _customer;
}
void setCustomer(Customer arg) {
_customer = arg;
}
Customer _customer;
class Customer {
private Set _orders = new HashSet();
class Order...
void setCustomer(Customer arg) {
if (_customer != null) {
_customer.friendOrders().remove(this);
}
_customer = arg;
if (_customer != null) {
_customer.friendOrders().add(this);
}
}
class Customer...
void addOrder(Order arg) {
arg.setCustomer(this);
}
class Order...
void addCustomer(Customer arg) {
arg.friendOrders().add(this);
_customers.add(arg);
}
void removeCustomers(Customer arg) {
arg.friendOrders().remove(this);
_customers.remove(arg);
}
class Customer...
void addOrder(Order arg) {
arg.addCustomer(this);
}
void removeOrder(Order arg) {
arg.removeCustomer(this);
}
8.8 Change Bidirectional Association to Unidirectional (将双向关联改为单向关联)
两个类之间有双向关联, 但其中一个类如今不再需要另一个类的特性.
去除不必要的关联
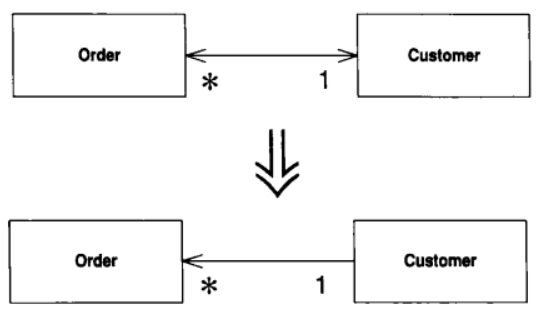
动机
双向关联很有用, 但你也必须为它付出代价, 那就是维护双向连接, 确保对象被正确创建和删除而增加的复杂度. 而且, 由于很多程序员并不习惯使用双向关联, 它往往称为错误之源
大量的双向连接也很容易造成"僵尸对象": 某个对象本来已经该死亡了, 却仍然保留在系统上, 因为对它的引用还没有完全清除
此外, 双向关联也迫使两个类之间有了依赖: 对其中任一个类的任何修改, 都可能引发另一个类的变化. 如果这两个类位于不同的包, 这种依赖就是包与包之间的相依. 过多的跨包依赖会造就紧耦合系统, 使得任何一点小小改动都可能造成许多无法预知的后果
只有在真正需要双向关联的时候, 才应该使用它. 如果发现双向关联不再有存在价值, 就应该去掉其中不必要的一条关联
范例
class Order...
Customer getCustomer() {
return _customer;
}
void setCustomer(Customer arg) {
if (_customer != null) {
_customer.friendOrders().remove(this);
}
_customer = arg;
if (_customer != null) {
_customer.friendOrders().add(this);
}
}
private Customer _customer;
class Customer...
void addOrder(Order arg) {
arg.setCustomer(this);
}
private Set _orders = new HashSet();
Set friendOrders() {
return _orders;
}
class Order...
double getDiscountedPrice() {
- _customer.getDiscount());
}
class Order...
double getDiscountedPrice(Customer customer) {
- customer.getDiscount());
}
class Customer...
double getPriceFor(Order order) {
Assert.isTrue(_orders.contains(order));
return order.getDiscountedPrice();
class Customer...
double getPriceFor(Order order) {
Assert.isTrue(_orders.contains(order));
return order.getDiscountedPrice(this);
}
class Order
Customer getCustomer() {
Iterator iter = Customer.getInstance().iterator();
while (iter.hasNext()) {
Customer each = (Customer)iter.next();
if (each.containsOrder(this)) return each;
}
return null;
}
8.9 Replace Magic Number with Symbolic Constant (以字面常亮取代魔法数)
你有一个字面数值, 带有特别含义
创造一个常量, 根据其意义为它命名, 并将上述的字面数值替换为这个常量

动机
在计算机科学中, 魔法数(magic number)是历史最悠久的不良现象之一. 所谓魔法数是指拥有特殊意义, 却又不能明确表现出这种意义的数字. 如果你需要在不同的地点引用同一个逻辑数, 魔法数会让你烦恼不已, 因为一旦这些数发生改变, 你就必须在程序中找到所有魔法数, 并将它们全部修改一遍, 这简直就是一场噩梦. 就算你不需要修改, 要准确指出每个魔法数的用途, 也会让你颇费脑筋
许多语言都允许你声明常量, 常量不会造成任何性能开销, 却可以大大提高代码的可读性
进行本项重构之前, 你应该先寻找其他替换方案. 你应该观察魔法数如何被使用, 而后你往往会发现一种更好的使用方式. 如果这个魔法数是个类型码, 请考虑使用 Replace Type Code with Class ; 如果这个魔法数代表一个数组的长度, 请在遍历该数组的时候, 改用 Array.length().
8.10 Encapsulate Field (封装字段)
你的类中存在一个public字段
将它声明为private, 并提供相应的访问函数

动机
面向对象的首要原则之一就是封装, 或者称为"数据隐藏". 按此原则, 你绝不应该将数据声明为public,否则其他对象就有可能访问甚至修改这项数据, 而拥有该数据的对象却毫无察觉. 于是, 数据和行为就被分开了----这可不是件好事
数据声明为public被看做是一种不好的做法, 因为这样会降低程序的模块化程度. 数据和使用该数据的行为如果集中在一起, 一旦情况发生变化, 代码的修改就会比较简单, 因为需要修改的代码都集中于同一块地方, 而不是星罗棋布地散落在整个程序中
Encapsulate Field 是封装过程的第一步, 通过这项重构手法, 你可以将数据隐藏起来, 并提供相应的访问函数. 但它毕竟只是第一步. 如果一个类除了访问函数外不能提供其他行为, 它终究只是一个哑巴类. 这样的类并不能享受对象技术带来的好处. 而你知道, 浪费任何一个对象都是很不好的. 实施 Encapsulate Field之后, 我会尝试寻找用到新建访问函数的代码, 看看是否可以通过简单的 Move Method 轻快地将它们移到新对象去
8.11 Encapsulate Collection (封装集合)
有个函数返回一个集合
让这个函数返回该集合的一个只读副本, 并在这个类中提供添加/移除集合元素的函数
动机
我们常常会在一个类中使用集合(collection, 可能是array, list, set或vector)来保存一组实例. 这样的类通常也会提供针对该集合的取值/设值函数
但是, 集合的处理方式应该和其他种类的数据略有不同. 取值函数不该返回集合自身, 因为这会让用户得以修改集合内容而集合拥有者却一无所悉.这也会对用户暴露过多对象内部数据结构的信息. 如果一个取值函数确实需要返回多个值, 它应该避免用户直接操作对象内所保存的集合, 并隐藏对象内与用户无关的数据结构. 至于如何做到这一点, 视你使用的Java版本不同而有所不同
另外, 不应该为这整个集合提供一个设置函数,但应该提供用以为集合添加/移除元素的函数. 这样, 集合拥有者(对象)就可以控制集合元素的添加和移除
如果你做到以上几点, 集合就被很好地封装起来了, 这便可以降低集合拥有者和用户之间的耦合度
8.12 Replace Record with Data Class (以数据类取代记录)
你需要面对传统编程环境中的记录结构
为该记录创建一个"哑"数据对象
动机
记录型结构是许多编程环境的共同性质. 有一些理由使它们被带进面向对象程序之中: 你可能面对的是一个遗留程序, 也可能需要通过一个传统API来与记录结构交流, 或是处理从数据库读出的记录. 这些时候你就有必要创建一个接口类, 用以处理这些外来数据. 最简单的做法就是先建立一个看起来类似外部记录的类, 以便日后将某些字段和函数搬移到这个类之中. 一个不太常见但非常令人注目的情况是: 数组中的每个位置上的元素都有特定含义, 这种情况下应该使用 Replace Array with Object
8.13 Replace Type Code with Class (以类取代类型码)
类之中有一个数值类型码, 但它并不影响类的行为
以一个新的类替换该数值类型码
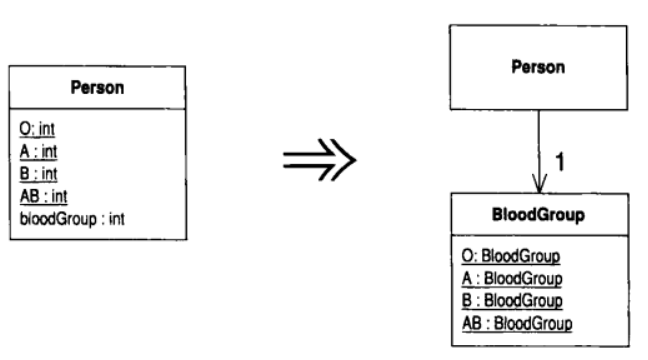
动机
在以C为基础的编程语言中, 类型码或枚举值很常见. 如果带着一个有意义的符号名, 类型码的可读性还是不错的. 问题在于, 符号名终究只是个别名, 编译器看见的, 进行类型检验的, 还是背后那个数值. 任何接受类型码作为参数的函数, 所期望的实际上是一个数值, 无法强制使用符号名. 这会大大降低代码的可读性, 从而成为bug之源
如果把那样的数值换成一个类, 编译器就可以对这个类进行类型检验.只要为这个类提供工厂函数, 你就可以始终保证只有合法的实例才会被创建出来, 而且它们都会被传递给正确的宿主对象
但是, 在使用 Replace Type Code with Class 之前, 你应该先考虑类型码的其他替换方式. 只有当类型码是纯粹数据时(也就是类型码不会在switch语句中引起行为变化时),你才能以类来取代它. Java只能以整数作为switch语句的判断依据, 不能使用任意类, 因此那种情况下不能够以类替换类型码. 更重要的是: 任何switch语句都应该运用 Replace Conditional with Polymorphism 去掉. 为了进行那样的重构, 你首先必须运用 Replace Type Code with Subclasses 或 Replace Type Code with State/Strategy, 把类型码处理掉
即使一个类型码不会因其数值的不同而引起行为上的差异, 宿主类中的某些行为还是有可能更适合置放于类型码类中, 因此你还应该留意是否有必要使用 Move Method 将一两个函数搬过去
8.14 Replace Type Code with Subclass (以子类取代类型码)
当然, 我总是避免使用switch语句. 但这里只有一处用到switch语句, 并且只用于决定创建何种对象, 这样的switch语句是可以接受的
8.15 Replace Type Code with State/Strategy (以 State/Strategy 取代类型码)
你有一个类型码, 它会影响类的行为, 但你无法通过继承手法消除它
以状态对象取代类型码
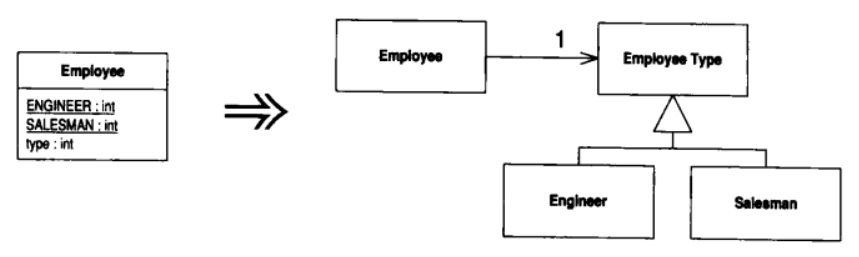
动机
本项重构和 Replace Type Code with Subclass 很相似, 但如果"类型码的值在对象生命周期中发生变化"或"其他原因使得宿主类不能被继承",你也可以使用本重构. 本重构使用State模式或Strategy模式
State模式和Strategy模式非常相似, 因此无论你选择其中哪一个, 重构过程都是相同的. "选择哪一个模式"并非问题关键所在, 你只需要选择更适合特定情境的模式就行了. 如果你打算在完成本项重构之后再以 Replace Conditional with Polymorphism 简化一个算法, 那么选择Strategy模式比较合适; 如果你打算搬移与状态相关的数据, 而且你把新建对象视为一种变迁状态, 就应该选择使用State模式
范例
class Employee {
private int _type;
;
;
;
Employee(int type) {
_type = type;
}
int payAmount() {
switch (_type) {
case ENGINEER:
return _monthlySalary;
case SALEMAN:
return _monthlySalary + _commission;
case MANAGER:
return _monthlySalary + _bonus;
default:
throw new RuntimeException("Incorrect Employee");
}
}
Employee(int type) {
setType(type);
}
int getType() {
return _type;
}
void setType(int arg) {
_type = arg;
}
int payAmount() {
switch (getType()) {
case ENGINEER:
return _monthlySalary;
case SALESMAN:
return _monthlySalary + _commission;
case MANAGER:
return _monthlySalary + _bonus;
default:
throw new RuntimeException("Incorrect Employee");
}
}
abstract class EmployeeType() {
abstract int getTypeCode();
}
class Engineer extends EmployeeType() {
int getTypeCode() {
return Employee.ENGINEER;
}
}
class Manager extends EmployeeType {
int getTypeCode() {
return Employee.MANAGER;
}
}
class Salesman extends EmployeeType {
int getTypeCode() {
return Employee.SALESMAN;
}
}
class Employee...
private EmployeeType _type;
int getType() {
return _type.getTypeCode();
}
void setType(int arg) {
switch (arg) {
case ENGINEER:
_type = new Engineer();
break;
case SALESMAN:
_type = new Salesman();
break;
case MANAGER:
_type = new Manager();
break;
default:
throw new IllegalArgumentException("Incorrect Employee Code");
}
}
class Employee...
void setType(int arg) {
_type = EmployeeType.newType(arg);
}
class EmloyeeType...
static EmployeeType newType(int code) {
swtich(code) {
case ENGINEER:
return new Engineer();
case SALESMAN:
return new Salesman();
case MANAGER:
return new Manager();
default:
throw new IllegalArgumentException("Incorrect Employee Code");
}
}
;
;
;
class Employee...
int payAmount() {
switch(getType()) {
case EmployeeType.ENGINEER:
return _monthlySalary;
case EmployeeType.SALESMAN:
return _monthlySalary + _commission;
case EmployeeType.MANAGER:
return _monthlySalary + _bonus;
default:
throw new RuntimeException("Incorrect Employee");
}
}
8.16 Replace Subclass with Fields (以字段取代子类)
你的各个子类的唯一差别只在"返回常量数据"的函数身上
修改这些函数, 使它们返回超类中的某个(新增)字段, 然后销毁子类
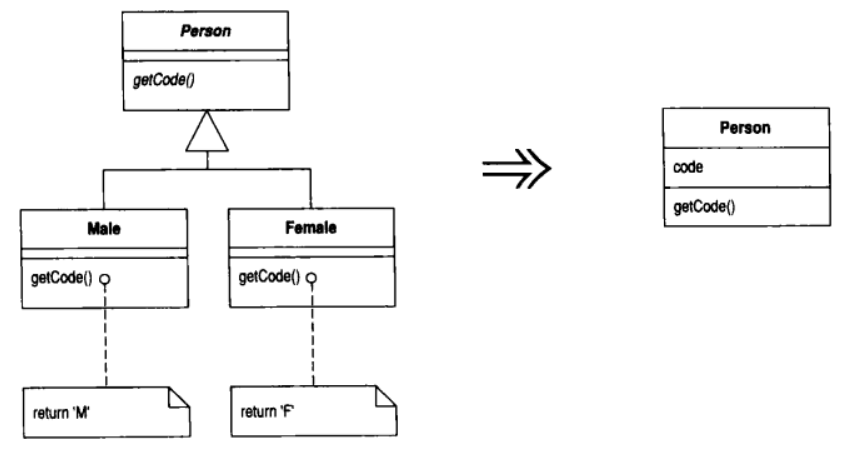
动机
建立子类的目的, 是为了增加新特性或变化其行为. 有一种变化行为被称为"常量函数"(constant method), 它们会返回一个硬编码的值. 这东西有其用途: 你可以让不同的子类中的同一访问函数返回不同的值. 你可以在超类中将访问函数声明为抽象函数, 并在不同的子类中让它返回不同的值.
尽管常量函数有其用途, 但若子类中只有常量函数, 实在没有足够的存在价值. 你可以在超类中设计一个与常量函数返回值相应的字段, 从而完全去除这样的子类. 如此一来就可以避免因继承而带来的额外复杂性
第9章 简化条件表达式
9.1 Decompose Conditional (分解条件表达式)
你有一个复杂的条件(if-then-else)语句.
从 if, then, else 三个段落中分别提炼出独立函数

动机
程序之中, 复杂的条件逻辑是最常导致复杂度上升的地点之一.你必须编写代码来检查不同的条件分支, 根据不同的分支做不同的事, 然后, 你很快就会得到
9.2 Consolidate Conditional Expression (合并条件表达式)
9.3 Consolidate Duplicate Conditional Fragments (合并重复的条件片段)
9.4 Remove Control Flag (移除控制标记)
9.5 Replace Nested Conditional with Guard Clauses (以卫语句取代嵌套条件表达式)
9.6 Replace Conditional with Polymorphism (以多态取代条件表达式)
9.7 Introduce Null Object (引入Null 对象)
9.8 Introduce Assertion (引入断言)
第10章 简化函数调用
10.1 Rename Method (函数改名)
函数的名称未能揭示函数的用途
修改函数名称
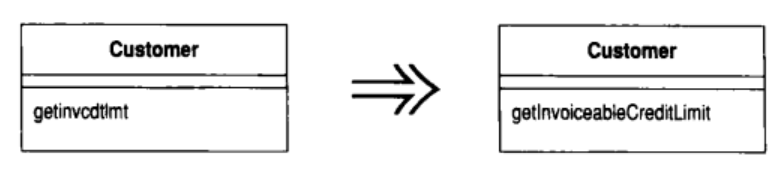
动机
我极力提倡的一种编程风格就是: 将复杂的处理过程分解为小函数. 但是, 如果做的不好,这会使你费尽周折却弄不清楚这些小函数各自的用途.要避免这种麻烦, 关键在于给函数起一个好名称. 函数的名称应该准确表达它的用途. 给函数命名有一个好办法: 首先考虑应该给这个函数写上一句怎样的注释, 然后想办法将注释变成函数名称
生活就是如此, 你常常无法第一次就给函数起一个好名称. 这时候你可能会想: 就这样将就着吧, 毕竟只是一个名称而已. 当心! 这是恶魔的召唤, 是通向混乱之路, 千万不要被它诱惑! 如果你看到一个函数名称不能很好地表达它的用途, 应该马上加以修改. 记住, 你的代码首先是为人写的, 其次才是为计算机写的. 而人需要良好名称的函数. 想想过去曾经浪费的无数时间吧. 如果给每个函数都起一个良好的名称, 也许你可以节约好多时间. 起一个好名称并不容易, 需要经验: 想要成为一个真正的编程高手, 起名的水平是至关重要的. 当然, 函数签名中的其他部分也一样重要. 如果重新安排参数顺序, 能够帮助提高代码的清晰度, 那就大胆地去做吧, 你有 Add Parameter 和 Remove Parameter 这两项武器
10.2 Add Parameter (添加参数)
某个函数需要从调用端得到更多信息
为此函数添加一个对象参数, 让该对象带进函数所需信息
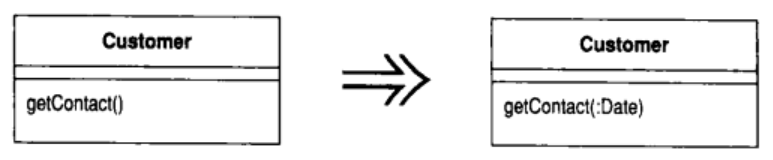
Add Parameter 是一个很常用的重构方法, 我几乎可以肯定你已经用过它了. 使用这项重构的动机很简单: 你必须修改一个函数, 而修改后的函数需要一些过去没有的信息, 因此你需要给该函数添加一个参数
实际上我比较需要说明的是: 不使用本重构的时机. 除了添加参数外, 你常常还有其他选择. 只要可能, 其他选择都比添加参数要好, 因为它们不会增加参数列的长度. 过长的参数列是不好的味道, 因为程序员很难记住那么多参数, 而且长参数列往往伴随着坏味道 Data Clumps
请看看现有的参数, 然后问自己: 你能从这些参数得到所需的信息吗? 如果回答是否定的, 有可能通过某个函数提供所需信息吗? 你究竟把这些信息用于何处? 这个函数是否应该属于拥有该信息的那个对象所有? 看看现有参数, 考虑一下, 加入新参数是否合适? 也许你应该考虑使用 Introduce Parameter Object
我并非要你绝对不要添加参数. 事实上我自己经常添加参数, 但是在添加参数之前你有必要了解其他选择
10.3 Remove Parameter (移除参数)
函数本体不再需要某个参数
将该参数去除
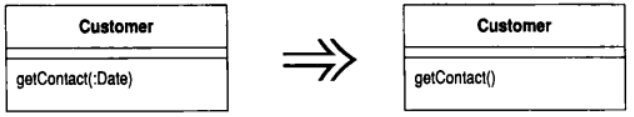
程序员可能经常添加参数, 却往往不愿意去掉它们. 他们打的如意算盘是: 无论如何, 多余的参数不会引起任何问题, 而且以后还可能用上它
这也是恶魔的诱惑, 一定要把它从脑子里赶出去! 参数代表着函数所需的信息, 不同的参数值有不同的意义. 函数调用者必须为每一个参数操心该传什么东西进去. 如果你不去掉多余参数, 就是让你的每一位用户多费一份心. 是很不划算的, 更何况"去除参数"是非常简单的一项重构
但是, 对于多态函数, 情况有所不同. 这种情况下, 可能多态函数的另一份(或多份)实现会使用这个参数, 此时你就不能去除它. 你可以添加一个独立函数, 在这些情况下使用, 不过你应该先检查调用者如何使用这个函数, 以决定是否值得这么做. 如果某些调用者已经知道他们正在处理的是一个特定的子类, 并且已经做了额外工作找出自己需要的参数, 或已经利用对类体系的了解来避免取到null, 那么就值得你建立一个新函数, 去除那多余的参数. 如果调用者不需要了解该函数所属的类, 你也可以继续保持调用者无知而幸福的状态.
10.4 Separate Query from Modifier (将查询函数和修改函数分离)
某个函数既返回对象状态值, 又修改对象状态
建立两个不同的函数, 其中一个负责查询, 另一个负责修改

动机
如果某个函数只是向你提供一个值, 没有任何看得到的副作用, 那么这是个很有价值的东西. 你可以任意调用这个函数, 也可以把调用动作搬到函数的其他地方. 简而言之, 需要操心的事情少多了
明确表现出"有副作用"与"无副作用"两种函数之间的差异, 是个很好的想法. 下面是一条好规则: 任何有返回值的函数, 都不应该有看得到的副作用. 有些程序员甚至将此作为一条必须遵守的规则[Meyer]. 就像对待任何东西一样, 我并不绝对遵守它, 不过我总是尽量遵守, 而它也回报我很好的效果
如果你遇到一个"既有返回值又有副作用"的函数, 就应该试着将查询动作从修改动作中分割出来.
10.5 Parameterize Method (令函数携带参数)
若干函数做了类似的工作, 但在函数本体中却包含了不同的值
建立单一函数, 以参数表达那些不同的值
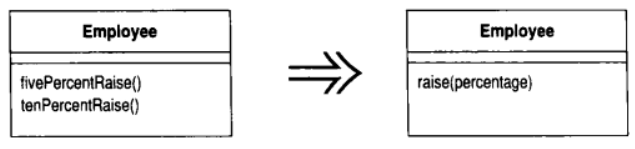
动机
你可能会发现这样的两个函数: 它们做着类似的工作, 但因少数几个值致使行为略有不同. 这种情况下, 你可以将这些各自分离的函数统一起来, 并通过参数来处理那些变化情况, 用以简化问题. 这样的修改可以去除重复的代码, 并提高灵活性, 因为你可以用这个参数处理更多的变化情况
范例
class Employee {
void tenPercentRaise() {
salary *= 1.1;
}
void fivePercentRaise() {
salary *= 1.05;
}
}
void raise(double factor) {
salary *= ( + factor);
}
protected Dollars baseCharge() {
) * 0.03;
) {
result += (Math.min(lastUsage(), ) - ) * 0.05;
}
) {
result += (lastUsage() - ) * 0.07;
}
return new Dollars(result);
}
protected Dollars baseCharge() {
, ) * 0.03;
result += usageInRange(, ) * 0.05;
result += usageInRange(, Integer.MAX_VALUE) * 0.07;
return new Dollars(result);
}
protected int usageInRange(int start, int end) {
if (lastUsage() > start) return Math.min(lastUsage(), end) - start;
;
}
本项重构的要点在于: 以"可将少量数值视为参数"为依据, 找出带有重复性的代码
10.6 Replace Parameter with Explicit Methods (以明确函数取代参数)
你有一个函数,其中完全取决于参数值而采取不同行为
针对该参数的每一个可能值, 建立一个独立函数
void setValue(String name, int value) {
if (name.equals("height")) {
_height = value;
return;
}
if (name.equals("width")) {
_width = value;
return;
}
Assert.shouldNeverReachHere();
}
void setHeight(int arg) {
_height = arg;
}
void setWidth(int arg) {
_width = arg;
}
动机
Replace Parameter with Explicit Methods 恰恰相反于 Parameterize Method. 如果某个参数有多种可能的值, 而函数又以条件表达式检查这些参数值, 并根据不同参数值做出不同的行为, 那么就应该使用本项重构. 调用者原本必须赋予参数适当的值, 以决定该函数做出何种响应. 现在, 既然你提供了不同的函数给调用者使用, 就可以避免出现条件表达式. 此外你还可以获得编译期检查的好处, 而且接口也更清楚. 如果以参数值决定函数行为, 那么函数用于不但需要观察该函数, 而且还要判断参数值是否合法, 而"合法的参数值"往往很少在文档中被清楚地提出.
就算不考虑编译期检查的好处, 只是为了获得一个清晰的接口, 也值得你执行本项重构. 哪怕只是给一个内部的布尔变量赋值, 相较之下, Switch.beOn()也比 Switch.setState(true)要清楚得多
但是, 如果参数值不会对函数行为有太多影响, 你就不应该使用 Replace Parameter with Explicit Methods . 如果情况真是这样, 而你也只需要通过参数为一个字段赋值, 那么直接使用设值函数就行了. 如果的确需要条件判断的行为, 可考虑使用 Replace Conditional with Polymorphism
范例
;
;
;
static Employee create(int type) {
switch (type) {
case ENGINEER:
return new Engineer();
case SALESMAN:
return new Saleman();
case MANAGER:
return new Manager();
default:
throw new IllegalArgumentException("Incorrect type code value");
}
}
static Employee createEngineer() {
return new Engineer();
}
statice Employee createSalesman() {
return new Salesman();
}
static Employee createManager() {
return new Manager();
}
Employee kent = Employee.create(ENGINEER);
Employee kent = Employee.createEngineer();
10.7 Preserve Whole Object (保持对象完整)
10.8 Replace Parameter with Methods (以函数取代参数)
10.9 Introduce Parameter Object (引入参数对象)
10.10 Remove Setting Method (移除设值函数)
10.11 Hide Method (隐藏函数)
有一个函数, 从来没有被其他任何类用到
将这个函数修改为private

动机
重构往往促使你修改函数的可见度, 提高函数的可见度的情况很容易想象; 另一个类需要用到某个函数, 因此你必须提高该函数的可见度. 但是要指出一个函数的可见度是否过高, 就稍微困难一些. 理想状况下, 你可以使用工具检查所有函数, 指出可被隐藏起来的函数. 即使没有这样的工具, 你也应该时常进行这样的检查
一种特别常见的情况是: 当你面对一个过于丰富, 提供了过多行为的接口时, 就值得将非必要的取值函数和设置函数隐藏起来. 尤其当你面对的是一个只有简单封装的数据容器时, 情况更是如此. 随着愈来愈多行为被放入这个类, 你会发现许多取值/设置函数不再需要公开, 因此可以把它们隐藏起来, 如果你把取值/设值函数设为private, 然后在所有地方都直接访问变量, 那就可以放心移除取值/设置函数了
10.12 Replace Constructor with Factory Method (以工厂函数取代构造函数)
10.13 Encapsulate Downcast (封装向下转型)
10.14 Replace Error Code with Exception (以异常取代错误码)
10.15 Replace Exception with Test (以测试取代异常)
第11章 处理概括关系(generalization, 即继承关系)
11.1 Pull Up Field (字段上移)
两个子类拥有相同的字段
将该字段移至超类
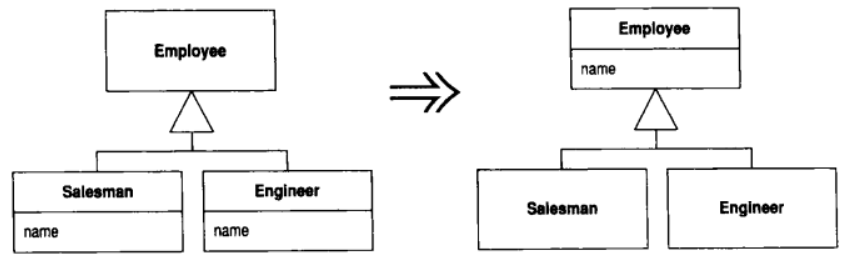
动机
如果各子类是分别开发的, 或者是在重构过程中组合起来的, 你常会发现它们拥有重复特性, 特别是字段更容易重复. 这样的字段有时拥有近似的名字, 但也并非绝对如此. 判断若干字段是否重复, 唯一的办法就是观察函数如何使用它们. 如果它们被使用的方式很相似, 你就可以将它们归纳到超类去
本项重构从两方面减少重复: 首先它去除了重复的数据声明; 其次它使你可以将使用该字段的行为从子类移至超类, 从而去除重复的行为
11.2 Pull Up Method (函数上移)
有些函数, 在各个子类中产生完全相同的结果
将该函数移至超类

动机
避免行为重复是很重要的. 尽管重复的两个函数也可以各自工作得很好, 但重复自身只会成为错误得滋生地, 此外别无价值. 无论何时, 只要系统之内出现重复, 你就会面临"修改其中一个却未能修改另一个"的风险. 通常, 找出重复也有一定困难.
如果某个函数在各子类中的函数体都相同(它们很可能是通过复制粘贴得到的), 这就是显而易见的 Pull Up Method 适用场合. 当然, 情况并不总是如此明显. 你也可以只管放心地重构, 再看看测试程序会不会发牢骚, 但这就需要对你的测试有充分的信心. 我发现, 观察这些可能重复的函数之间的差异往往大有收获: 它们经常会向我展示那些我忘记测试的行为
Pull Up Method 常常紧随其他重构而被使用. 也许你能找出若干个身处不同子类内的函数, 而它们又可以通过某种形式的参数调整成为相同的函数. 这时候, 最简单的办法就是首先分别调整这些函数的参数, 然后再将它们概括到超类中, 当然, 如果你足够自信, 也可以一次完成这两个步骤
有一种特殊情况也需要使用Pull Up Method: 子类的函数覆写了超类的函数,但却仍然做相同的工作
Pull Up Method 过程中最麻烦的一点就是: 被提升的函数可能会引用只出现于子类而不出现于超类的特性. 如果被引用的是个函数, 你可以将该函数也一同提升到超类,或者在超类中建立一个抽象函数. 在此过程中, 你可能需要修改某个函数的签名, 或建立一个委托函数
如果两个函数相似但不相同, 你或许可以先借助 Form Template Method 构造出相同的函数, 然后再提升它们
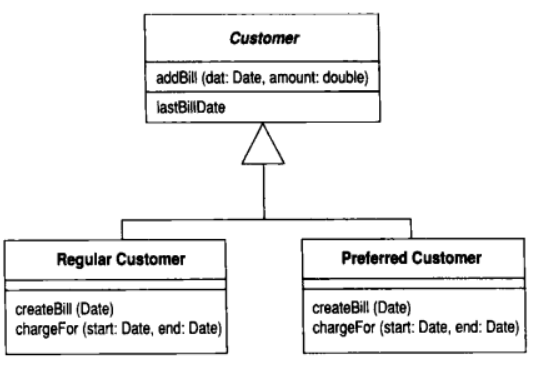
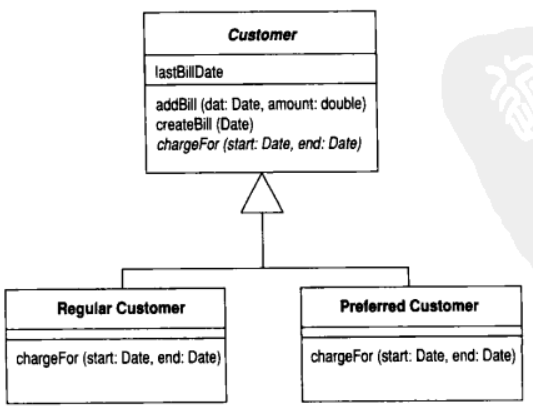
void createBill(date Date) {
double chargeAmount = chargeFor(lastBillDate, date);
addBill(date, charge);
}
class Customer...
abstract double chargeFor(date start, date end)
11.3 Pull Up Constructor Body (构造函数本体上移)
你在各个子类中拥有一些构造函数, 它们的本体几乎完全一致
在超类中新建一个构造函数, 并在子类构造函数中调用它
class Manager extends Employee...
public Manager(String name, String id, int grade) {
_name = name;
_id = id;
_grade = grade;
}
public Manager(String name, String id, int grade) {
super(name, id);
_grade = grade;
}
动机
构造函数是很奇妙的东西. 它们不是普通函数, 使用它们比使用普通函数受到更多的限制
如果你看见各个子类中的函数有共同行为, 第一个念头应该是将共同行为提炼到一个独立函数中, 然后将这个函数提升到超类. 对构造函数而言, 它们彼此的共同行为往往就是"对象的建构". 这时候你需要在超类中提供一个构造函数, 然后让子类都来调用它. 很多时候, 子类构造函数的唯一动作就是调用超类构造函数. 这里不能运用 Pull Up Method , 因为你无法在子类中继承超类构造函数(你可曾痛恨过这个规定?)
如果重构过程过于复杂, 你可以考虑转而使用 Replace Constructor with Factory Method
11.4 Push Down Method (函数下移)
超类中的某个函数只与部分(而非全部)子类有关
将这个函数移到相关的那些子类去
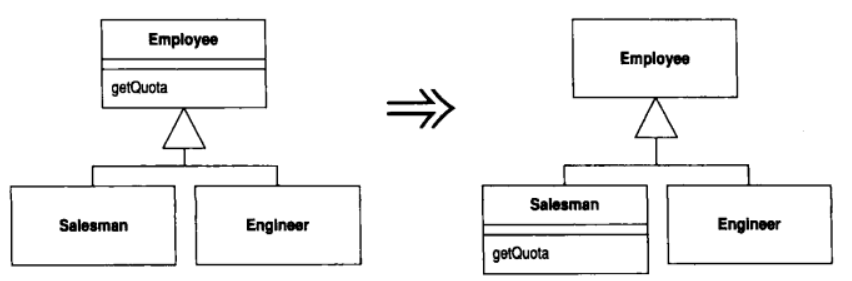
动机
Push Down Method 与 Pull Up Method 恰恰相反. 当我有必要吧某些行为从超类移至特定的子类时, 我就使用 Push Down Method, 它通常也只在这种时候有用. 使用 Extract Subclass 之后你可能会需要它
11.5 Push Down Field (字段下移)
超类中的某个字段只被部分(而非全部)子类用到
将这个字段移到需要它的那些子类去
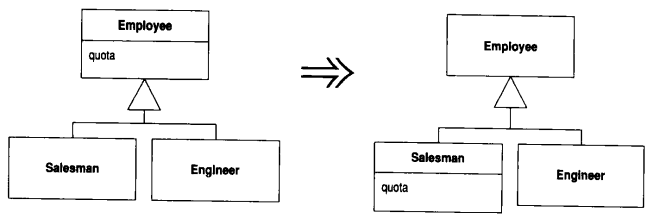
动机
Push Down Field 与 Pull Up Field 恰恰相反, 如果只有某些(而非全部)子类需要超类内的一个字段, 你可以使用本项重构
11.6 Extract Subclass (提炼子类)
11.7 Extract Superclass (提炼超类)
11.8 Extract Interface (提炼接口)
11.9 Collapse Hierarchy (折叠继承体系)
11.10 Form Tem Plate Method (塑造模板函数)
11.11 Replace Inheritance with Delegation (以委托取代继承)
某个子类只使用超类接口中的一部分, 或是根本不需要继承而来的数据
在子类中新建一个字段用以保存超类; 调整子类函数, 令它改而委托超类; 然后去掉两者之间的继承关系
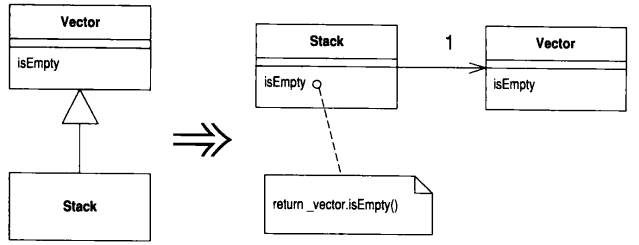
动机
继承是个好东西, 但有时候它并不是你要的. 你常常会遇到这样的情况: 一开始继承了一个类, 随后发现超类中的许多操作并不真正适用于子类. 这种情况下, 你所拥有的接口并未真正反映出子类的功能. 或者, 你可能发现从超类中继承了一大堆子类并不需要的数据, 抑或你可能发现超类中的某些protected 函数对子类并没有什么意义
你可以选择容忍, 并接受传统说法: 子类可以只使用超类功能的一部分. 但这样做的结果是: 代码传达的信息与你的意图南辕北辙----这是一种混淆 你应该将它去除
如果以委托取代继承, 你可以更清楚地表明: 你只需要委托类的一部分功能.接口中的哪一部分应该被使用, 哪一部分应该被忽略, 完全由你主导控制.这样做的成本则是需要额外写出委托函数, 但这些函数都非常简单, 极少可能出错
范例
class MyStack extends Vector {
public void push(Object element) {
insertElementAt(element, );
}
public Object pop() {
Object result = firstElement();
removeElementAt();
return result;
}
}
class MyStack...
private Vector _vector = new Vector();
public int size() {
return _vector.size();
}
public boolean isEmpty() {
return _vector.isEmpty();
}
public void push(Object element) {
_vector.insertElementAt(element, );
}
public Object pop() {
Object result = _vector.firstElement();
_vector.removeElementAt();
return result;
}
11.12 Replace Delegation with Inheritance (以继承取代委托)
你在两个类之间使用委托关系, 并经常为整个接口编写许多极简单的委托函数
让委托类继承受托类

动机
本重构与 Replace Inheritance with Delegation 恰恰相反. 如果你发现自己需要使用受托类中的所有函数, 并且费了很大力气编写所有极简的委托函数, 本重构可以帮助你轻松回头使用继承
两条告诫需牢记于心. 首先, 如果你并没有使用受托类的所有函数, 那么就不应该使用 Replace Delegation Inheritance, 因为子类应该总是遵循超类的接口. 如果过多的委托函数让你烦心, 你有别的选择: 你可以通过 Remove Middle Man 让客户端自己调用受托函数, 也可以使用 Extract Superclass 将两个类接口相同的部分提炼到超类中, 然后让两个类都继承这个新的超类; 你还可以用类似的手法使用 Extract Interface
另一种需要当心的情况是: 受托对象被不止一个其他对象共享, 而且受托对象是可变的. 在这种情况下, 你就不能将委托关系替换为继承关系, 因为这样就无法再共享数据了. 数据共享是必须由委托关系承担的一种责任, 你无法把它转给继承关系. 如果受托对象是不可变的, 数据共享就不成问题, 因为你大可放心地复制对象, 谁都不会知道
class Employee {
Person _person = new Person();
public String getName() {
return _person.getName();
}
public void setName(String arg) {
_person.setName(arg);
}
public String toString() {
return "Emp: " + _person.getLastName();
}
}
class Person {
String _name;
public String getName() {
return _name;
}
public void setName(String arg) {
_name = arg;
}
public String getLastName() {
);
}
}
class Employee extends Person
public String toString() {
return "Emp: " + getLastName();
}
第12章 大型重构
12.1 Tease Apart Inheritance (梳理并分解继承体系)
12.2 Convert Procedural Design to Objects (将过程化设计转化为对象设计)
12.3 Separate Domain from Presentation (将领域和表达/显示分离)
12.4 Extract Hierarchy (提炼继承体系)
第13章 重构, 复用与现实
13.1 现实的检验
13.2 为什么开发者不愿意重构他们的程序
13.3 再论现实的检验
13.4 重构的资源和参考资料
13.5 从重构联想到软件复用和技术传播
13.6 小结
13.7 参考文献
第14章 重构工具
14.1 使用工具进行重构
14.2 重构工具的技术标准
14.3 重构工具的使用标准
14.4 小结
第15章 总结
参考书目
[Auer]
Ken.Auer "Reusability through Self-Encapulation." In Pattern Languages of Program Desgin 1, edited by J.O. Coplien and .D.C Schmidt. Reading, Mass.: Addison-Wesley, 1995.
一篇关于"自我封装"概念的模式论文
[Baumer and Riehle]
Baumer, Dirk, and Dirk Riehle. "Product Trader." In Pattern Languages of Program Design 3, edited by R.Martin, E Buschmann, and D.Riehle. Reading, Mass.: Addison-Wesley, 1998
一个模式, 用来灵活创建对象而不需要知道对象隶属哪个类
[Beck]
Beck, Kent. Smalltalk Best Practice Patterns. Upper Saddle River, N.J.: Prentice Hall, 1997a
一本适合任何Smalltalker的基本图书, 也是一本对任何面向对象开发者很有用的图书. 谣传有Java版本
[Beck, hanoi]
Beck, Kent. "Make it Run, Make it Right: Design Through Refactoring." The Smalltalk Report, 6:(1997b): 19~24
第一本真正领悟"重构过程如何运作"的出版物, 也是本书第1章许多构想的源头
[Beck, XP]
Beck, Kent. eXtreme Programming eXplained: Embrace Change. Reading, Mass.: Addison-Wesley, 2000.
[Fowler, UML]
Fowler, M., with K. Scott. UML Distilled, Second Edition: A Brief Guide to the Standard Object Modeling Language. Reading, Mass.: Addison-Wesley, 2000.
一本简明扼要的导引, 助你了解本书中各式各样的UML图
[Fowler, AP]
Fowler, M. Analysis Patterns: Reusable Object Models. Reading, Mass.:Addison-Wesley, 1997.
一本领域建模模式专著, 包括对Range模式的讨论
[Gang of Four]
Gamma, E., R. Helm, R. Johnson, and J. Vlissides. Desgin Patterns: Elements of Reusable Object Oriented Software. Reading, Mass.: Addison-Wesley, 1995.
或许是面向对象设计领域中最有价值的一本书. 现今几乎任何人都必须语带智慧地谈点 Strategy, Singleton和Chain of Responsibility, 才敢说自己懂得对象技术
[Jackson, 1993]
Jackson, Michael. Michael Jackson's Beer Guide, Mitchell Beazley, 1993.
一本有用的导引, 提供大量实用的研究
[Java Spec]
Gosling, James, Bill Joy, and Guy Steele. The Java Language Specifications, Second Edition. Boston, Mass.: Addison-Wesley, 2000
所有Java问题的官方答案
[JUnit]
Beck, Kent, and Erich Gamma. JUnit Open-Source Testing Framework. Available on the Web(http://www.junit.org)
撰写Java程序的基本应用工具. 是个简单框架, 帮助你撰写, 组织, 运行单元测试. 类似的框架也存在于Smalltalk和C++中
[Lea]
Lea, Doug. Concurrent Programming in Java: Desgin Principles and Patterns, Reading, Mass.: Addison-Wesley, 1997.
编译器应该禁止任何没有读过这本书的人实现Runnable接口
[McConnell]
McConnel, Steve. Code Complete: A Practical Handbook of Software Construction. Redmond, Wash.: Microsoft Press, 1993.
一本对于编程风格和软件建构的卓越导引. 写于Java诞生之前, 但几乎书中的所有忠告都适用于Java
[Meyer]
Meyer, Bertrand. Object Oriented Software Construction. 2 ed. Upper Saddle River, N.J.: Prentice Hall, 1997.
面向对象设计领域中一本很好(也很庞大)的图书, 其中包括对于契约式设计的详尽讨论
[Opdyke]
Opdyke, William F. "Refactoring Object-Oriented rameworks." Ph.D. diss., University of Illinois at Urbana-Champaign, 1992
参见ftp://st.cs.uiuc.edu/pub/papers/refactoring/opdyke-thesis.ps.Z, 是关于重构的第一份体面长度的著作. 多少带点教育和工具导向的角度(毕竟这是一篇博士论文),对于想更多了解重构理论的人, 是很有价值的读物
[Refactoring Browser]
Brant, John, and Don Roberts. Refactoring Browser Tool,
http://st-www.cs.uiuc.edu/~brant/RefactoringBrowser. 未来的软件开发工具
[Woolf]
Woolf, Boddy. "Null Object." In Pattern Languages of Program Desgin 3, edited by R.Martin, F.Buschmann, and D. Riehle. Reading, Mass.: Addison-Wesley, 1998.
针对Null Object模式的讨论
重构 改善既有代码的设计 (Martin Fowler 著)的更多相关文章
- 【转】PHP 杂谈《重构-改善既有代码的设计》之一 重新组织你的函数
原文地址: PHP 杂谈<重构-改善既有代码的设计>之一 重新组织你的函数 思维导图 点击下图,可以看大图. 介绍 我把我比较喜欢的和比较关注的地方写下来和大家分享.上次我写 ...
- 《重构--改善既有代码的设计》总结or读后感:重构是程序员的本能
此文写得有点晚,记得去年7月读完的这本书,只是那时没有写文章的意识,也无所谓总结了,现在稍微聊一下吧. 想起写这篇感想,还是前几天看了这么一篇文章 研究发现重构软件并不会改善代码质量 先从一个大家都有 ...
- 《重构——改善既有代码的设计》【PDF】下载
<重构--改善既有代码的设计>[PDF]下载链接: https://u253469.ctfile.com/fs/253469-231196358 编辑推荐 重构,一言以蔽之,就是在不改变外 ...
- 【重构.改善既有代码的设计】14、总结&读后感
14.总结 首先,这是一本太老的书,很多观点已经被固化或者过时了.但核心观点没有问题,虽然大多数观点已经被认为是理所当然的事情了. 重构的定义 重构分几种: 1.狭义的代码重构 就是本书讲的, ...
- 『重构--改善既有代码的设计』读书笔记----Extract Method
在编程中,比较忌讳的一件事情就是长函数.因为长函数代表了你这段代码不能很好的复用以及内部可能出现很多别的地方的重复代码,而且这段长函数内部的处理逻辑你也不能很好的看清楚.因此,今天重构第一个手法就是处 ...
- 『重构--改善既有代码的设计』读书笔记---Duplicate Observed Data
当MVC出现的时候,极大的推动了Model与View分离的潮流.然而对于一些已存在的老系统或者没有维护好的系统,你都会看到当前存在大把的巨大类----将Model,View,Controller都写在 ...
- 『重构--改善既有代码的设计』读书笔记----Replace Array with Object
如果你有一个数组,其中的元素各自代表不同东西,比如你有一个 QList<QString> strList; 其中strList[0]代表选手姓名,strList[1]代表选手家庭住址,很显 ...
- 『重构--改善既有代码的设计』读书笔记----Change Value to Reference
有时候你会认为某个对象应该是去全局唯一的,这就是引用(Reference)的概念.它代表当你在某个地点对他进行修改之后,那么所有共享他的对象都应该在再次访问他的时候得到相应的修改.而不会像值对象(Va ...
- 『重构--改善既有代码的设计』读书笔记----Self Encapsulate Field
如果你直接访问一个字段,你就会和这个字段直接的耦合关系变得笨拙.也就是说当这个字段权限更改,或者名称更改之后你的客户端代码都需要做相应的改变,此时你可以为这个字段建立设值和取值函数并且只以这些函数来访 ...
随机推荐
- 洛谷 P5686 [CSP-SJX2019]和积和
传送门 思路 应用多个前缀和推出式子即可 \(30pts\): 首先如果暴力算的话很简单,直接套三层循环就好了(真的是三层!!最后两个\(sigma\)一起算就好了) \[\sum_{l = 1}^{ ...
- BERT-wwm、BERT-wwm-ext、RoBERTa、SpanBERT、ERNIE2
一.BERT-wwm wwm是Whole Word Masking(对全词进行Mask),它相比于Bert的改进是用Mask标签替换一个完整的词而不是子词,中文和英文不同,英文中最小的Token就是一 ...
- CF750G New Year and Binary Tree Paths(DP)
神仙题.为啥我第一眼看上去以为是个普及题 路径有两种,第一种是从 LCA 一边下去的,第二种是从 LCA 两边都下去了的. 先考虑第一种. 先枚举路径长度 \(h\). 当 LCA 编号是 \(x\) ...
- 趣谈Linux操作系统学习笔记:第二十五讲
一.mmap原理 在虚拟内存空间那一节,我们知道,每一个进程都有一个列表vm_area_struct,指向虚拟地址空间的不同内存块,这个变量名字叫mmap struct mm_struct { str ...
- Sublime和VSCode生成基础HTML代码
我们在编写前端页面时,常希望能自动生成基础的HTML代码.而在Sublime和VSCode就有这样的功能 在Sublime中,在编辑栏输入html,然后敲Tab键,则自动生成代码如下: <!DO ...
- 黄聪:PHP转换网址相对路径到绝对路径的一种方法
相信很多程序(尤其是采集类的程序)都会有需要把网址的相对路径转换成绝对路径的需要,例如采集到某页面的HTML代码中包含资源文件经常会看到这样的文件名: <link rel="style ...
- NET EF 连接Oracle 的配置方法记录
主要记录下如何在EF 中连接Oracle s数据库,很傻瓜式,非常简单,但是不知道的童鞋,也会搞得很难受,我自己就是 1.创一个控制台程序,并且添加 Oracle.ManagedDataAccess ...
- C#用Call代替CallVirt之后的测试用例
一. C# 原始代码和直接结果 测试 C# 代码: class Program { static void Main(string[] args) { A c1 = new C(); c1.Foo() ...
- Java关键字之abstract、final、static用法
abstract:即抽象的,可以修饰类.方法: 修饰类:当有一个方法为抽象方法时,这个类就是抽象类,抽象类不能被new,它是一个不完整的类. 修饰方法:这个方法就是抽象的,即只能方法的定义,没有方法的 ...
- 连接常见错误linker command failed with exit code 1 (use -v to see invocation)
这种问题,通常出现在添加第三方库文件或者多人开发时. 这种问题一般是找不到文件而导致的链接错误. 我们可以从如下几个方面着手排查. 1.以如下错误为例,如果是多人开发,你同步完成后发现出现如下的错误. ...