大数据分析的下一代架构--IOTA架构设计实践[下]
IOTA架构提出背景
大数据3.0时代以前,Lambda数据架构成为大数据公司必备的架构,它解决了大数据离线处理和实时数据处理的需求。典型的Lambda架构如下: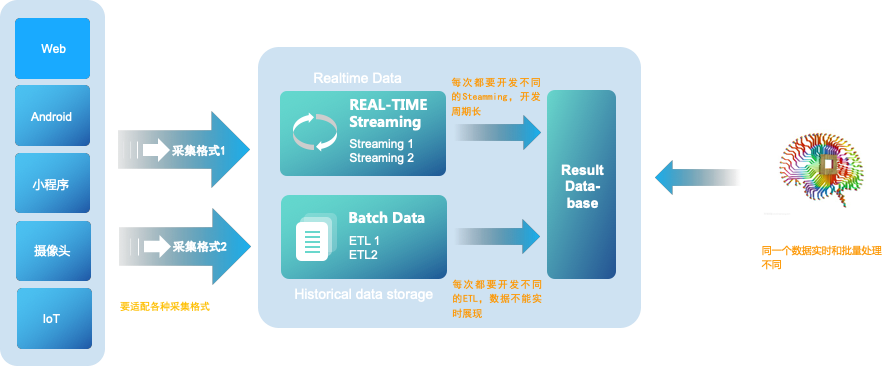
Lambda架构的核心思想是:
数据从底层的数据源开始,经过各样的格式进入大数据平台,然后分成两条线进行计算。一条线是进入流式计算平台,去计算实时的一些指标;另一条线进入批量数据处理离线计算平台,去计算T+1的相关业务指标,这些指标需要隔日才能看见。
Lambda优点是稳定、实时和离线计算高峰错开,但是它有一些致命缺点,其缺点主要有:
● 实时与批量计算结果不一致引起的数据口径问题:因为批量和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
● 批量计算在计算窗口内无法完成:在IOT时代,数据量级越来越大,经常发现夜间只有4、5个小时的时间窗口,已经无法完成白天20多个小时累计的数据,保证早上上班前准时出数据已成为每个大数据团队头疼的问题。
● 数据源变化都要重新开发,开发周期长:每次数据源的格式变化,业务的逻辑变化都需要针对ETL和Streaming做开发修改,整体开发周期很长,业务反应不够迅速。
● 服务器存储大:数据仓库的典型设计,会产生大量的中间结果表,造成数据急速膨胀,加大服务器存储压力。
IOTA架构
IOT大潮下,智能手机、PC、智能硬件设备的计算能力越来越强,业务要求数据有实时的响应能力,Lambda架构已经不能适应当今大数据分析时代的需求
IOTA架构的核心概念:
● Common Data Model:贯穿整体业务始终的数据模型,这个模型是整个业务的核心,要保持SDK、Buffer、历史数据、查询引擎保持一致。对于用户数据分析来讲可以定义为“主-谓-宾”或者“对象-事件”这样的抽象模型来满足各种各样的查询。
● Edge SDKs & Edge Servers:这是数据的采集端,不仅仅是过去的简单的SDK,在复杂的计算情况下,会赋予SDK更复杂的计算,在设备端就转化为形成统一的数据模型来进行传送。例如对于智能Wi-Fi采集的数据,从AC端就变为“X用户的MAC 地址-出现- A楼层(2018/4/11 18:00)”这种主-谓-宾结构。对于APP和H5页面来讲,没有计算工作量,只要求埋点格式即可。
● Real-Time Data:即实时数据缓存区。这部分是为了达到实时计算的目的,海量数据接收不可能海量实时入历史数据库,会出现建立索引延迟、历史数据碎片文件等问题。因此,有一个实时数据缓存区来存储最近几分钟或者几秒钟的数据。这块可以使用Kudu或HBase等组件来实现。此处的数据模型和SDK端数据模型是保持一致的,都是Common Data Model。
● Historical Data:历史数据沉浸区,这部分是保存了大量的历史数据,为了实现Ad-hoc查询,将自动建立相关索引提高整体历史数据查询效率,从而实现秒级复杂查询百亿条数据。例如可以使用HDFS存储历史数据,此处的数据模型依然SDK端数据模型是保持一致的Common Data Model。
● Dumper:Dumper的主要工作就是把最近几秒或者几分钟的Realtime Data区的数据,根据汇聚规则、建立索引,存储到历史存储结构Historical Data区中。
● Query Engine:查询引擎,提供统一的对外查询接口和协议(例如SQL),把Realtime Data和Historical Data合并到一起查询,从而实现对于数据实时的Ad-hoc查询。例如常见的计算引擎可以使用Presto、Impala、Clickhouse等。
● Realtime model feedback:通过Edge computing技术,在边缘端有更多的交互可以做,可以通过在Realtime Data去设定规则来对Edge SDK端进行控制,例如,数据上传的频次降低、语音控制的迅速反馈,某些条件和规则的触发等等。
整体思路是设定标准数据模型,通过边缘计算技术把所有的计算过程分散在数据产生、计算和查询过程当中,以统一的数据模型贯穿始终,从而提高整体的预算效率,同时满足即时计算的需要,可以使用各种Ad-hoc Query来查询底层数据。
IOTA整体架构引擎实例
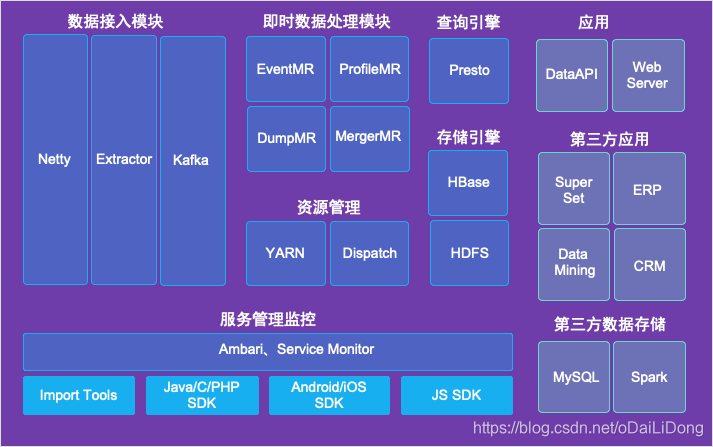
IOTA的特点:
- 去“ETL”化
- 高效:时时入库即时分析
- 稳定:经过易观5.8Pb,5.2亿月活数据锤炼
- 便捷:支持SQL级别的二次开发和UDAF定义
- 扩充性强:组件基于Apache开源协议,可支持众多开源存储对接
IOTA架构 — 数据模型 Common Data Model
Common Data Model :
贯穿整体业务始终的核心数据模型,保持SDK、Buffer、历史数据、查询引擎端数据模型一致。
对于用户行为分析业务来讲:
可以定义为“主-谓-宾”或者“用户-事件”抽象模型来满足各种各样的查询。
例如 :
智能手表:X用户 – 进行了 – 游泳运动
视频APP: X用户 – 播放 – 影片
电商网站:X用户 – 购买 – 手机( 2018/12/11 18:00:00 , IP , GPS)”
IOTA架构 — 数据模型 Common Data Model
用户-事件模型之事件 (Event)
事件(Event)
主要是描述用户做了什么事情,记录用户触发的行为,例如注册、登录、支付事件等等
事件属性
更精准的描述用户行为,例如事件发生的位置、方式和内容
每一条event数据对应用户的一次行为信息, 例如浏览、登录、搜索事件等等。
具体请参考易观方舟文档关于数据模型的说明:https://ark.analysys.cn/docs/integration-data-model.html
用户-事件模型之用户 (Profile)
用户这里没有太多要说的,要提醒注意唯一标识这块
唯一标识
方舟的事件模型中,数据上报时会有用户这个实体,使用 who 来进行标识,在登录前匿名阶段,who 中会记录一个 匿名 ID ,登录后会记录一个注册 ID。
1.1 匿名 ID
匿名 ID 用来在用户主体未登录应用之前标识,当用户打开集成有方舟 SDK 的应用时,SDK 会给其分配一个 UUID 来做为匿名 ID 。
当然,方舟也提供了给用户主体设置匿名 ID 的方式,比如可以使用设备 ID ( iOS 的 IDFA/IDFV,Web 的 Cookie 等)。
1.2 注册 ID
通常是业务数据库里的主键或其它唯一标识,注册 ID 是更加精确的用户 ID,但很多应用不会用注册 ID,或者用户使用一些功能时是在未登录的状态下进行的,此时,就不会有注册 ID。
另外,在方舟系统中,我们以为用户主体来进行分析,这个用户主体可能是一个人,一个帐号,也可能是一个家电,一辆汽车。具体以什么做为用户主体,要根据用户实际的业务场景来决定。
1.3 distinct_id
即使有了who( 注册 ID / 匿名 ID),实际使用中也会存在注册用户匿名访问等情况,所以需要一个唯一标识将用户行为贯穿起来,distinct_id 就是在who 的基础上根据一些规则生成的唯一 ID。
IOTA架构 — 数据流转过程
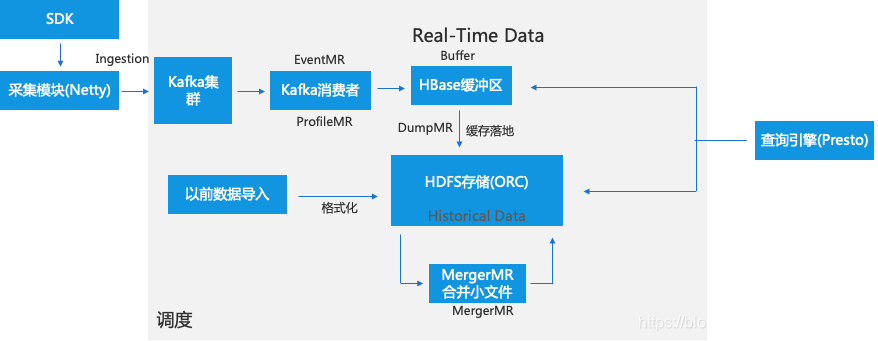
IOTA架构 — 数据采集(Ingestion)
数据采集

数据采集要注意:
传输加密
策略控制
服务器可以随时更改发发送策略,比如发送频率调整,重试频率
发送策略优先级: 服务器策略>debug>用户设置>启动、间隔策略
服务器约束示例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
服务器端返回示意:
IOTA架构 — 数据缓冲区(Real-Time Data)
Real-Time Data区是数据缓冲区,当从Kafka消费完数据首先落入Buffer区,这样设计主要是因为目前主流存储格式都不支持实时追加(Parquet、ORC)。Buffer区一般采用HBase、Kudu等高性能存储,考虑到成熟度、可控、社区等因素,我们采用HBase。
HBase的特点:
– 主键查询速度快
– Scan性能慢如何解决Scan性能:-- In-memory
– Snappy压缩
– 动态列族
– 只存一定量的数据
– Rowkey设计hash
– hfile数据转换成OrcFile
IOTA架构 — 历史存储区(Historical data storage)
当HBase里的数据量达到百万规模时,调度会启动DumpMR(Spark、MR任务)会将HBase数据flush到HDFS中去,因为还要支持数据的实时查询,我们采用R/W表切换方案,即一直写入一张表直到阈值,就写入新表,老表开始转为ORC格式。
HDFS高效存储:
按天分区
基于用户ID,事件时间排序
冷热分层
Orc存储
BloomFilter
稀疏索引
Snappy压缩
- 1
- 2
- 3
- 4
- 5
- 6
- 7
小文件问题:
不按事件分区
MergerMR定时合并小文件
- 1
- 2
稀疏索引:
数据有序:
IOTA架构 — 即时查询引擎(Query Engine)
因为需支持从历史到最近一条数据的即时查询,查询引擎需要同时查HBase缓冲区里和历史存储区的数据,采用View视图的方式进行查询。
Query Engine基于Presto进行二次开发
- HBase-Connector定制开发、优化
- 通过视图View建立热数据与历史数据的联合计算
- Session,漏斗,留存,智能路径等模型的算法实现

关于olap引擎测评请参考:
http://geek.analysys.cn/topic/21 开源OLAP引擎测评报告(SparkSql、Presto、Impala、HAWQ、ClickHouse、GreenPlum)
IOTA架构 — 调度(EasyScheduler)
整个数据处理流程都离不开一个组件 – 调度。
考虑调度易用性、可维护性及方便二次开发等综合原因,我们开发了自己的大数据分布式调度系统EasyScheduler。
EasyScheduler(易调度) 主要解决数据研发ETL 错综复杂的依赖关系,而不能直观监控任务健康状态等问题。EasyScheduler以DAG流式的方式将Task组装起来,
可实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及Kill任务等操作。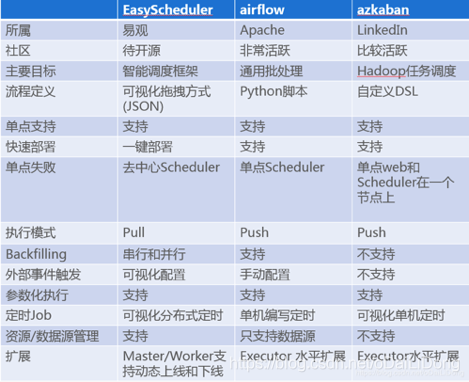
更多关于调度的信息:
https://blog.csdn.net/oDaiLiDong/article/details/84994247
IOTA架构 — 优化策略
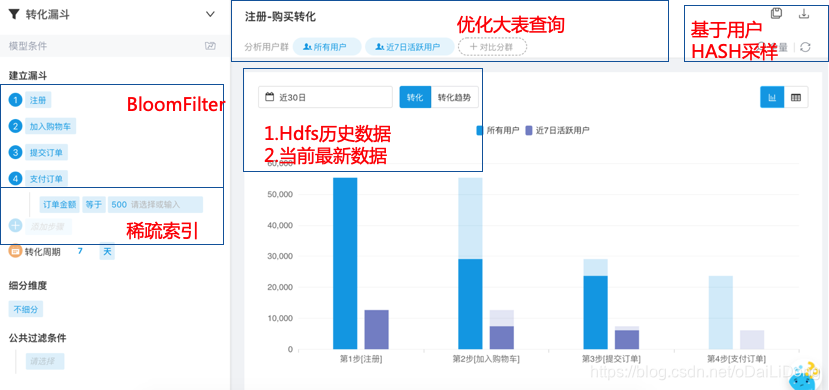
IOTA架构 — 优化经验
1、添加布隆过滤器,TPC-DS有50%-80%性能提升
2、全局 + 局部字典,尽量整型,避免过长字符串,数倍性能提升
如:事件名称使用id,查询速度提升近1倍
3、数据缓存Alluxio使用,2~5倍性能提升
4、SQL优化,耗时sql优化非常重要
5、Unsafe调用。Presto里开源Slice的使用
IOTA架构 — 前进方向
天下武功唯快不破!
1、数据本地化,尽量避免shuffle调用
2、更合适的索引构建,如bitmap索引
3、堆外内存的使用,避免GC问题
更多关于IOTA架构的交流请加我微信,加我时请注明公司+职位+IOTA,谢谢:
大数据分析的下一代架构--IOTA架构设计实践[下]的更多相关文章
- ETL化的IOTA架构
经过这么多年的发展,已经从大数据1.0的BI/Datawarehouse时代,经过大数据2.0的Web/APP过渡,进入到了IOT的大数据3.0时代,而随之而来的是数据架构的变化. ▌Lambda架构 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 电竞大数据平台 FunData 的系统架构演进
电竞大数据时代,数据对比赛的观赏性和专业性都起到了至关重要的作用.同样的,这也对电竞数据的丰富性与实时性提出了越来越高的要求. 电竞数据的丰富性从受众角度来看,可分为赛事.战队和玩家数据:从游戏角 ...
- NVIDIA Turing Architecture架构设计(下)
NVIDIA Turing Architecture架构设计(下) GDDR6 内存子系统 随着显示分辨率不断提高,着色器功能和渲染技术变得更加复杂,内存带宽和大小在 GPU 性能中扮演着更大的角色. ...
- 【DDD】领域驱动设计实践 —— 架构风格及架构实例
概述 DDD为复杂软件的设计提供了指导思想,其将易发生变化的业务核心域放置在限定上下文中,在确保核心域一致性和内聚性的基础上,DDD可以被多种语言和多种技术框架实现,具体的框架实现需要根据实际的业务场 ...
- QQ会员活动运营平台架构设计实践——高效自动化运营
QQ会员活动运营平台(AMS),是QQ会员增值运营业务的重要载体之一,承担海量活动运营的Web系统.在过去四年的时间里,AMS日请求量从200-500万的阶段,一直增长到日请求3-5亿,最高CGI日请 ...
- Java生鲜电商平台-App系统架构开发与设计
Java生鲜电商平台-App系统架构开发与设计 说明:阅读此文,你可以学习到以下的技术分享 1.Java生鲜电商平台-App架构设计经验谈:接口的设计2.Java生鲜电商平台-App架构设计经验谈:技 ...
- zz《分布式服务架构 原理、设计与实战》综合
这书以分布式微服务系统为主线,讲解了微服务架构设计.分布式一致性.性能优化等内容,并介绍了与微服务系统紧密联系的日志系统.全局调用链.容器化等. 还是一样,每一章摘抄一些自己觉得有用的内容,归纳整理, ...
- 理解RESTful架构——Restful API设计指南
理解RESTful架构 Restful API设计指南 理解RESTful架构 越来越多的人开始意识到,网站即软件,而且是一种新型的软件. 这种"互联网软件"采用客户端/服务器模式 ...
随机推荐
- 搭建SSM框架的配置文件
pom.xml所需要的基本依赖和插件: <dependency> <groupId>org.mybatis</groupId> ...
- vue-cli 引用elementUI打包后文件过大
解决方案:使用externals引用第三方资源,防止element资源被打包到自己项目中,(总共修改3个页面index.html.webpack.base.conf.js.main.js) 1.修改i ...
- WordPress疑难问题以及解决方案汇总
版权声明:本文为xing_star原创文章,转载请注明出处! 本文同步自http://javaexception.com/archives/101 WordPress疑难问题以及解决方案汇总: 最近这 ...
- iOS sqlite ORM框架-LKDBHelper
LKDBHelper 一个sqlite ORM(全自动操作数据库)框架. 线程安全.不再担心递归锁死的问题 安装要求 iOS 4.3+ 仅支持 ARC FMDB 添加到你的项目 如果你使用 Cocoa ...
- 并发编程 ~~~ 多进程~~~进程创建的两种方式, 进程pid, 验证进程之间的空间隔离, 进程对象join方法, 进程对象其他属性
一 进程创建的两种方式 from multiprocessing import Process import time def task(name): print(f'{name} is runnin ...
- 一个版本烧录过程中记录:fdisk、mkfs.ext4、make_ext4fs、img2simg、simg2img
关键词:dd.fdisk.mkfs.ext4.make_ext4fs.img2simg.simg2img等等. 一个典型的嵌入式系统是由uboot+kernel+rootfs组成的,其中uboot和k ...
- 实操《kubernetes网络权威指南》之veth pair
https://book.douban.com/subject/34855927/ 作者: 杜军 出版社: 电子工业出版社出品方: 博文视点出版年: 2019-10页数: 348定价: 89ISBN: ...
- Deepin nginx lumen配置
正常安装 sudo apt install nginxsudo apt install php-fpm 启动后将 /etc/nginx/sites-enabled/default 配置文件 copy一 ...
- Day6 - Python基础6 模块shelve、xml、re、subprocess、pymysql
本节目录: 1.shelve模块 2.xml模块 3.re模块 4.subprocess模块 5.logging模块 6.pymysql 1.shelve 模块 shelve模块是一个简单的k,v将内 ...
- Leetcode 1239. 串联字符串的最大长度
地址 https://leetcode-cn.com/problems/maximum-length-of-a-concatenated-string-with-unique-characters/s ...