Jsoup+HttpUnit爬取搜狐新闻
怎么说呢,静态的页面,但我也写了动态的接口支持,方便后续爬取别的新闻网站使用。
一个接口,接口有一个抽象方法pullNews用于拉新闻,有一个默认方法用于获取新闻首页:
public interface NewsPuller {
void pullNews();
// url:即新闻首页url
// useHtmlUnit:是否使用htmlunit
default Document getHtmlFromUrl(String url, boolean useHtmlUnit) throws Exception {
if (!useHtmlUnit) {
return Jsoup.connect(url)
//模拟火狐浏览器
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")
.get();
} else {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(10000);
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(10000);
String htmlString = htmlPage.asXml();
return Jsoup.parse(htmlString);
} finally {
webClient.close();
}
}
}
}
之后就是爬虫;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.WebConsole.Logger;
import com.gargoylesoftware.htmlunit.html.HtmlPage; import java.io.IOException;
import java.net.MalformedURLException;
import java.util.Date;
import java.util.HashSet; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.LoggerFactory; public class SohuNewsPuller implements NewsPuller {
public static void main(String []args) {
System.out.println("123");
SohuNewsPuller ss=new SohuNewsPuller();
ss.pullNews();
}
private String url="http://news.sohu.com/";
public void pullNews() {
Document html= null;
try {
html = getHtmlFromUrl(url, false);
} catch (Exception e) {
e.printStackTrace();
return;
}
// 2.jsoup获取新闻<a>标签
Elements newsATags = html.select("div.focus-news")
.select("div.list16")
.select("li")
.select("a"); for (Element a : newsATags) {
String url = a.attr("href");
System.out.println("内容"+a.text());
Document newsHtml = null;
try {
newsHtml = getHtmlFromUrl(url, false);
Element newsContent = newsHtml.select("div#article-container")
.select("div.main")
.select("div.text")
.first();
String title1 = newsContent.select("div.text-title").select("h1").text();
String content = newsContent.select("article.article").first().text();
System.out.println("url"+"\n"+title1+"\n"+content); } catch (Exception e) {
e.printStackTrace();
}
}
} }
结果:
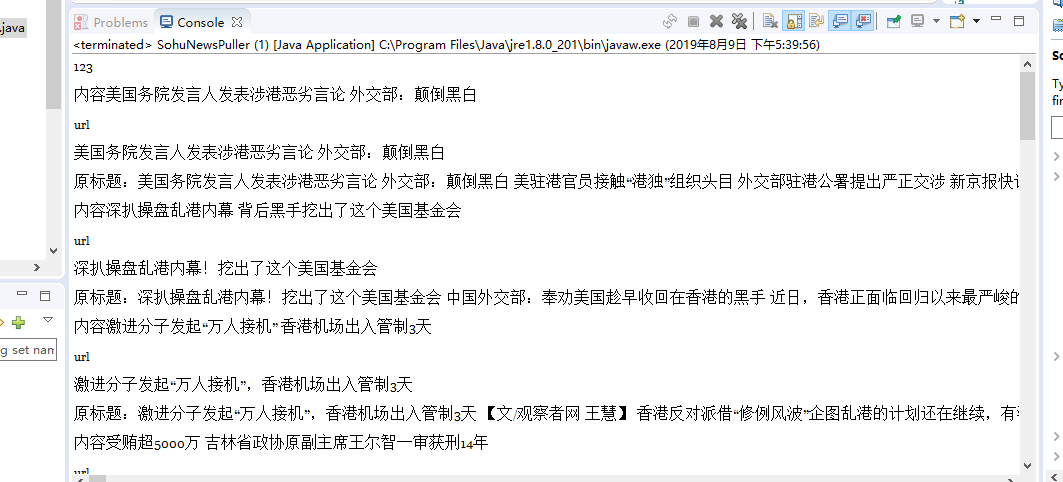
当然还没有清洗内容,后续会清洗以及爬取动态网站啥的。
参考博客:https://blog.csdn.net/gx304419380/article/details/80619043#commentsedit
代码已上传github:https://github.com/mmmjh/GetSouhuNews
欢迎吐槽!!!!
绝大部分代码是参考的人家的博客。我只是把项目还原了。
Jsoup+HttpUnit爬取搜狐新闻的更多相关文章
- 利用Jsoup包爬取网站内容
一 Jsoup包 下载链接:http://download.csdn.net/detail/u014000832/7994245 二 爬取搜狐新闻网站标题等内容 package com.test1; ...
- 利用朴素贝叶斯分类算法对搜狐新闻进行分类(python)
数据来源 https://www.sogou.com/labs/resource/cs.php介绍:来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL ...
- 搜狗输入法弹出搜狐新闻的解决办法(sohunews.exe)
狗输入法弹出搜狐新闻的解决办法(sohunews.exe) 1.找到搜狗输入法的安装目录(一般是C:\program files\sougou input\版本号\)2.右键点击sohunews.ex ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- 【NLP】3000篇搜狐新闻语料数据预处理器的python实现
3000篇搜狐新闻语料数据预处理器的python实现 白宁超 2017年5月5日17:20:04 摘要: 关于自然语言处理模型训练亦或是数据挖掘.文本处理等等,均离不开数据清洗,数据预处理的工作.这里 ...
- Python爬取腾讯新闻首页所有新闻及评论
前言 这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫.选用Python的Scrapy框架.这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址. Chrom ...
- 基于jieba,TfidfVectorizer,LogisticRegression进行搜狐新闻文本分类
一.简介 此文是对利用jieba,word2vec,LR进行搜狐新闻文本分类的准确性的提升,数据集和分词过程一样,这里就不在叙述,读者可参考前面的处理过程 经过jieba分词,产生24000条分词结果 ...
- 利用jieba,word2vec,LR进行搜狐新闻文本分类
一.简介 1)jieba 中文叫做结巴,是一款中文分词工具,https://github.com/fxsjy/jieba 2)word2vec 单词向量化工具,https://radimrehurek ...
- 利用搜狐新闻语料库训练100维的word2vec——使用python中的gensim模块
关于word2vec的原理知识参考文章https://www.cnblogs.com/Micang/p/10235783.html 语料数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会, ...
随机推荐
- Redux API
Redux API Redux的API非常少.Redux定义了一系列的约定(contract),同时提供少量辅助函数来把这些约定整合到一起. Redux只关心如何管理state.在实际的项目中 ...
- QT debug执行exe文件 应用程序无法正常启动0xc000007b
遇到这种错,发现并不是因为缺失dll文件,因为我把需要的DLL都放到Debug文件下了,但还是有这问题: 解决方法: 右键点击-- >我的电脑--属性-->高级系统设置-->环境变量 ...
- day(66)作业
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- docker修改系统时间总结
最近弄docker烦躁的一笔,时区问题踩了不少坑,为了以后再遇到类似问题再花时间查资料,特记录一下... Ubuntu: echo "Asia/Shanghai" > /et ...
- 2019徐州网络赛 I J M
I. query 比赛时候没有预处理因子疯狂t,其实预处理出来因子是\(O(nlog(n))\)级别的 每个数和他的因子是一对偏序关系,因此询问转化为(l,r)区间每个数的因子在区间(l,r)的个数 ...
- SVO 特征对齐代码分析
SVO稀疏图像对齐之后使用特征对齐,即通过地图向当前帧投影,并使用逆向组合光流以稀疏图像对齐的结果为初始值,得到更精确的特征位置. 主要涉及文件: reprojector.cpp matcher.cp ...
- npm 命令 --save 和 --save-dev 的区别
回顾 npm install 命令 我们在使用 npm install 安装模块的模块的时候 ,一般会使用下面这几种命令形式: 1 2 3 4 5 6 7 npm install moduleName ...
- hashlib和hmac模块
目录 一.hashlib模块 1.0.1 hash是什么 1.0.2 撞库破解hash算法加密 一.hashlib模块 1.0.1 hash是什么 hash是一种算法(Python3.版本里使用has ...
- Windows许可证 即将过期
最近打开电脑,系统总是自动弹出Windows许可证即将过期的弹窗,现在总结方法如下. 命令都是在运行窗口输入的打开方式:win+R组合键或者右键点击win10开始菜单,点击“运行”查看系统版本:win ...
- php+laravel依赖注入浅析
laravel容器包含控制反转和依赖注入,使用起来就是,先把对象bind好,需要时可以直接使用make来取就好. 通常我们的调用如下. $config = $container->make('c ...