基于C#的机器学习--我应该接受这份工作吗-使用决策树
决策树
要使决策树完整而有效,它必须包含所有的可能性。事件序列也必须提供,并且是互斥的,这意味着如果一个事件发生,另一个就不能发生。
决策树是监督机器学习的一种形式,因为我们必须解释输入和输出应该是什么。有决策节点和叶子。叶子是决策,不管是否是最终决策,节点是决策分裂发生的地方。
虽然有很多算法可供我们使用,但我们将使用迭代二分法(ID3)算法。
在每个递归步骤中,根据一个标准(信息增益、增益比等)选择对我们正在处理的输入集进行最佳分类的属性。
这里必须指出的是,无论我们使用什么算法,都不能保证生成尽可能小的树。因为这直接影响到算法的性能。
请记住,对于决策树,学习仅仅基于启发式,而不是真正的优化标准。让我们用一个例子来进一步解释这一点。
下面的示例来自http://jmlr.csail.mit.edu/papers/volume8/esmeir07a/esmeir07a.pdf,它演示了XOR学习概念,我们所有的开发人员都(或应该)熟悉这个概念。稍后的例子中也会出现这种情况,但现在a3和a4与我们要解决的问题完全无关。它们对我们的答案没有影响。也就是说,ID3算法将选择其中一个构建树,事实上,它将使用a4作为根节点!记住,这是算法的启发式学习,而不是优化结果:
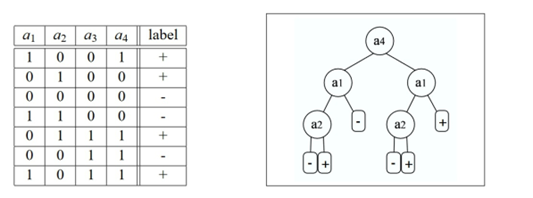
希望这张图能让大家更容易理解刚刚所说的内容。我们的目标并不是深入研究决策树机制和理论。而是如何使用它,尽管存在很多问题,但决策树仍然是许多算法的基础,尤其是那些需要对结果进行人工描述的算法。这也是我们前面试试人脸检测算法的基础。
决策节点
决策树的一个节点。每个节点可能有关联的子节点,也可能没有关联的子节点
决策的变量
此对象定义树和节点可以处理的每个决策变量的性质。值可以是范围,连续的,也可以是离散的。
决策分支节点的集合
此集合包含将一个或多个决策节点组,以及关于决策变量的附加信息,以便进行比较。
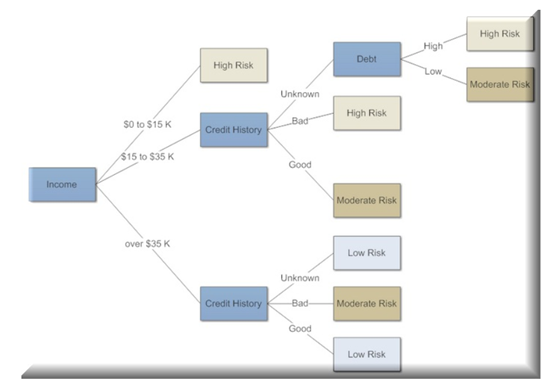
下面是一个用于确定金融风险的决策树示例。我们只需要在节点之间导航,就可以很容易地跟随它,决定要走哪条路,直到得到最终的答案。在这种情况下,当有人正在申请贷款,而我们需要对他们的信用价值做出决定。这时决策树就是解决这个问题的一个很好的方法:
我应该接受这份工作吗?
你刚刚得到一份新工作,你需要决定是否接受它。有一些重要的事情需要考虑,所以我们将它们作为输入变量或特性,用于决策树。
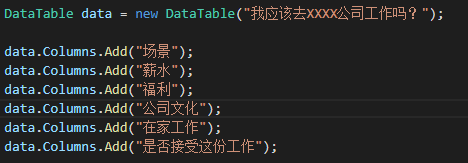
对你来说最重要的是:薪水、福利、公司文化,当然还有,我能在家工作吗?
我们将创建一个内存数据库并以这种方式添加特性,而不是从磁盘存储中加载数据。我们将创建DataTable并创建列,如下图所示:
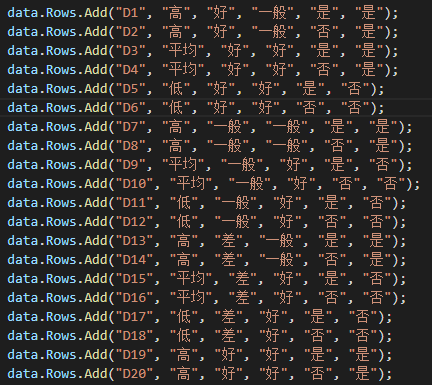
在这之后,我们将加载几行数据,每一行都有一组不同的特性,最后一列应该是Yes或No,作为我们的最终决定:
一旦所有的数据都创建好并放入表中,我们就需要将之前的特性转换成计算机能够理解的表示形式。
由于数字更简单,我们将通过一个称为编码的过程将我们的特性(类别)转换为一本代码本。该代码本有效地将每个值转换为整数。
注意,我们将传递我们的数据类别作为输入:

接下来,我们需要为决策树创建要使用的决策变量。
这棵树会帮助我们决定是否接受新的工作邀请。对于这个决策,将有几类输入,我们将在决策变量数组中指定它们,以及两个可能的决策,是或者否。
DecisionVariable数组将保存每个类别的名称以及该类别可能的属性的总数。例如,薪水类别有三个可能的值,高、平均或低。我们指定类别名和数字3。然后,除了最后一个类别(即我们的决定)之外,我们对所有其他类别都重复这个步骤:
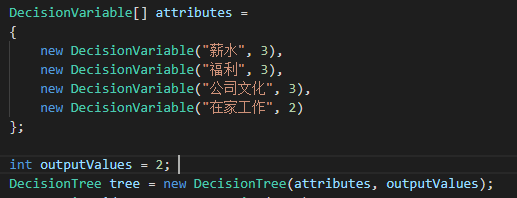
现在我们已经创建了决策树,我们必须教它如何解决我们要解决的问题。为了做到这一点,我们必须为这棵树创建一个学习算法。由于我们只有这个示例的分类值,所以ID3算法是最简单的选择。

一旦学习算法被运行,它就会被训练并可供使用。我们简单地为算法提供一个样本数据集,这样它就可以给我们一个答案。在这种情况下,薪水不错,公司文化不错,福利也不错,我可以在家工作。如果正确地训练决策树,答案将会是是:

Numl
numl是一个非常著名的开源机器学习工具包。与大多数机器学习框架一样,它的许多示例也使用Iris数据集,包括我们将用于决策树的那个。
下面是我们的numl输出的一个例子:
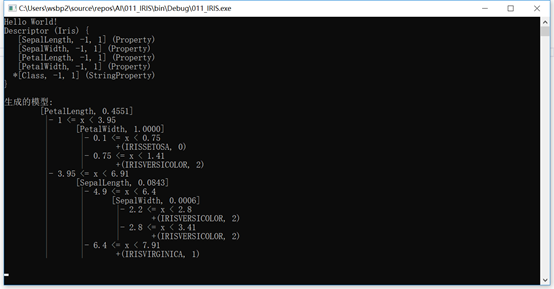
让我们看一下这个例子背后的代码:
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
var description = Descriptor.Create<Iris>();
Console.WriteLine(description);
var generator = new DecisionTreeGenerator();
var data = Iris.Load();
var model = generator.Generate(description, data);
Console.WriteLine("生成的模型:");
Console.WriteLine(model);
Console.ReadKey();
}
这个方法并不复杂,对吧?这就是在应用程序中使用numl的好处;它非常容易使用和集成。
上述代码创建描述符和DecisionTreeGenerator,加载Iris数据集,然后生成模型。这里只是正在加载的数据的一个示例:
public static Iris[] Load()
{
return new Iris[]
{
new Iris { SepalLength = 5.1m, SepalWidth = 3.5m, PetalLength = 1.4m, PetalWidth = 0.2m, Class = "Iris-setosa" },
new Iris { SepalLength = 4.9m, SepalWidth = 3m, PetalLength = 1.4m, PetalWidth = 0.2m, Class = "Iris-setosa" },
new Iris { SepalLength = 4.7m, SepalWidth = 3.2m, PetalLength = 1.3m, PetalWidth = 0.2m, Class = "Iris-setosa" },
new Iris { SepalLength = 4.6m, SepalWidth = 3.1m, PetalLength = 1.5m, PetalWidth = 0.2m, Class = "Iris-setosa" },
new Iris { SepalLength = 5m, SepalWidth = 3.6m, PetalLength = 1.4m, PetalWidth = 0.2m, Class = "Iris-setosa" },
new Iris { SepalLength = 5.4m, SepalWidth = 3.9m, PetalLength = 1.7m, PetalWidth = 0.4m, Class = "Iris-setosa" }
};
}
Accord.NET 决策树
Accord.NET framework也有自己的决策树例子。它采用了一种不同的、更图形化的方法来处理决策树,但是您可以通过调用来决定您喜欢哪个决策树,并且最习惯使用哪个决策树。
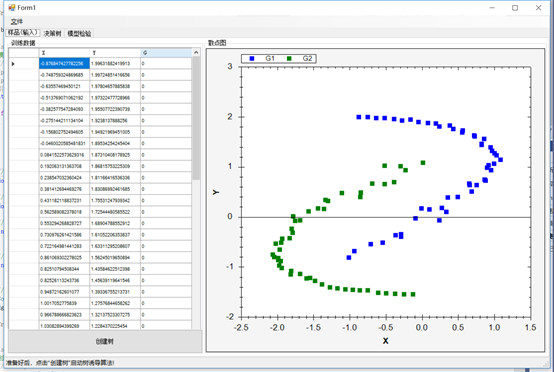
一旦数据被加载,您就可以创建决策树并为学习做好准备。您将看到与这里类似的数据图,使用了X和Y两个类别:
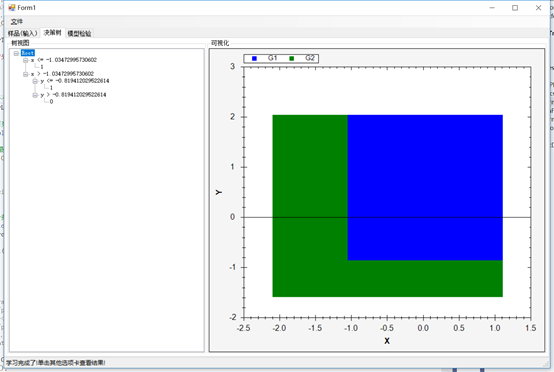
下一个选项卡将让您看到树节点、叶子和决策。右边还有一个自顶向下的树的图形视图。最有用的信息在左边的树形视图中,你可以看到节点,它们的值,以及做出的决策:
最后,最后一个选项卡将允许您执行模型测试:
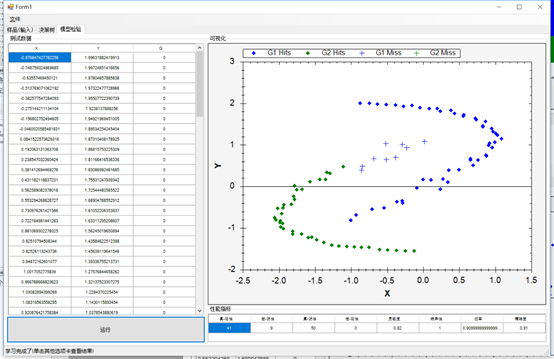
代码
下面是学习代码
// 指定输入变量
DecisionVariable[] variables =
{
new DecisionVariable("x", DecisionVariableKind.Continuous),
new DecisionVariable("y", DecisionVariableKind.Continuous),
};
// 创建C4.5学习算法
var c45 = new C45Learning(variables); // 使用C4.5学习决策树
tree = c45.Learn(inputs, outputs); // 在视图中显示学习树
decisionTreeView1.TreeSource = tree; // 获取每个变量(X和Y)的范围
DoubleRange[] ranges = table.GetRange(); // 生成一个笛卡尔坐标系
double[][] map = Matrix.Mesh(ranges[], , ranges[], ); // 对笛卡尔坐标系中的每个点进行分类
double[,] surface = map.ToMatrix().InsertColumn(tree.Decide(map));
CreateScatterplot(zedGraphControl2, surface);
//测试
// 从整个源数据表创建一个矩阵
double[][] table = (dgvLearningSource.DataSource as DataTable).ToJagged(out columnNames); //只获取输入向量值(前两列)
double[][] inputs = table.GetColumns(, ); // 获取预期的输出标签(最后一列)
int[] expected = table.GetColumn().ToInt32(); // 计算实际的树输出
int[] actual = tree.Decide(inputs); // 使用混淆矩阵来计算一些统计数据。
ConfusionMatrix confusionMatrix = new ConfusionMatrix(actual, expected, , );
dgvPerformance.DataSource = new[] { confusionMatrix }; CreateResultScatterplot(zedGraphControl1, inputs, expected.ToDouble(), actual.ToDouble());
然后他的值被输入一个混淆矩阵。对于不熟悉这一点的同学,让我简单解释一下.
混淆矩阵
混淆矩阵是用来描述分类模型性能的表。它在已知真值的测试数据集上运行。这就是我们如何得出如下结论的。
真-阳性
在这个例子中,我们预测是,这是事实。
真-阴性
在这种情况下,我们预测否,这是事实。
假-阳性
在这种情况下,我们预测是,但事实并非如此。有时您可能会看到这被称为type 1错误。
假-阴性
在这种情况下,我们预测“否”,但事实是“是”。有时您可能会看到这被type 2类错误。
现在,说了这么多,我们需要谈谈另外两个重要的术语,精确度和回忆。
让我们这样来描述它们。在过去的一个星期里,每天都下雨。这是7天中的7天。很简单。一周后,你被问到上周多久下一次雨?
回忆
它是你正确回忆下雨的天数与正确事件总数的比值。如果你说下了7天雨,那就是100%。如果你说下了四天雨,那么57%的人记得。在这种情况下,它的意思是你的回忆不是那么精确,所以我们有精确度来识别。
精确度
它是你正确回忆将要下雨的次数与那一周总天数的比值。
对我们来说,如果我们的机器学习算法擅长回忆,并不一定意味着它擅长精确。有道理吗?这就涉及到其他的事情,比如F1的分数,我们会留到以后再讲。
可视化错误类型
以下是一些可能会有帮助的可视化:

识别真阳性和假阴性:
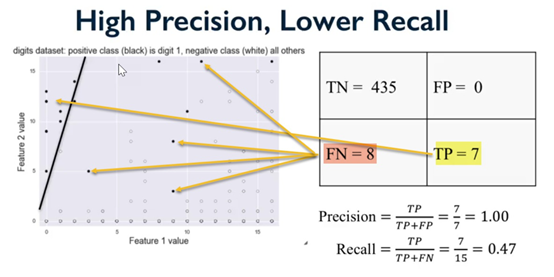
使用混淆矩阵计算统计量后,创建散点图,识别出所有内容:
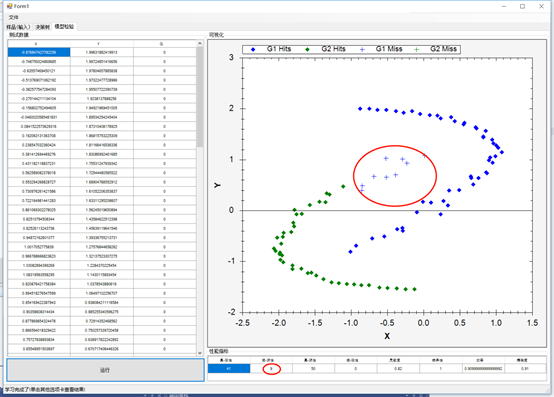
总结
在这一章中,我们花了很多时间来研究决策树;它们是什么,我们如何使用它们,以及它们如何使我们在应用程序中受益。在下一章中,我们将进入深度信念网络(DBNs)的世界,它们是什么,以及我们如何使用它们。
我们甚至会谈论一下计算机的梦,当它做梦的时候!
基于C#的机器学习--我应该接受这份工作吗-使用决策树的更多相关文章
- 基于C#的机器学习--目录
转载请注明出处:https://www.cnblogs.com/wangzhenyao1994/p/10223666.html 文章发表的另一个地址:https://blog.csdn.net/wyz ...
- 基于C#的机器学习--旅行推销员问题
我们有一个必须在n个城市之间旅行的推销员.他不在乎什么顺序.他最先或最后访问的城市除外.他唯一关心的是他会去拜访每一个人,每个城市只有一次,最后一站是他得家. 每个城市都是一个节点,每个节点通过一条边 ...
- 基于Python的机器学习实战:KNN
1.KNN原理: 存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应 ...
- Spark学习之基于MLlib的机器学习
Spark学习之基于MLlib的机器学习 1. 机器学习算法尝试根据训练数据(training data)使得表示算法行为的数学目标最大化,并以此来进行预测或作出决定. 2. MLlib完成文本分类任 ...
- 基于python的机器学习开发环境安装(最简单的初步开发环境)
一.安装Python 1.下载安装python3.6 https://www.python.org/getit/ 2.配置环境变量(2个) 略...... 二.安装Python算法库 安装顺序:Num ...
- 基于Apache Spark机器学习的客户流失预测
流失预测是个重要的业务,通过预测哪些客户可能取消对服务的订阅来最大限度地减少客户流失.虽然最初在电信行业使用,但它已经成为银行,互联网服务提供商,保险公司和其他垂直行业的通用业务. 预测过程是大规模数 ...
- 基于C#的机器学习--惩罚与奖励-强化学习
强化学习概况 正如在前面所提到的,强化学习是指一种计算机以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使程序获得最大的奖赏,强化学习不同于连督学习,区别主要表现在强化信号上,强 ...
- 基于C#的机器学习--贝叶斯定理-执行数据分析解决肇事逃逸之谜
贝叶斯定理-执行数据分析解决肇事逃逸之谜 在这一章中,我们将: 应用著名的贝叶斯定理来解决计算机科学中的一个非常著名的问题. 向您展示如何使用贝叶斯定理和朴素贝叶斯来绘制数据,从真值表中发现异常值 ...
- 基于C#的机器学习--面部和动态检测-图像过滤器
在本章中,我们将展示两个独立的例子,一个用于人脸检测,另一个用于动态检测,以及如何快速地将这些功能添加到应用程序中. 在这一章中,我们将讨论: 面部检测 动态检测 将检测添加到应用程序中 面部检测 人 ...
随机推荐
- mysql 优化 读写分离 主从复制
1:mysql所在服务器内核 优化 ---------此优化可由系统运维人员完成 2:mysql配置参数优化(my.cnf) -------- 此优化需进行压力测试来进行参数调整 3:sql语句及表 ...
- [WPF]有Focus(), 那Unfocus()呢?
原文:[WPF]有Focus(), 那Unfocus()呢? [WPF]有Focus(), 那Unfocus()呢? 周银辉 我们可以调用Focus()方法,让WPF控件获得焦点, 那我现在不想要焦点 ...
- MVC EF Code First
1 在Models里面创建类,用[Key]特性指定主键: 2 在Model里面增加导航属性: 3 在web.config里面增加连接字符串 4 创建继承于DbContext的类 5 创建Control ...
- JavaScript eval() 函数,计算某个字符串,并执行其中的的 JavaScript 代码。
JavaScript eval() 函数,计算某个字符串,并执行其中的的 JavaScript 代码. 适合用于计算器的计算,等. 例子: eval("x=10;y=20;document. ...
- canvas——粒子系统(1)
这个动画在很早之前就见过,当时就没迷住了.最近在学canavs动画,动手实现了一下.代码在这里.展示效果在这里. 这属于粒子系统的一种,粒子系统就是需要管理一堆粒子嘛,动画实现的关键在于,遍历这些粒子 ...
- 图像滤镜艺术---Wave滤镜
原文:图像滤镜艺术---Wave滤镜 Wave Filter水波滤镜 水波滤镜是通过坐标变换来模拟水波效果,使图像呈现出水波的特效.这个滤镜有一个可调参数:水波的扭曲程度. 代码如下; // ...
- 使用Newtonsoft.Json输出JSON
安装: Install-Package Newtonsoft.Json 代码: //序列化DataTable DataTable dt = new DataTable(); dt.Columns.Ad ...
- 彻底删除kafka topic步骤
基于kafka-2.11-0.9.0.0 . a.kill掉kafka进程,然后在server.properties里面加上delete.topic.enable=true.重启kafka.集群中的每 ...
- IT职场初体验一
自己学习计算机专业也算有两个年头了吧,对于这个刚刚IT入门的菜鸟,对IT职场充满了好奇和憧憬,本人大学也像很多大学生一样,进入计算机专业也不是自己最初想进入的专业,进入这个原本离自己有点遥远的行业,一 ...
- Java基础(一) 八大基本数据类型
自从Java发布以来,基本数据类型就是Java语言的一部分,分别是byte, short, int, long, char, float, double, boolean. 其中: 整型:byte, ...