Sqoop 的基本使用
目录
一、Sqoop 基本命令
1. 查看所有命令
# sqoop help
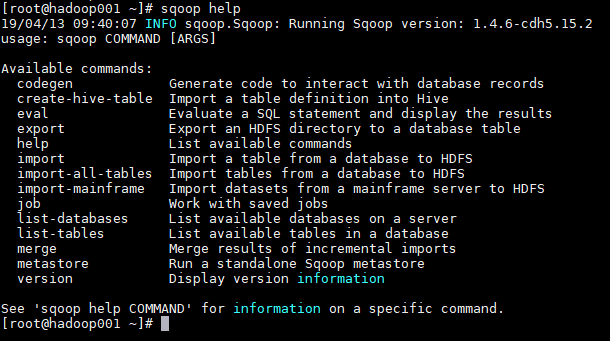
2. 查看某条命令的具体使用方法
# sqoop help 命令名
二、Sqoop 与 MySQL
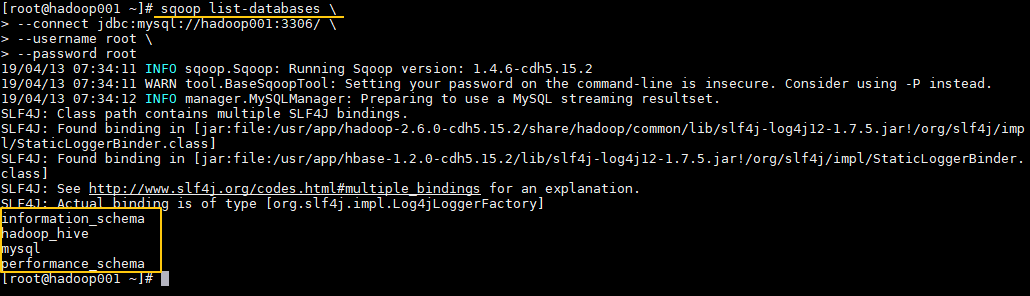
1. 查询MySQL所有数据库
通常用于Sqoop与MySQL连通测试:
sqoop list-databases \
--connect jdbc:mysql://hadoop001:3306/ \
--username root \
--password root
2. 查询指定数据库中所有数据表
sqoop list-tables \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root
三、Sqoop 与 HDFS
3.1 MySQL数据导入到HDFS
1. 导入命令
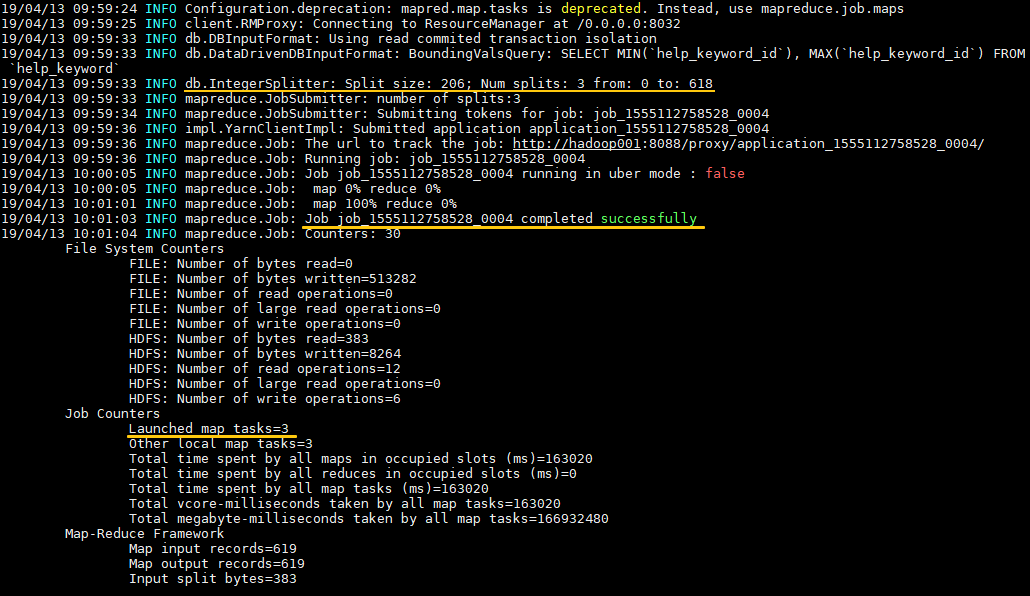
示例:导出MySQL数据库中的help_keyword表到HDFS的/sqoop目录下,如果导入目录存在则先删除再导入,使用3个map tasks并行导入。
注:help_keyword是MySQL内置的一张字典表,之后的示例均使用这张表。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 目标目录存在则先删除
--target-dir /sqoop \ # 导入的目标目录
--fields-terminated-by '\t' \ # 指定导出数据的分隔符
-m 3 # 指定并行执行的map tasks数量
日志输出如下,可以看到输入数据被平均split为三份,分别由三个map task进行处理。数据默认以表的主键列作为拆分依据,如果你的表没有主键,有以下两种方案:
- 添加
-- autoreset-to-one-mapper参数,代表只启动一个map task,即不并行执行; - 若仍希望并行执行,则可以使用
--split-by <column-name>指明拆分数据的参考列。
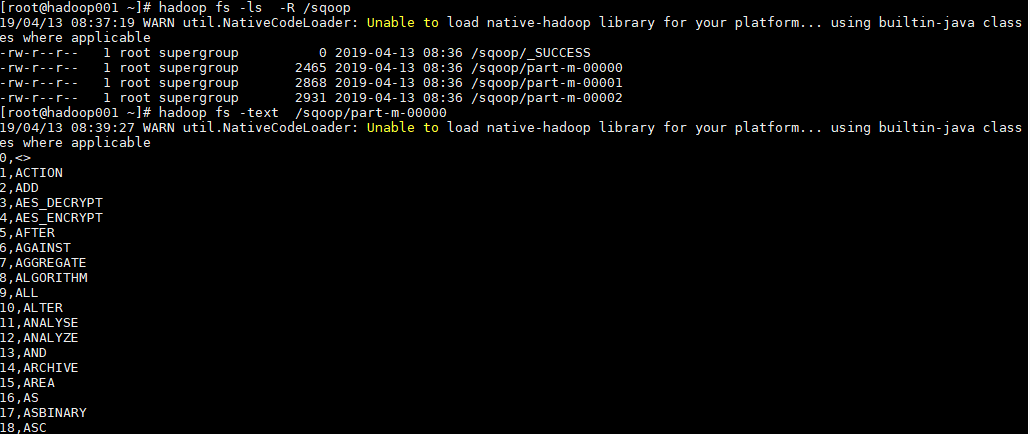
2. 导入验证
# 查看导入后的目录
hadoop fs -ls -R /sqoop
# 查看导入内容
hadoop fs -text /sqoop/part-m-00000
查看HDFS导入目录,可以看到表中数据被分为3部分进行存储,这是由指定的并行度决定的。
3.2 HDFS数据导出到MySQL
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hdfs \ # 导出数据存储在MySQL的help_keyword_from_hdf的表中
--export-dir /sqoop \
--input-fields-terminated-by '\t'\
--m 3
表必须预先创建,建表语句如下:
CREATE TABLE help_keyword_from_hdfs LIKE help_keyword ;
四、Sqoop 与 Hive
4.1 MySQL数据导入到Hive
Sqoop导入数据到Hive是通过先将数据导入到HDFS上的临时目录,然后再将数据从HDFS上Load到Hive中,最后将临时目录删除。可以使用target-dir来指定临时目录。
1. 导入命令
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 如果临时目录存在删除
--target-dir /sqoop_hive \ # 临时目录位置
--hive-database sqoop_test \ # 导入到Hive的sqoop_test数据库,数据库需要预先创建。不指定则默认为default库
--hive-import \ # 导入到Hive
--hive-overwrite \ # 如果Hive表中有数据则覆盖,这会清除表中原有的数据,然后再写入
-m 3 # 并行度
导入到Hive中的sqoop_test数据库需要预先创建,不指定则默认使用Hive中的default库。
# 查看hive中的所有数据库
hive> SHOW DATABASES;
# 创建sqoop_test数据库
hive> CREATE DATABASE sqoop_test;
2. 导入验证
# 查看 sqoop_test 数据库的所有表
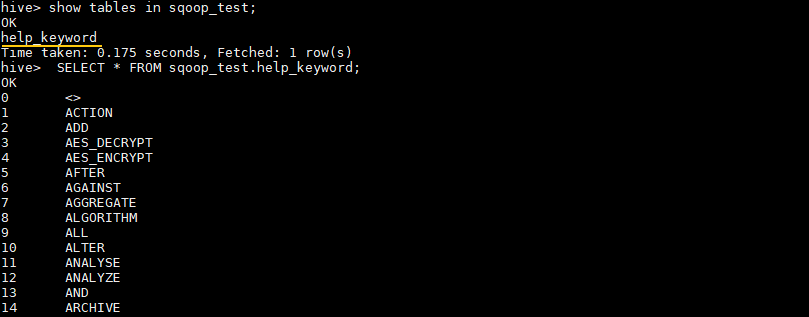
hive> SHOW TABLES IN sqoop_test;
# 查看表中数据
hive> SELECT * FROM sqoop_test.help_keyword;
3. 可能出现的问题
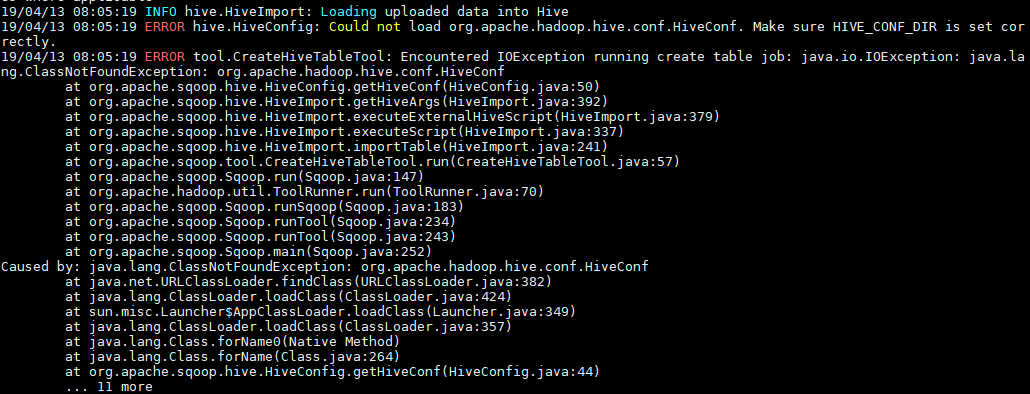
如果执行报错java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf,则需将Hive安装目录下lib下的hive-exec-**.jar放到sqoop 的lib 。
[root@hadoop001 lib]# ll hive-exec-*
-rw-r--r--. 1 1106 4001 19632031 11月 13 21:45 hive-exec-1.1.0-cdh5.15.2.jar
[root@hadoop001 lib]# cp hive-exec-1.1.0-cdh5.15.2.jar ${SQOOP_HOME}/lib
4.2 Hive 导出数据到MySQL
由于Hive的数据是存储在HDFS上的,所以Hive导入数据到MySQL,实际上就是HDFS导入数据到MySQL。
1. 查看Hive表在HDFS的存储位置
# 进入对应的数据库
hive> use sqoop_test;
# 查看表信息
hive> desc formatted help_keyword;
Location属性为其存储位置:
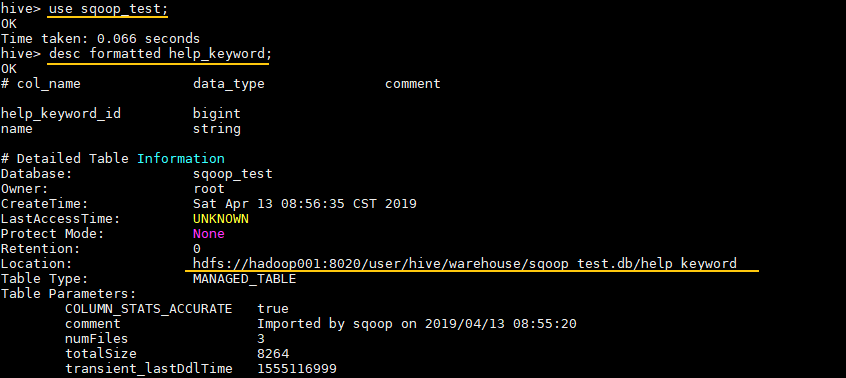
这里可以查看一下这个目录,文件结构如下:

3.2 执行导出命令
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hive \
--export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \
-input-fields-terminated-by '\001' \ # 需要注意的是 hive 中默认的分隔符为 \001
--m 3
MySQL中的表需要预先创建:
CREATE TABLE help_keyword_from_hive LIKE help_keyword ;
五、Sqoop 与 HBase
本小节只讲解从RDBMS导入数据到HBase,因为暂时没有命令能够从HBase直接导出数据到RDBMS。
5.1 MySQL导入数据到HBase
1. 导入数据
将help_keyword表中数据导入到HBase上的 help_keyword_hbase表中,使用原表的主键help_keyword_id作为RowKey,原表的所有列都会在keywordInfo列族下,目前只支持全部导入到一个列族下,不支持分别指定列族。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--hbase-table help_keyword_hbase \ # hbase 表名称,表需要预先创建
--column-family keywordInfo \ # 所有列导入到 keywordInfo 列族下
--hbase-row-key help_keyword_id # 使用原表的help_keyword_id作为RowKey
导入的HBase表需要预先创建:
# 查看所有表
hbase> list
# 创建表
hbase> create 'help_keyword_hbase', 'keywordInfo'
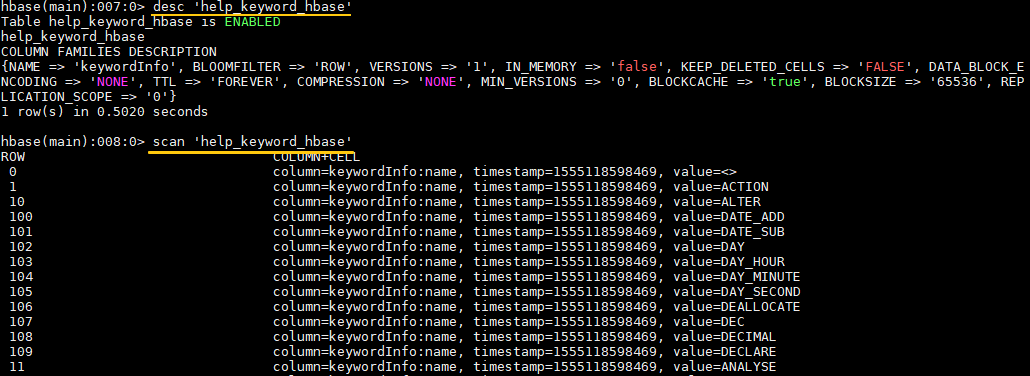
# 查看表信息
hbase> desc 'help_keyword_hbase'
2. 导入验证
使用scan查看表数据:
六、全库导出
Sqoop支持通过import-all-tables命令进行全库导出到HDFS/Hive,但需要注意有以下两个限制:
- 所有表必须有主键;或者使用
--autoreset-to-one-mapper,代表只启动一个map task; - 你不能使用非默认的分割列,也不能通过WHERE子句添加任何限制。
第二点解释得比较拗口,这里列出官方原本的说明:
- You must not intend to use non-default splitting column, nor impose any conditions via a
WHEREclause.
全库导出到HDFS:
sqoop import-all-tables \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--warehouse-dir /sqoop_all \ # 每个表会单独导出到一个目录,需要用此参数指明所有目录的父目录
--fields-terminated-by '\t' \
-m 3
全库导出到Hive:
sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--hive-database sqoop_test \ # 导出到Hive对应的库
--hive-import \
--hive-overwrite \
-m 3
七、Sqoop 数据过滤
7.1 query参数
Sqoop支持使用query参数定义查询SQL,从而可以导出任何想要的结果集。使用示例如下:
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--query 'select * from help_keyword where $CONDITIONS and help_keyword_id < 50' \
--delete-target-dir \
--target-dir /sqoop_hive \
--hive-database sqoop_test \ # 指定导入目标数据库 不指定则默认使用Hive中的default库
--hive-table filter_help_keyword \ # 指定导入目标表
--split-by help_keyword_id \ # 指定用于split的列
--hive-import \ # 导入到Hive
--hive-overwrite \ 、
-m 3
在使用query进行数据过滤时,需要注意以下三点:
必须用
--hive-table指明目标表;如果并行度
-m不为1或者没有指定--autoreset-to-one-mapper,则需要用--split-by指明参考列;SQL的
where字句必须包含$CONDITIONS,这是固定写法,作用是动态替换。
7.2 增量导入
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \
--target-dir /sqoop_hive \
--hive-database sqoop_test \
--incremental append \ # 指明模式
--check-column help_keyword_id \ # 指明用于增量导入的参考列
--last-value 300 \ # 指定参考列上次导入的最大值
--hive-import \
-m 3
incremental参数有以下两个可选的选项:
- append:要求参考列的值必须是递增的,所有大于
last-value的值都会被导入; - lastmodified:要求参考列的值必须是
timestamp类型,且插入数据时候要在参考列插入当前时间戳,更新数据时也要更新参考列的时间戳,所有时间晚于last-value的数据都会被导入。
通过上面的解释我们可以看出来,其实Sqoop的增量导入并没有太多神器的地方,就是依靠维护的参考列来判断哪些是增量数据。当然我们也可以使用上面介绍的query参数来进行手动的增量导出,这样反而更加灵活。
八、类型支持
Sqoop默认支持数据库的大多数字段类型,但是某些特殊类型是不支持的。遇到不支持的类型,程序会抛出异常Hive does not support the SQL type for column xxx异常,此时可以通过下面两个参数进行强制类型转换:
- –map-column-java<mapping> :重写SQL到Java类型的映射;
- –map-column-hive <mapping> : 重写Hive到Java类型的映射。
示例如下,将原先id字段强制转为String类型,value字段强制转为Integer类型:
$ sqoop import ... --map-column-java id=String,value=Integer
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Sqoop 的基本使用的更多相关文章
- sqoop:Failed to download file from http://hdp01:8080/resources//oracle-jdbc-driver.jar due to HTTP error: HTTP Error 404: Not Found
环境:ambari2.3,centos7,sqoop1.4.6 问题描述:通过ambari安装了sqoop,又添加了oracle驱动配置,如下: 保存配置后,重启sqoop报错:http://hdp0 ...
- 安装sqoop
安装sqoop 1.默认已经安装好java+hadoop 2.下载对应hadoop版本的sqoop版本 3.解压安装包 tar zxvf sqoop-1.4.6.bin__hadoop-2.0.4-a ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- Oozie分布式任务的工作流——Sqoop篇
Sqoop的使用应该是Oozie里面最常用的了,因为很多BI数据分析都是基于业务数据库来做的,因此需要把mysql或者oracle的数据导入到hdfs中再利用mapreduce或者spark进行ETL ...
- [大数据之Sqoop] —— Sqoop初探
Sqoop是一款用于把关系型数据库中的数据导入到hdfs中或者hive中的工具,当然也支持把数据从hdfs或者hive导入到关系型数据库中. Sqoop也是基于Mapreduce来做的数据导入. 关于 ...
- [大数据之Sqoop] —— 什么是Sqoop?
介绍 sqoop是一款用于hadoop和关系型数据库之间数据导入导出的工具.你可以通过sqoop把数据从数据库(比如mysql,oracle)导入到hdfs中:也可以把数据从hdfs中导出到关系型数据 ...
- Sqoop切分数据的思想概况
Sqoop通过--split-by指定切分的字段,--m设置mapper的数量.通过这两个参数分解生成m个where子句,进行分段查询.因此sqoop的split可以理解为where子句的切分. 第一 ...
- sqoop数据导出导入命令
1. 将mysql中的数据导入到hive中 sqoop import --connect jdbc:mysql://localhost:3306/sqoop --direct --username r ...
- Apache Sqoop - Overview——Sqoop 概述
Apache Sqoop - Overview Apache Sqoop 概述 使用Hadoop来分析和处理数据需要将数据加载到集群中并且将它和企业生产数据库中的其他数据进行结合处理.从生产系统加载大 ...
- sqoop使用中的小问题
1.数据库连接异常 执行数据导出 sqoop export --connect jdbc:mysql://192.168.208.129:3306/test --username hive --P - ...
随机推荐
- wxWindows
用C++编写跨平台程序 中文版说明 本教程由Gxl117翻译并将继续维护,这是本教程的第一稿,假设发现错误请与我(Email:gxl117@yahoo.com.cn)联系让我能及时修正它.之后还会对这 ...
- 获取当前电脑的cpu使用率、内存使用率
https://www.cnblogs.com/Chary/p/7771365.html http://www.cnblogs.com/zl1991/p/4679461.html 要关注几个类 Per ...
- 在MVC项目中分页使用MvcPager插件
参考网站 http://www.webdiyer.com/mvcpager/demos/ 这个插件非常简单易用,如果想快速使用 可以参考我这篇文章,其实参考网站也是非常简单的 首先选择你的web项目 ...
- 保存画面为图片 当前MFC保存该程序为图片 c++ vc
将屏幕保存为图片.使用vs2008编译通过. [cpp] view plaincopy #include "stdafx.h" #include <windows.h> ...
- [实时更新]jquery完整版下载
jquery-2.1.0 注!不再支持IE 6/7/8 直接引用地址: 开发版地址1: <script src="http://code.jquery.com/jquery-2. ...
- Linux性能测试 top衍生命令 atop/htop/slaptop
1. Atop Atop 是一个类似 top 的工具,但比 top 更有料.通过 Atop,你能够监视 Linux 系统的性能状况,包括进程活动.CPU.内存.硬盘.网络等方面的使用情况等. 2. h ...
- 使用devcpp在windowXP上qt4.4.3安装与使用入门
1.安装前先安装devcpp,我下载的是devcpp-4.9.9.2_setup.exe2.安装qt4.4.3,下载的是qt-win-opensource-4.4.3-mingw.rar,解压后运行后 ...
- ASP.NET Core 使用 EF 框架查询数据 - ASP.NET Core 基础教程 - 简单教程,简单编程
原文:ASP.NET Core 使用 EF 框架查询数据 - ASP.NET Core 基础教程 - 简单教程,简单编程 ASP.NET Core 使用 EF 框架查询数据 上一章节我们学习了如何设置 ...
- [Windows][VC]开机自动启动程序的几种方法
原文:[Windows][VC]开机自动启动程序的几种方法 很多监控软件要求软件能够在系统重新启动后不用用户去点击图标启动项目,而是直接能够启动运行,方法是写注册表Software\\Microsof ...
- ELINK编程器典型场景之多APP文件下载
有些应用场合中,单MCU内会采用BootLoader+APP1+APP2的加载模式,程序启动时先进入BootLoader程序,依据设定条件跳转至APPx应用运行:为满足此类需求,设计多达5个程序文件( ...