01 | 可见性、原子性和有序性问题:并发编程Bug的源头
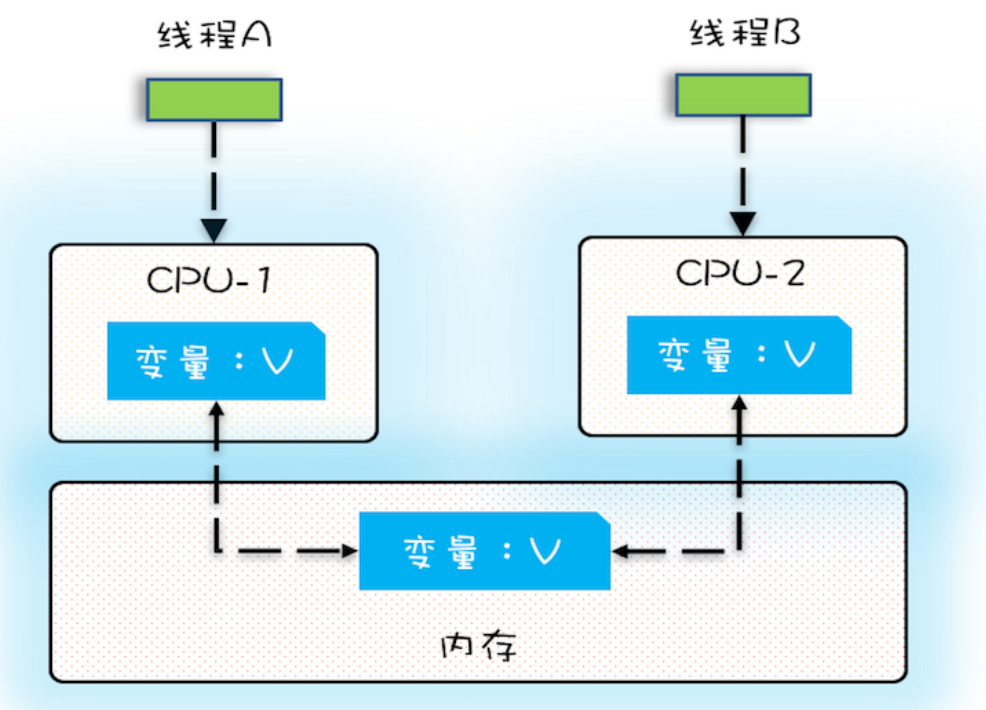
由于CPU、内存、I/O 设备的速度差异,为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系机构、操作系统、编译程序都做出以下处理:
public class Test {
private long count = 0;
private void add10K() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
public static long calc() {
final Test test = new Test();
// 创建两个线程,执行 add() 操作
Thread th1 = new Thread(()->{
test.add10K();
});
Thread th2 = new Thread(()->{
test.add10K();
});
// 启动两个线程
th1.start();
th2.start();
// 等待两个线程执行结束
th1.join();
th2.join();
return count;
}
}

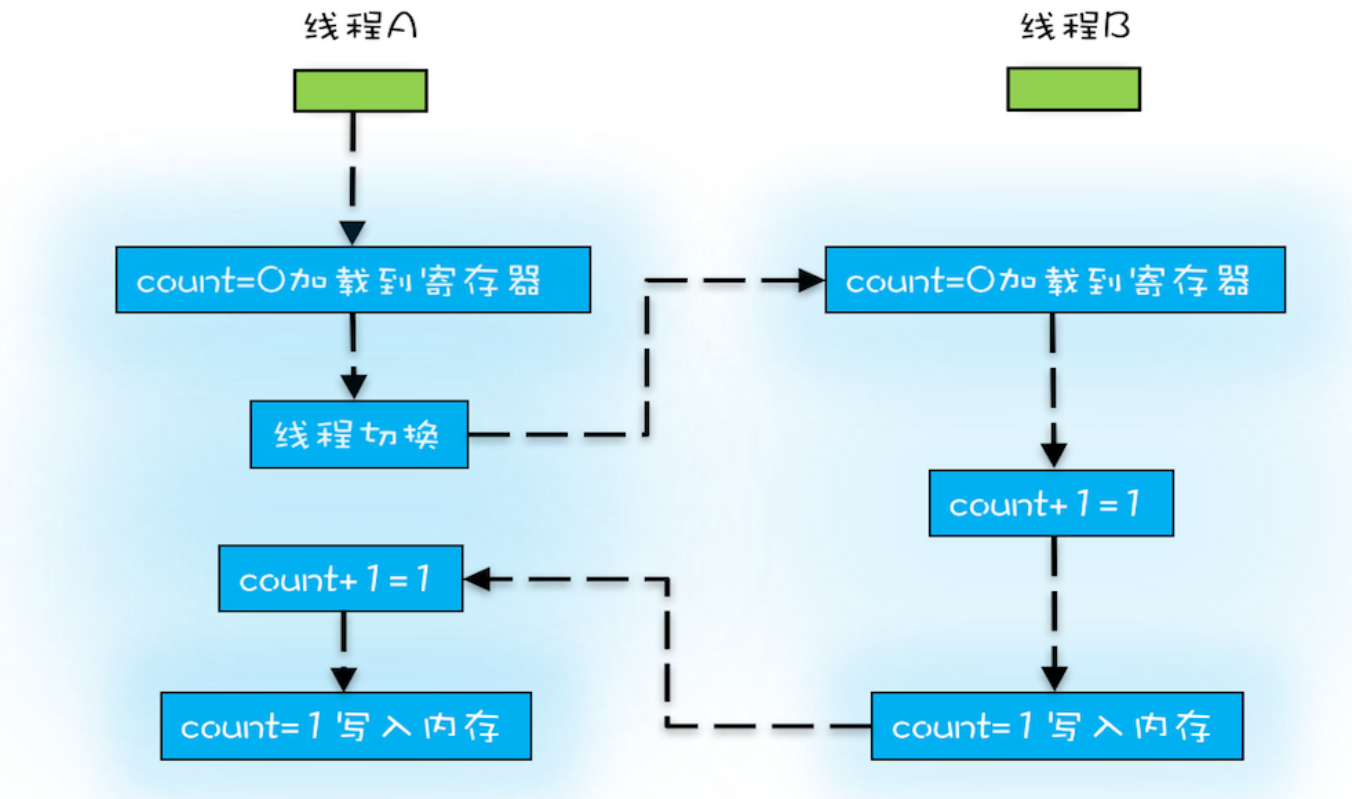
指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
指令 2:之后,在寄存器中执行 +1 操作;
指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}

01 | 可见性、原子性和有序性问题:并发编程Bug的源头的更多相关文章
- 【转】可见性、原子性和有序性问题:并发编程Bug的源头
如果你细心观察的话,你会发现,不管是哪一门编程语言,并发类的知识都是在高级篇里.换句话说,这块知识点其实对于程序员来说,是比较进阶的知识.我自己这么多年学习过来,也确实觉得并发是比较难的,因为它会涉及 ...
- 并发编程Bug起源:可见性、有序性和原子性问题
以前古老的DOS操作系统,是单进行的系统.系统每次只能做一件事情,完成了一个任务才能继续下一个任务.每次只能做一件事情,比如在听歌的时候不能打开网页.所有的任务操作都按照串行的方式依次执行. 这类服务 ...
- 【Java并发基础】并发编程bug源头:可见性、原子性和有序性
前言 CPU .内存.I/O设备之间的速度差距十分大,为了提高CPU的利用率并且平衡它们的速度差异.计算机体系结构.操作系统和编译程序都做出了改进: CPU增加了缓存,用于平衡和内存之间的速度差异. ...
- java并发编程实战《一》可见性、原子性和有序性
可见性.原子性和有序性问题:并发编程Bug的源头 核心矛盾:CPU.IO.内存三者之间的速度差异. 为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构.操作系统.编译程序都做出了贡献 ...
- Java并发编程实战 01并发编程的Bug源头
摘要 编写正确的并发程序对我来说是一件极其困难的事情,由于知识不足,只知道synchronized这个修饰符进行同步. 本文为学习极客时间:Java并发编程实战 01的总结,文章取图也是来自于该文章 ...
- 【漫画】JAVA并发编程三大Bug源头(可见性、原子性、有序性)
原创声明:本文转载自公众号[胖滚猪学编程] 某日,胖滚猪写的代码导致了一个生产bug,奋战到凌晨三点依旧没有解决问题.胖滚熊一看,只用了一个volatile就解决了.并告知胖滚猪,这是并发编程导致的 ...
- 【漫画】JAVA并发编程 如何解决原子性问题
原创声明:本文转载自公众号[胖滚猪学编程],转载务必注明出处! 在并发编程BUG源头文章中,我们初识了并发编程的三个bug源头:可见性.原子性.有序性.在如何解决可见性和原子性文章中我们大致了解了可见 ...
- 基于JVM原理、JMM模型和CPU缓存模型深入理解Java并发编程
许多以Java多线程开发为主题的技术书籍,都会把对Java虚拟机和Java内存模型的讲解,作为讲授Java并发编程开发的主要内容,有的还深入到计算机系统的内存.CPU.缓存等予以说明.实际上,在实际的 ...
- java并发编程 --并发问题的根源及主要解决方法
目录 并发问题的根源在哪 缓存导致的可见性 线程切换带来的原子性 编译器优化带来的有序性 主要解决办法 避免共享 Immutability(不变性) 管程及其他工具 并发问题的根源在哪 首先,我们要知 ...
随机推荐
- # & 等特殊字符会导致传参失败
# & 等特殊字符会导致 post 传参失败 处理方法使用 encodeURIComponent 将字符串转化一下 实例 // toUpperCase() 转化为大写字母 var cateco ...
- Ubuntu 18 安装搜狗输入法
Ubuntu 18 安装搜狗输入法: 1. 搜狗输入法官网下载对应的Linux输入法 2. 双击 刚刚下载好的 deb 文件 3. 点击 install(安装) 4. 在 settings(系统设置) ...
- nyoj 198-数数 (python, string[::-1])
198-数数 内存限制:64MB 时间限制:3000ms 特判: No 通过数:16 提交数:25 难度:2 题目描述: 我们平时数数都是喜欢从左向右数的,但是我们的小白同学最近听说德国人数数和我们有 ...
- javescript 的 对象
一,定义:对象是JavaScript的一个基本数据类型,是一种复合值,它将很多值(原始值或者其他对象)聚合在一起,可通过名字(name/作为属性名)访问这些值.即属性的无序集合. 关键是name属性名 ...
- PHP中的服务容器与依赖注入的思想
依赖注入 当A类需要依赖于B类,也就是说需要在A类中实例化B类的对象来使用时候,如果B类中的功能发生改变,也会导致A类中使用B类的地方也要跟着修改,导致A类与B类高耦合.这个时候解决方式是,A类应该去 ...
- 教你用Java web实现多条件过滤功能
生活中,当你闲暇之余浏览资讯的时候,当你搜索资料但繁杂信息夹杂时候,你就会想,如何更为准确的定位需求信息.今天就为你带来: 分页查询 需求分析:在列表页面中,显示指定条数的数据,通过翻页按钮完成首页/ ...
- jQuery学习笔记3
* 动画效果 * 在一定的时间内, 不断改变元素样式 * slideDown()/slideUp()/slideToggle() * fadeOut()/fadeIn()/fadeToggle() * ...
- postgresql修改最大连接数配置
1.查看配置文件位置等信息,用来确定配置对应的配置文件. select setting,boot_val,reset_val,sourcefile,*from pg_settings where n ...
- Kotlin实战案例:带你实现RecyclerView分页查询功能(仿照主流电商APP,可切换列表和网格效果)
随着Kotlin的推广,一些国内公司的安卓项目开发,已经从Java完全切成Kotlin了.虽然Kotlin在各类编程语言中的排名比较靠后(据TIOBE发布了 19 年 8 月份的编程语言排行榜,Kot ...
- 如何在SQL Server 2008下轻松调试T-SQL语句和存储过程
一.回顾早期的SQL SERVER版本:早在SQL Server 2000时代,查询分析器的功能还很简陋,远不如VS那么强大.到SQL Server 2005时代,代码高亮.SQL优化等功能逐渐加强, ...