Solr的知识点学习
Solr官方网站:http://lucene.apache.org/solr/
1、Solr单机版的安装与使用,简单写了如何进行Solr的安装与使用。那么很多细节性问题,这里进行简单的介绍。我使用的是Solr与Tomcat整合配置。
2、什么是Solr Home,之前写的是Solr需要和Solr home进行关联,但是什么是Solr Home呢?
答:创建一个Solr home目录,目录中包括了运行Solr实例所有的配置文件和数据文件,SolrHome是Solr运行的主目录,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
例如:example\solr是一个solr home目录结构,目录结构如下所示:
[root@localhost example]# cd solr
[root@localhost solr]# ls
bin collection1 README.txt solr.xml zoo.cfg
[root@localhost solr]# ll
total
drwxr-xr-x. root root Dec bin
drwxr-xr-x. root root Sep : collection1
-rw-r--r--. root root Dec README.txt
-rw-r--r--. root root Dec solr.xml
-rw-r--r--. root root Dec zoo.cfg
[root@localhost solr]#
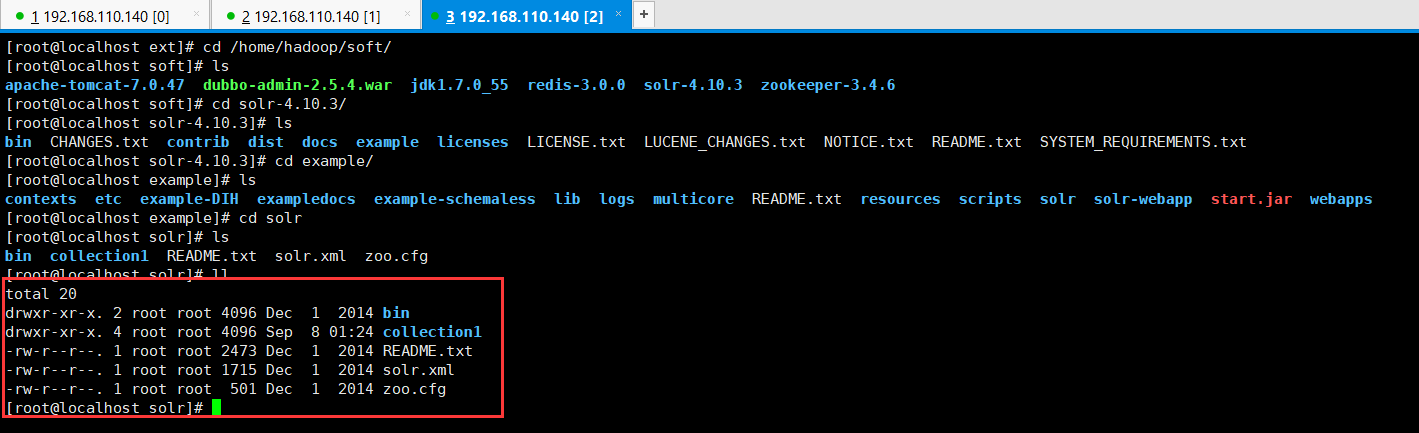
上图中"collection1"是一个SolrCore(Solr实例)目录。
说明:collection1:叫做一个solr运行实例solrCore,solrCore名称不固定,一个solr运行实例对外单独提供索引和搜索接口。solrHome中可以创建多个solr运行实例solrCore,一个solr的运行实例对应一个索引目录,conf是solrCore的配置文件目录 。
总结:一个solrHome可以包括多个solrCore(solr实例),每个solrCore提供单独的搜索和索引服务。collection1叫做一个solr运行实例solrCore。
3、什么是Solr SolrCore。
答:collection1是一个solrCore(solr实例)。其目录结构如下所示:schema.xml配置文件就在一个Solr实例里面,目录路径如是:/home/hadoop/soft/solr-4.10.3/example/solr/collection1/conf
[root@localhost ext]# cd /home/hadoop/soft/
[root@localhost soft]# ls
apache-tomcat-7.0. dubbo-admin-2.5..war jdk1..0_55 redis-3.0. solr-4.10. zookeeper-3.4.
[root@localhost soft]# cd solr-4.10./
[root@localhost solr-4.10.]# ls
bin CHANGES.txt contrib dist docs example licenses LICENSE.txt LUCENE_CHANGES.txt NOTICE.txt README.txt SYSTEM_REQUIREMENTS.txt
[root@localhost solr-4.10.]# cd example/
[root@localhost example]# ls
contexts etc example-DIH exampledocs example-schemaless lib logs multicore README.txt resources scripts solr solr-webapp start.jar webapps
[root@localhost example]# cd solr
[root@localhost solr]# ls
bin collection1 README.txt solr.xml zoo.cfg
[root@localhost solr]# ll
total
drwxr-xr-x. root root Dec bin
drwxr-xr-x. root root Sep : collection1
-rw-r--r--. root root Dec README.txt
-rw-r--r--. root root Dec solr.xml
-rw-r--r--. root root Dec zoo.cfg
[root@localhost solr]# cd collection1/
[root@localhost collection1]# ls
conf core.properties data README.txt
[root@localhost collection1]# ll
total
drwxr-xr-x. root root Sep : conf
-rw-r--r--. root root Dec core.properties
drwxr-xr-x. root root Sep : data
-rw-r--r--. root root Dec README.txt
[root@localhost collection1]#
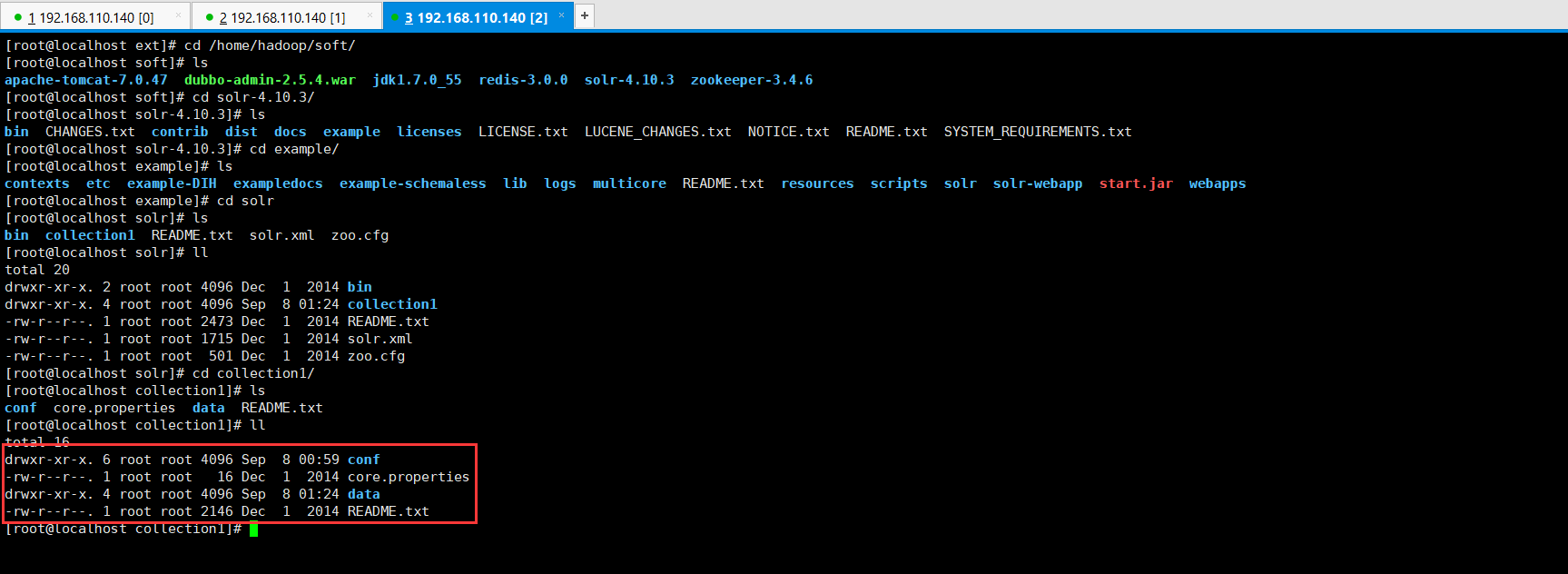
4、Solr Home与SolrCore什么关系呢?
答:创建一个solr home目录,目录中包括了运行Solr实例所有的配置文件和数据文件,solrHome是Solr运行的主目录,一个solrHome可以包括多个solrCore(Solr实例),每个solrCore提供单独的搜索和索引服务。
创建一个目录作为solr Home,将/home/hadoop/soft/solr-4.10.3/example/solr目录拷贝至新创建的solr Home目录下并改名为solrhome。/home/hadoop/soft/solr-4.10.3/example/solr/collection1/conf/solrconfig.xml配置文件,在solrCore的conf目录下,它是solrCore运行的配置文件。
注意:
collection1:叫做一个Solr运行实例SolrCore,SolrCore名称不固定,一个solr运行实例对外单独提供索引和搜索接口。
solrHome中可以创建多个solr运行实例SolrCore。
一个solr的运行实例对应一个索引目录。
conf是SolrCore的配置文件目录 。
5、Solr提供web界面菜单栏都是什么呢?

详细介绍如下所示:
a、Dashboard:
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。 b、Logging:
Solr运行日志信息 c、Cloud:
Cloud即SolrCloud,即Solr云(集群),当使用SolrCloud模式运行时会显示此菜单,如下图是Solr Cloud的管理界面: d、Core Admin:
Solr Core的管理界面。Solr Core是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。 e、java properties:
Solr在JVM运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。 f、Tread Dump:
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。 g、Core selector:
选择一个SolrCore进行详细操作。
Core selector选择一个SolrCore进行详细操作,如下:
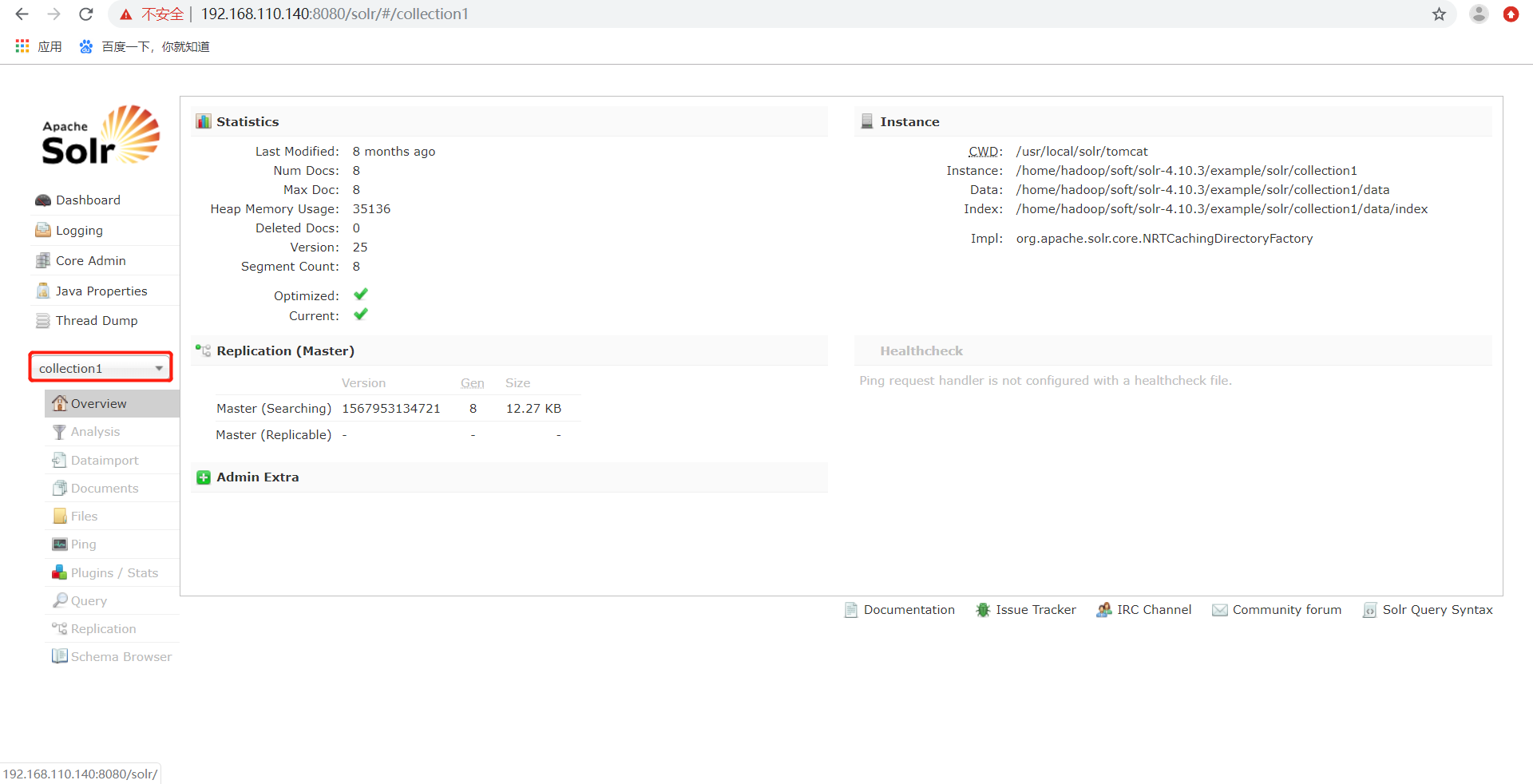
Analysis通过此界面可以测试索引分析器和搜索分析器的执行情况。
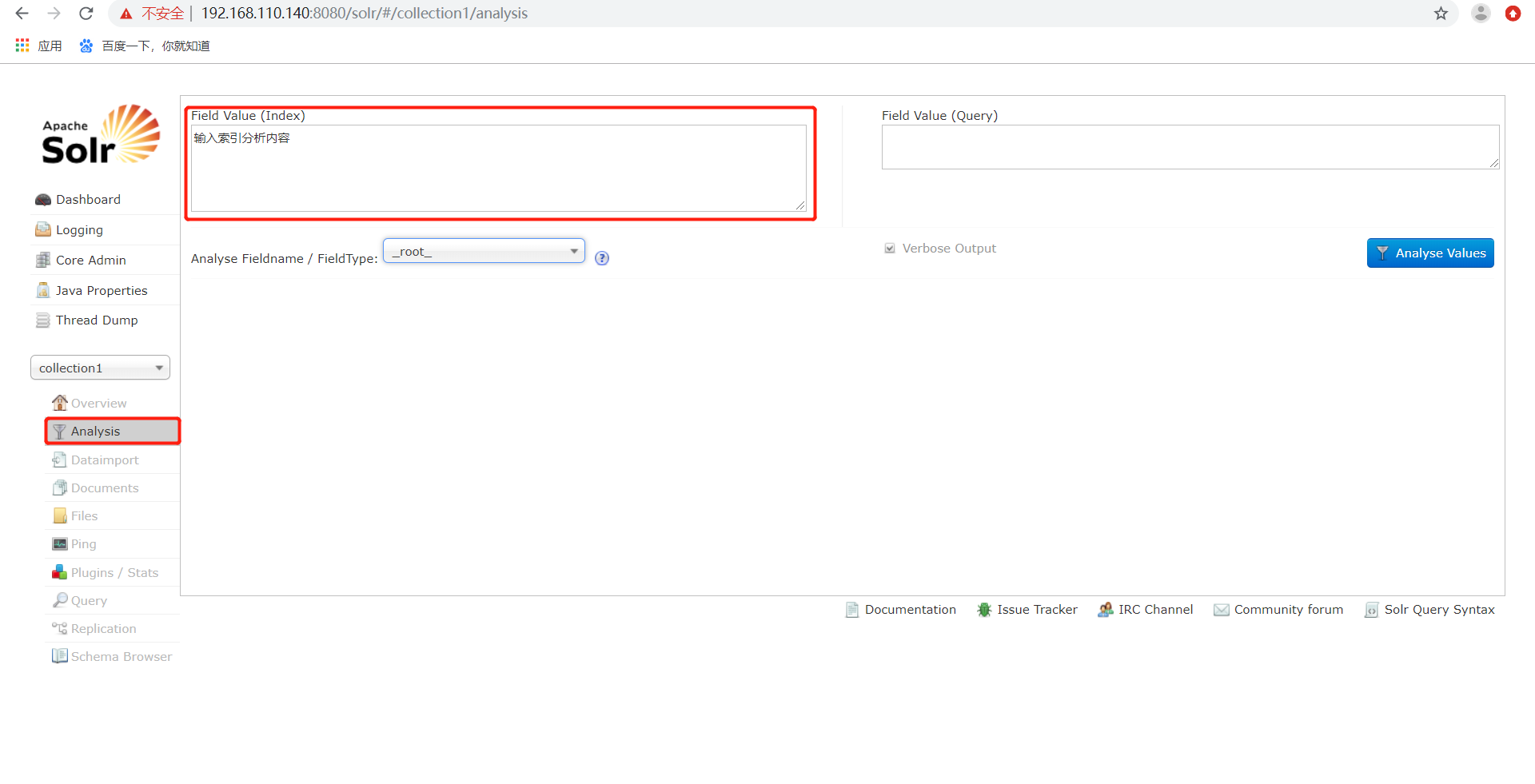
Dataimport可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
Document通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
注意:/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
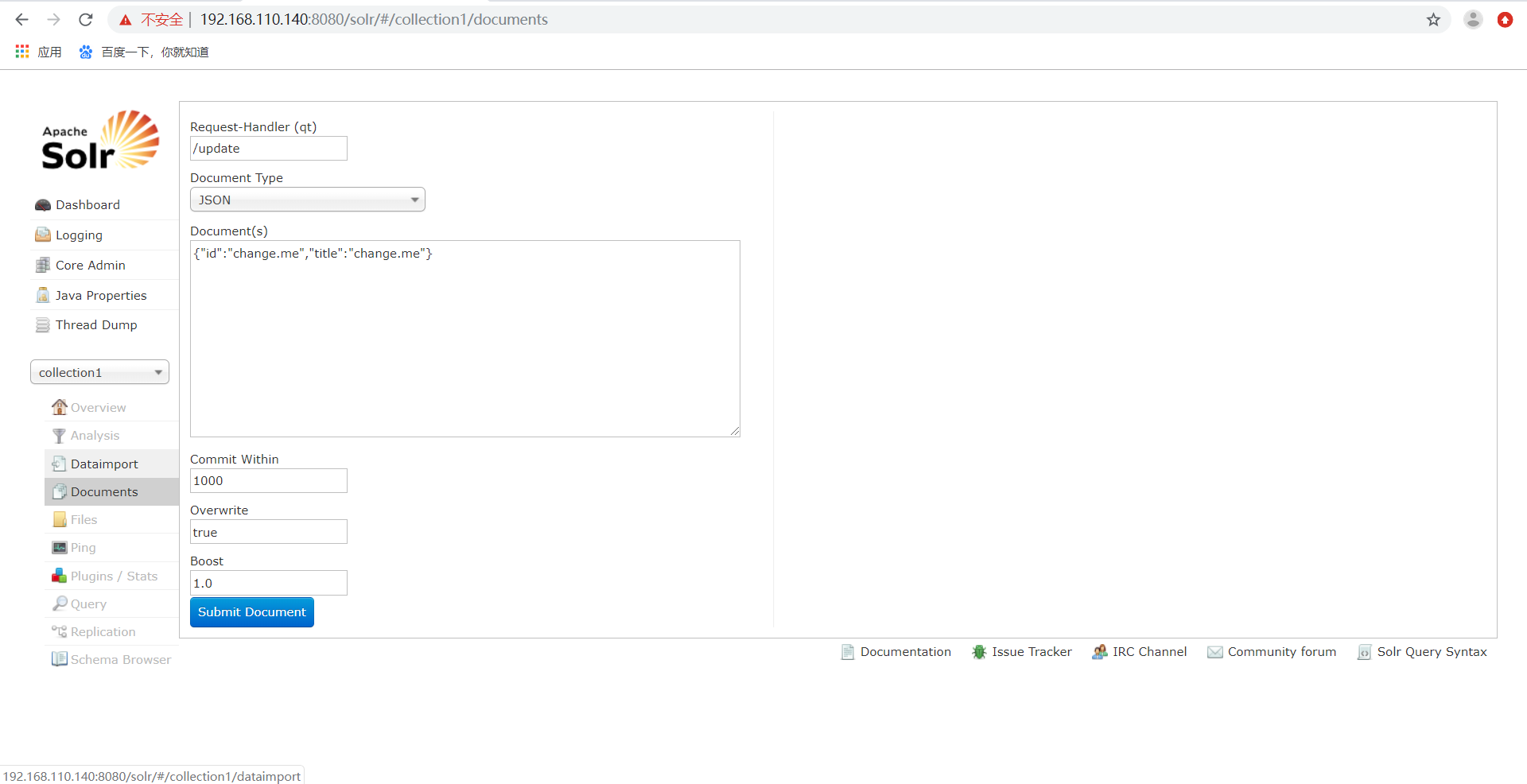
索引维护,使用/update进行索引维护,进入Solr管理界面SolrCore下的Document下,可以使用xml或者json格式进行维护的。
overwrite="true",solr在做索引的时候,如果文档已经存在,就用xml中的文档进行替换。
commitWithin="1000",solr在做索引的时候,每个1000(1秒)毫秒,做一次文档提交。
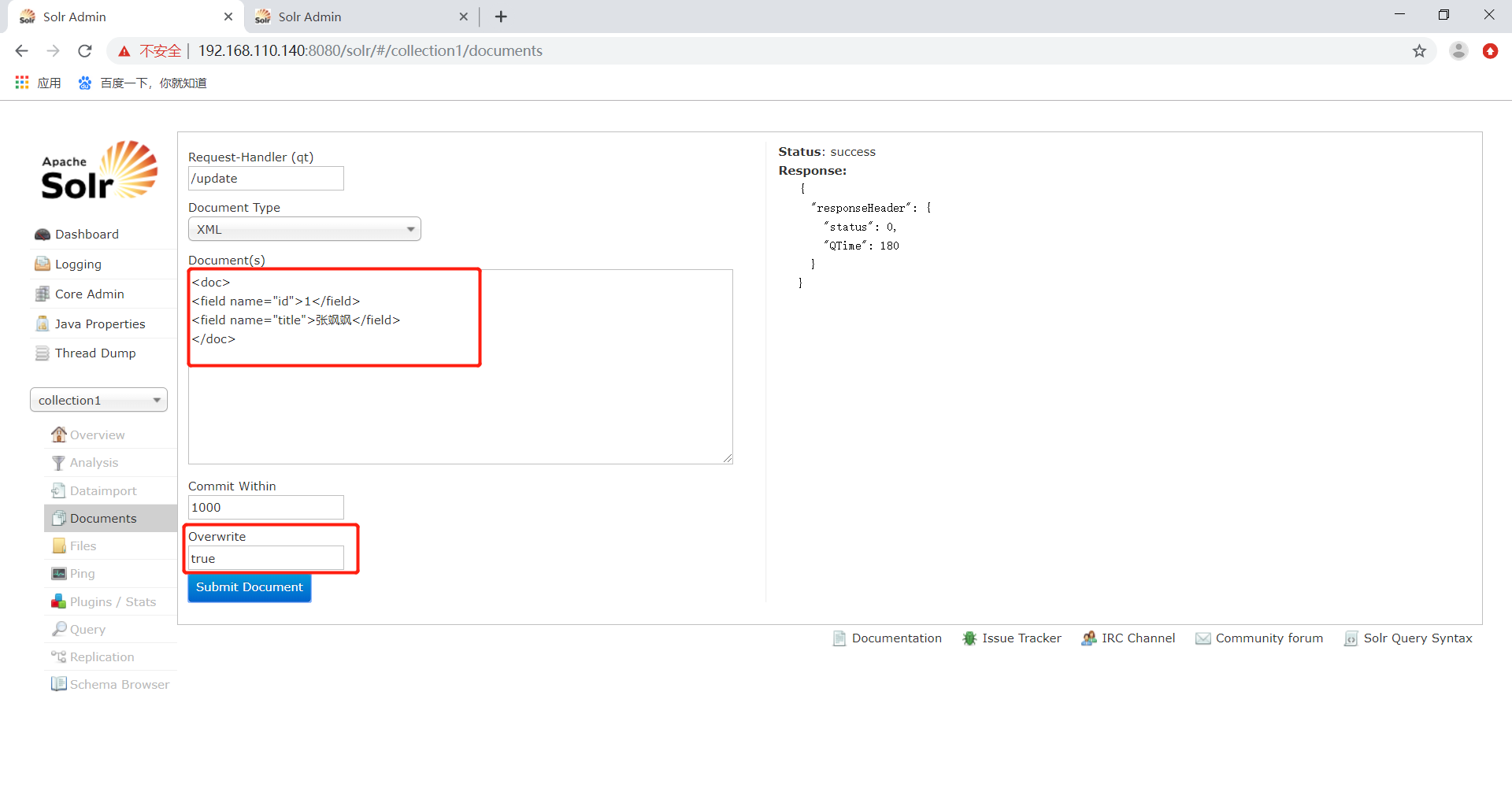
为了方便测试也可以在Document中立即提交,在</add>后边添加<commit/>。
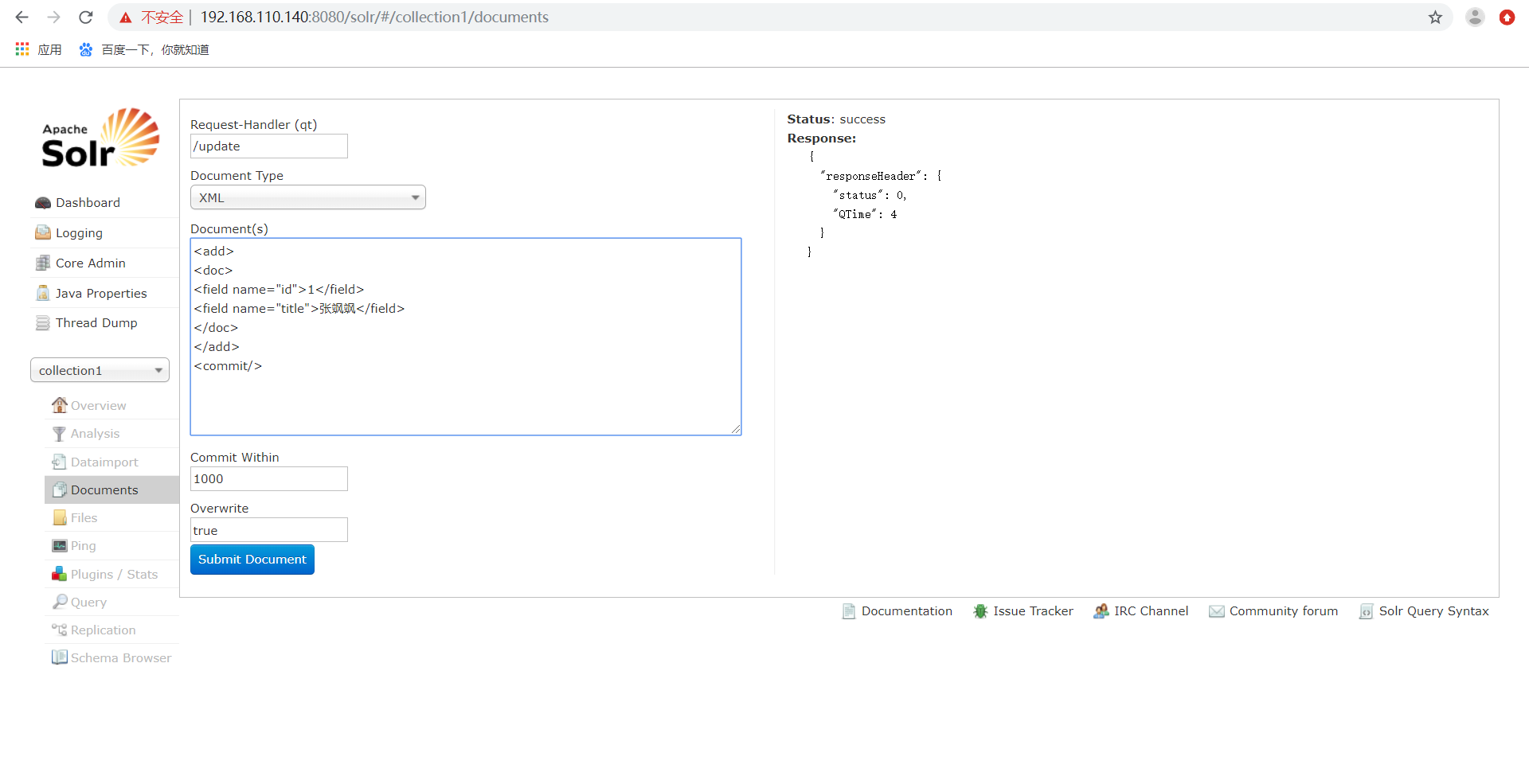
添加/更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。 说明:唯一标识 Field必须有,这里使用Solr默认的id。
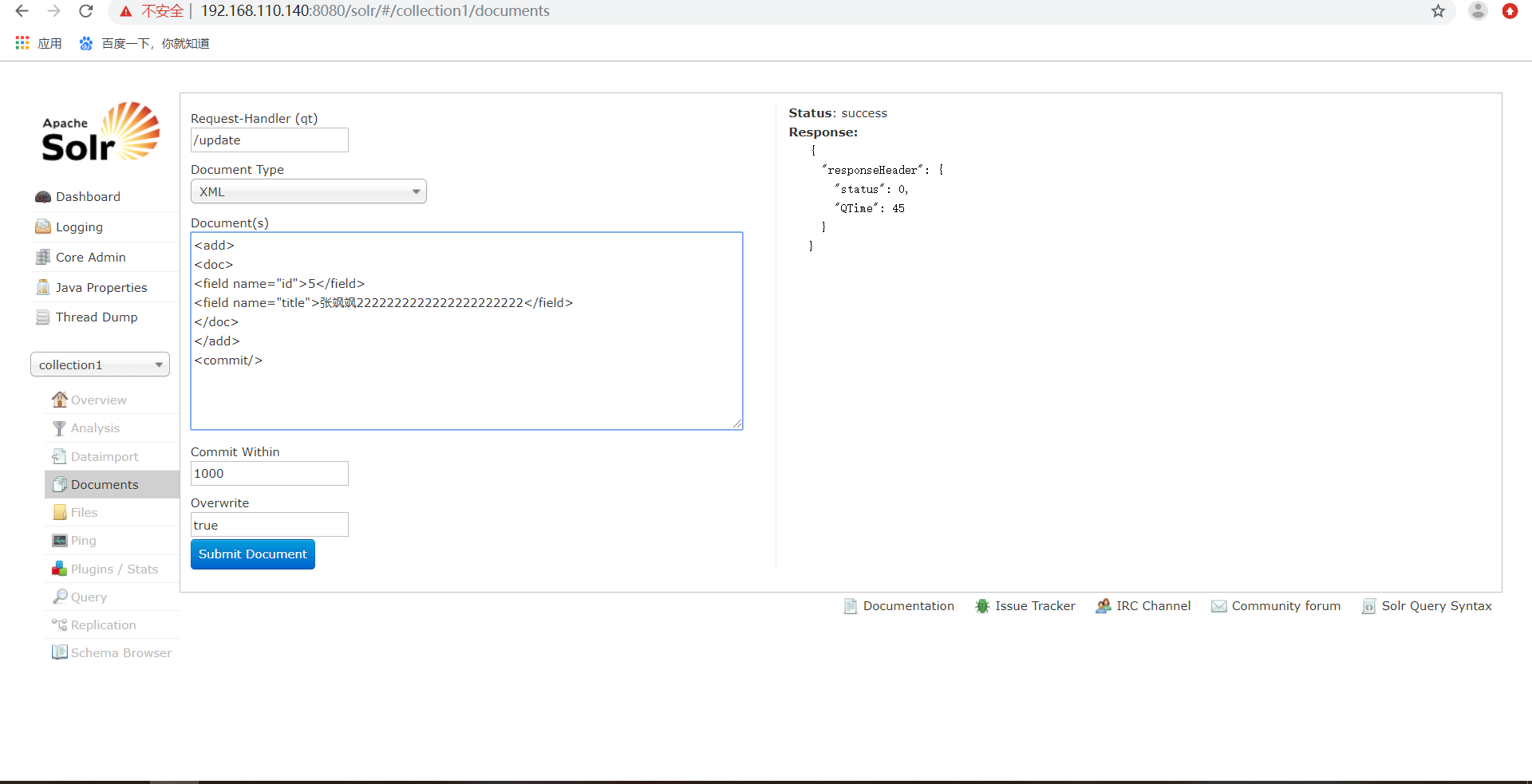
删除索引,删除制定ID的索引,索引格式如下:
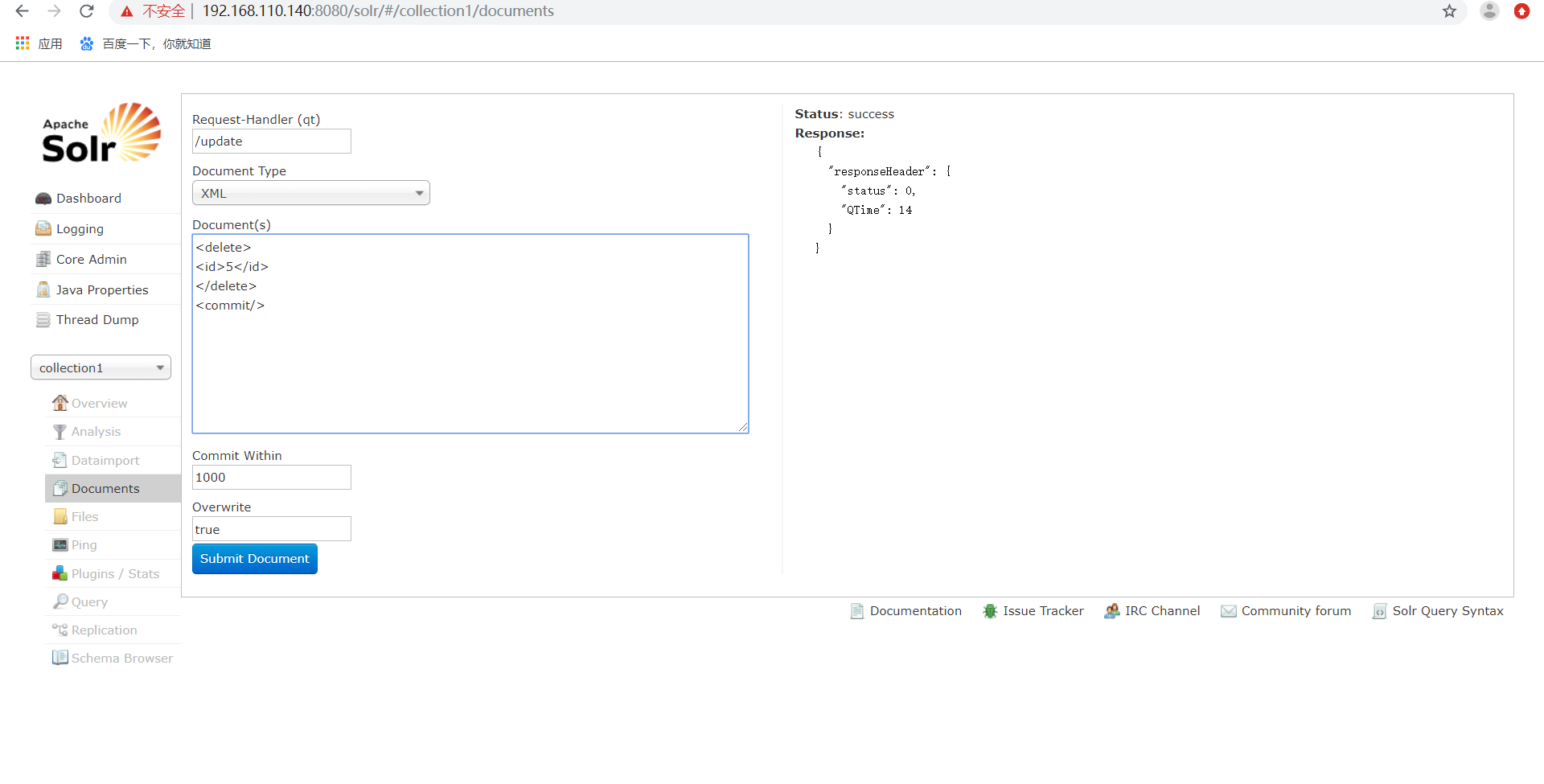
删除索引,删除查询到的索引数据,索引格式如下:
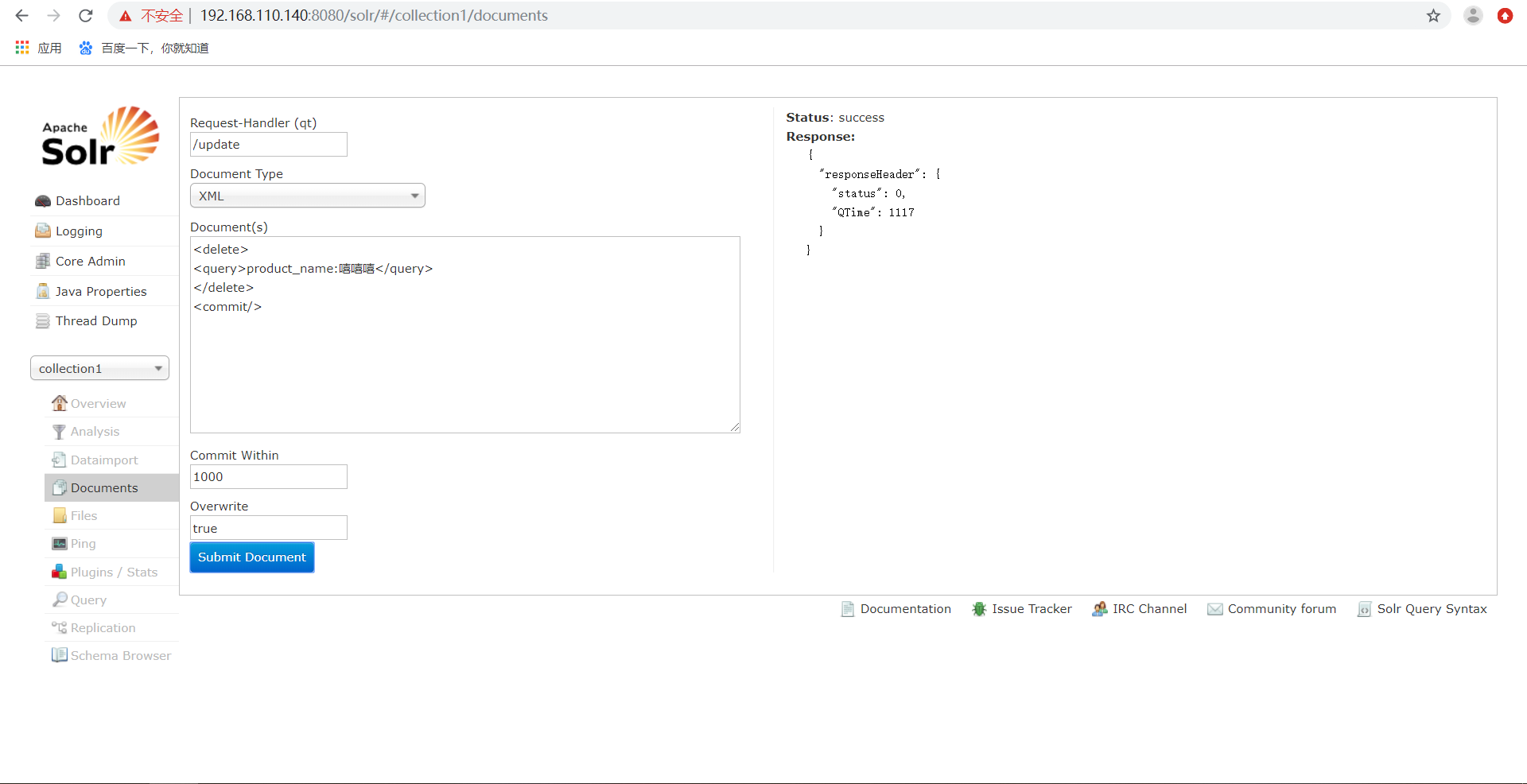
删除索引,删除所有索引数据,索引格式如下:
Query通过/select执行搜索索引,必须指定“q”查询条件方可搜索。
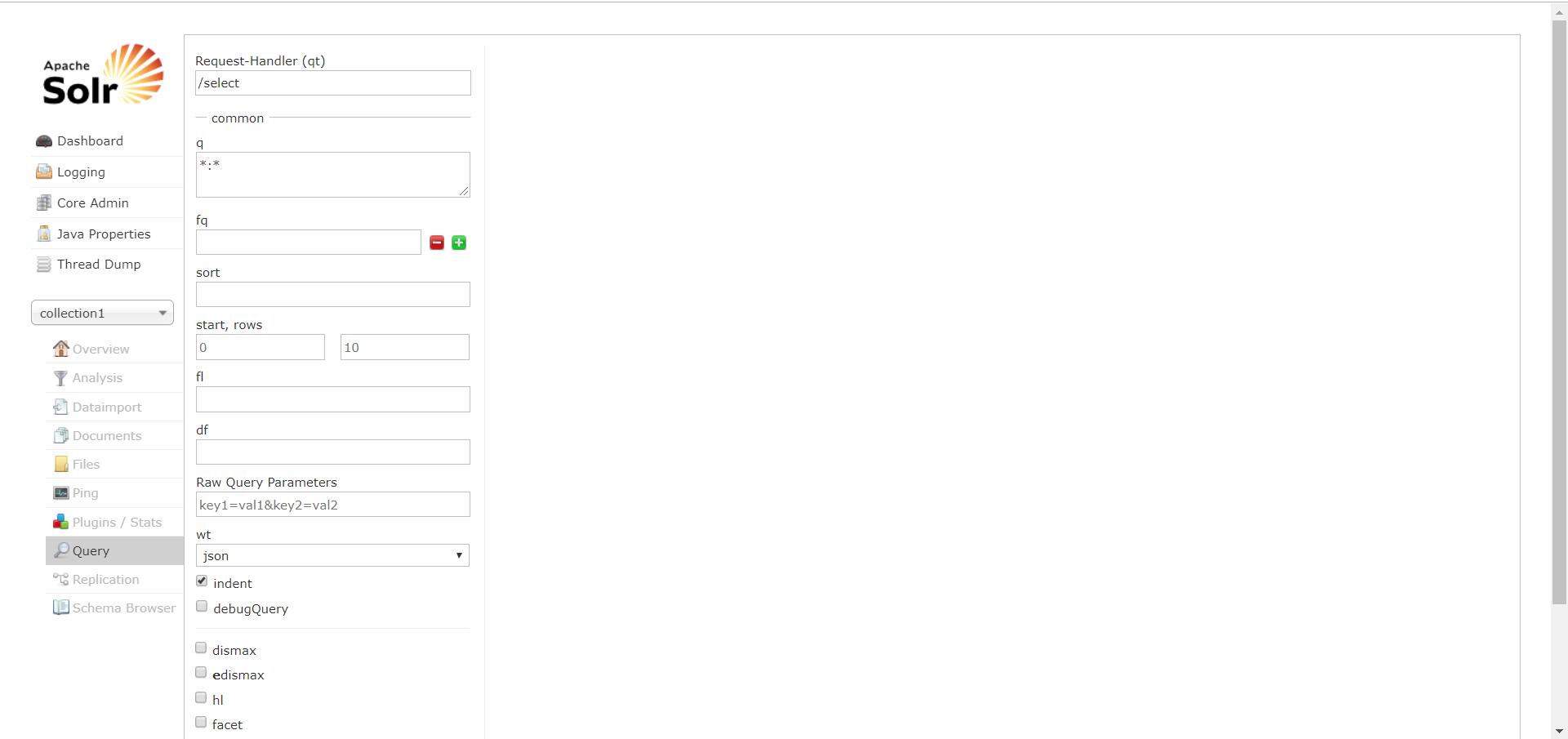
6、Solr实例Solr Core(即collection1)提供web界面菜单栏都是什么呢?
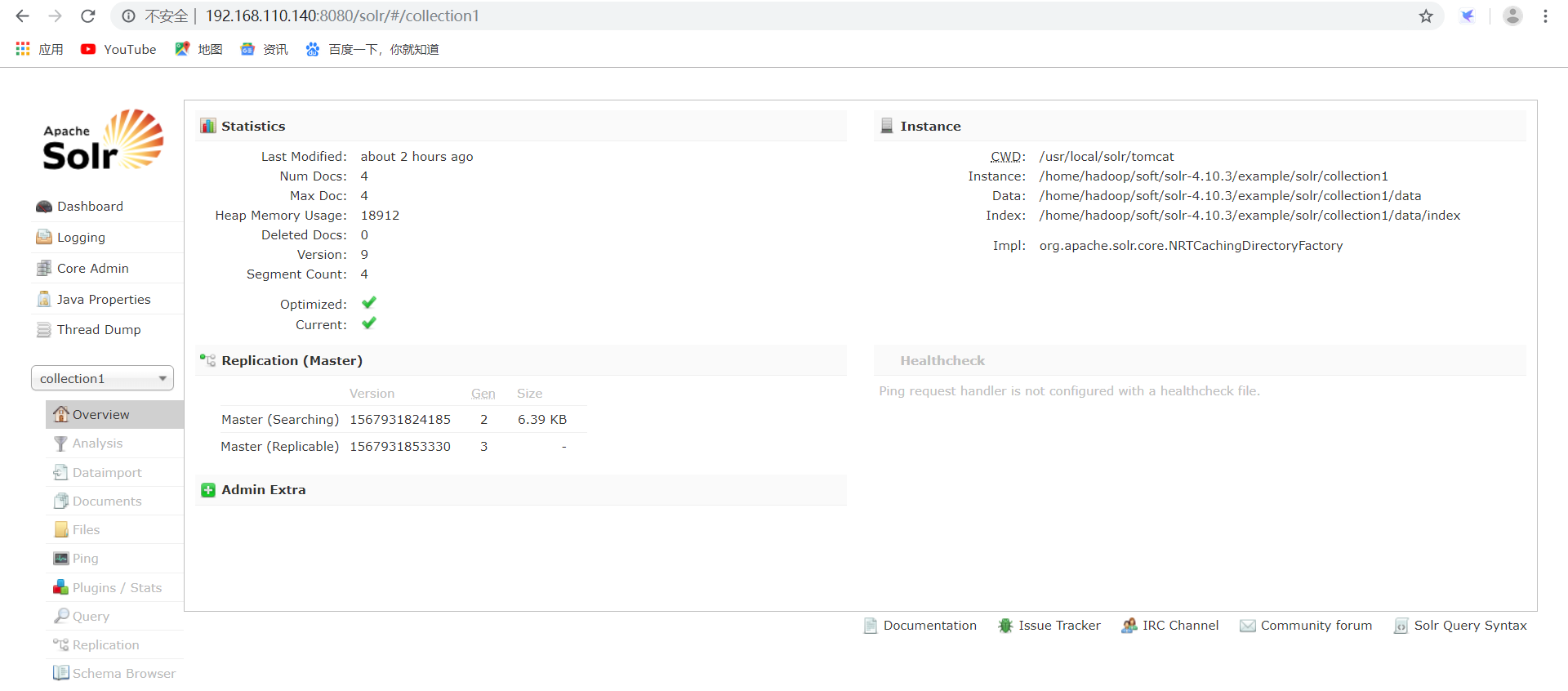
详细介绍如下所示:
a、Analysis:
通过此界面可以测试索引分析器和搜索分析器的执行情况。 b、dataimport:
可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。 c、Document:
通过此菜单可以创建索引、更新索引、删除索引等操作。
/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。 d、query:
通过/select执行搜索索引,必须指定"q"查询条件方可搜索。"sort"是排序,可选值desc和asc。"start", "rows"是分页的开始和每页多少条数。"hl"是指某个字段高亮。"df"是指需要指定默认字段。
7、Solr全文检索,如何支持中文分词?如何添加中文分词器?
答:需要使用IK中文分词器。
注意:ext_stopword.dic 和mydict.dic必须保存成无BOM的utf-8类型。
添加中文分词器的时候,首先将你的tomcat停止了,然后开始添加IK中文分词器。将IK Analyzer 2012FF_hf1.zip解压缩以后拷贝到tomcat的solr应用服务下面。
# 将IKAnalyzer2012FF_u1.jartomcat的solr应用服务下面/usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/。
[root@localhost package]# ls
apache-tomcat-7.0..tar.gz IK Analyzer 2012FF_hf1 jdk-7u55-linux-i586.tar.gz redis-3.0..gem redis-3.0..tar.gz solr-4.10..tgz.tar zookeeper-3.4..tar.gz
[root@localhost package]# cd IK\ Analyzer\ 2012FF_hf1/
[root@localhost IK Analyzer 2012FF_hf1]# ls
doc IKAnalyzer2012FF_u1.jar IKAnalyzer.cfg.xml IKAnalyzer???ķִ???V2012_FFʹ???ֲ?.pdf LICENSE.txt NOTICE.txt stopword.dic
[root@localhost IK Analyzer 2012FF_hf1]# cp IKAnalyzer2012FF_u1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
[root@localhost IK Analyzer 2012FF_hf1]# ll /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar
-rw-r--r--. root root Sep : /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar
[root@localhost IK Analyzer 2012FF_hf1]# # 在/usr/local/solr/tomcat/webapps/solr/WEB-INF/下面创建clesses文件夹。将IKAnalyzer.cfg.xml、stopword.dic(禁止对文件里面的词进行分词操作)两个配置文件拷贝到这里面即可。
[root@localhost WEB-INF]# ls
lib weblogic.xml web.xml
[root@localhost WEB-INF]# mkdir classes
[root@localhost WEB-INF]# cp /home/hadoop/package/IK\ Analyzer\ 2012FF_hf1/IKAnalyzer.cfg.xml /home/hadoop/package/IK\ Analyzer\ 2012FF_hf1/stopword.dic ./classes/
[root@localhost WEB-INF]# ll ./classes/
total
-rw-r--r--. root root Sep : IKAnalyzer.cfg.xml
-rw-r--r--. root root Sep : stopword.dic
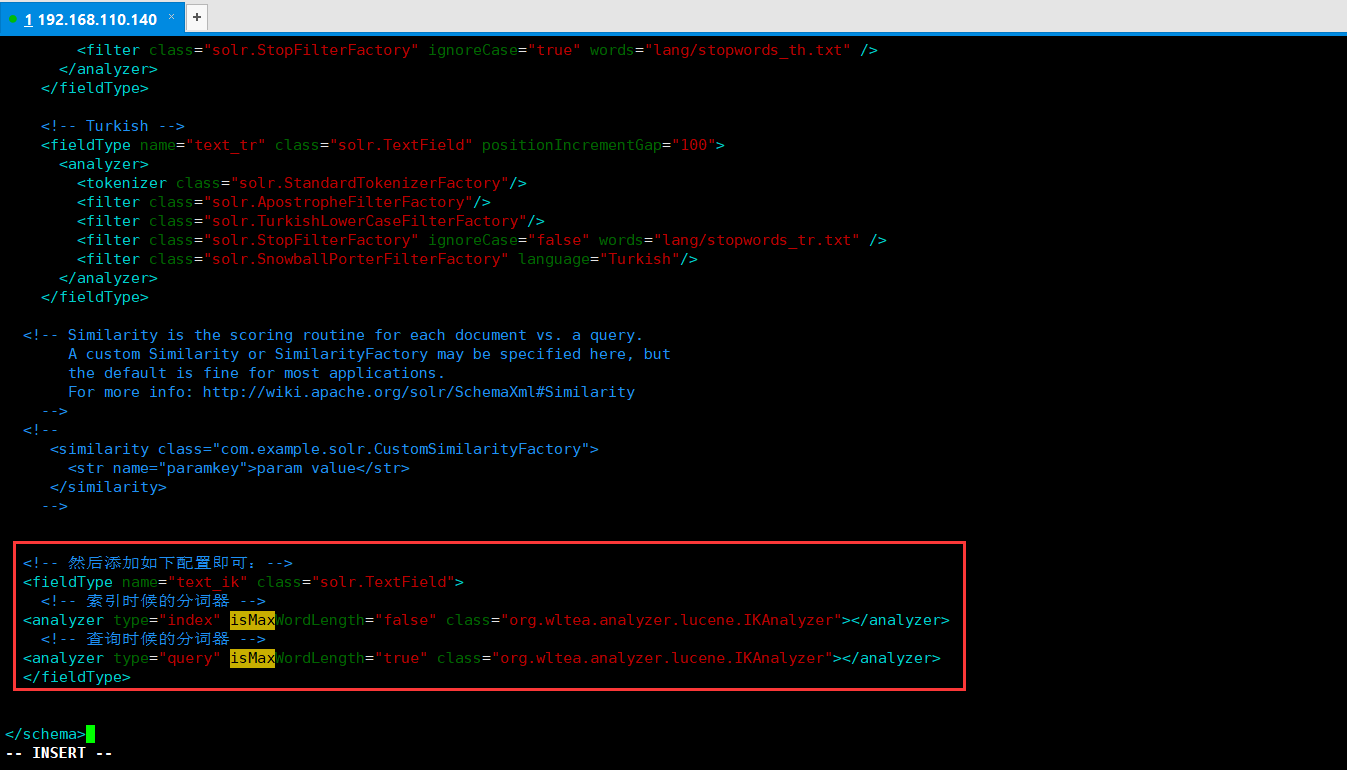
[root@localhost WEB-INF]# # 然后修改solr core的schema.xml文件,默认位置是:/home/hadoop/soft/solr-4.10./example/solr/collection1/conf/schema.xml
[root@localhost WEB-INF]# vim /home/hadoop/soft/solr-4.10./example/solr/collection1/conf/schema.xml # 然后添加如下配置即可:
<fieldType name="text_ik" class="solr.TextField">
<!-- 索引时候的分词器 -->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"></analyzer>
<!-- 查询时候的分词器 -->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"></analyzer>
</fieldType>
如下图所示:
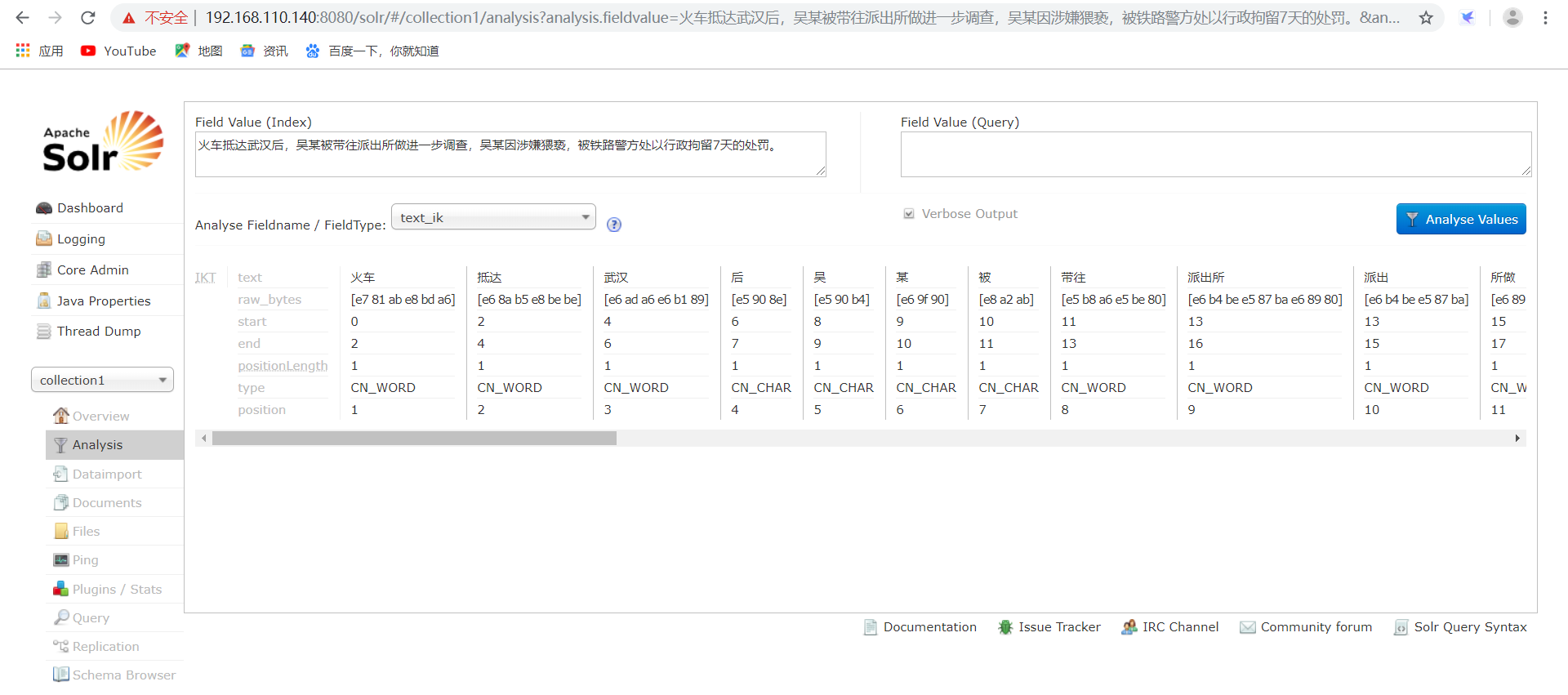
然后启动tomcat去solr的页面Analysis即可查看到自己加IK中文分词器。效果如下所示:
8、如果想自定义一些词库如何操作?
答:如果我们想自定义一些词库,让IK分词器可以识别,那么就需要自定义扩展词库了。操作步骤如下所示:
修改IKAnalyzer.cfg.xml配置文件,将注释ext.dic打开。切记,这个ext.dic可以随意,但是必须对应你创建的文件的名称。
[root@localhost ~]# ls
anaconda-ks.cfg Desktop Documents Downloads install.log install.log.syslog Music Pictures Public Templates Videos
[root@localhost ~]# cd /usr/local/solr/tomcat/webapps/solr/WEB-INF/classes/
[root@localhost classes]# ls
IKAnalyzer.cfg.xml stopword.dic
[root@localhost classes]# vim IKAnalyzer.cfg.xml # 修改内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties> # 在/usr/local/solr/tomcat/webapps/solr/WEB-INF/classes下面创建ext.dic文件。
[root@localhost classes]# ls
IKAnalyzer.cfg.xml stopword.dic
[root@localhost classes]# vim ext.dic
[root@localhost classes]# vim ext.dic
[root@localhost classes]#
操作如下所示:

自定义分词如下所示:
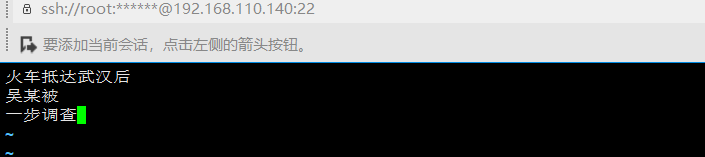
启动你的tomcat,然后重新查询一下,看看效果如何:
9、scheam.xml文件中属性的解释和说明?
答:位置如是/home/hadoop/soft/solr-4.10.3/example/solr/collection1/conf/scheam.xml,schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
、FieldType域类型定义:
FieldType子结点包括:name,class,positionIncrementGap等一些参数: name:是这个FieldType的名称。 class:是Solr提供的包solr.TextField,solr.TextField。允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)。和多个过滤器(filter)。 positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。 在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤。 索引分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilte rFactory停用词过滤器,solr.LowerCaseFilterFactory小写过滤器。 搜索分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilte rFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。 、Field定义。
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
如下:
<field name="name" type="text_general" indexed="true" stored="true"/> <field name="features" type="text_general" indexed="true" stored="true" multiValued="true"/>
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组。 、uniqueKey
Solr中默认定义唯一主键key为id域,如下:
<uniqueKey>id</uniqueKey>
Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。 、copyField复制域
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:
比如,输入关键字搜索title标题内容content,定义title、content、text的域:
<field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="content" type="text_general" indexed="false" stored="true" multiValued="true"/>
<field name="text" type="text_general" indexed="true" stored="true" multiValued="true"/>
根据关键字只搜索text域的内容就相当于搜索title和content,将title和content复制到text中,如下:
<copyField source="title" dest="text"/>
<copyField source="author" dest="text"/>
<copyField source="description" dest="text"/>
<copyField source="keywords" dest="text"/>
<copyField source="content" dest="text"/> 、dynamicField(动态字段)。
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
自定义Field名为:product_title_t,"product_title_t"和scheam.xml中的dynami cField规则匹配成功,如下:
<dynamicField name="*_t" type="text_general" indexed="true" stored="true"/>
"product_title_t"是以"_t"结尾。
10、如何根据需求配置自定义域。
FieldType首先需要在types结点内定义一个FieldType子结点,包括name,class,等参数,name就是这个FieldType的名称,class指向org.apache.solr.analysis包里面对应的class名称,用来定义这个类型的行为。在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤。修改Solr的schema.xml文件,添加FieldType:
# 前提:请提前配置好你的IK域类型。如下所示:修改Solr的schema.xml文件,添加FieldType:
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
FieldType定义好后就可以在fields结点内定义具体的field,filed定义包括name,type(即FieldType),indexed(是否被索引),stored(是否被储存),multi Valued(是否有多个值)等。
# 根据需求配置自定义域。如果不使用Solr提供的Field可以针对具体的业务需要自定义一套Field。
<!--IKAnalyzer Field-->
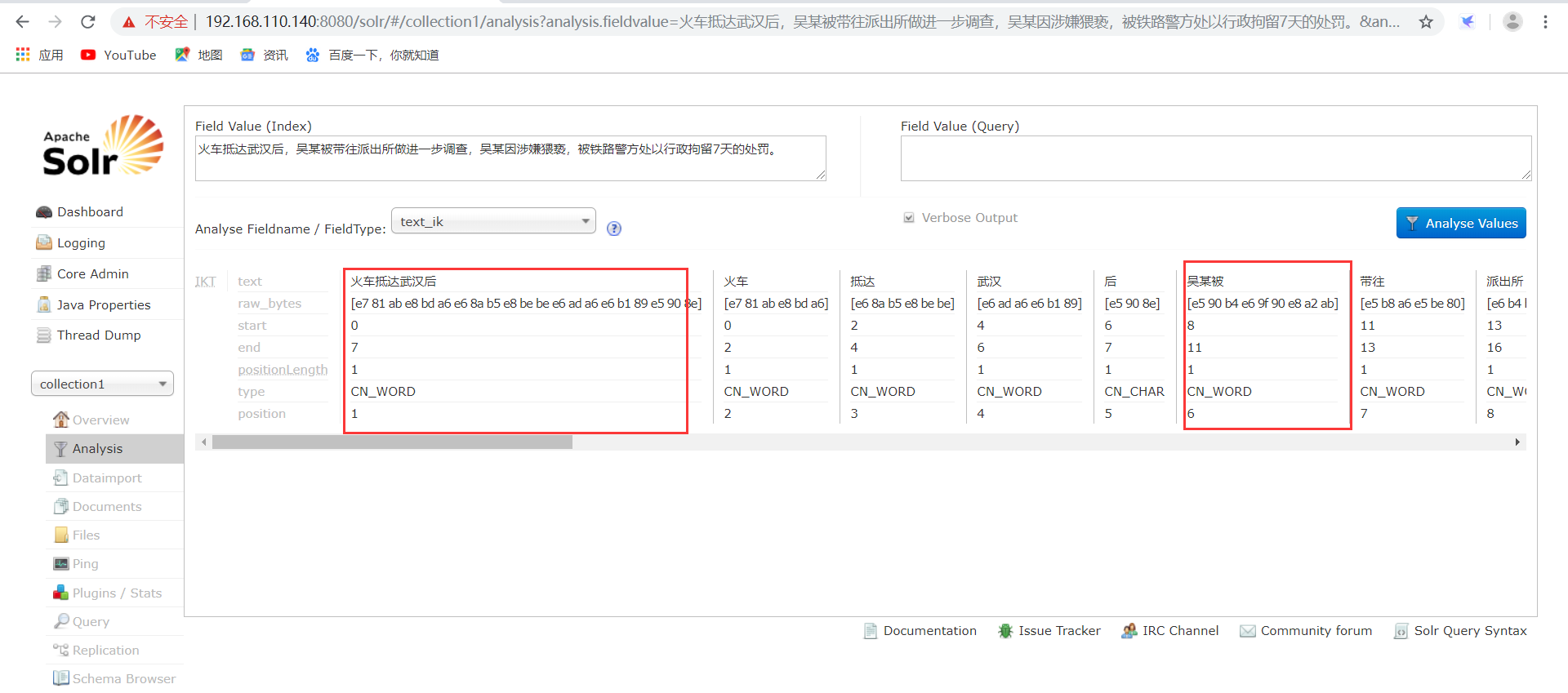
<field name="product_name" type="text_ik" indexed="true" stored="true" />
操作如下所示:
查询操作是否成功咯:

11、如何进行索引维护?
、使用/update进行索引维护,进入Solr管理界面SolrCore下的Document下:
overwrite="true"的时候,solr在做索引的时候,如果文档已经存在,就用xml中的文档进行替换。
commitWithin=""的时候,solr在做索引的时候,每个10000(10秒)毫秒,做一次文档提交。
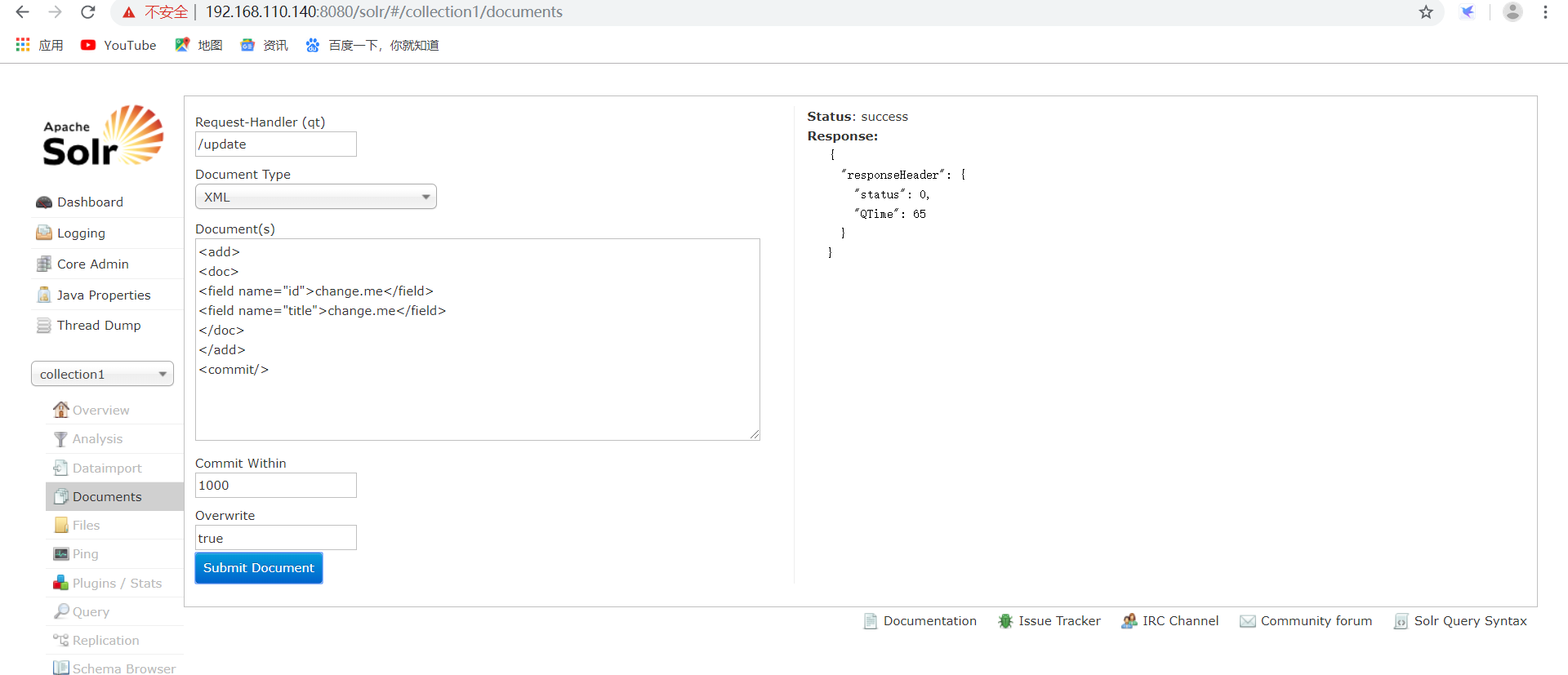
为了方便测试也可以在Document中立即提交,在</add>后边添加“<commit/>”,如下:
<add>
<doc>
<field name="id">change.me</field>
<field name="title">change.me</field>
</doc>
</add>
<commit/>
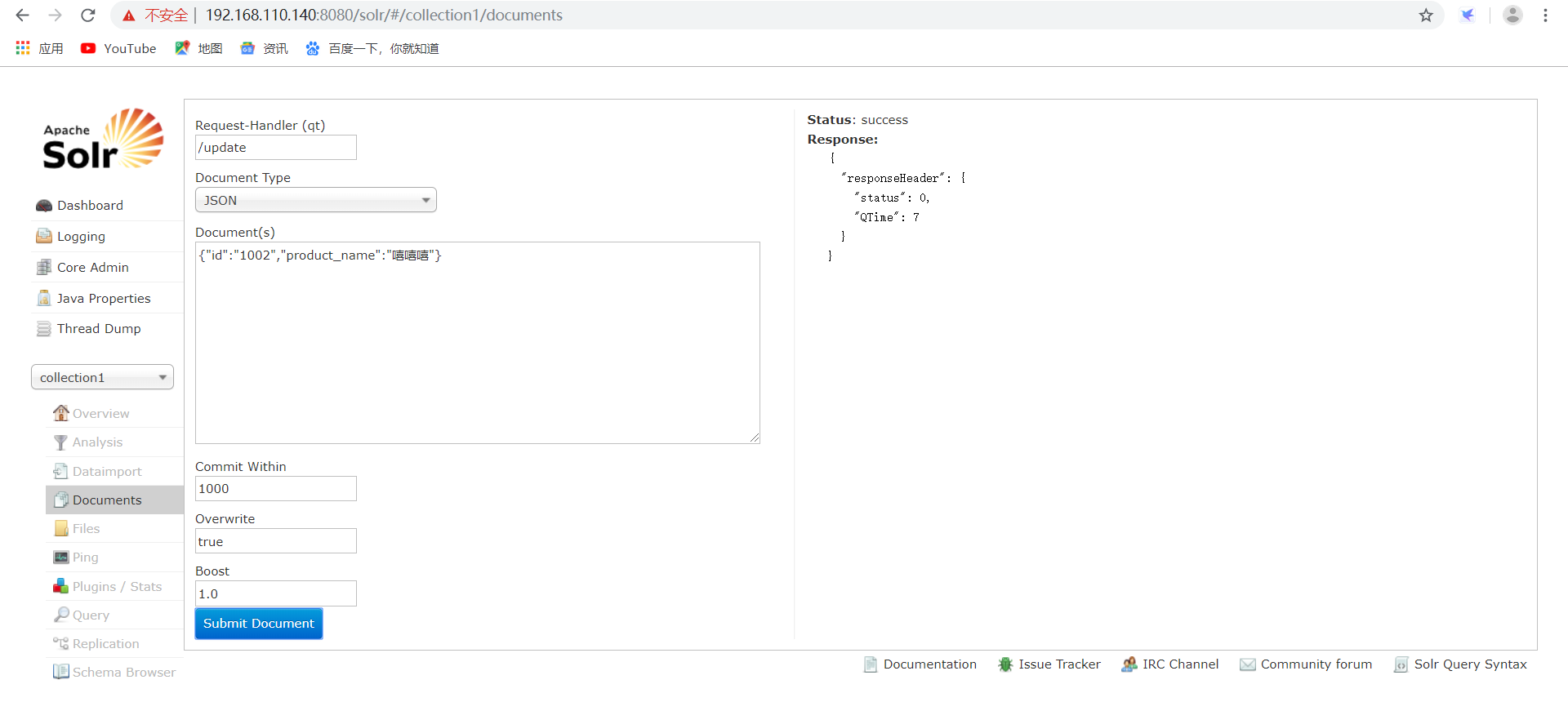
、添加/更新索引。
solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
Solr 全文检索服务:
请求xml格式如下:
<add>
<doc>
<field name="id">change.me</field>
<field name="name" >change.me</field>
</doc>
</add>
说明:唯一标识 Field必须有,这里使用Solr默认的id。 、删除索引。
删除索引格式如下:
) 删除制定ID的索引
<delete>
<id></id>
</delete>
) 删除查询到的索引数据
<delete>
<query>product_catalog_name:哈哈哈</query> </delete>
) 删除所有索引数据
<delete>
<query>*:*</query>
</delete>
12、什么是SolrJ?
答:Solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务。
13、Solr的query查询语法。
通过/select搜索索引,Solr制定一些参数完成不同需求的搜索:
a、q代表查询字符串,必须的,如果查询所有使用*:*。
b、fq (filter query)代表过虑查询,作用:在q查询符合结果中同时是fq查询符合的。
例如:product_price:[ TO ]。
过滤查询价格从1到20的记录。也可以在"q"查询条件中使用product_price:[ TO ],如下:
也可以使用“*”表示无限,例如:
20以上:product_price:[ TO *]
20以下:product_price:[* TO ]
c、sort代表排序,格式:sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]… 。示例:product_price desc。按照价格降序。
d、start代表分页显示使用,开始记录下标,从0开始。rows代表指定返回结果最多有多少条记录,配合start来实现分页。
e、fl代表指定返回那些字段内容,用逗号或空格分隔多个。示例:product_picture,product_name,product_price。显示商品图片、商品名称、商品价格。
f、df代表指定一个搜索Field。也可以在SolrCore目录中conf/solrconfig.xml文件中指定默认搜索Field,指定后就可以直接在“q”查询条件中输入关键字。
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="rows"></str>
<!-- 注意:在使用SearchHandler中设置df -->
<str name="df">text</str>
</lst>
</requestHandler>
g、wt(writer type)代表指定输出格式,可以有 xml, json, php, phps, 后面 solr .3增加的,要用通知我们,因为默认没有打开。
h、hl代表是否高亮 ,设置高亮Field,设置格式前缀和后缀。
14、查询语法,通过/select搜索索引,Solr制定一些参数完成不同需求的搜索。
1)、q代表了查询字符串,必须的,如果查询所有使用*:*。
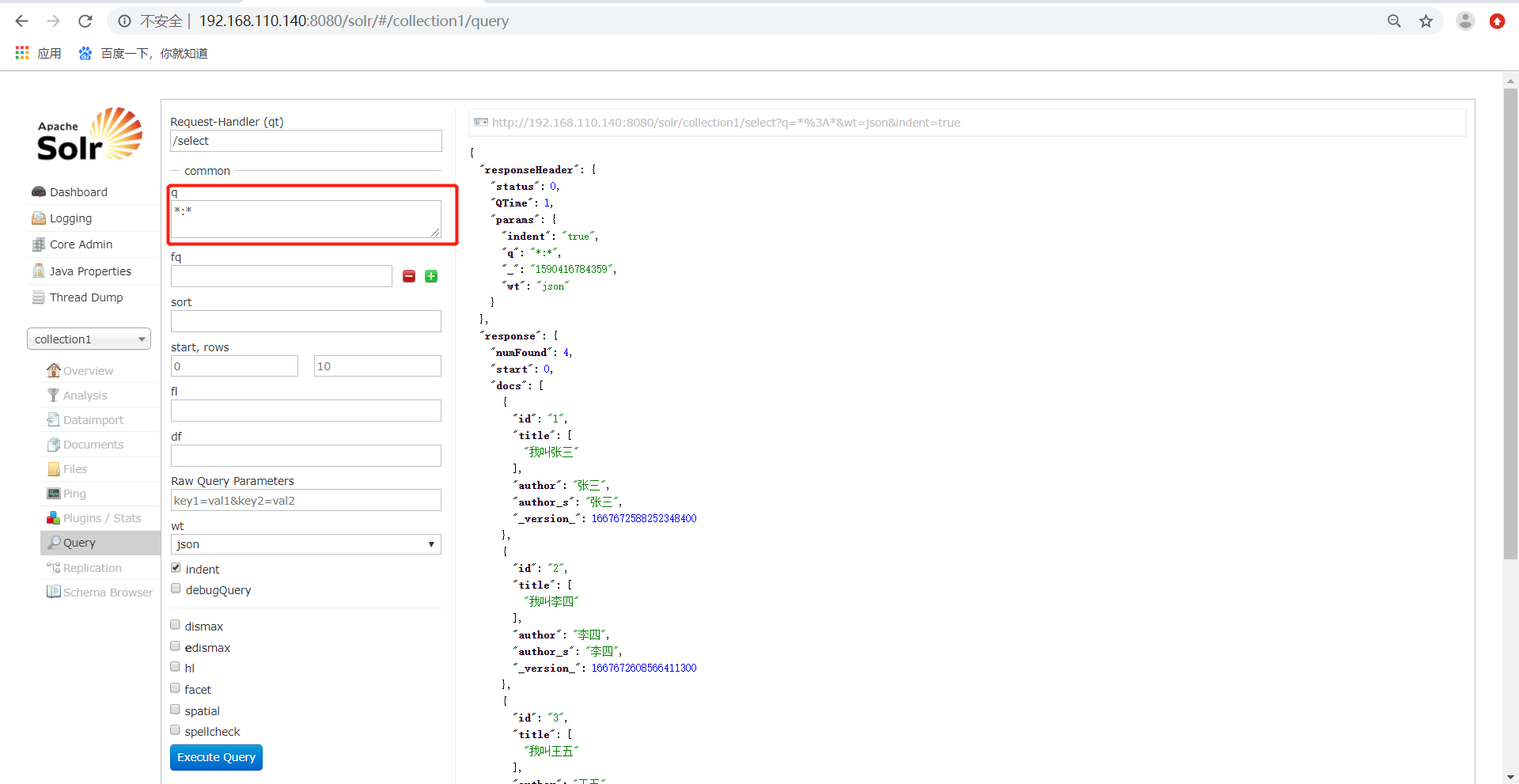
可以根据单条件进行查询,如下所示:
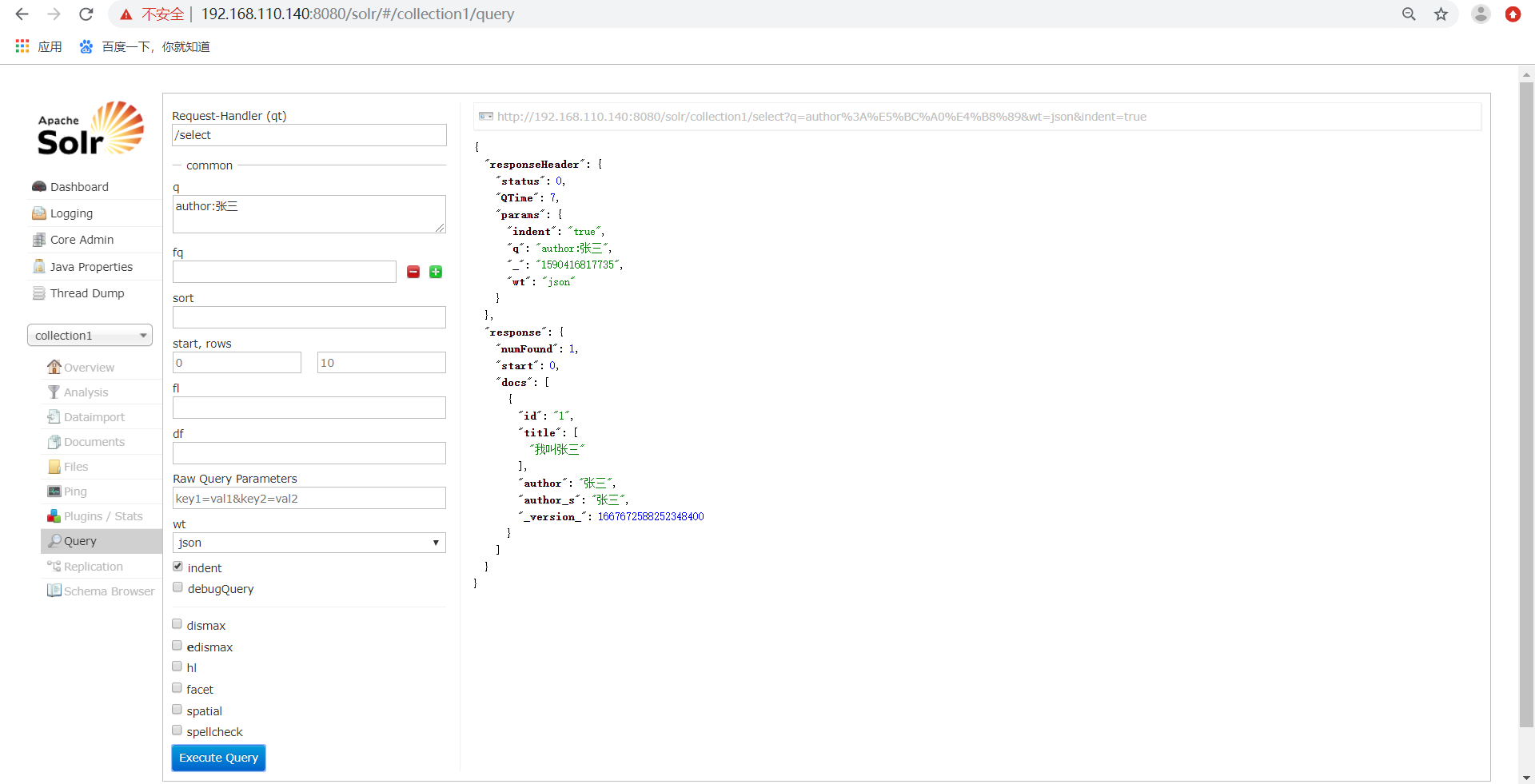
可以根据多条件进行查询,如下所示:
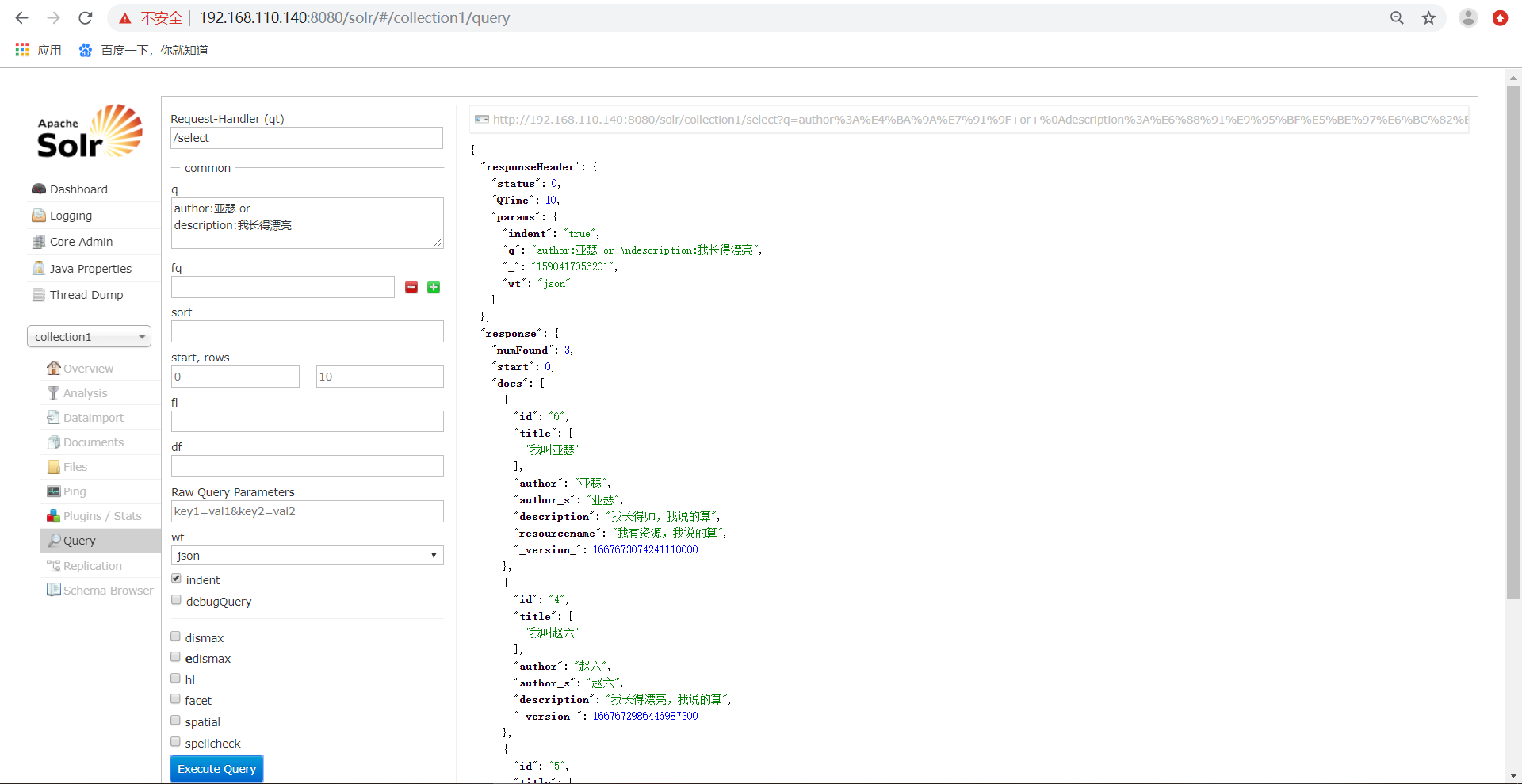
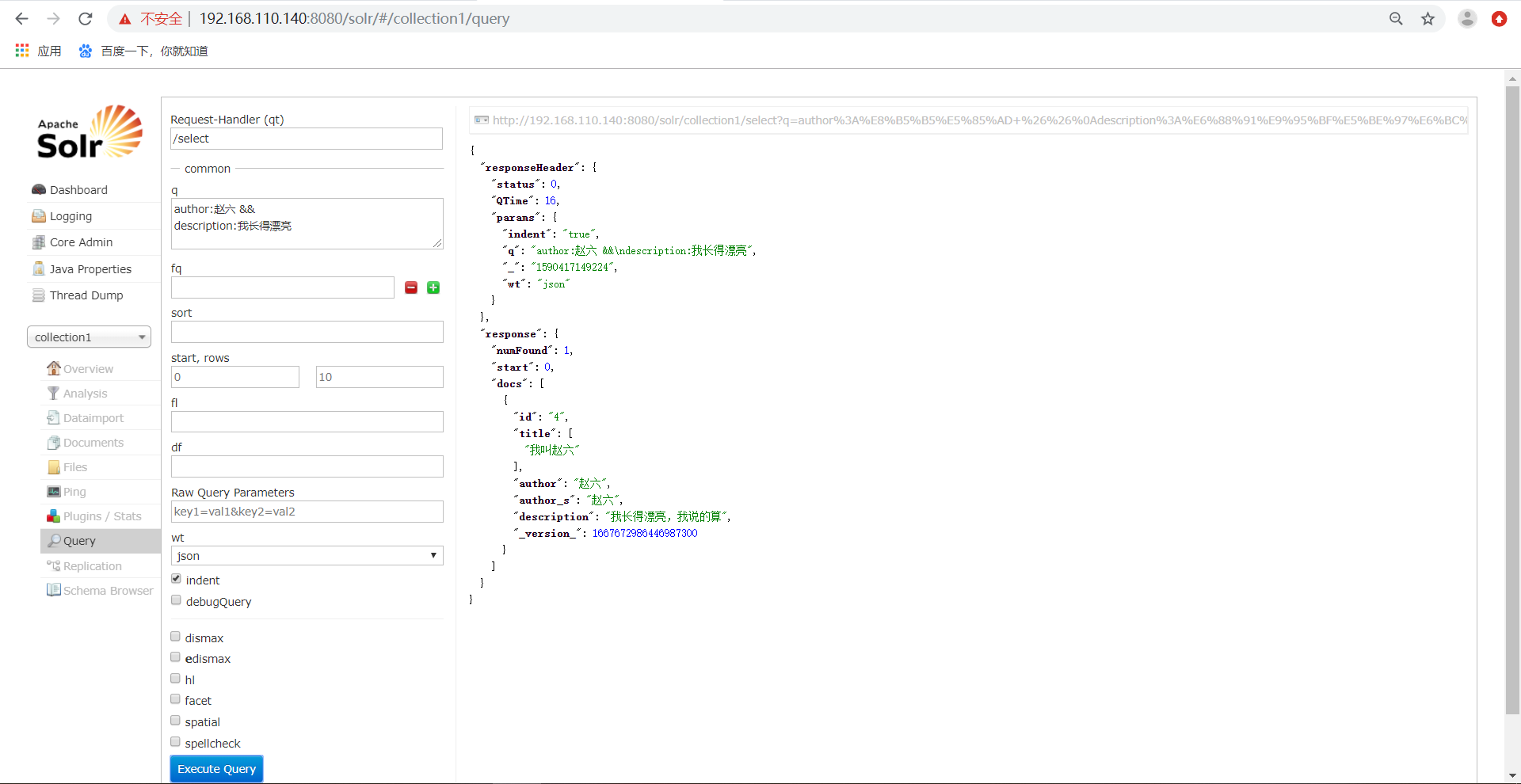
2)、fq代表了(filterquery)过虑查询,作用:在q查询符合结果中同时是fq查询符合的,例如:
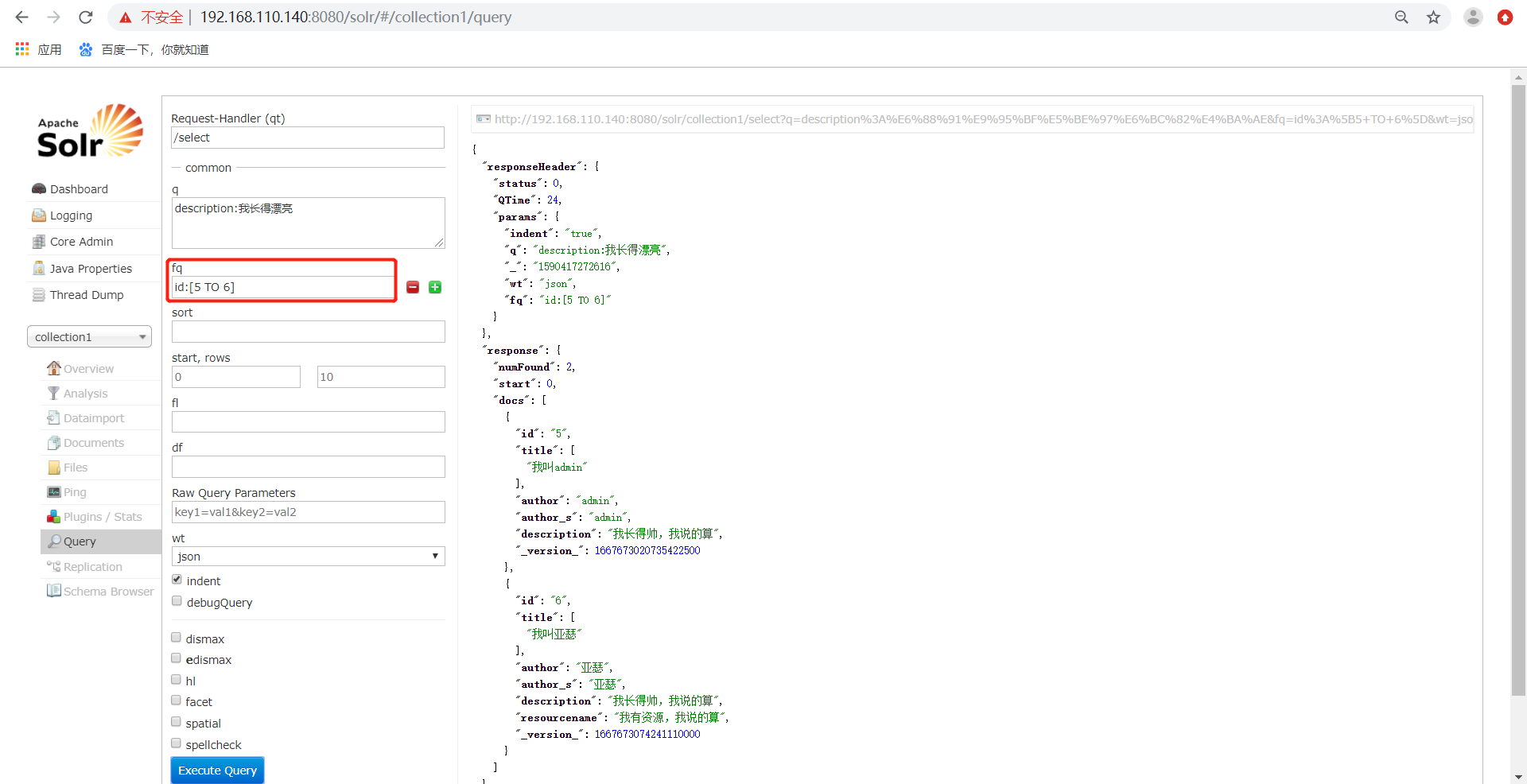
过滤查询价格从5到6的记录。也可以在q上面输入ID:[5 TO 6],如下:
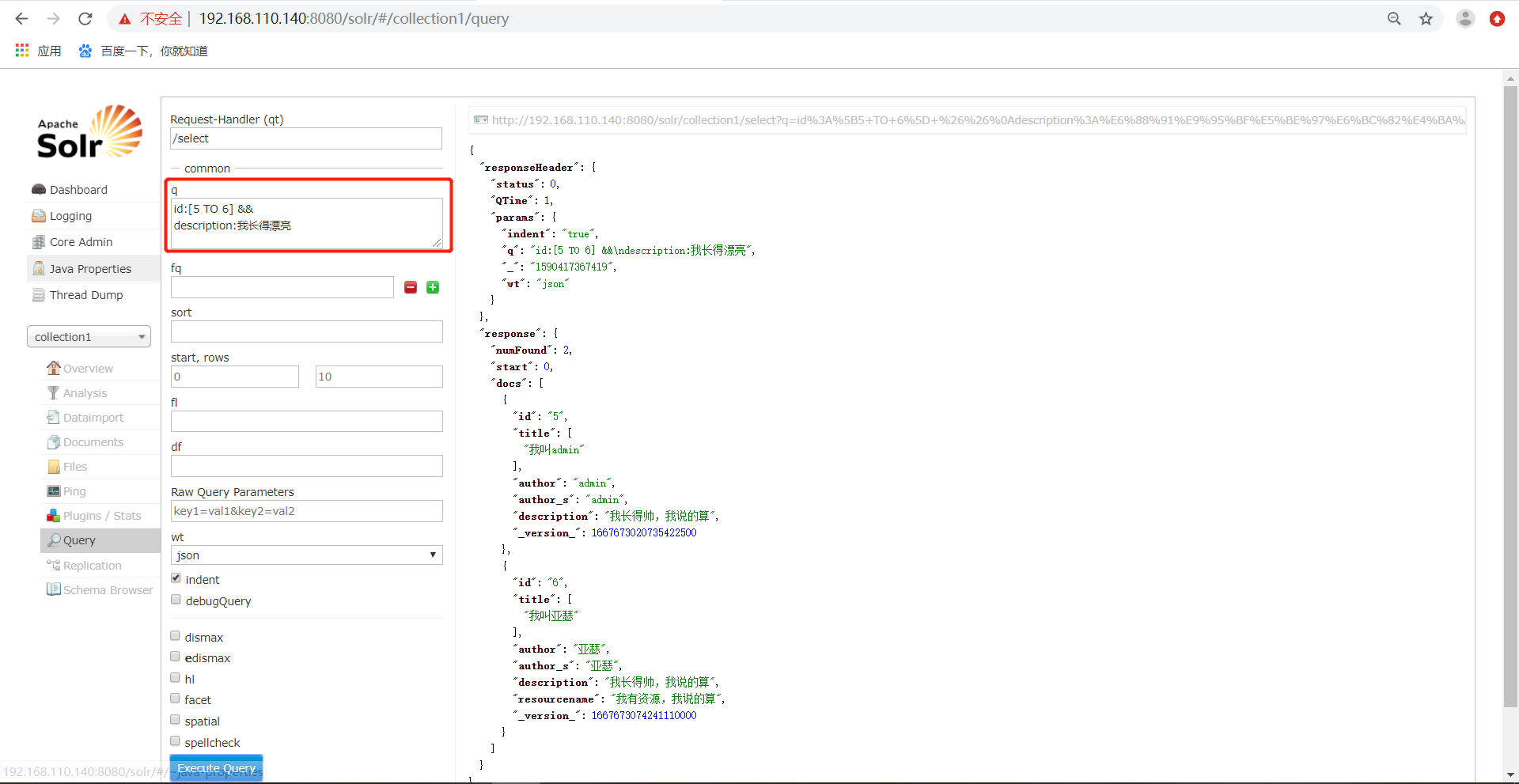
也可以使用"*"表示无限,例如,20以上:product_price:[20 TO *]、20以下:product_price:[* TO 20]。
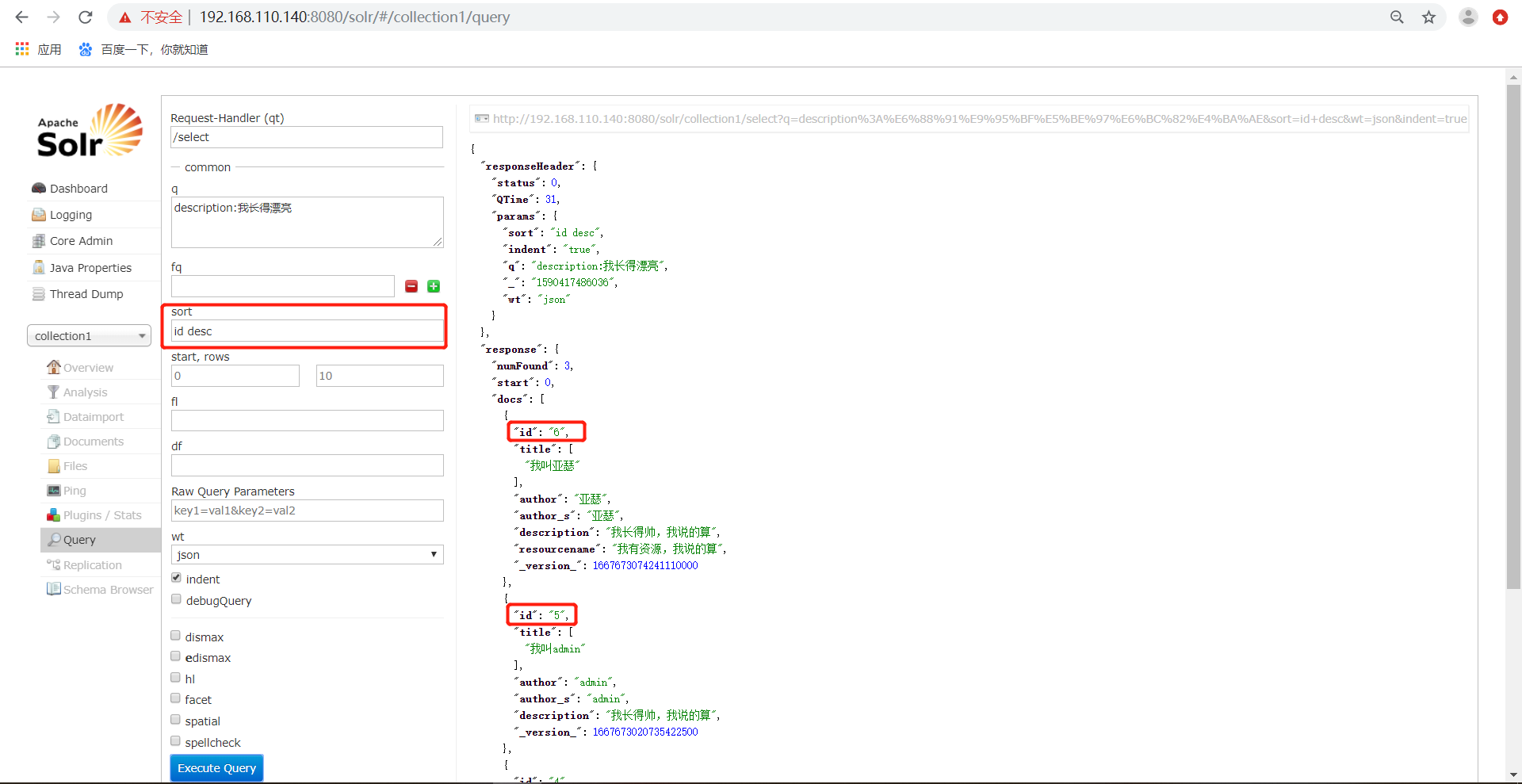
3)、sort代表了排序,格式为sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]… 。示例:
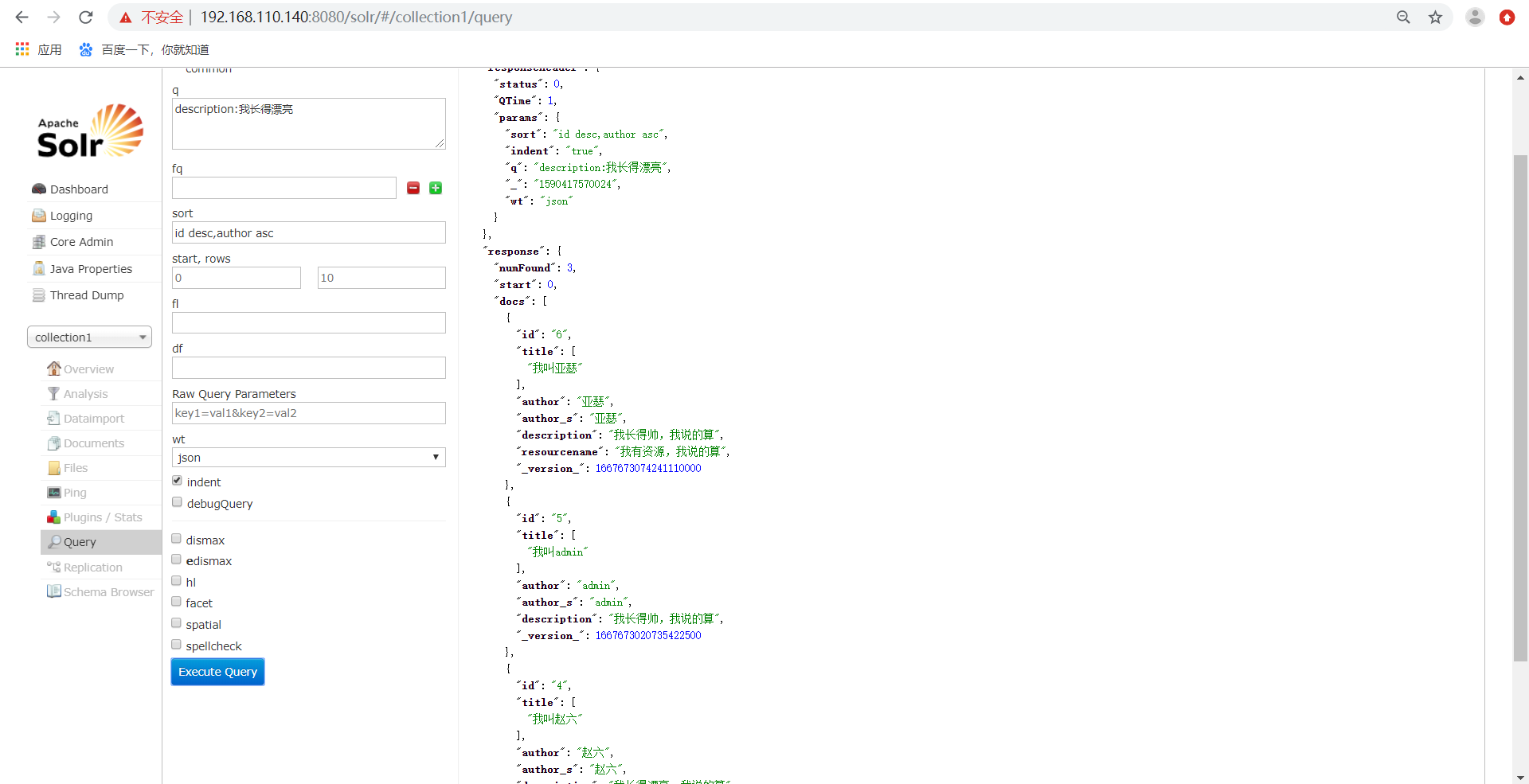
组合字段排序,如下所示:
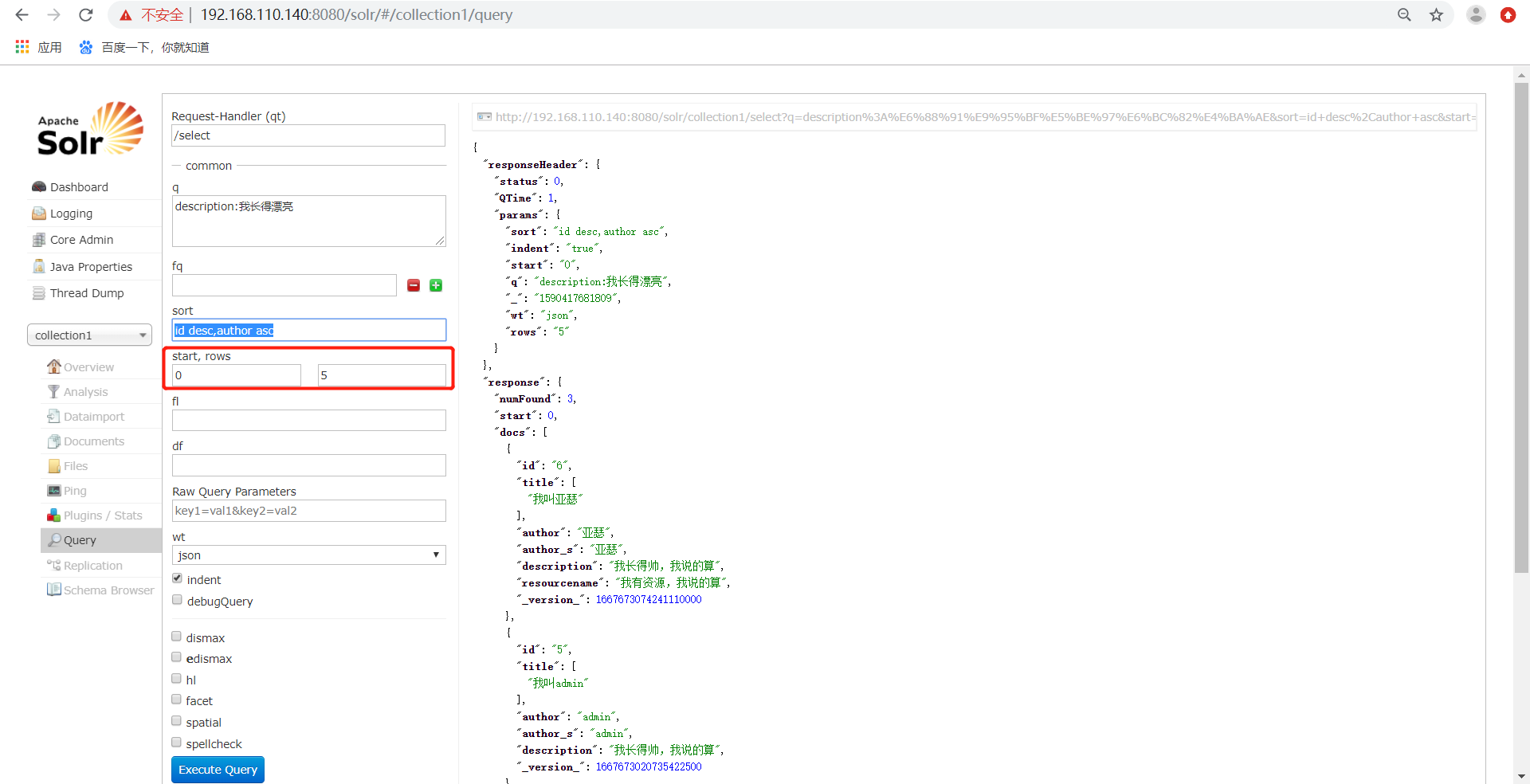
4)、start代表了分页显示使用,开始记录下标,从0开始。rows代表了指定返回结果最多有多少条记录,配合start来实现分页。显示前10条,如下所示。
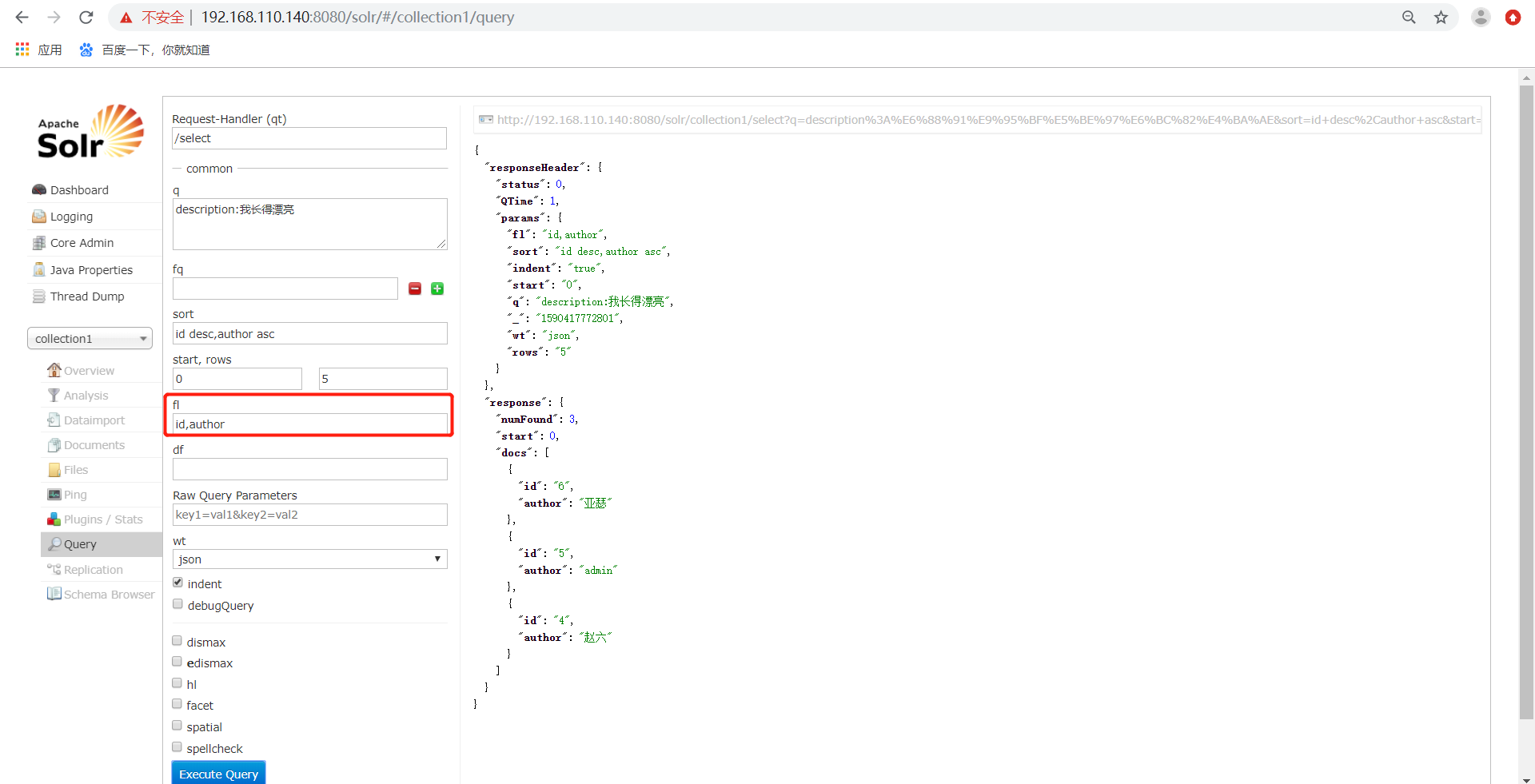
5)、fl代表了指定返回那些字段内容,用逗号或空格分隔多个。
6)、df代表了指定一个搜索Field。也可以在solrCore目录中conf/solrconfig.xml文件中指定默认搜索Field,指定后就可以直接在"q"查询条件中输入关键字。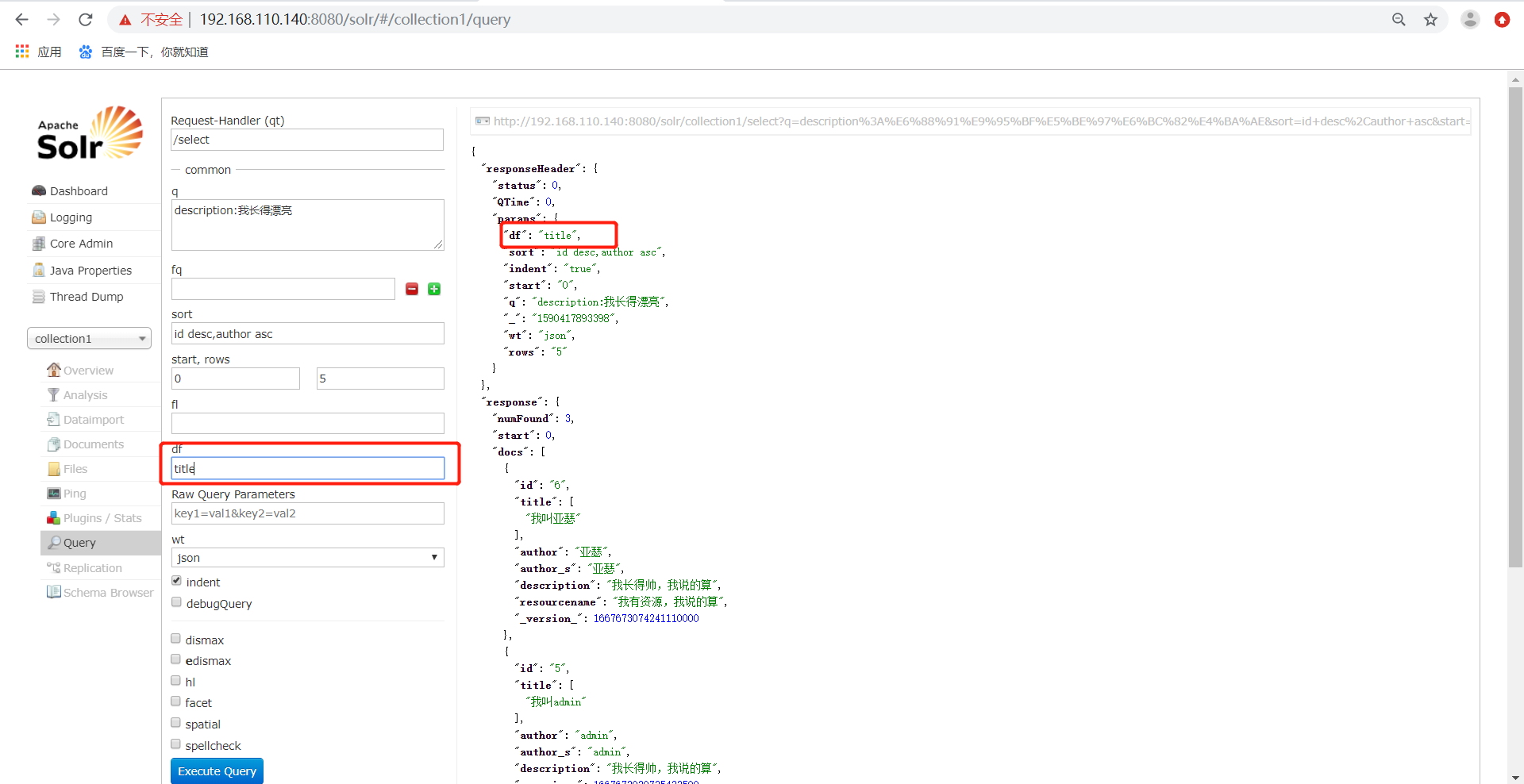
7)、wt 代表了 (writer type)指定输出格式,可以有 xml, json, php, phps, 后面 solr 1.3增加的,要用通知我们,因为默认没有打开。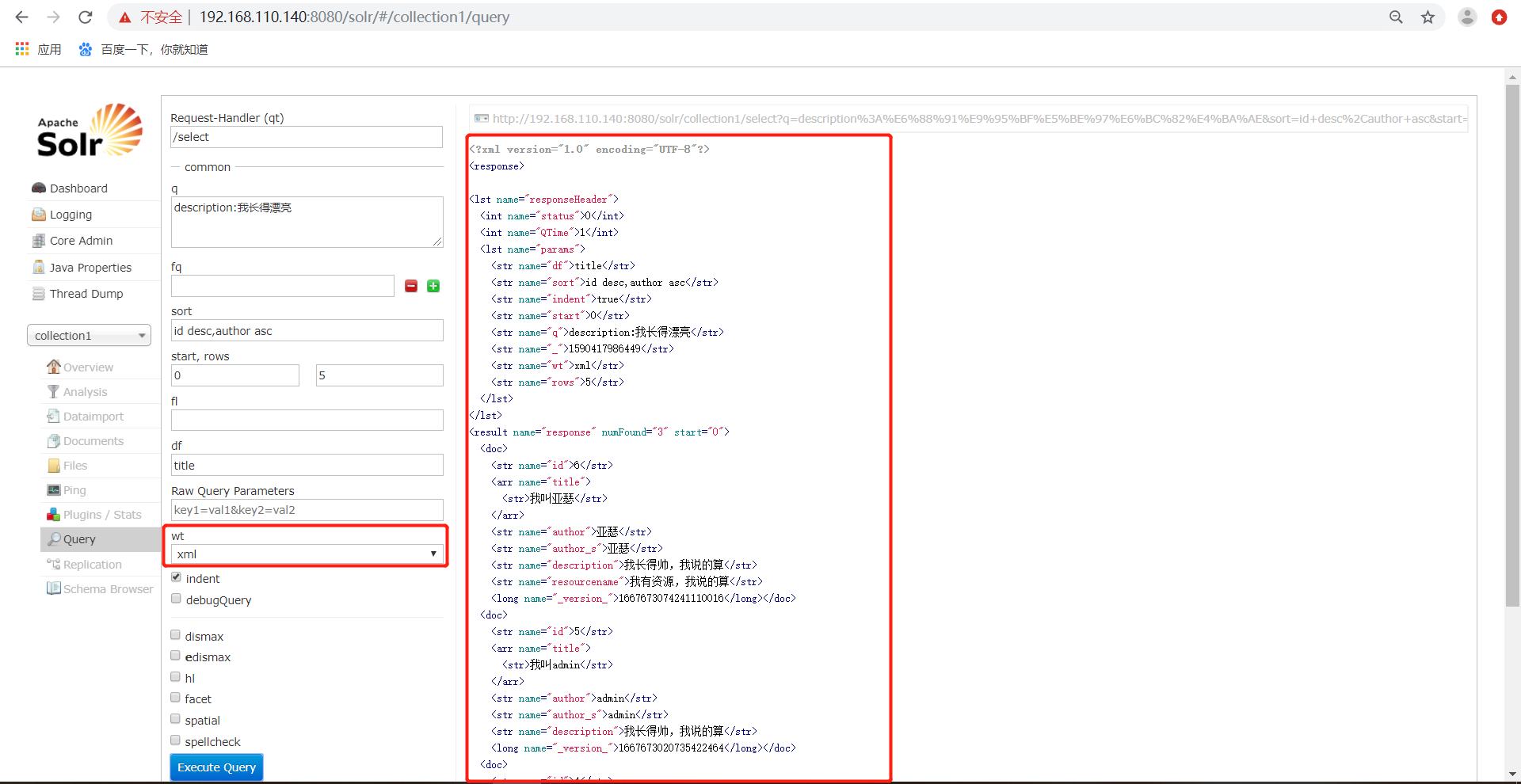
8)、hl代表了是否高亮 ,设置高亮Field,设置格式前缀和后缀。这里并没有高亮耶!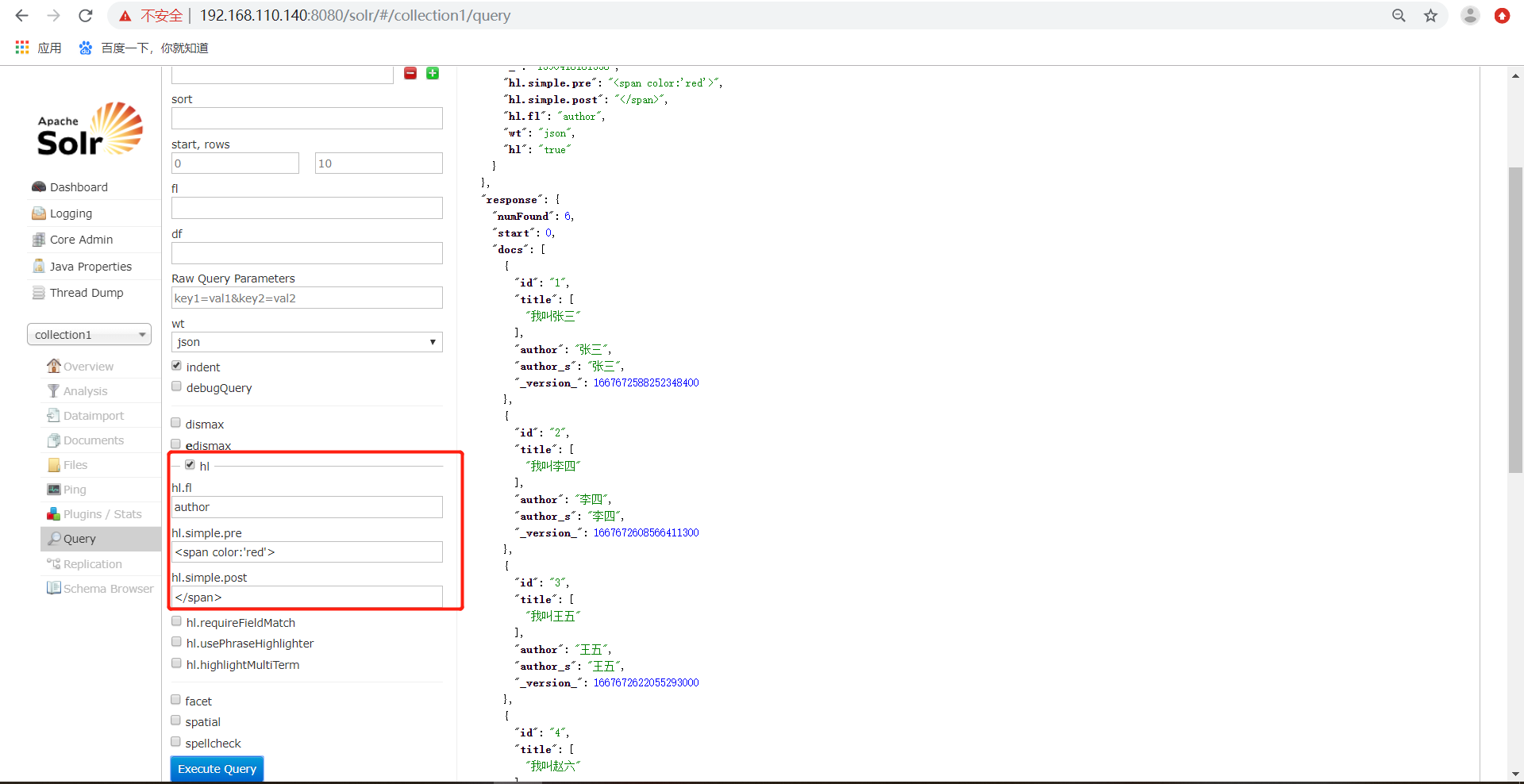
Solr的知识点学习的更多相关文章
- Java核心知识点学习----多线程中的阻塞队列,ArrayBlockingQueue介绍
1.什么是阻塞队列? 所谓队列,遵循的是先进先出原则(FIFO),阻塞队列,即是数据共享时,A在写数据时,B想读同一数据,那么就将发生阻塞了. 看一下线程的四种状态,首先是新创建一个线程,然后,通过s ...
- Java核心知识点学习----使用Condition控制线程通信
一.需求 实现线程间的通信,主线程循环3次后,子线程2循环2次,子线程3循环3次,然后主线程接着循环3次,如此循环3次. 即:A->B->C---A->B->C---A-> ...
- Java核心知识点学习----线程中如何创建锁和使用锁 Lock,设计一个缓存系统
理论知识很枯燥,但这些都是基本功,学完可能会忘,但等用的时候,会发觉之前的学习是非常有意义的,学习线程就是这样子的. 1.如何创建锁? Lock lock = new ReentrantLock(); ...
- Lucene/Solr企业级搜索学习资源
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引:也可以通过Http GSol ...
- Solr 6.7学习笔记(02)-- 配置文件 managed-schema (schema.xml) -- 样例(6)
managed-schema 样例: <?xml version="1.0" encoding="UTF-8" ?> <!-- License ...
- Solr 6.7学习笔记(02)-- 配置文件 managed-schema (schema.xml)(3)
5. <fieldType> fieldType主要定义了一些字段类型,其name属性值用于前面<field>中的type属性的值.e.g. <fieldTyp ...
- vue散碎知识点学习
1. vue散碎知识点学习 1.1. 特点 数据渲染/数据同步 组件化/模块化 其他功能路由,ajax,数据流 1.2. Vue.js学习资源 vuejs中文官网:http://cn.vuejs.or ...
- Solr 6.7学习笔记(04)-- Suggest
当我们使用baidu或者Google时,你输入很少的字符,就会自动跳出来一些建议选项,在Solr里,我们称之为Suggest,在solrconfig.xml里做一些简单的配置,即可实现这一功能.配置如 ...
- Solr 6.7学习笔记(02)-- 配置文件 managed-schema (schema.xml) - filter(5)
自定义fieldType时,通常还会用到filter.filter必须跟在tokenizer或其它filter之后.如: <fieldType> <analyzer> < ...
随机推荐
- C#中巧用Lambda进行数据的筛选查询等处理
场景 有一个Record对象的list,如果要根据其某个属性CycleIndex进行分组,类似于sql的group by分组查询. 如果要在这个这个list中查找出符合某种条件的数据,类似于sql的w ...
- 易优CMS:type的基础用法
[基础用法] 名称:type 功能:获取指定栏目信息 语法: {eyou:type typeid='栏目ID' empty='暂时没有数据'} <a href="{$field.typ ...
- 4-1-JS数据类型及相关操作
js的数据类型 判断数据类型 用typeof typeof "John" // alert(typeof "John") 返 ...
- 细数C++中的for循环
1.for(;;)这个是最基础最简单的for循环,从刚开始学习C语言的时候就知道的.for(int i = 0; i < 10; ++i){ }2.foreach完整的是for each(obj ...
- Android App自动更新解决方案(DownloadManager)
一开始,我们先向服务器请求数据获取版本 public ObservableField<VersionBean> appVersion = new ObservableField<&g ...
- java 和 spring 的异步
spring 的 async 注解 https://www.baeldung.com/spring-async@Async will make it execute in a separate thr ...
- 记录Flex布局的属性
容器属性 flex-dirextion(主轴的方向):>>row(水平) | row-reverse(水平取反) | column(垂直) | column-reverse(垂直取反) f ...
- [20190531]ORA-600 kokasgi1故障模拟与恢复(后续).txt
[20190531]ORA-600 kokasgi1故障模拟与恢复(后续).txt --//http://blog.itpub.net/267265/viewspace-2646340/=>[2 ...
- 判断map是否包含另一个map
判断map是否包含另一个map: map不同与list集合,list集合有直接判断集合是否包含其他集合或者元素的方法. boolean contains(Object o) 如果list包含指定的元素 ...
- pyhton 基础数据的爬取1
1. 什么是网络爬虫? 在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高.如何自动高效地获取互联网中我们感兴趣的信息 ...