HBase 系列(七)——HBase 过滤器详解
一、HBase过滤器简介
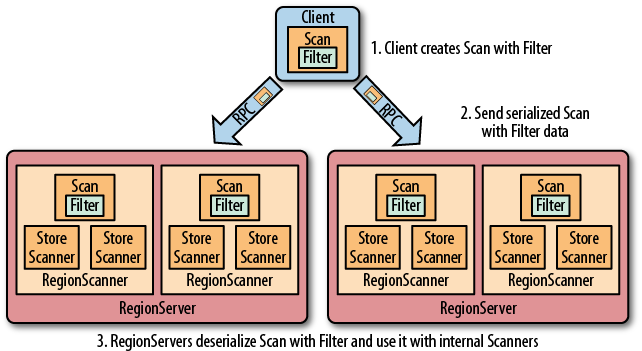
Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端,从而减轻网络传输和客户端处理的压力。
二、过滤器基础
2.1 Filter接口和FilterBase抽象类
Filter 接口中定义了过滤器的基本方法,FilterBase 抽象类实现了 Filter 接口。所有内置的过滤器则直接或者间接继承自 FilterBase 抽象类。用户只需要将定义好的过滤器通过 setFilter 方法传递给 Scan 或 put 的实例即可。
setFilter(Filter filter) // Scan 中定义的 setFilter
@Override
public Scan setFilter(Filter filter) {
super.setFilter(filter);
return this;
} // Get 中定义的 setFilter
@Override
public Get setFilter(Filter filter) {
super.setFilter(filter);
return this;
}FilterBase 的所有子类过滤器如下:
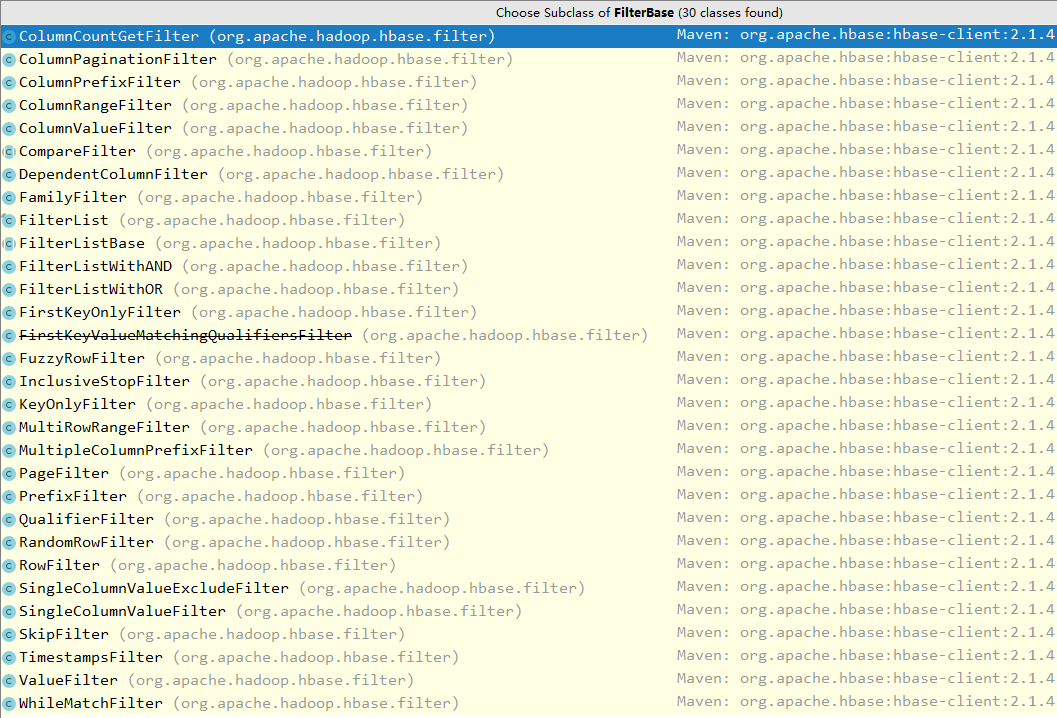
说明:上图基于当前时间点(2019.4)最新的 Hbase-2.1.4 ,下文所有说明均基于此版本。
2.2 过滤器分类
HBase 内置过滤器可以分为三类:分别是比较过滤器,专用过滤器和包装过滤器。分别在下面的三个小节中做详细的介绍。
三、比较过滤器
所有比较过滤器均继承自 CompareFilter。创建一个比较过滤器需要两个参数,分别是比较运算符和比较器实例。
public CompareFilter(final CompareOp compareOp,final ByteArrayComparable comparator) {
this.compareOp = compareOp;
this.comparator = comparator;
}3.1 比较运算符
- LESS (<)
- LESS_OR_EQUAL (<=)
- EQUAL (=)
- NOT_EQUAL (!=)
- GREATER_OR_EQUAL (>=)
- GREATER (>)
- NO_OP (排除所有符合条件的值)
比较运算符均定义在枚举类 CompareOperator 中
@InterfaceAudience.Public
public enum CompareOperator {
LESS,
LESS_OR_EQUAL,
EQUAL,
NOT_EQUAL,
GREATER_OR_EQUAL,
GREATER,
NO_OP,
}注意:在 1.x 版本的 HBase 中,比较运算符定义在
CompareFilter.CompareOp枚举类中,但在 2.0 之后这个类就被标识为 @deprecated ,并会在 3.0 移除。所以 2.0 之后版本的 HBase 需要使用CompareOperator这个枚举类。
3.2 比较器
所有比较器均继承自 ByteArrayComparable 抽象类,常用的有以下几种:

- BinaryComparator : 使用
Bytes.compareTo(byte [],byte [])按字典序比较指定的字节数组。 - BinaryPrefixComparator : 按字典序与指定的字节数组进行比较,但只比较到这个字节数组的长度。
- RegexStringComparator : 使用给定的正则表达式与指定的字节数组进行比较。仅支持
EQUAL和NOT_EQUAL操作。 - SubStringComparator : 测试给定的子字符串是否出现在指定的字节数组中,比较不区分大小写。仅支持
EQUAL和NOT_EQUAL操作。 - NullComparator :判断给定的值是否为空。
- BitComparator :按位进行比较。
BinaryPrefixComparator 和 BinaryComparator 的区别不是很好理解,这里举例说明一下:
在进行 EQUAL 的比较时,如果比较器传入的是 abcd 的字节数组,但是待比较数据是 abcdefgh:
- 如果使用的是
BinaryPrefixComparator比较器,则比较以abcd字节数组的长度为准,即efgh不会参与比较,这时候认为abcd与abcdefgh是满足EQUAL条件的; - 如果使用的是
BinaryComparator比较器,则认为其是不相等的。
3.3 比较过滤器种类
比较过滤器共有五个(Hbase 1.x 版本和 2.x 版本相同),见下图:
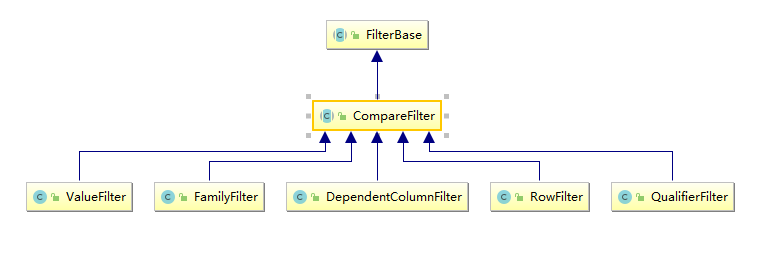
- RowFilter :基于行键来过滤数据;
- FamilyFilterr :基于列族来过滤数据;
- QualifierFilterr :基于列限定符(列名)来过滤数据;
- ValueFilterr :基于单元格 (cell) 的值来过滤数据;
- DependentColumnFilter :指定一个参考列来过滤其他列的过滤器,过滤的原则是基于参考列的时间戳来进行筛选 。
前四种过滤器的使用方法相同,均只要传递比较运算符和运算器实例即可构建,然后通过 setFilter 方法传递给 scan:
Filter filter = new RowFilter(CompareOperator.LESS_OR_EQUAL,
new BinaryComparator(Bytes.toBytes("xxx")));
scan.setFilter(filter); DependentColumnFilter 的使用稍微复杂一点,这里单独做下说明。
3.4 DependentColumnFilter
可以把 DependentColumnFilter 理解为一个 valueFilter 和一个时间戳过滤器的组合。DependentColumnFilter 有三个带参构造器,这里选择一个参数最全的进行说明:
DependentColumnFilter(final byte [] family, final byte[] qualifier,
final boolean dropDependentColumn, final CompareOperator op,
final ByteArrayComparable valueComparator)- family :列族
- qualifier :列限定符(列名)
- dropDependentColumn :决定参考列是否被包含在返回结果内,为 true 时表示参考列被返回,为 false 时表示被丢弃
- op :比较运算符
- valueComparator :比较器
这里举例进行说明:
DependentColumnFilter dependentColumnFilter = new DependentColumnFilter(
Bytes.toBytes("student"),
Bytes.toBytes("name"),
false,
CompareOperator.EQUAL,
new BinaryPrefixComparator(Bytes.toBytes("xiaolan")));首先会去查找
student:name中值以xiaolan开头的所有数据获得参考数据集,这一步等同于 valueFilter 过滤器;其次再用参考数据集中所有数据的时间戳去检索其他列,获得时间戳相同的其他列的数据作为
结果数据集,这一步等同于时间戳过滤器;最后如果
dropDependentColumn为 true,则返回参考数据集+结果数据集,若为 false,则抛弃参考数据集,只返回结果数据集。
四、专用过滤器
专用过滤器通常直接继承自 FilterBase,适用于范围更小的筛选规则。
4.1 单列列值过滤器 (SingleColumnValueFilter)
基于某列(参考列)的值决定某行数据是否被过滤。其实例有以下方法:
- setFilterIfMissing(boolean filterIfMissing) :默认值为 false,即如果该行数据不包含参考列,其依然被包含在最后的结果中;设置为 true 时,则不包含;
- setLatestVersionOnly(boolean latestVersionOnly) :默认为 true,即只检索参考列的最新版本数据;设置为 false,则检索所有版本数据。
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"student".getBytes(),
"name".getBytes(),
CompareOperator.EQUAL,
new SubstringComparator("xiaolan"));
singleColumnValueFilter.setFilterIfMissing(true);
scan.setFilter(singleColumnValueFilter);4.2 单列列值排除器 (SingleColumnValueExcludeFilter)
SingleColumnValueExcludeFilter 继承自上面的 SingleColumnValueFilter,过滤行为与其相反。
4.3 行键前缀过滤器 (PrefixFilter)
基于 RowKey 值决定某行数据是否被过滤。
PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("xxx"));
scan.setFilter(prefixFilter);4.4 列名前缀过滤器 (ColumnPrefixFilter)
基于列限定符(列名)决定某行数据是否被过滤。
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("xxx"));
scan.setFilter(columnPrefixFilter);4.5 分页过滤器 (PageFilter)
可以使用这个过滤器实现对结果按行进行分页,创建 PageFilter 实例的时候需要传入每页的行数。
public PageFilter(final long pageSize) {
Preconditions.checkArgument(pageSize >= 0, "must be positive %s", pageSize);
this.pageSize = pageSize;
}下面的代码体现了客户端实现分页查询的主要逻辑,这里对其进行一下解释说明:
客户端进行分页查询,需要传递 startRow(起始 RowKey),知道起始 startRow 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 startRow 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 startRow,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 lastRow)。
我们不能将 lastRow 作为新一次查询的 startRow 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 startRow 在新的查询也会被返回,这条数据就重复了。
同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 lastRow 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。
由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 lastRow 后面加上 0 ,作为 startRow 传入,因为按照字典序的规则,某个值加上 0 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。
所以最后传入 lastRow+0,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。
25 个字母以及数字字符,字典排序如下:
'0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z'
分页查询主要实现逻辑:
byte[] POSTFIX = new byte[] { 0x00 };
Filter filter = new PageFilter(15);
int totalRows = 0;
byte[] lastRow = null;
while (true) {
Scan scan = new Scan();
scan.setFilter(filter);
if (lastRow != null) {
// 如果不是首行 则 lastRow + 0
byte[] startRow = Bytes.add(lastRow, POSTFIX);
System.out.println("start row: " +
Bytes.toStringBinary(startRow));
scan.withStartRow(startRow);
}
ResultScanner scanner = table.getScanner(scan);
int localRows = 0;
Result result;
while ((result = scanner.next()) != null) {
System.out.println(localRows++ + ": " + result);
totalRows++;
lastRow = result.getRow();
}
scanner.close();
//最后一页,查询结束
if (localRows == 0) break;
}
System.out.println("total rows: " + totalRows);需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。
4.6 时间戳过滤器 (TimestampsFilter)
List<Long> list = new ArrayList<>();
list.add(1554975573000L);
TimestampsFilter timestampsFilter = new TimestampsFilter(list);
scan.setFilter(timestampsFilter);4.7 首次行键过滤器 (FirstKeyOnlyFilter)
FirstKeyOnlyFilter 只扫描每行的第一列,扫描完第一列后就结束对当前行的扫描,并跳转到下一行。相比于全表扫描,其性能更好,通常用于行数统计的场景,因为如果某一行存在,则行中必然至少有一列。
FirstKeyOnlyFilter firstKeyOnlyFilter = new FirstKeyOnlyFilter();
scan.set(firstKeyOnlyFilter);五、包装过滤器
包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。
5.1 SkipFilter过滤器
SkipFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。下面是一个使用示例:
// 定义 ValueFilter 过滤器
Filter filter1 = new ValueFilter(CompareOperator.NOT_EQUAL,
new BinaryComparator(Bytes.toBytes("xxx")));
// 使用 SkipFilter 进行包装
Filter filter2 = new SkipFilter(filter1);5.2 WhileMatchFilter过滤器
WhileMatchFilter 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,WhileMatchFilter 则结束本次扫描,返回已经扫描到的结果。下面是其使用示例:
Filter filter1 = new RowFilter(CompareOperator.NOT_EQUAL,
new BinaryComparator(Bytes.toBytes("rowKey4")));
Scan scan = new Scan();
scan.setFilter(filter1);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (Cell cell : result.listCells()) {
System.out.println(cell);
}
}
scanner1.close();
System.out.println("--------------------");
// 使用 WhileMatchFilter 进行包装
Filter filter2 = new WhileMatchFilter(filter1);
scan.setFilter(filter2);
ResultScanner scanner2 = table.getScanner(scan);
for (Result result : scanner1) {
for (Cell cell : result.listCells()) {
System.out.println(cell);
}
}
scanner2.close();rowKey0/student:name/1555035006994/Put/vlen=8/seqid=0
rowKey1/student:name/1555035007019/Put/vlen=8/seqid=0
rowKey2/student:name/1555035007025/Put/vlen=8/seqid=0
rowKey3/student:name/1555035007037/Put/vlen=8/seqid=0
rowKey5/student:name/1555035007051/Put/vlen=8/seqid=0
rowKey6/student:name/1555035007057/Put/vlen=8/seqid=0
rowKey7/student:name/1555035007062/Put/vlen=8/seqid=0
rowKey8/student:name/1555035007068/Put/vlen=8/seqid=0
rowKey9/student:name/1555035007073/Put/vlen=8/seqid=0
--------------------
rowKey0/student:name/1555035006994/Put/vlen=8/seqid=0
rowKey1/student:name/1555035007019/Put/vlen=8/seqid=0
rowKey2/student:name/1555035007025/Put/vlen=8/seqid=0
rowKey3/student:name/1555035007037/Put/vlen=8/seqid=0可以看到被包装后,只返回了 rowKey4 之前的数据。
六、FilterList
以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 FilterList。FilterList 支持通过构造器或者 addFilter 方法传入多个过滤器。
// 构造器传入
public FilterList(final Operator operator, final List<Filter> filters)
public FilterList(final List<Filter> filters)
public FilterList(final Filter... filters)
// 方法传入
public void addFilter(List<Filter> filters)
public void addFilter(Filter filter)多个过滤器组合的结果由 operator 参数定义 ,其可选参数定义在 Operator 枚举类中。只有 MUST_PASS_ALL 和 MUST_PASS_ONE 两个可选的值:
- MUST_PASS_ALL :相当于 AND,必须所有的过滤器都通过才认为通过;
- MUST_PASS_ONE :相当于 OR,只有要一个过滤器通过则认为通过。
@InterfaceAudience.Public
public enum Operator {
/** !AND */
MUST_PASS_ALL,
/** !OR */
MUST_PASS_ONE
}使用示例如下:
List<Filter> filters = new ArrayList<Filter>();
Filter filter1 = new RowFilter(CompareOperator.GREATER_OR_EQUAL,
new BinaryComparator(Bytes.toBytes("XXX")));
filters.add(filter1);
Filter filter2 = new RowFilter(CompareOperator.LESS_OR_EQUAL,
new BinaryComparator(Bytes.toBytes("YYY")));
filters.add(filter2);
Filter filter3 = new QualifierFilter(CompareOperator.EQUAL,
new RegexStringComparator("ZZZ"));
filters.add(filter3);
FilterList filterList = new FilterList(filters);
Scan scan = new Scan();
scan.setFilter(filterList);参考资料
HBase: The Definitive Guide _> Chapter 4. Client API: Advanced Features
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
HBase 系列(七)——HBase 过滤器详解的更多相关文章
- ASP.NET MVC深入浅出系列(持续更新) ORM系列之Entity FrameWork详解(持续更新) 第十六节:语法总结(3)(C#6.0和C#7.0新语法) 第三节:深度剖析各类数据结构(Array、List、Queue、Stack)及线程安全问题和yeild关键字 各种通讯连接方式 设计模式篇 第十二节: 总结Quartz.Net几种部署模式(IIS、Exe、服务部署【借
ASP.NET MVC深入浅出系列(持续更新) 一. ASP.NET体系 从事.Net开发以来,最先接触的Web开发框架是Asp.Net WebForm,该框架高度封装,为了隐藏Http的无状态模 ...
- MVC过滤器详解
MVC过滤器详解 APS.NET MVC中(以下简称"MVC")的每一个请求,都会分配给相应的控制器和对应的行为方法去处理,而在这些处理的前前后后如果想再加一些额外的逻辑处理. ...
- Asp.Net MVC学习总结之过滤器详解(转载)
来源:http://www.php.cn/csharp-article-359736.html 一.过滤器简介 1.1.理解什么是过滤器 1.过滤器(Filters)就是向请求处理管道中注入额外的 ...
- ISO七层模型详解
ISO七层模型详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我刚刚接触运维这个行业的时候,去面试时总是会做一些面试题,笔试题就是看一个运维工程师的专业技能的掌握情况,这个很 ...
- Hexo系列(三) 常用命令详解
Hexo 框架可以帮助我们快速创建一个属于自己的博客网站,熟悉 Hexo 框架提供的命令有利于我们管理博客 1.hexo init hexo init 命令用于初始化本地文件夹为网站的根目录 $ he ...
- UWP入门(七)--SplitView详解与页面跳转
原文:UWP入门(七)--SplitView详解与页面跳转 官方文档,逼着自己用英文看,UWP开发离不开官方文档 1. SplitView 拆分视图控件 拆分视图控件具有一个可展开/可折叠的窗格和一个 ...
- Wireshark过滤器详解
Wireshark过滤器详解 1.Wireshark主要提供两种主要的过滤器 捕获过滤器:当进行数据包捕获时,只有那些满足给定的包含/排除表达式的数据包会被捕获 显示过滤器:该过滤器根据指定的表达式用 ...
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- hbase实践之数据读取详解
hbase基本存储组织结构与数据读取组织结构对比 Segment是Hbase2.0的概念,MemStore由一个可写的Segment,以及一个或多个不可写的Segments构成.故hbase 1.*版 ...
- HBase Filter 过滤器之RowFilter详解
前言:本文详细介绍了HBase RowFilter过滤器Java&Shell API的使用,并贴出了相关示例代码以供参考.RowFilter 基于行键进行过滤,在工作中涉及到需要通过HBase ...
随机推荐
- 2019年7月16日 abp(net core)+easyui+efcore实现仓储管理系统——多语言(十)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统——ABP总体介绍(一) abp(net core)+ ...
- ES6 symbol 以及symbol的简单应用
前置 1.ES6 引入了一种新的原始数据类型Symbol,表示独一无二的值. 2.Symbol 值通过Symbol函数生成. 3.Symbol 函数可以接受一个字符串作为参数,表示对 Symbol 实 ...
- python函数对象-命名空间-作用域-02
函数对象 函数是第一对象: # 函数名指向的值可以被当做参数传递 函数对象的特性(*****灵活运用,后面讲装饰器会用到) 函数名可以像变量一样被传递 # 变量可以被传递 name = 'jason' ...
- 数组(ArrayPool数组池、Span<T>结构)
前言 如果需要使用相同的类型的多个对象,就可以使用集合和数组,这一节主要讲解数组,其中会重点涉及到Span<T>结构和ArrayPool数组池.我们也会先涉及到简单的数组.多维数组.锯齿数 ...
- zabbix 支持的主要监控方式
zabbix 支持的主要监控方式 一.zabbix支持的主要监控方式: zabbix主要Agent,Trapper,SNMP,JMX,IPMI这几种监控方式,本文章主要通过监控理论和实际操作测试等方式 ...
- 关于 64位系统 java连接access 报错java.sql.SQLException: [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序
报错的原因是url = "jdbc:odbc:Driver={Microsoft Access Driver (*.mdb)};DBQ=E:/公司/2000.mdb"; 这样是不行 ...
- 剖析std::function接口与实现
目录 前言 一.std::function的原理与接口 1.1 std::function是函数包装器 1.2 C++注重运行时效率 1.3 用函数指针实现多态 1.4 std::function的接 ...
- ListActivity
ListActivity的使用 ListActivity类中集成了一个ListView控件. 通过继承ListActivity类可方便地使用ListView控件 1 public class 类名ex ...
- Unity3D热更新之LuaFramework篇[09]--资源热更新与代码热更新的具体实现
前言 在上一篇文章 Unity3D热更新之LuaFramework篇[08]--热更新原理及热更服务器搭建 中,我介绍了热更新的基本原理,并且着手搭建一台服务器. 本篇就做一个实战练习,真正的来实现热 ...
- IDEA自定义配置
目录 1 常规设置 1 修改字体大小 2 创建文件时 增加注释信息 3 项目编码为UTF-8 4 properties 文件编码为UTF-8且Transparent native-to-ascii c ...