centos6.8下hadoop3.1.1完全分布式安装指南
前述:这篇文档是建立在三台虚拟机相互ping通,防火墙关闭,hosts文件修改,SSH 免密码登录,主机名修改等的基础上开始的。
一.传入文件
1.创建安装目录
mkdir /usr/local/soft

2.打开xftp,找到对应目录,将所需安装包传入进去

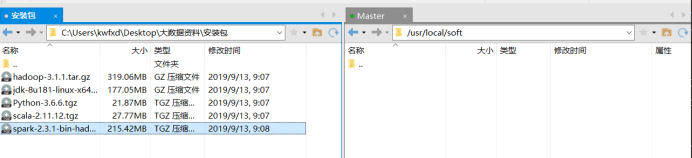

查看安装包:cd /usr/local/soft

二.安装JAVA
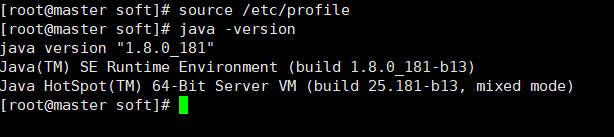
1.查看是否已安装jdk: java -version

2.未安装,解压java安装包: tar -zxvf jdk-8u181-linux-x64.tar.gz
(每个人安装包可能不一样,自己参考)


3.给jdk重命名,并查看当前位置:mv jdk1.8.0_181 java

4.配置jdk环境:vim /etc/profile.d/jdk.sh


export JAVA_HOME=/usr/local/soft/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/rt.jar
5.更新环境变量并检验:source /etc/profile
三.安装Hadoop
1.解压hadoop安装包:tar -zxvf hadoop-3.1.1.tar.gz

2.查看并重命名:mv hadoop-3.1.1 hadoop

3.配置 hadoop 配置文件
3.1修改 core-site.xml 配置文件:vim hadoop/etc/hadoop/core-site.xml

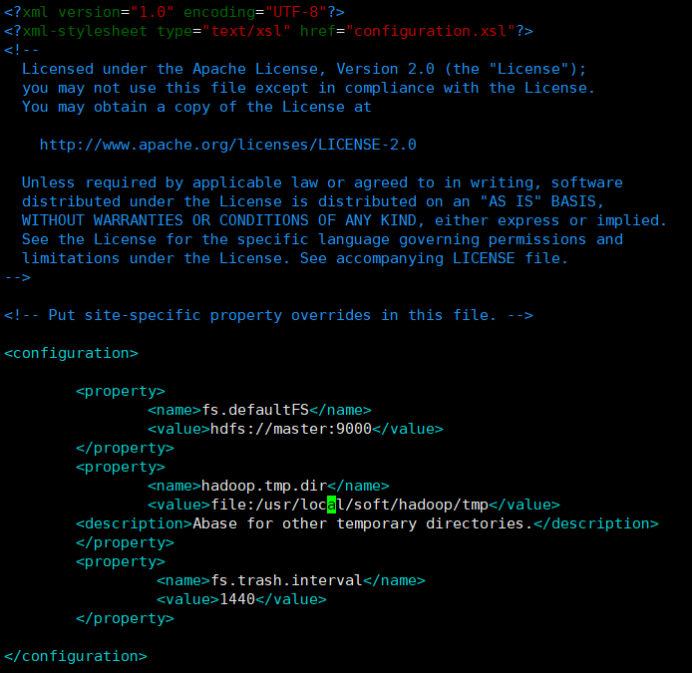
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/soft/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
3.2修改 hdfs-site.xml 配置文件:vim hadoop/etc/hadoop/hdfs-site.xml
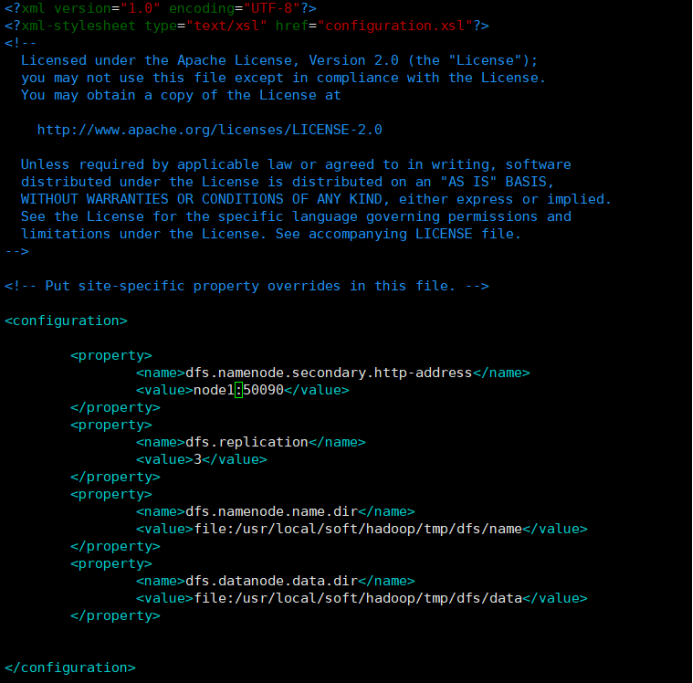
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/soft/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/soft/hadoop/tmp/dfs/data</value>
</property>
3.3修改 workers 配置文件:vim hadoop/etc/hadoop/workers

3.4修改hadoop-env.sh文件:vim hadoop/etc/hadoop/hadoop-env.sh
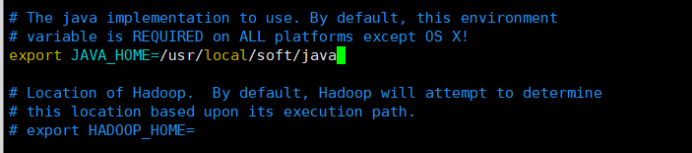
export JAVA_HOME=/usr/local/soft/java
3.5修改yarn-site.xml文件:vim hadoop/etc/hadoop/yarn-site.xml
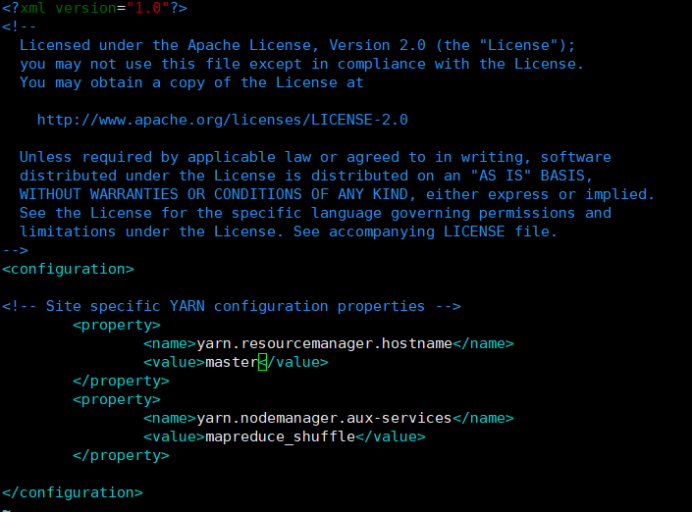
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.6更新配置文件:source hadoop/etc/hadoop/hadoop-env.sh

3.7修改 start-dfs.sh配置文件: im hadoop/sbin/start-dfs.sh


export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.8修改 stop-dfs.sh配置文件: vim hadoop/sbin/stop-dfs.sh

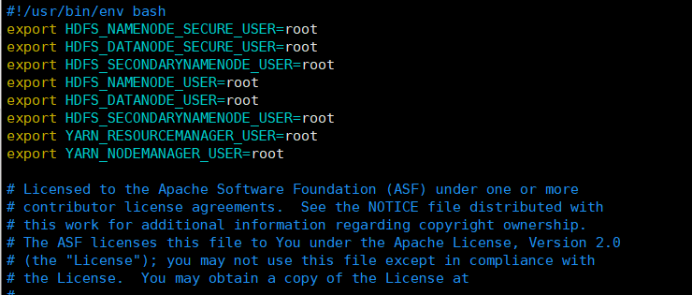
export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.9修改 start-yarn.sh配置文件:vim hadoop/sbin/start-yarn.sh

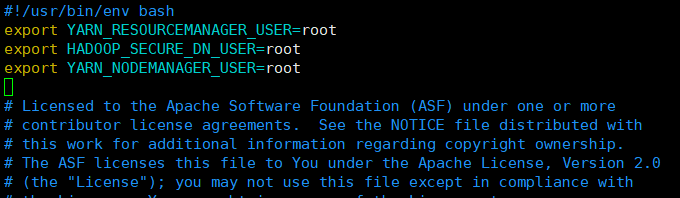
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
3.10修改 stop-yarn.sh配置文件:vim hadoop/sbin/stop-yarn.sh

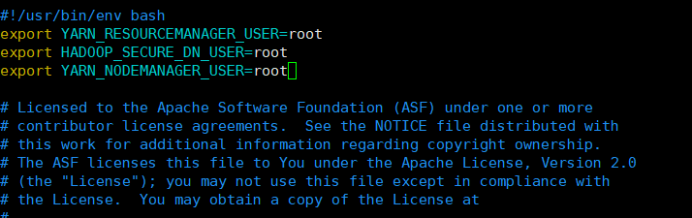
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
3.11 取消打印警告信息:vim hadoop/etc/hadoop/log4j.properties
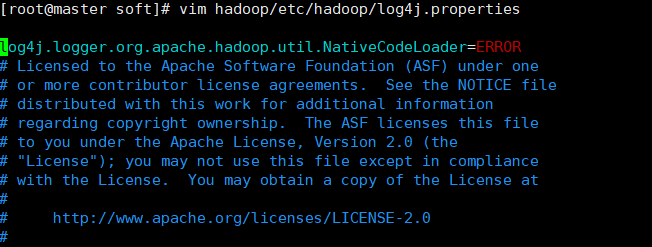
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
四.同步配置信息:
1.同步node1:scp -r soft root@node1:/usr/local/

同步node2:scp -r soft root@node2:/usr/local/

2.等待所有传输完成,配置profile文件:vim /etc/profile.d/hadoop.sh

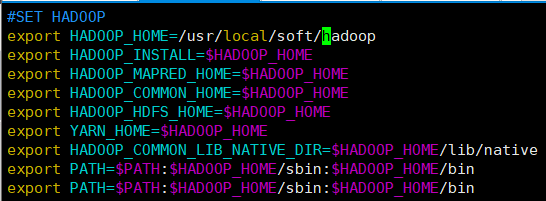
#SET HADOOP
export HADOOP_HOME=/usr/local/soft/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
3.继续传输
对node1: scp /etc/profile.d/jdk.sh root@node1:/etc/profile.d/
scp /etc/profile.d/hadoop.sh root@node1:/etc/profile.d/

对node2: scp /etc/profile.d/jdk.sh root@node2:/etc/profile.d/
scp /etc/profile.d/hadoop.sh root@node2:/etc/profile.d/

4.在三台虚拟机上都要执行
source /etc/profile
source /usr/local/soft/hadoop/etc/hadoop/hadoop-env.sh

(只显示一台)
5.格式化 HDFS 文件系统:hdfs namenode -format(只在master上)

五.启动集群
cd /usr/local/soft/hadoop/sbin/
./start-all.sh

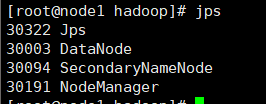
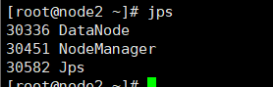
启动后在三台虚拟机上分别输入jps
结果如下:

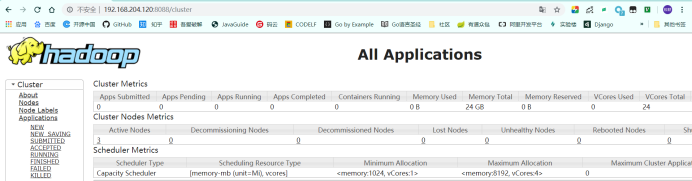
windows下谷歌浏览器检验:
http://192.168.204.120:8088/cluster(输入自己的master的ip地址)
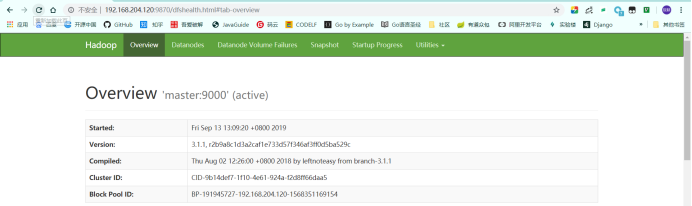
Hadoop测试(MapReduce 执行计算测试):


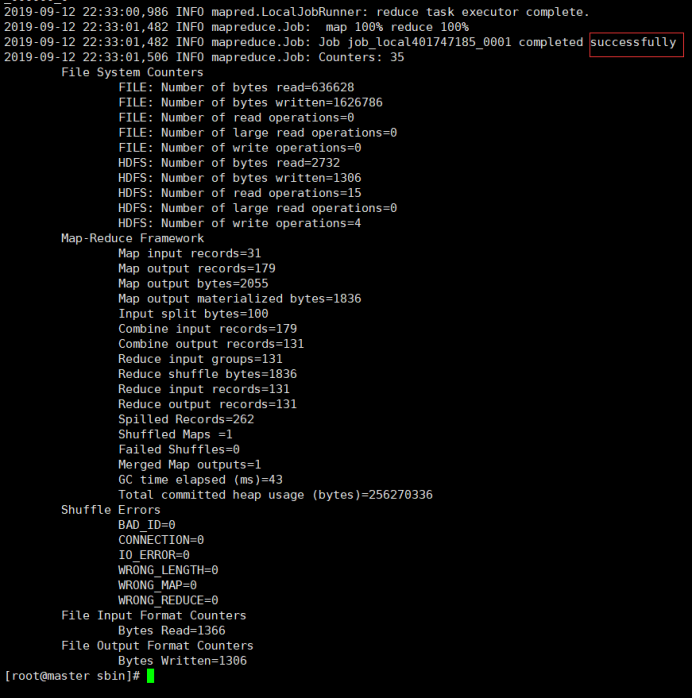
hadoop jar /usr/local/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /input /output

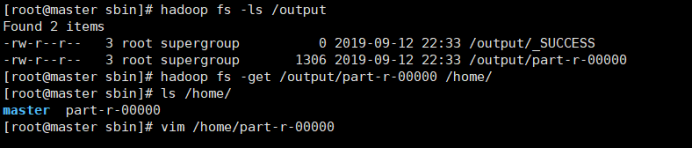
查看运行结果:
以上hadoop配置完成。
centos6.8下hadoop3.1.1完全分布式安装指南的更多相关文章
- 伪分布式下Hadoop3.2版本打不开localhost:50070,可以打开localhost:8088
一.问题描述 伪分布式下Hadoop3.2版本打不开localhost:50070,可以打开localhost:8088 二.解决办法 Hadoop3.2版本namenode的默认端口配置已经更改为9 ...
- Centos6.9下RabbitMQ集群部署记录
之前简单介绍了CentOS下单机部署RabbltMQ环境的操作记录,下面详细说下RabbitMQ集群知识,RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言, ...
- 大数据学习笔记【一】:Hadoop-3.1.2完全分布式环境搭建(Windows 10)
一.前言 Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建). 首先,步骤: ① 准备安装包和工具: hadoop-3 ...
- 【转载】CentOS6.5_X64下安装配置MongoDB数据库
[转载]CentOS6.5_X64下安装配置MongoDB数据库 2014-05-16 10:07:09| 分类: 默认分类|举报|字号 订阅 下载LOFTER客户端 本文转载自zhm&l ...
- CentOS6.8下部署Zabbix3.0
Centos6.8下部署安装zabbix3.0: 环境要求 PHP >= 5.4 (CentOS6默认为5.3.3,需要更新) curl >= 7.20 (如需支持SMTP认证,需更新) ...
- CentOS6.5下安装apache2.2和PHP 5.5.28
CentOS6.5下安装apache2.2 1. 准备程序 :httpd-2.2.27.tar.gz 下载地址:http://httpd.apache.org/download.cgi#apache2 ...
- [转] Linux学习之CentOS(十三)--CentOS6.4下Mysql数据库的安装与配置
from: http://www.cnblogs.com/xiaoluo501395377/archive/2013/04/07/3003278.html 如果要在Linux上做j2ee开发,首先得 ...
- CentOS6.5下安装配置MySQL
CentOS6.5下安装配置MySQL,配置方法如下: 安装mysql数据库:# yum install -y mysql-server mysql mysql-deve 查看mysql-server ...
- centos6.7下编译安装lnmp
很多步骤不说明了,请参照本人的centos6.7下编译安装lamp,这次的架构是nginx+php-fpm一台服务器,mysql一台服务器 (1)首先编译安装nginx: 操作命令: yum -y g ...
随机推荐
- 6.python3实用编程技巧进阶(一)
1.1.如何在列表中根据条件筛选数据 # 1.1.如何在列表中根据条件筛选数据 data = [-1, 2, 3, -4, 5] #筛选出data列表中大于等于零的数据 #第一种方法,不推荐 res1 ...
- https://jwt.io/一个可以解析token的神奇网站
网址:https://jwt.io/ 效果:
- Linux MySQL 开启远程访问
进入mysql以后 use mysql; GRANT ALL ON *.* TO user@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
- python爬虫(1)——正则表达式
原子 原子是正则表达式中最基本的组成单位,每个正则表达式中至少要包含一个原子. 常见的原子类型: 普通字符作为原子 非打印字符作为原子 通用字符作为原子 原子表 #普通字符作为原子 import re ...
- 如何把转入成功的XXX.sql导入到自己的数据库里
1.新建自己的mysql连接,mysql连接名随便起,如cxf 密码尽量写123456或者root,防止忘记.按照图示右键(如果想在已有的mysql连接基础上建立数据库连接直接看第二步) 2.右键名 ...
- background-origin和background-origin和2D转换
1--> background-origin:可以定义背景图片的定位区域,它有3个属性值 background-origin:border-box /padding-box/ content-b ...
- prometheus数据可视化
一.prometheus自带简单的web可视化页面: http://192.168.1.28:9090/graph 二.grafana是一套开源的分析监视平台,支持prometheus等数据源:UI非 ...
- mysql high severity error 缺少根元素
high severity error 缺少根元素: C:\Users\cf.yu\AppData\Roaming\Oracle\MySQL Notifier里的settings.config.删除他 ...
- 剑指Offer-14.链表中倒数第k个结点(C++/Java)
题目: 输入一个链表,输出该链表中倒数第k个结点. 分析: 第一个解法,我们可以先遍历一遍链表,计算下节点的总数n,然后再从头结点查n-k个节点,即是倒数第k个节点. 第二个解法,便是使用双指针,两个 ...
- vscode中关于launch.json和tasks.json的变量说明
vscode是一个轻量级的文本编辑器,但是它的拓展插件可以让他拓展成功能齐全的IDE,这其中就靠的是tasks.json和launch.json的配置 这两个json文件的相关变量是vscode特有的 ...