Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label
页面显示如下:
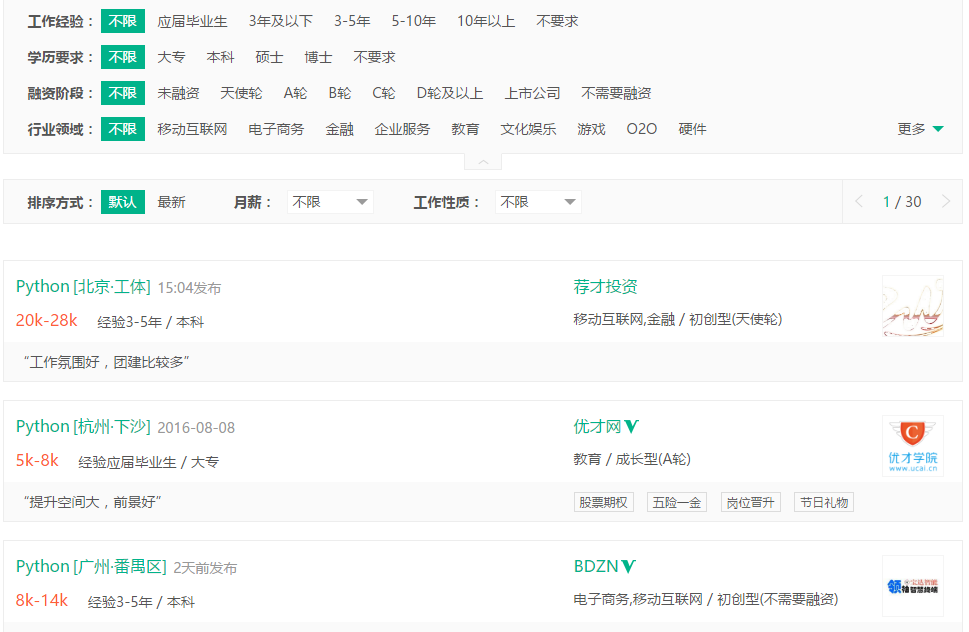
在Chrome浏览器中审查元素,找到对应的链接:

然后依次针对相应的链接(比如上面显示的第一个,链接为:http://www.lagou.com/jobs/2234309.html),打开之后查看,下面是我想具体爬取的每个公司岗位相关信息:
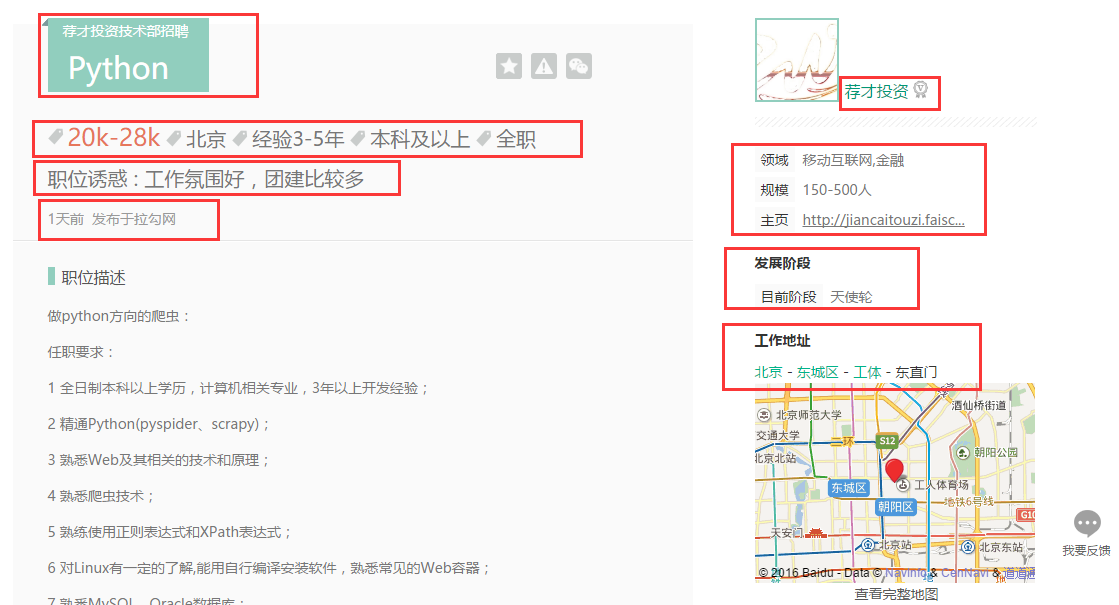
针对想要爬取的内容信息,找到html代码标签位置:
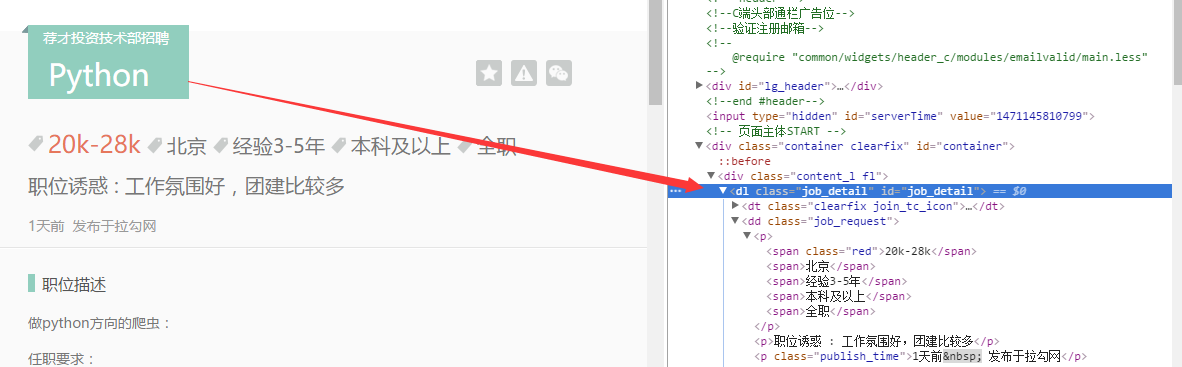
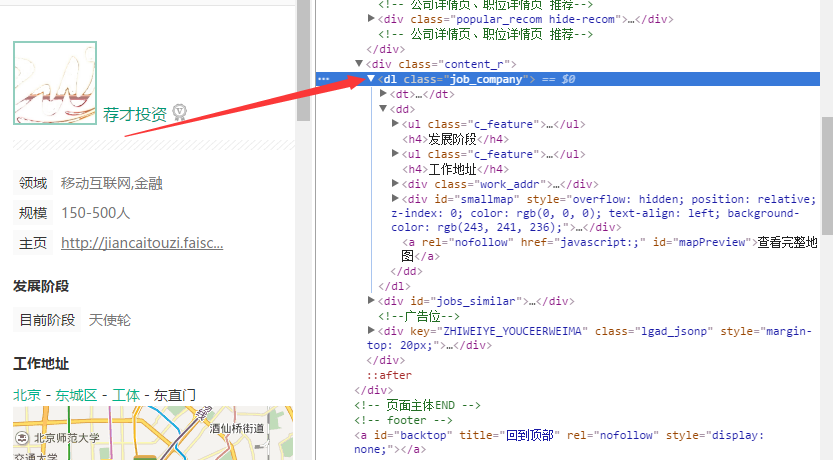
找到了相关的位置之后,就可以进行爬取的操作了。
以下是代码部分
# -*- coding:utf-8 -*- import urllib
import urllib2
from bs4 import BeautifulSoup
import re
import xlwt # initUrl = 'http://www.lagou.com/zhaopin/Python/?labelWords=label'
def Init(skillName):
totalPage = 30
initUrl = 'http://www.lagou.com/zhaopin/'
# skillName = 'Java'
userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
headers = {'User-Agent':userAgent} # create excel sheet
workBook = xlwt.Workbook(encoding='utf-8')
sheetName = skillName + ' Sheet'
bookSheet = workBook.add_sheet(sheetName)
rowStart = 0
for page in range(totalPage):
page += 1
print '##################################################### Page ',page,'#####################################################'
currPage = initUrl + skillName + '/' + str(page) + '/?filterOption=3'
# print currUrl
try:
request = urllib2.Request(currPage,headers=headers)
response = urllib2.urlopen(request)
jobData = readPage(response)
# rowLength = len(jobData)
for i,row in enumerate(jobData):
for j,col in enumerate(row):
bookSheet.write(rowStart + i,j,col)
rowStart = rowStart + i +1
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
xlsName = skillName + '.xls'
workBook.save(xlsName) def readPage(response):
btfsp = BeautifulSoup(response.read())
webLinks = btfsp.body.find_all('div',{'class':'p_top'})
# webLinks = btfsp.body.find_all('a',{'class':'position_link'})
# print weblinks.text
count = 1
jobData = []
for link in webLinks:
print 'No.',count,'==========================================================================================='
pageUrl = link.a['href']
jobList = loadPage(pageUrl)
# print jobList
jobData.append(jobList)
count += 1
return jobData def loadPage(pageUrl):
currUrl = 'http:' + pageUrl
userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
headers = {'User-Agent':userAgent}
try:
request = urllib2.Request(currUrl,headers=headers)
response = urllib2.urlopen(request)
content = loadContent(response.read())
return content
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason def loadContent(pageContent):
# print pageContent
btfsp = BeautifulSoup(pageContent)
# job infomation
job_detail = btfsp.find('dl',{'id':'job_detail'})
jobInfo = job_detail.h1.text
tempInfo = re.split(r'(?:\s*)',jobInfo) # re.split is better than the Python's raw split function
jobTitle = tempInfo[1]
jobName = tempInfo[2]
job_request = job_detail.find('dd',{'class':'job_request'})
reqList = job_request.find_all('p')
jobAttract = reqList[1].text
publishTime = reqList[2].text
itemLists = job_request.find_all('span')
salary = itemLists[0].text
workplace = itemLists[1].text
experience = itemLists[2].text
education = itemLists[3].text
worktime = itemLists[4].text # company's infomation
jobCompany = btfsp.find('dl',{'class':'job_company'})
# companyName = jobCompany.h2
companyName = re.split(r'(?:\s*)',jobCompany.h2.text)[1]
companyInfo = jobCompany.find_all('li')
# workField = companyInfo[0].text.split(' ',1)
workField = re.split(r'(?:\s*)|(?:\n*)',companyInfo[0].text)[2]
# companyScale = companyInfo[1].text
companyScale = re.split(r'(?:\s*)|(?:\n*)',companyInfo[1].text)[2]
# homePage = companyInfo[2].text
homePage = re.split(r'(?:\s*)|(?:\n*)',companyInfo[2].text)[2]
# currStage = companyInfo[3].text
currStage = re.split(r'(?:\s*)|(?:\n*)',companyInfo[3].text)[1]
financeAgent = ''
if len(companyInfo) == 5:
# financeAgent = companyInfo[4].text
financeAgent = re.split(r'(?:\s*)|(?:\n*)',companyInfo[4].text)[1]
workAddress = ''
if jobCompany.find('div',{'class':'work_addr'}):
workAddress = jobCompany.find('div',{'class':'work_addr'})
workAddress = ''.join(workAddress.text.split()) # It's sooooo cool! # workAddress = jobCompany.find('div',{'class':'work_addr'})
# workAddress = ''.join(workAddress.text.split()) # It's sooooo cool! infoList = [companyName,jobTitle,jobName,salary,workplace,experience,education,worktime,jobAttract,publishTime,
workField,companyScale,homePage,workAddress,currStage,financeAgent] return infoList def SaveToExcel(pageContent):
pass if __name__ == '__main__':
# Init(userAgent)
Init('Python')
也是一边摸索一边来进行的,其中的一些代码写的不是很规范和统一。
结果显示如下:
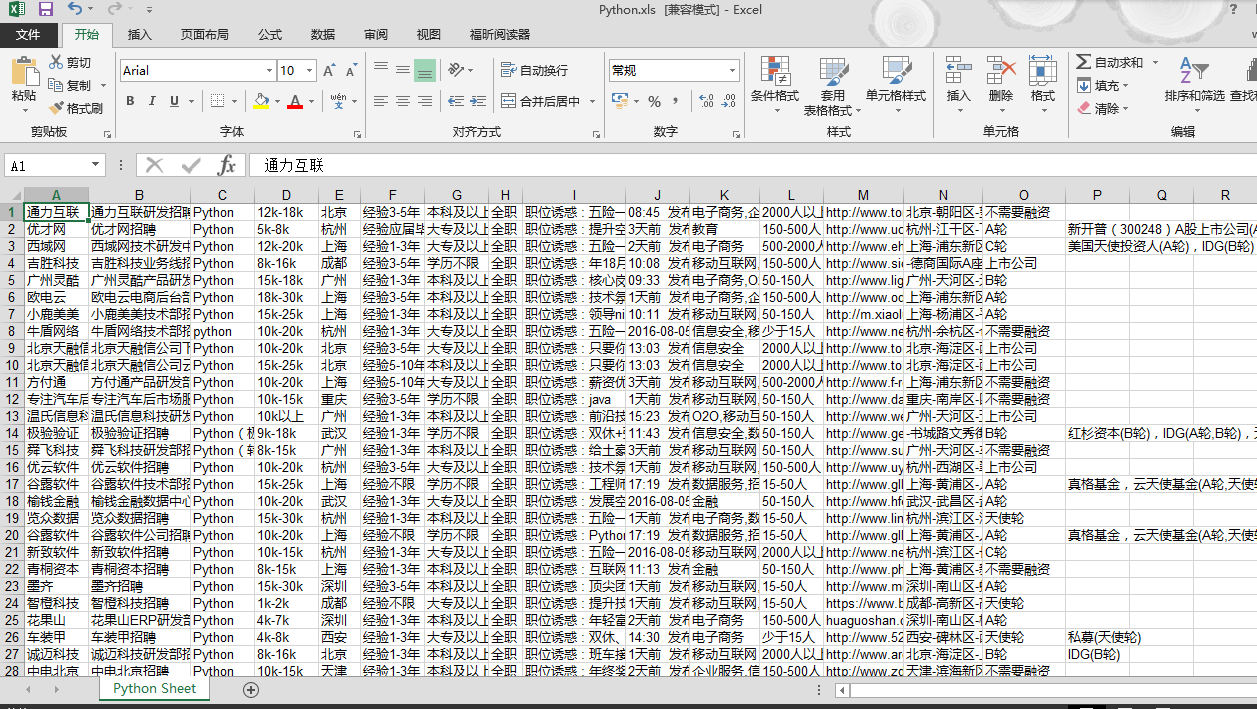
考虑打算下一步可以对相关的信息进行处理分析下,比如统计一下分布、薪资水平等之类的。
原文地址:http://www.cnblogs.com/leonwen/p/5769888.html
欢迎交流,请不要私自转载,谢谢
Python爬取拉勾网招聘信息并写入Excel的更多相关文章
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- 爬取拉勾网招聘信息并使用xlwt存入Excel
xlwt 1.3.0 xlwt 文档 xlrd 1.1.0 python操作excel之xlrd 1.Python模块介绍 - xlwt ,什么是xlwt? Python语言中,写入Excel文件的扩 ...
- python-scrapy爬虫框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏 ...
- python爬取拉勾网职位信息-python相关职位
import requestsimport mathimport pandas as pdimport timefrom lxml import etree url = 'https://www.la ...
- (转)python爬取拉勾网信息
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Androi ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
随机推荐
- 推荐一款好用到爆的开源 Java 诊断工具
Arthas是什么鬼?Arthas是一款阿里巴巴开源的 Java 线上诊断工具,功能非常强大,可以解决很多线上不方便解决的问题. Arthas诊断使用的是命令行交互模式,支持JDK6+,Linux.M ...
- 【微信小程序】mpvue中页面之间传值(全网唯一真正可行的方法,中指推了一下隐形眼镜)
摘要: mpvue中页面之间传值(注意:是页面之间,不是组件之间) 场景:A页面跳转B页面,在B页面选择商品,将商品名带回A页面并显示 使用api: getCurrentPages step1: A页 ...
- C#中char[]与string之间的转换;byte[]与string之间的转化
目录 1.char[]与string之间的转换 2.byte[]与string之间的转化 1.char[]与string之间的转换 //string 转换成 Char[] string str=&qu ...
- 简单的Python GUI界面框架
Python开发GUI界面, 可以使用pyQT或者wxpython. 不过不论pyQT还是wxpython都需要比较多的学习成本.Python工程往往是用于快速开发的,有些时候引入pyQT,wxpyt ...
- 自动编写Python程序的神器,Python 之父都发声力挺!
就在不久前,kite——那个能够自己编写python代码的AI,Python 之父 Guido van Rossum 使用之后,也发出了「really love」感叹,向大家墙裂推荐了这一高效工具 ...
- WPF 使用XML作为绑定源时Xaml注意事项
直接在xaml定义时xml时应该注意的! xml数据 <?xml version="1.0" encoding="utf-8"?> <Stri ...
- css 行内水平均等排布方式
<div class="justify"> <span>测试1</span> <span>测试2</span> < ...
- 教你如何用Python向手机发送通知
------------恢复内容开始------------ 你曾想尝试在服务器端或电脑上向手机发送通知吗? 你曾烦恼过企业邮箱的防骚扰机制吗? 现在,我们可以用一种简单轻松的方法来代替企业邮箱了! ...
- 网上售卖几百一月的微信机器,Python几十行代码就能搞定
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 故事胶片 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 程序员编程时常用的mac快捷方式
fn + F2/F3 = 调节音量 commend + shift +k = 显示或隐藏键盘 commend+shift +h = iPhone返回主页面 commend+ shift + hh = ...