使用Python爬取、清洗并分析前程无忧的大数据职位
爬取前程无忧的数据(大数据职位)
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 1 14:47:27 2019 @author: loo
""" import scrapy
import csv
from scrapy.crawler import CrawlerProcess class MySpider(scrapy.Spider):
name = "spider" def __init__(self):
# 保存为CSV文件操作
self.f = open('crawl_51jobs.csv', 'wt', newline='', encoding='GBK', errors='ignore')
self.writer = csv.writer(self.f)
'''title,locality,salary,companyName,releaseTime'''
self.writer.writerow(('职位', '公司地区','薪资', '公司名称', '发布时间')) # 设置待爬取网站列表
self.urls = []
# 设置搜索工作的关键字 key
key = '大数据'
print("关键字:", key)
# 设置需要爬取的网页地址
for i in range(1,200):
f_url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,' + key + ',2,' + str(i) + '.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
self.urls.append(f_url)
# print(self.urls) def start_requests(self):
# self.init_urls()
for url in self.urls:
yield scrapy.Request(url=url, callback=self.parse)
# parse方法会在每个request收到response之后调用 def parse(self, response):
# 提取工作列表
jobs = response.xpath('//*[@id="resultList"]/div[@class="el"]')
# print(jobs) for job in jobs:
# 工作职位
title = job.xpath('p/span/a/text()').extract_first().strip()
# 工作地区
locality = job.xpath('span[2]/text()').extract_first()
# 薪资
salary = job.xpath('span[3]/text()').extract_first()
# 公司名称
companyName = job.xpath('span[1]/a/text()').extract_first().strip()
# 发布时间
releaseTime = job.xpath('span[4]/text()').extract_first() print(title, locality, salary, companyName, releaseTime)
# 保存数据
self.writer.writerow((title, locality, salary, companyName, releaseTime))
# print("over: " + response.url) def main():
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}) process.crawl(MySpider)
process.start() # 这句代码就是开始了整个爬虫过程 ,会输出一大堆信息,可以无视 if __name__=='__main__':
main()
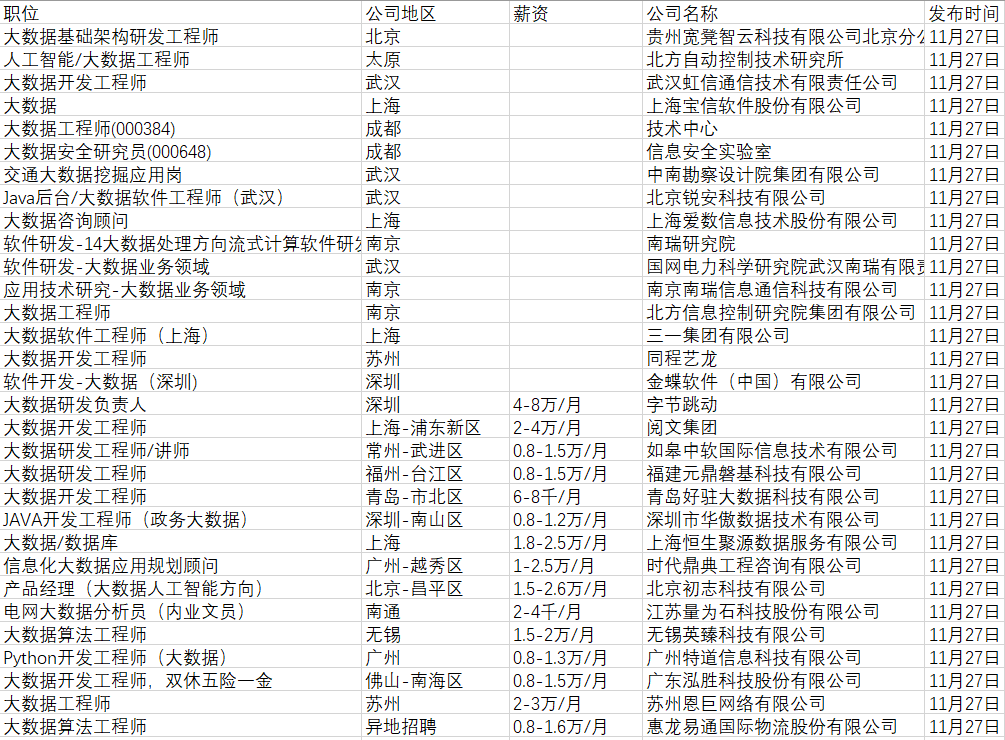
爬取后的数据保存到CSV文件中(如下图)
可以在文件中观察数据的特点
- 薪资单位不一样
公司地区模式不一样(有的为城市,有的是城市-地区)
有职位信息的空白
清洗数据
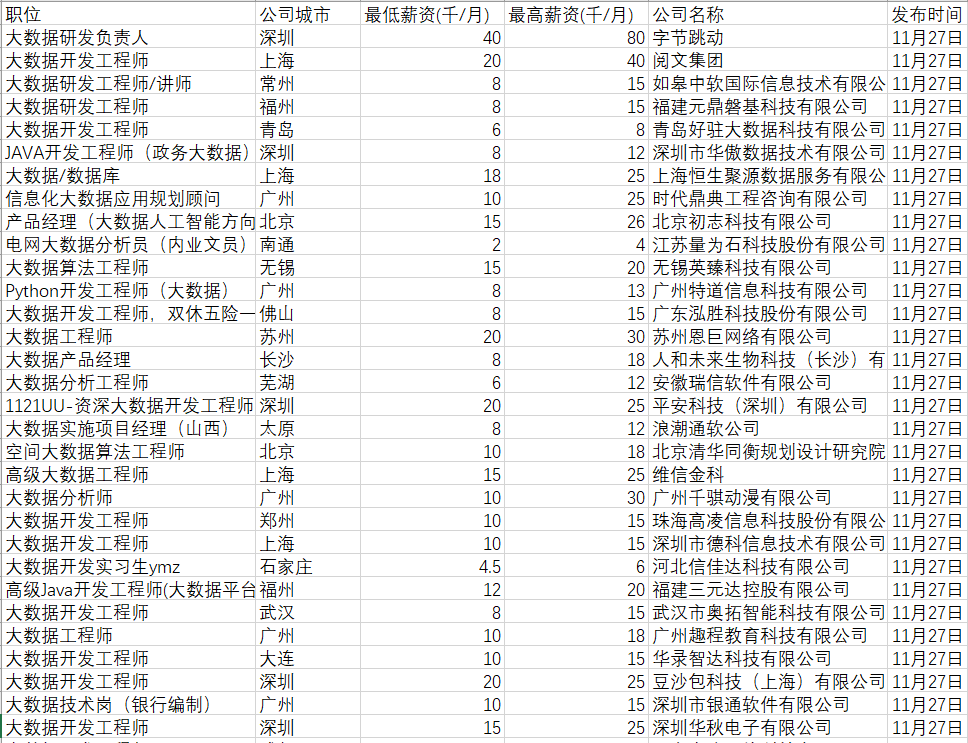
根据CSV文件中信息的特点进行数据清洗
- 将公司位置从区域改为公司城市:地区取到城市,把区域去掉。如“上海-浦东”转化为“上海”
- 薪资规范化(源数据有的是千/月,有的是万/月):统一单位(千元/月),并且将薪资范围拆分为最低薪资和最高薪资。如将“4-6千/月”转化为:最低薪资为4,最高薪资为6
- 删除含有空值的行(有的岗位信息的工作地点、薪资等可能为空,需要删除,便于后面分析)和公司地区为“异地招聘”的行
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 1 14:47:27 2019 @author: loo
""" import re
import csv
import numpy as np def salaryCleaning(salary):
"""
统一薪资的单位:(千元/月);
将薪资范围拆分为最低薪资和最高薪资
"""
minSa, maxSa = [], []
for sa in salary:
if sa:
if '-'in sa: # 针对1-2万/月或者10-20万/年的情况,包含-
minSalary=re.findall(re.compile('(\d*\.?\d+)'),sa)[0]
maxSalary=re.findall(re.compile('(\d?\.?\d+)'),sa)[1]
if u'万' in sa and u'年' in sa: # 单位统一成千/月的形式
minSalary = float(minSalary) / 12 * 10
maxSalary = float(maxSalary) / 12 * 10
elif u'万' in sa and u'月' in sa:
minSalary = float(minSalary) * 10
maxSalary = float(maxSalary) * 10
else: # 针对20万以上/年和100元/天这种情况,不包含-,取最低工资,没有最高工资
minSalary = re.findall(re.compile('(\d*\.?\d+)'), sa)[0]
maxSalary=""
if u'万' in sa and u'年' in sa: # 单位统一成千/月的形式
minSalary = float(minSalary) / 12 * 10
elif u'万' in sa and u'月' in sa:
minSalary = float(minSalary) * 10
elif u'元'in sa and u'天'in sa:
minSalary=float(minSalary)/1000*21 # 每月工作日21天
else:
minSalary = ""; maxSalary = ""; minSa.append(minSalary); maxSa.append(maxSalary)
return minSa,maxSa def locFormat(locality):
"""
将“地区-区域”转化为“地区”
"""
newLocality = []
for loc in locality:
if '-'in loc: # 针对有区域的情况,包含-
newLoc = re.findall(re.compile('(\w*)-'),loc)[0]
else: # 针对没有区域的情况
newLoc = loc
newLocality.append(newLoc)
return newLocality def readFile():
"""
读取源文件
"""
data = []
with open("crawl_51jobs.csv",encoding='gbk') as f:
csv_reader = csv.reader(f) # 使用csv.reader读取f中的文件
data_header = next(csv_reader) # 读取第一行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到data中
data.append(row) nd_data = np.array(data) # 将list数组转化成array数组便于查看数据结构
jobName = nd_data[:, 0]
locality = nd_data[:, 1]
salary = nd_data[:, 2]
companyName = nd_data[:, 3]
releaseTime = nd_data[:, 4]
return jobName, locality, salary, companyName, releaseTime def saveNewFile(jobName, newLocality, minSa, maxSa, companyName, releaseTime):
"""
将清洗后的数据写入新文件
"""
new_f = open('cleaned_51jobs.csv', 'wt', newline='', encoding='GBK', errors='ignore')
writer = csv.writer(new_f)
writer.writerow(('职位', '公司城市','最低薪资(千/月)','最高薪资(千/月)', '公司名称', '发布时间')) num = 0
while True:
try: # 所有数据都写入文件后,退出循环
if newLocality[num] and minSa[num] and maxSa[num] and companyName[num] and newLocality[num]!="异地招聘": # 当有空值时或者公司地点为异地招聘时不存入清洗后文件
writer.writerow((jobName[num], newLocality[num], minSa[num], maxSa[num], companyName[num], releaseTime[num]))
num += 1
except Exception:
break def main():
"""
主函数
"""
# 获取源数据
jobName, locality, salary, companyName, releaseTime = readFile() # 清洗源数据中的公司地区和薪资
newLocality = locFormat(locality)
minSa, maxSa = salaryCleaning(salary) # 将清洗后的数据存入CSV文件
saveNewFile(jobName, newLocality, minSa, maxSa, companyName, releaseTime) if __name__ == '__main__':
main()
可视化并分析数据
职位数前20名的城市以及平均薪资前20的城市
大数据岗位的职称情况
大数据岗位的城市分布情况
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 1 20:15:56 2019 @author: loo
""" import matplotlib.pyplot as plt
import csv
import numpy as np
import re
from wordcloud import WordCloud,STOPWORDS def readFile():
"""
读取清洗后的文件
"""
data = []
with open("cleaned_51jobs.csv",encoding='gbk') as f:
csv_reader = csv.reader(f) # 使用csv.reader读取f中的文件
data_header = next(csv_reader) # 读取第一行每一列的标题
for row in csv_reader: # 将csv文件中的数据保存到data中
data.append(row) nd_data = np.array(data) # 将list数组转化成array数组便于查看数据结构
jobName = nd_data[:, 0]
locality = nd_data[:, 1]
minSalary = nd_data[:, 2]
maxSalary = nd_data[:, 3]
return data, jobName, locality, minSalary, maxSalary def salary_locality(data):
"""
计算城市对应的职位数和平均薪资,并打印
"""
city_num = dict() for job in data:
loc, minSa, maxSa = job[1], float(job[2]), float(job[3])
if loc not in city_num:
avg_salary = minSa*maxSa/2
city_num[loc] = (1, avg_salary)
else:
num = city_num[loc][0]
avg_salary = (minSa*maxSa/2 + num * city_num[loc][1])/(num+1)
city_num[loc] = (num+1, avg_salary) # 将其按职位数降序排列
title_sorted = sorted(city_num.items(), key=lambda x:x[1], reverse=True)
title_sorted = dict(title_sorted) # 将其按平均薪资降序排列
salary_sorted = sorted(city_num.items(), key=lambda x:x[1][1], reverse=True)
salary_sorted = dict(salary_sorted) allCity1, allCity2, allNum, allAvg = [], [], [], []
i, j = 1, 1
# 取职位数前20
for city in title_sorted:
if i<=20:
allCity1.append(city)
allNum.append(title_sorted[city][0])
i += 1 # 取平均薪资前20
for city in salary_sorted:
if j<=20:
allCity2.append(city)
allAvg.append(salary_sorted[city][1])
j += 1 #解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 柱状图在横坐标上的位置
x = np.arange(20) # 设置图的大小
plt.figure(figsize=(13, 11)) # 列出你要显示的数据,数据的列表长度与x长度相同
y1 = allNum
y2 = allAvg bar_width=0.8 # 设置柱状图的宽度
tick_label1 = allCity1
tick_label2 = allCity2 # 绘制柱状图
plt.subplot(211)
plt.title('51job——大数据职位数前20名城市')
plt.xlabel(u"城市")
plt.ylabel(u"职位数")
plt.xticks(x,tick_label1) # 显示x坐标轴的标签,即tick_label
plt.bar(x,y1,bar_width,color='salmon') plt.subplot(212)
plt.title('51job——大数据职位平均薪资的前20名城市')
plt.xlabel(u"城市")
plt.ylabel(u"平均薪资(千元/月)")
plt.xticks(x,tick_label2) # 显示x坐标轴的标签,即tick_label
plt.bar(x,y2,bar_width,color='orchid') plt.legend() # 显示图例,即label
# plt.savefig('city.jpg', dpi=500) # 指定像素保存
plt.show() def jobTitle(jobName): word="".join(jobName); # 图片模板和字体
# image=np.array(Image.open('model.jpg'))#显示中文的关键步骤
font='simkai.ttf' # 去掉英文,保留中文
resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%\-]", " ",word)
# 已经中文和标点符号
wl_space_split = resultword
# 设置停用词
sw = set(STOPWORDS)
sw.add("高提成");sw.add("底薪");sw.add("五险");sw.add("双休")
sw.add("五险一金");sw.add("社保");sw.add("上海");sw.add("广州")
sw.add("无责底薪");sw.add("月薪");sw.add("急聘");sw.add("急招")
sw.add("资深");sw.add("包吃住");sw.add("周末双休");sw.add("代招")
sw.add("高薪");sw.add("高底薪");sw.add("校招");sw.add("月均")
sw.add("可实习");sw.add("年薪");sw.add("北京");sw.add("经理")
sw.add("包住");sw.add("应届生");sw.add("南京");sw.add("专员")
sw.add("提成");sw.add("方向") # 关键一步
my_wordcloud = WordCloud(font_path=font,stopwords=sw,scale=4,background_color='white',
max_words = 100,max_font_size = 60,random_state=20).generate(wl_space_split)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() #保存生成的图片
# my_wordcloud.to_file('title.jpg') def localityWordCloud(locality):
font='simkai.ttf'
locality = " ".join(locality) # 关键一步
my_wordcloud = WordCloud(font_path=font,scale=4,background_color='white',
max_words = 100,max_font_size = 60,random_state=20).generate(locality) #显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show() #保存生成的图片
# my_wordcloud.to_file('place.jpg') def main():
# 得到清洗后的数据数据
data, jobName, locality, minSalary, maxSalary = readFile()
# 进行分析
salary_locality(data)
jobTitle(jobName)
localityWordCloud(locality) if __name__ == '__main__':
main()
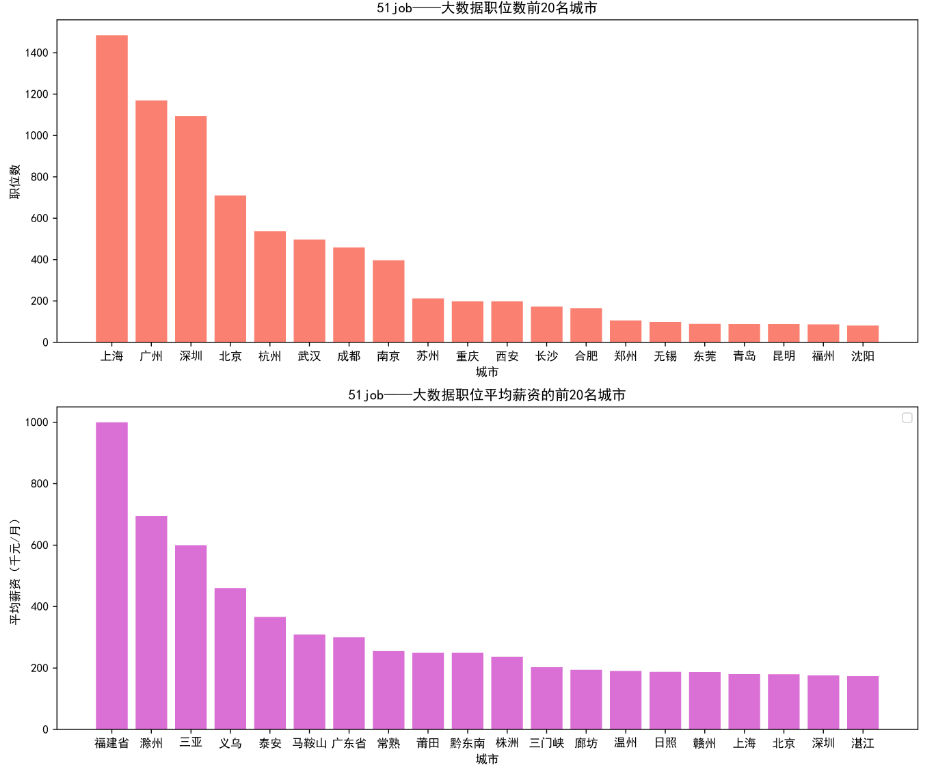
可视化图片如下


结论
1) 职位数排名前三的城市:上海、广州、深圳
2) 平均薪资排名前三的城市:福建、滁州、三亚
3) 大数据职位需求多的城市其平均薪资不一定高。相反,大数据职位需求多的城市的平均薪资更低,而大数据职位需求少的城市的平均薪资更高。
4) 大数据岗位需求最大的职称是:开发工程师
使用Python爬取、清洗并分析前程无忧的大数据职位的更多相关文章
- Python 爬取 热词并进行分类数据分析-[拓扑数据]
日期:2020.01.29 博客期:137 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 用Python爬取《王者荣耀》英雄皮肤数据并可视化分析,用图说话
大家好,我是辰哥~ 今天辰哥带大家分析一波当前热门手游<王者荣耀>英雄皮肤,比如皮肤上线时间.皮肤类型(勇者:史诗:传说等).价格. 1.获取数据 数据来源于<王者荣耀官方网站> ...
- Python爬取猪肉价格网并获取Json数据
场景 猪肉价格网站: http://zhujia.zhuwang.cc/ 注: 博客: https://blog.csdn.net/badao_liumang_qizhi 关注公众号 霸道的程序猿 获 ...
- python爬取post请求Reque Payload的json数据
import requests,json url = "https://www.yijiupi.com/v31/Product/ListProduct" headers = { ' ...
- python爬取网易云周杰伦所有专辑,歌曲,评论,并完成可视化分析
---恢复内容开始--- 去年在网络上有一篇文章特别有名:我分析42万字的歌词,为搞清楚民谣歌手们在唱些什么.这篇文章的作者是我大学的室友,随后网络上出现了各种以为爬取了XXX,发现了XXX为名的文章 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- 用Python爬取分析【某东618】畅销商品销量数据,带你看看大家都喜欢买什么!
618购物节,辰哥准备分析一波购物节大家都喜欢买什么?本文以某东为例,Python爬取618活动的畅销商品数据,并进行数据清洗,最后以可视化的方式从不同角度去了解畅销商品中,名列前茅的商品是哪些?销售 ...
- Python爬取南京市往年天气预报,使用pyecharts进行分析
上一次分享了使用matplotlib对爬取的豆瓣书籍排行榜进行分析,但是发现python本身自带的这个绘图分析库还是有一些局限,绘图不够美观等,在网上搜索了一波,发现现在有很多的支持python的绘图 ...
- Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析
爬取过程在这里: Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图 本文基于前文爬取生成的douban.txt,基于SnowNLP做情感分析. 依赖库: 豆瓣镜像比较快: ...
随机推荐
- Excel的IYQ钓鱼
0x00 环境准备 1.操作系统:windows7 2.microsoft office版本:office 2010 0x01 了解IYQ的基本概念 可以将IYQ简单的理解成内置在excel中的一种特 ...
- RTKLib的Manual解读
Key-word: integer ambiguity resolution :整周模糊度解算 navigation:导航 Kinematic:动态,RTK的K rover:漫游 validation ...
- Kong05-Kong 的健康检查和监控
您可以让 Kong 代理的 API 使用 ring-balancer , 通过添加包含一个或多个目标实体的upstream 实体来配置,每个目标指向不同的IP地址(或主机名)和端口.ring-bala ...
- appium 处理webview
折腾了一段时间,无论是模拟器还是真机,driver.contexts都只有NATIVE_APP,无奈放弃切换webview,直接查找定位元素 from time import sleep import ...
- Numpy 中的比较和 Fancy Indexing
# 导包 import numpy as np Fancy Indexing 应用在一维数组 x = np.arange(16) x[3] x[3:9] # array([3, 4, 5, 6, 7, ...
- python之小木马(文件上传,下载,调用命令行,按键监控记录)
window版 服务端: 开启两个线程,一个用来接收客户端的输入,一个用来监控服务端键盘的记录 客户端: get 文件(下载)put 文件(上传) window下cmd命令执行结果会直接打印出来,ke ...
- 第六天、用户、组、权限、grep
第六天.用户.组.权限.grep 权限总结表 操作 源目录权限 文件权限 目标目录权限 rm删文件 wx - - mv改名 wx - - mv移动文件 wx r wx cp复制文件 x r wx &g ...
- tap事件封装
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8 ...
- Secure CRT注册码
secure CRT 把记忆的东西放在这就行了,:) SecureCRT 5.2.2的注册码 Name: Apollo InteractiveCompany: Apollo ...
- Pashmak and Parmida's problem(树状数组)
题目链接:http://codeforces.com/contest/459/problem/D 题意: 数列A, ai表示 i-th 的值, f(i,j, x) 表示[i,j]之间x的数目, 问:当 ...