Map Reduce 论文阅读
Map Reduce 是 Google 在 2004 年发表的一篇论文,原文链接 在这 后来 Hadoop 直接内置了这一框架。
读完之后记录一下心得。
主要背景:MapReduce 的出现很具有工程特性,在海量数据出现后,面临的问题是我们如何利用大量的,性能不是很强的服务器对数据进行处理。
主要思想:主要思想也很简单,分治的思想解决问题。把大量的数据划分成较小的,单机可处理的数据,对不同的主机进行任务划分,最终合并结果。主机之间的连接通过。
主要模型:
整个 Map Reduce 阶段如下图所示,先做数据的划分,然后由一个 master 节点划分出不同的 worker,然后分配给不同的 worker 进行 Map 或者 Reduce 操作。Map 后的结果进行 Reduce 操作,得到最终的结果。
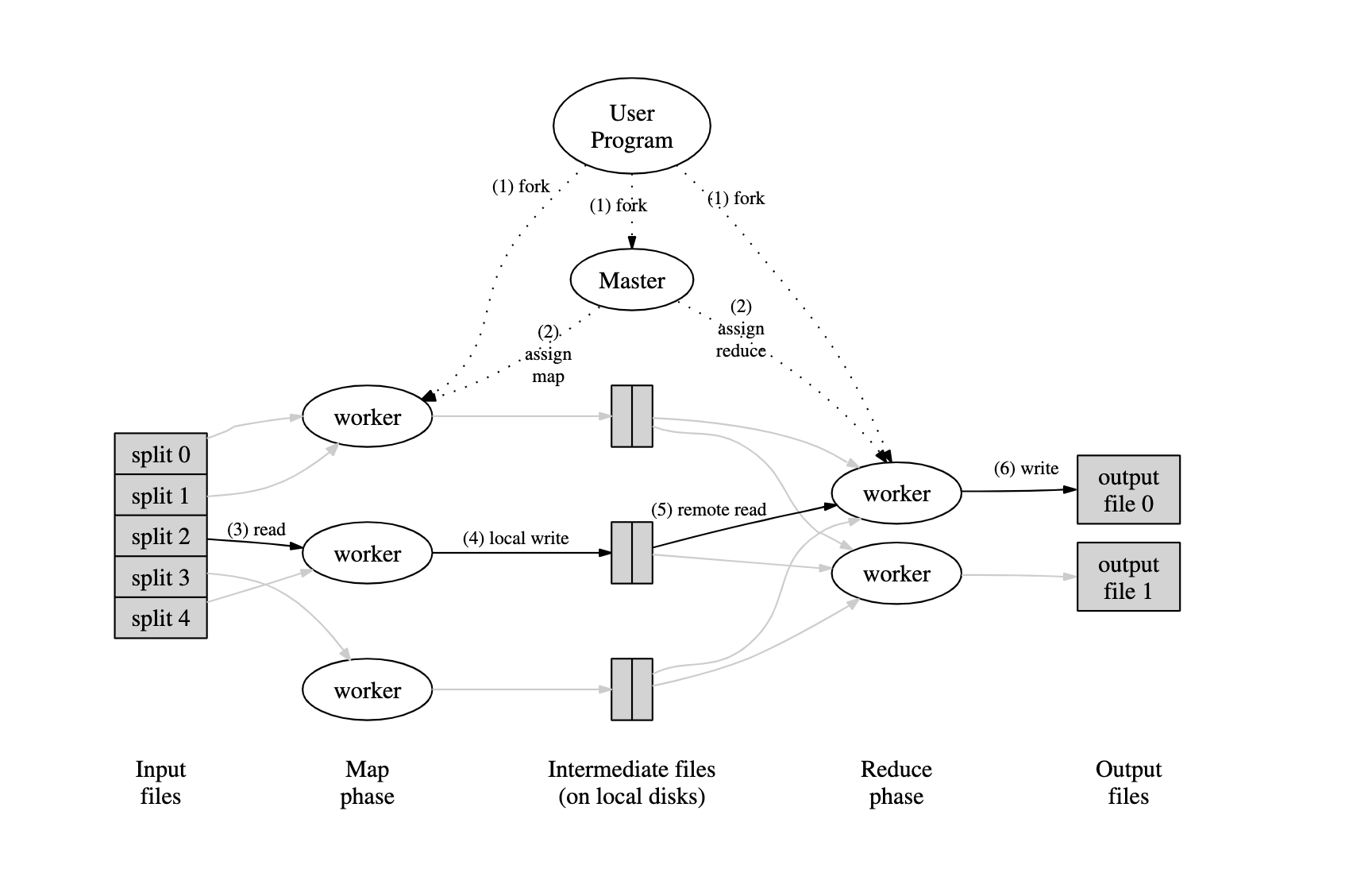
可以看到,主要完成的计算有两个: Map() 和 Reduce() ,这两个函数从语义上已经很好理解,Map 函数的 input 是一组 key-value 对,output 也是一组 key-value 对。主要功能是把原先的大数据量下的 k-v 映射到一个新的空间下的 k-v 。
Reduce 函数的 input 基于 Map 函数产出的 k-v,output 是处理后的结果,但基本都是在原先的数据上做汇总处理。也就是 reduce 的语义。
Google 给出的Map-Reduce 函数模型如下:
map (k1, v1) -> list (k2, v2)
reduce(k2, list(v2)) -> list(v2)
给个栗子,现在有十副牌已经混乱,现在需要在其中找出一副牌,用 MapReduce 的思想来处理这个问题,就可以分成两个阶段,Map 阶段,把 10 副牌进行划分,对每一个划分而言做 Map 操作,这里的 Map 操作可以为把手中的牌分为4类 ♥️,♣️,♦️,♠️这四类。然后对这四类的结果做 Reduce 操作,即从每个花色找到13张不同的牌,这样,就可以找到一副完整的扑克牌。
map(list pokers) :
for poker in pokers:
dic[getClass(poker)].append(poker)
return dic;
reduce(list hearts, list diamonds, list clubs, list spades):
finish(hearts)
finish(diamonds)
finish(clubs)
finish(spades)
整个过程在理论上而言很简单,也很容易理解。难点主要集中在下面几个部分
- 如何做数据的划分
- 如何对大量的主机做调度
- 如果某一个主机出现了失败如何处理
- 主机间的通信如何管理
失败的处理:
Master 通过心跳机制来维护对 worker 的管理,由于单机的 worker 会先把 Map 的结果存在本地,所以,如果一个 worker A失去维护,那么这个 worker 的任务将会被重新进行编排分给 worker B。并且,所有进行 Reduce 操作的 worker 都会收到通知,因为 Reduce 需要的数据可能会从 A 读,所以,需要通知所有进行 Reduce 操作的 worker。
如果 Master 失败,由于 Master 只有一个,所以 Master 会定期进行状态存储,如果 Master 失败,则人工恢复到最新状态。
一些优化:
Backup Task:因为总的时间会受耗时最长的任务影响,而对于某个耗时最长任务而言,可能不是其任务本身带来的负面影响导致其处理时间延长,而是执行这个任务的机器自身的影响。所以,对于一个快要结束的任务,Master 会为其分配一个 backup 的操作,这个 backup 状态和之前的一样,只是在不同的机器上执行。如果这两个任务中任何一个完成,那么就视为这个任务已经完成。而这个 backup 操作提升时间也是非常显著的,大概能有44%的提升。
Ordering Guarantee:在一个 map 操作完成后,进行 sort 操作,保证其的顺序,这样对于 reduce 而言,在进行查找的时候,会变得非常高效。
Combiner Function:在 map 操作完成后,在本地进行 combine 操作,可以减少数据的传输,也可以减少 Reduce 的数据量。
Map Reduce 论文阅读的更多相关文章
- python基础——map/reduce
python基础——map/reduce Python内建了map()和reduce()函数. 如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Pro ...
- 用通俗易懂的大白话讲解Map/Reduce原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- hadoop入门级总结二:Map/Reduce
在上一篇博客:hadoop入门级总结一:HDFS中,简单的介绍了hadoop分布式文件系统HDFS的整体框架及文件写入读出机制.接下来,简要的总结一下hadoop的另外一大关键技术之一分布式计算框架: ...
- Map Reduce和流处理
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由@从流域到海域翻译,发表于腾讯云+社区 map()和reduce()是在集群式设备上用来做大规模数据处理的方法,用户定义一个特定的映射 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- Python进阶:函数式编程(高阶函数,map,reduce,filter,sorted,返回函数,匿名函数,偏函数)...啊啊啊
函数式编程 函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计.函数就是面向过程的程序设计 ...
- [转] map/reduce
如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Processing on Large Clusters”,你就能大概明白map/reduce的概念. ...
- (转)Python进阶:函数式编程(高阶函数,map,reduce,filter,sorted,返回函数,匿名函数,偏函数)
原文:https://www.cnblogs.com/chenwolong/p/reduce.html 函数式编程 函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数 ...
- 函数式编程(1)-高阶变成(1)-map/reduce
map/reduce Python内建了map()和reduce()函数. 如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Processing on ...
随机推荐
- 一文读懂Java GC原理和调优
概述 本文介绍GC基础原理和理论,GC调优方法思路和方法,基于Hotspot jdk1.8,学习之后将了解如何对生产系统出现的GC问题进行排查解决 阅读时长约30分钟,内容主要如下: GC基础原理,涉 ...
- ELK 学习笔记之 elasticsearch Shard和Segment概念
Shard和segment概念: 转载: http://blog.csdn.net/likui1314159/article/details/53217750 Shard(分片) 一个Shard就是一 ...
- 从0开始学FreeRTOS-(消息队列)-5
## 问题解答 曾经有人问我,FreeRTOS那么多API,到底怎么记住呢? 我想说,其实API不难记,就是有点难找,因为FreeRTOS的API很多都是带参宏,所以跳来跳去的比较麻烦,而且注释也很多 ...
- Ubuntu16.04常用C++库安装及环境配置
1. 常用非线性求解库Ceres #================================================================================== ...
- 在chrome浏览器中调用IE浏览器并访问(openIE.reg自定义协议)
在谷歌浏览器中有4种方法调用IE浏览器.如下: c++ socket通过浏览器在ie中打开指定url : vb生成exe,url访问exe启动ie并打开指定url : 通过socket实现通过http ...
- m*n 矩阵中求正方形个数
<?php /** * Notes: * User: liubing17 * DateTime: 2019-10-17 17:10 */ function get($m, $n){ /* * 获 ...
- Json模块(dumps、loads、dump、load)函数篇
# dumps.loads函数 """json.dumps()用于将dict类型的数据转成strjson.loads()用于将str类型的数据转成dict. " ...
- 神奇的Java僵尸(defunct)进程问题排查过程
现象描述 大概1个月多以前 在启动脚本中增加了tail -f 用来启动后追踪日志判断是否启动成功 后发现无法执行shutdown.sh(卡住 利用curl) 然后无奈使用kill -9 但通过ps - ...
- 最简单的ArcGIS Engine应用程序(上)
名词: IWorkspaceFactory 工作空间工厂 ShapeFileWorksapceFactory 矢量文件工作空间工厂 IWorkspce 工作空间 IFeatrueWorkspace 要 ...
- C++11多线程相关
有关线程的知识,从C++11开始有了一些变化,作为初学者,对其先有个初步认识,后面用到的时候再详细剖析