Spark学习之路(十二)—— Spark SQL JOIN操作
一、 数据准备
本文主要介绍Spark SQL的多表连接,需要预先准备测试数据。分别创建员工和部门的Datafame,并注册为临时视图,代码如下:
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
empDF.createOrReplaceTempView("emp")
val deptDF = spark.read.json("/usr/file/json/dept.json")
deptDF.createOrReplaceTempView("dept")
两表的主要字段如下:
emp员工表
|-- ENAME: 员工姓名
|-- DEPTNO: 部门编号
|-- EMPNO: 员工编号
|-- HIREDATE: 入职时间
|-- JOB: 职务
|-- MGR: 上级编号
|-- SAL: 薪资
|-- COMM: 奖金
dept部门表
|-- DEPTNO: 部门编号
|-- DNAME: 部门名称
|-- LOC: 部门所在城市
注:emp.json,dept.json可以在本仓库的resources目录进行下载。
二、连接类型
Spark中支持多种连接类型:
- Inner Join : 内连接;
- Full Outer Join : 全外连接;
- Left Outer Join : 左外连接;
- Right Outer Join : 右外连接;
- Left Semi Join : 左半连接;
- Left Anti Join : 左反连接;
- Natural Join : 自然连接;
- Cross (or Cartesian) Join : 交叉(或笛卡尔)连接。
其中内,外连接,笛卡尔积均与普通关系型数据库中的相同,如下图所示:
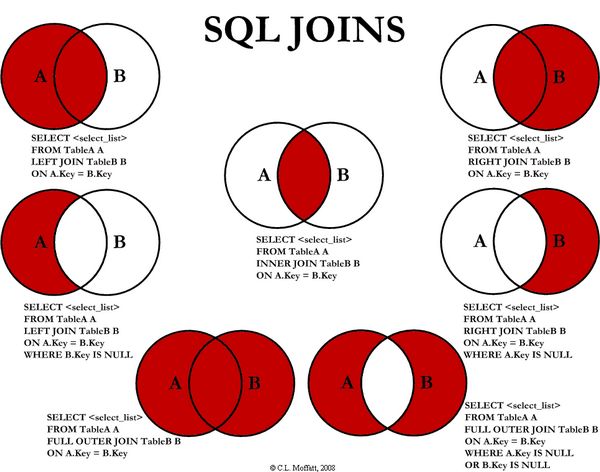
这里解释一下左半连接和左反连接,这两个连接等价于关系型数据库中的IN和NOT IN字句:
-- LEFT SEMI JOIN
SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的IN语句
SELECT * FROM emp WHERE deptno IN (SELECT deptno FROM dept)
-- LEFT ANTI JOIN
SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的IN语句
SELECT * FROM emp WHERE deptno NOT IN (SELECT deptno FROM dept)
所有连接类型的示例代码如下:
2.1 INNER JOIN
// 1.定义连接表达式
val joinExpression = empDF.col("deptno") === deptDF.col("deptno")
// 2.连接查询
empDF.join(deptDF,joinExpression).select("ename","dname").show()
// 等价SQL如下:
spark.sql("SELECT ename,dname FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
2.2 FULL OUTER JOIN
empDF.join(deptDF, joinExpression, "outer").show()
spark.sql("SELECT * FROM emp FULL OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.3 LEFT OUTER JOIN
empDF.join(deptDF, joinExpression, "left_outer").show()
spark.sql("SELECT * FROM emp LEFT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.4 RIGHT OUTER JOIN
empDF.join(deptDF, joinExpression, "right_outer").show()
spark.sql("SELECT * FROM emp RIGHT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.5 LEFT SEMI JOIN
empDF.join(deptDF, joinExpression, "left_semi").show()
spark.sql("SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno").show()
2.6 LEFT ANTI JOIN
empDF.join(deptDF, joinExpression, "left_anti").show()
spark.sql("SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno").show()
2.7 CROSS JOIN
empDF.join(deptDF, joinExpression, "cross").show()
spark.sql("SELECT * FROM emp CROSS JOIN dept ON emp.deptno = dept.deptno").show()
2.8 NATURAL JOIN
自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件的结果。
spark.sql("SELECT * FROM emp NATURAL JOIN dept").show()
以下是一个自然连接的查询结果,程序自动推断出使用两张表都存在的dept列进行连接,其实际等价于:
spark.sql("SELECT * FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
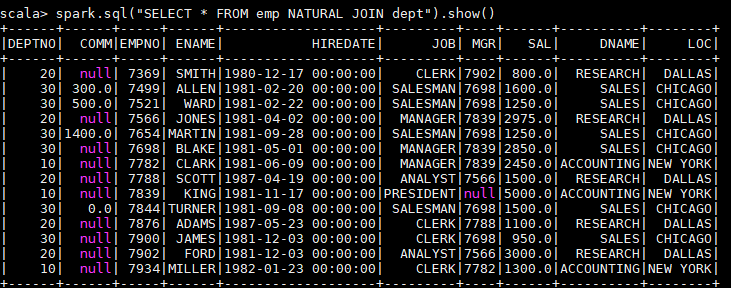
由于自然连接常常会产生不可预期的结果,所以并不推荐使用。
三、连接的执行
在对大表与大表之间进行连接操作时,通常都会触发Shuffle Join,两表的所有分区节点会进行All-to-All的通讯,这种查询通常比较昂贵,会对网络IO会造成比较大的负担。
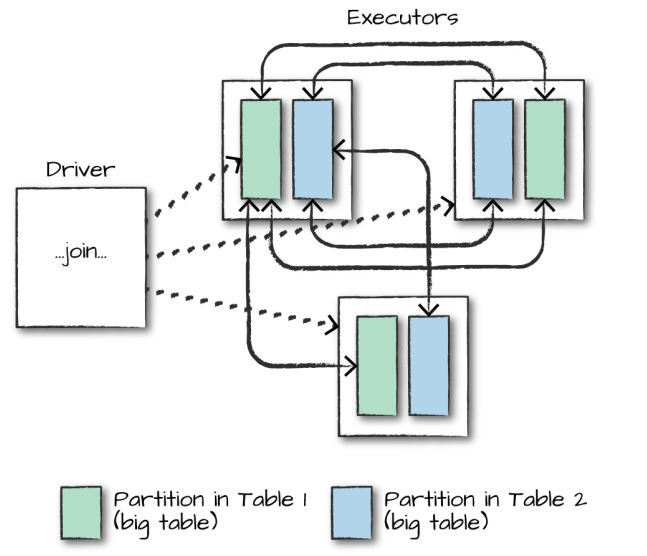
而对于大表和小表的连接操作,Spark会在一定程度上进行优化,如果小表的数据量小于Worker Node的内存空间,Spark会考虑将小表的数据广播到每一个Worker Node,在每个工作节点内部执行连接计算,这可以降低网络的IO,但会加大每个Worker Node的CPU负担。

是否采用广播方式进行Join取决于程序内部对小表的判断,如果想明确使用广播方式进行Join,则可以在DataFrame API 中使用broadcast方法指定需要广播的小表:
empDF.join(broadcast(deptDF), joinExpression).show()
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(十二)—— Spark SQL JOIN操作的更多相关文章
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark学习之路 (二)Spark2.3 HA集群的分布式安装
一.下载Spark安装包 1.从官网下载 http://spark.apache.org/downloads.html 2.从微软的镜像站下载 http://mirrors.hust.edu.cn/a ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (二)Spark2.3 HA集群的分布式安装[转]
下载Spark安装包 从官网下载 http://spark.apache.org/downloads.html 从微软的镜像站下载 http://mirrors.hust.edu.cn/apache/ ...
- Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore.SparkSQL和SparkStreaming的类似之处 SparkStreaming的运行流程 1.我们在集群中的其中一台机器上提交我们的Application Jar,然后就会 ...
- Spark学习之路 (二十八)分布式图计算系统
一.引言 在了解GraphX之前,需要先了解关于通用的分布式图计算框架的两个常见问题:图存储模式和图计算模式. 二.图存储模式 巨型图的存储总体上有边分割和点分割两种存储方式.2013年,GraphL ...
- Spark学习之路 (二十)SparkSQL的元数据
一.概述 SparkSQL 的元数据的状态有两种: 1.in_memory,用完了元数据也就丢了 2.hive , 通过hive去保存的,也就是说,hive的元数据存在哪儿,它的元数据也就存在哪儿. ...
- Spark学习之路 (二十八)分布式图计算系统[转]
引言 在了解GraphX之前,需要先了解关于通用的分布式图计算框架的两个常见问题:图存储模式和图计算模式. 图存储模式 巨型图的存储总体上有边分割和点分割两种存储方式.2013年,GraphLab2. ...
- Spark学习之路 (二十)SparkSQL的元数据[转]
概述 SparkSQL 的元数据的状态有两种: 1.in_memory,用完了元数据也就丢了 2.hive , 通过hive去保存的,也就是说,hive的元数据存在哪儿,它的元数据也就存在哪儿. 换句 ...
- Spark学习之路 (二十七)图简介
一.图 1.1 基本概念 图是由顶点集合(vertex)及顶点间的关系集合(边edge)组成的一种数据结构. 这里的图并非指代数中的图.图可以对事物以及事物之间的关系建模,图可以用来表示自然发生的连接 ...
随机推荐
- Java--垃圾收集算法及内存分配策略
本篇博客,主要介绍GC的收集算法以及根据算法要求所得的内存分配策略! 一.收集算法 收集算法,主要包括四种,分别是:Mark-Sweep(标记-清除).Copying(复制).Mark-Compact ...
- Java并发编程:synchronized和Lock
转自 : http://www.tuicool.com/articles/qYFzUjf
- Windows 下 MySQL-python 的安装
1. 标准方式 进入终端: > pip install MySQL-python 第一次安装(windows 下安装),可能会出错:缺少 vs 编译器,提示点击如下网站 Download Mic ...
- C# VS 2010创建、安装、调试 windows服务(windows service)
在一个应用程序中创建多个 windows 服务的方法和 1083 的解决办法 错误解决方案 ------------------------------------------------------ ...
- 距离北京奥运还有359天,发布WPF版本的北京2008标志(下)
原文:距离北京奥运还有359天,发布WPF版本的北京2008标志(下) 图片显示效果: XAML代码: <Viewbox Width="463.548828" Height ...
- ThreadingTest(线程测试)领先的白框进入这个行业
测试一直是黑色的,白点.在一般情况下,因为白盒测试需要逻辑思维能力是比较高的技术要求比一般开发商的项目经验和谨慎甚至更高,和较长的测试时间,用于单元测试,昂贵的工具,因此,国内企业普遍忽视白盒测试.这 ...
- js css加时间戳
为了强制更新文件,取消浏览器缓存 <link rel="stylesheet" href="~/XXX.css?time='+new Date().getTime( ...
- [转载]Delphi常用类型及定义单元
原文地址:Delphi常用类型及定义单元作者:沧海一声笑 Delphi常用类型及定义单元-总结 sndplaysound mmsystem Type Unit Date ...
- Emgu-WPF 激光雷达研究-定位实现
原文:Emgu-WPF 激光雷达研究-定位实现 特定位置或障碍物位置定位实现. 读取激光雷达数据并存储于本地作为测试数据.每一帧数据对同一障碍物的定位信息均存在偏差.所以先对需要定位的点进行数据取样. ...
- delphi2009(10,xe)下indy10发送utf8字符串
最近实现一个功能,使用delphi2009以TCP调用Java端的接口,接口要求先发送字符串的长度,然后再发送字符串内容,并且字符串要求是utf8格式的 调试了好长时间,才终于发现解决办法,或者说发现 ...