【Redis】集群方式
一、概述
1.1 Redis3.0版本之前
- 3.0版本之前的redis是不支持集群的,我们的redis如果想要集群的话,就需要一个中间件,然后这个中间件负责将我们需要存入redis中的数据的key通过一套算法计算得出一个值。然后根据这个值找到对应的redis节点,将这些数据存在这个redis的节点中。
- 在取值的时候,同样先将key进行计算,得到对应的值,然后就去找对应的redis节点,从对应的节点中取出对应的值。
- 这样做有很多不好的地方,比如说我们的这些计算都需要在系统中去进行,所以会增加系统的负担。还有就是这种集群模式下,某个节点挂掉,其他的节点无法知道。而且也不容易对每个节点进行负载均衡。
1.2 常见集群方案
- 官方方案:redis-cluster(强烈推荐),3.0之后开始实现
- 客户端分片技术(不推荐),扩容/缩容时,必须手动调整分片程序,出现故障不能自动转移
- 可以使用主从复制方式(不推荐):数据非常冗余,浪费内存
- 使用一些代理工具
二、Redis-Cluster原理
- Redis 是一个开源的 key-value 存储系统,由于出众的性能,大部分互联网企业都用来做服务器端缓存。Redis 在3.0版本前只支持单实例模式,虽然支持主从模式、哨兵模式部署来解决单点故障,但是现在互联网企业动辄大几百G的数据,可完全是没法满足业务的需求,所以,Redis 在 3.0 版本以后就推出了集群模式。
- Redis 集群采用了P2P的模式,完全去中心化。Redis 把所有的 Key 分成了 16384 个 slot,每个 Redis 实例负责其中一部分 slot 。集群中的
- 所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
- Redis 客户端可以在任意一个 Redis 实例发出请求,如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。

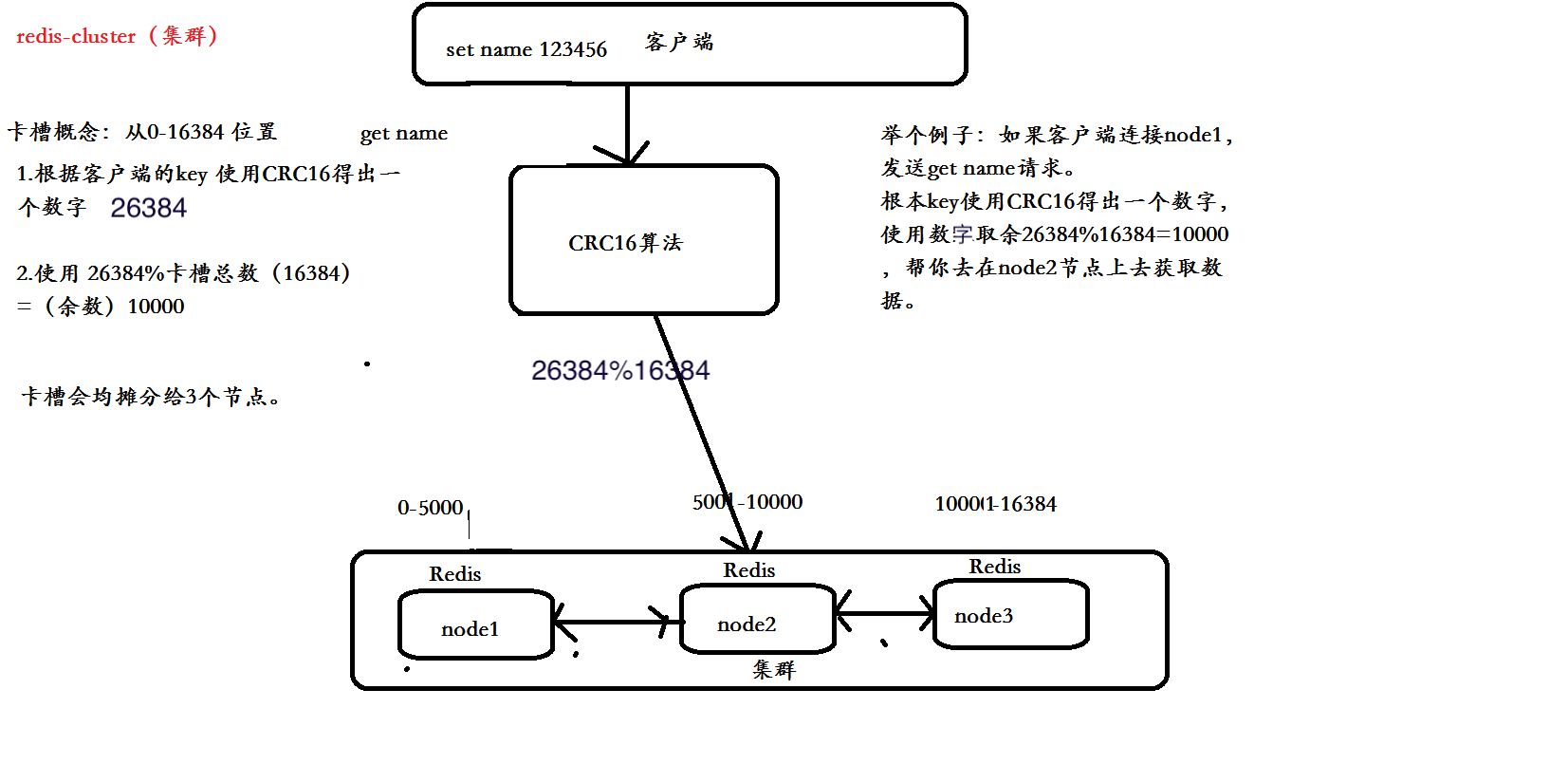
- 在这个图中,每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作。
- 那么redis是怎么做到的呢?首先,在redis的每一个节点上,都有这么两个东西,一个是插槽(slot)可以理解为是一个可以存储两个数值的一个变量这个变量的取值范围是:0-16383。还有一个就是cluster我个人把这个cluster理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
- 还有就是因为如果集群的话,是有好多个redis一起工作的,那么,就需要这个集群不是那么容易挂掉,所以呢,理论上就应该给集群中的每个节点至少一个备用的redis服务。这个备用的redis称为从节点(slave)。那么这个集群是如何判断是否有某个节点挂掉了呢?
- 首先要说的是,每一个节点都存有这个集群所有主节点以及从节点的信息。
- 它们之间通过互相的ping-pong判断是否节点可以连接上。如果有一半以上的节点去ping一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的备用节点。如果某个节点和所有从节点全部挂掉,我们集群就进入faill状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入发力了状态。这就是我们的redis的投票机制,具体原理如下图所示:
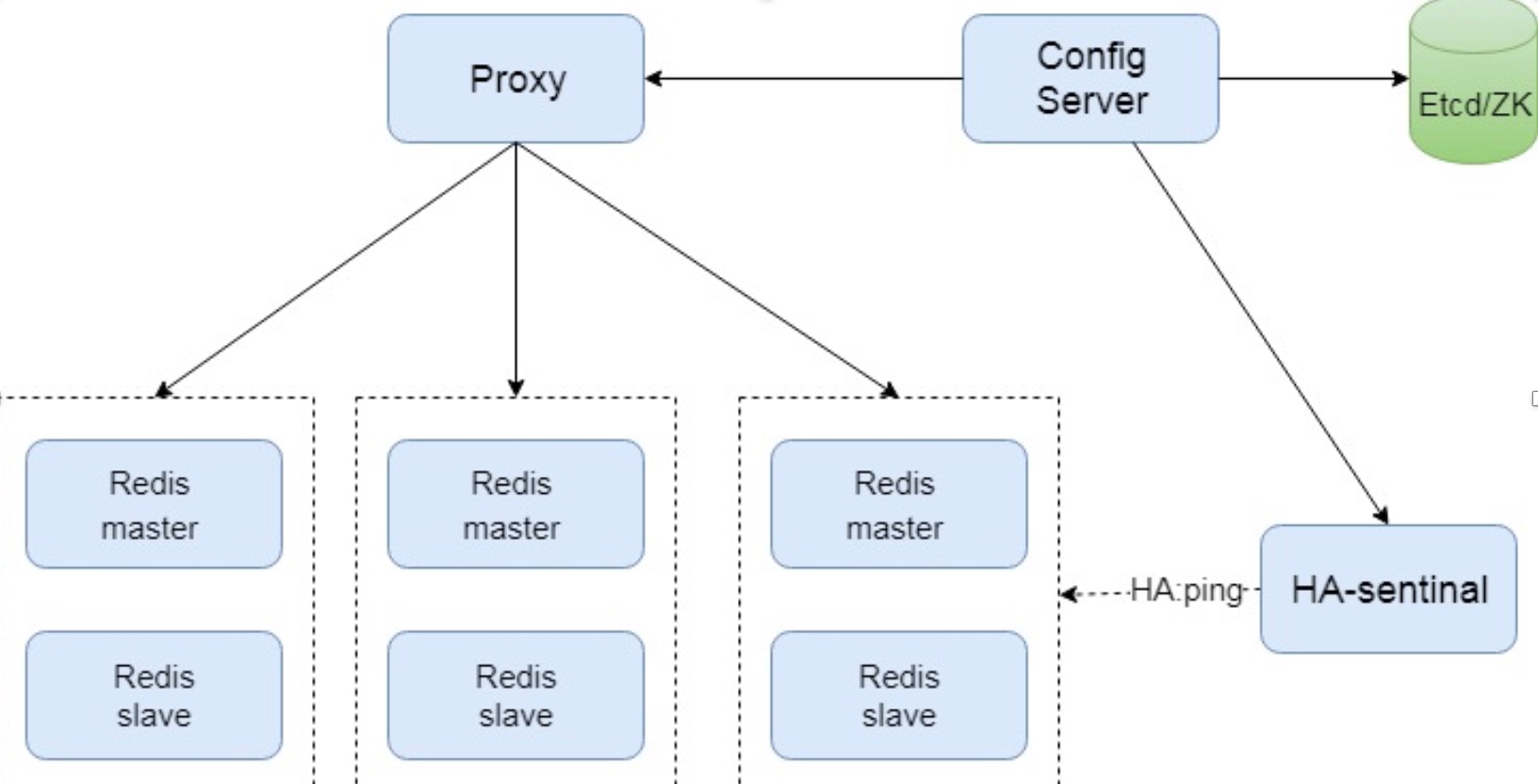
- 这套架构的特点:
- 分片算法:基于 slot hash桶;
- 分片实例之间相互独立,每组 一个master 实例和多个slave;
- 路由信息存放到第三方存储组件,如 zookeeper 或etcd
- 旁路组件探活
三、搭建集群方案
3.1 准备工作
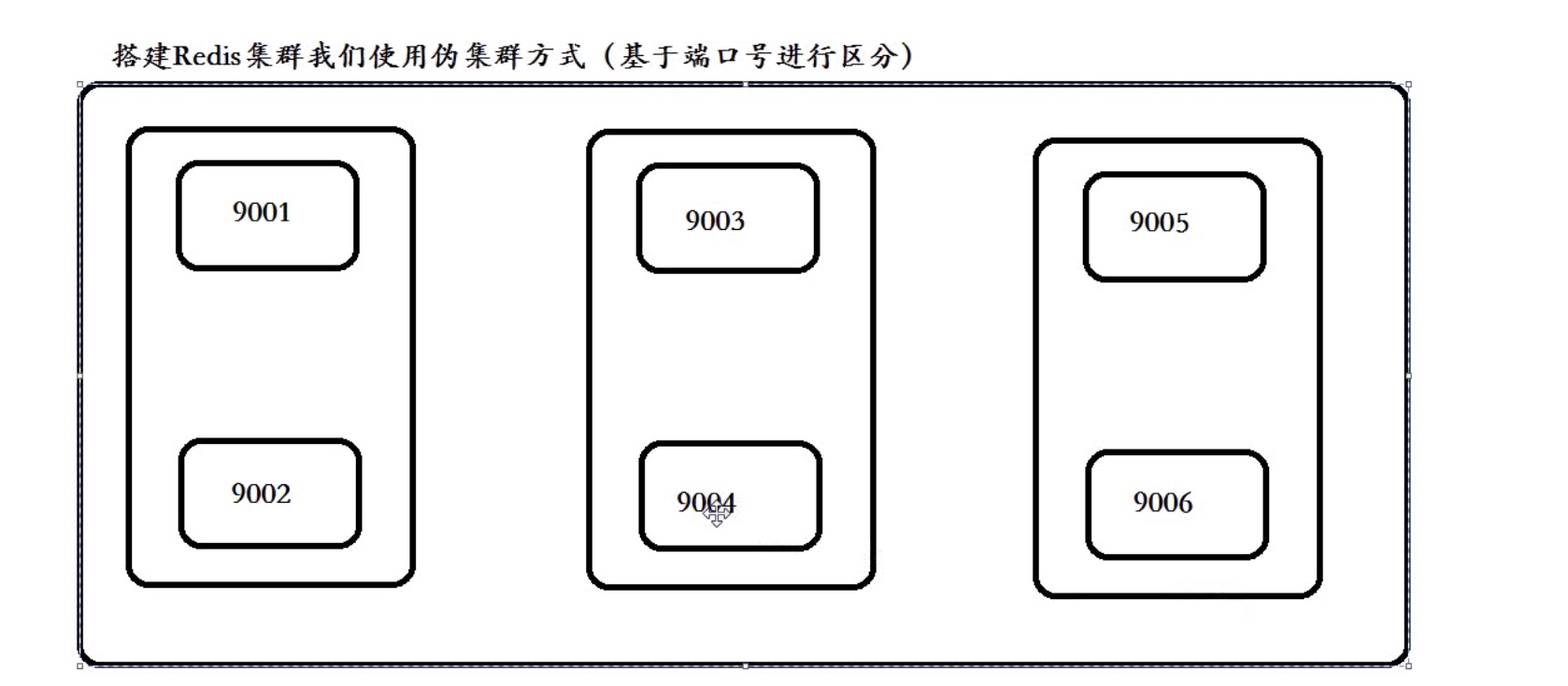
安装部署任何一个应用其实都很简单,只要安装步骤一步一步来就行了。下面说一下 Redis 集群搭建规划,由于集群至少需要6个节点(3主3从模式),所以,如果没有这么多机器,本地也起不了那么多虚拟机(电脑太烂),现在计划是在一台机器上模拟一个集群,当然,这和生产环境的集群搭建没本质区别。
- 安装一个Linux虚拟机,开启Linux,连接Linux
- 先关闭防火墙
- 然后安装纯净版本的redis Redis安装
- 修改redis.conf 文件 将 bind 改为当前Linux服务器的ip地址
- 并将redis改为后台启动。
3.2 创建模拟集群的文件夹
我们计划集群中 Redis 节点的端口号为 9001-9006 ,端口号即集群下各实例文件夹。数据存放在 端口号/data 文件夹中。
mkdir /usr/local/redis-cluster
cd redis-cluster/
mkdir -p 9001/data 9002/data 9003/data 9004/data 9005/data 9006/data

3.3 复制脚本
在 /usr/local/redis-cluster 下创建 bin 文件夹,用来存放集群运行脚本,并把安装好的 Redis 的 src 路径下的运行脚本拷贝过来。看命令:
cd /usr/local/redis-cluster
mkdir bin
cd /usr/local/redis-3.2.9/src
cp mkreleasehdr.sh redis-benchmark redis-check-aof redis-cli redis-server redis-trib.rb /usr/local/redis-cluster/bin

3.4 复制一个新 Redis 实例
##我们现在从已安装好的 Redis 中复制一个新的实例到 9001 文件夹,并修改 redis.conf 配置。
cp -r /usr/local/redis /usr/local/redis-cluster/9001
##注意,修改 redis.conf 配置和单点唯一区别是下面部分,其余还是常规的这几项:
port 9001(每个节点的端口号)
daemonize yes
bind 192.168.140.137(绑定当前机器 IP)
dir /usr/local/redis-cluster/9001/data/(数据文件存放位置)
pidfile /var/run/redis_9001.pid(pid 9001和port要对应)
cluster-enabled yes(启动集群模式)
cluster-config-file nodes-9001.conf(9001和port要对应)
cluster-node-timeout 15000
appendonly yes

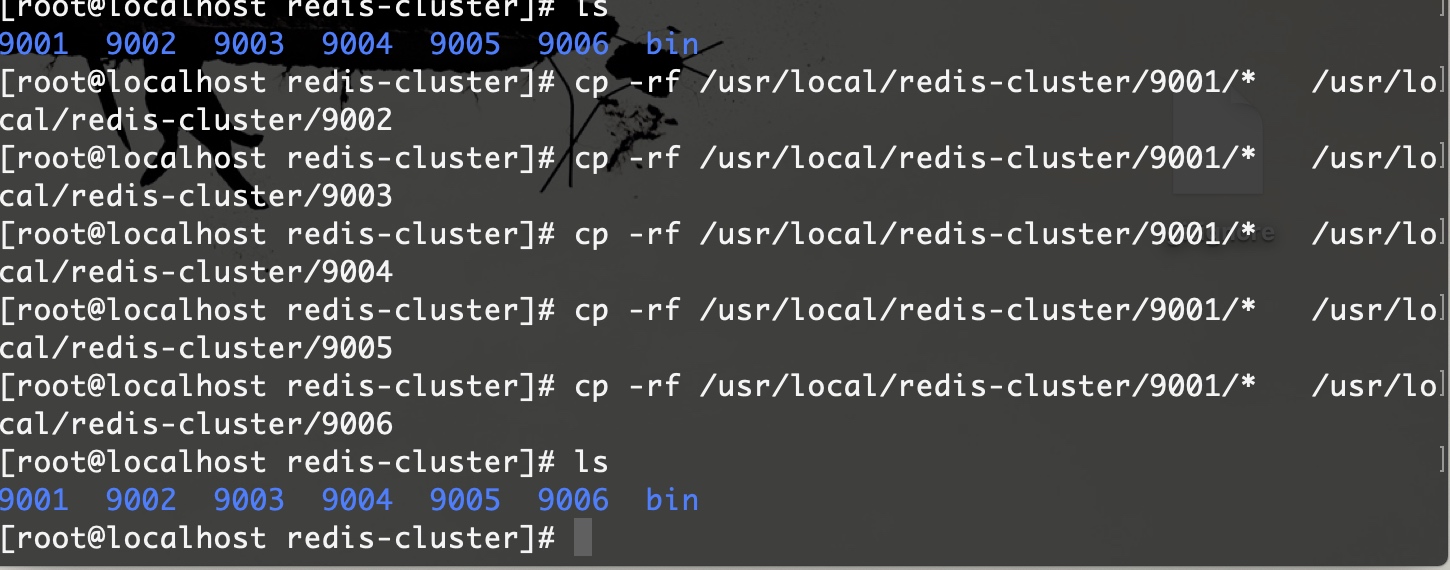
3.5 再复制出五个新 Redis 实例
我们已经完成了一个节点了,其实接下来就是机械化的再完成另外五个节点,其实可以这么做:把 9001 实例 复制到另外五个文件夹中,唯一要修改的就是 redis.conf 中的所有和端口的相关的信息即可,其实就那么四个位置。开始操作:
\cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9002
\cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9003
\cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9004
\cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9005
\cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9006
## \cp -rf 命令是不使用别名来复制,因为 cp 其实是别名 cp -i,操作时会有交互式确认,比较烦人。
3.6 修改 9002-9006 的 redis.conf 文件
其实非常简单了,你通过搜索会发现其实只有四个点需要修改,我们全局替换下吧,进入相应的节点文件夹,做替换就好了。命令非常简单:
vim /usr/local/redis-cluster/9002/redis/etc/redis.conf
vim /usr/local/redis-cluster/9003/redis/etc/redis.conf
vim /usr/local/redis-cluster/9004/redis/etc/redis.conf
vim /usr/local/redis-cluster/9005/redis/etc/redis.conf
vim /usr/local/redis-cluster/9006/redis/etc/redis.conf
:%s/9001/9002
:%s/9001/9003
:%s/9001/9004
:%s/9001/9005
:%s/9001/9006
## 其实我们也就是替换了下面这四行:
port 9002
dir /usr/local/redis-cluster/9002/data/
cluster-config-file nodes-9002.conf
pidfile /var/run/redis_9002.pid
3.7 启动9001-9006六个节点
##这里用了/usr/local/redis/bin/ 目录下的redis服务启动的,
## 也可以使用9001各个目录下的redis服务分别启动
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/9001/redis/etc/redis.conf
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/9002/redis/etc/redis.conf
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/9003/redis/etc/redis.conf
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/9004/redis/etc/redis.conf
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/9005/redis/etc/redis.conf
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/9006/redis/etc/redis.conf
启动成功看下图:

3.8 随便找一个节点测试试
/usr/local/redis-cluster/9001/redis/bin/redis-cli -c -h 192.168.140.137 -p 9001
**添加数据是会报错: **

(error) CLUSTERDOWN Hash slot not served
这是因为虽然我们配置并启动了 Redis 集群服务,但是他们暂时还并不在一个集群中,互相直接发现不了,而且还没有可存储的位置,就是所谓的slot(槽)。
3.9 安装集群所需软件
##由于 Redis 集群需要使用 ruby 命令,所以我们需要安装 ruby 和相关接口。
yum install ruby
yum install rubygems
gem install redis ##执行此行命令会报错, 要使用本地上传方式
下载地址: 安装包GitHub
从本地上传到Linux
将此文件拖到usr/local目录下

文件上传到Linux中后 进入/usr/local/到执行下面的命令
gem install -l redis-3.2.1.gem
3.10集群环境测试
/usr/local/redis-cluster/bin/redis-trib.rb create --replicas 1 192.168.140.137:9001 192.168.140.137:9002 192.168.140.137:9003 192.168.140.137:9004 192.168.140.137:9005 192.168.140.137:9006
执行效果如下,发现有三主三备:

目前来看,9001-9003 为主节点,9004-9006 为从节点,并向你确认是否同意这么配置。输入 yes 后,会开始集群创建。

- 简单解释一下这个命令:调用 ruby 命令来进行创建集群,--replicas 1 表示主从复制比例为 1:1,即一个主节点对应一个从节点;然后,默认给我们分配好了每个主节点和对应从节点服务,以及 solt 的大小,因为在 Redis 集群中有且仅有 16383 个 solt ,默认情况会给我们平均分配,当然你可以指定,后续的增减节点也可以重新分配。
M: fbec3c1091ff20adbabf8d144043cc3abae9a7f9 ##为主节点Id
S: 09726b68f4a1c849e8e188bd45d506aed17fd970 192.168.140.137:9004
slots: (0 slots) slave
replicates fbec3c1091ff20adbabf8d144043cc3abae9a7f9 ##从节点下对应主节点Id
3.11 验证集群环境
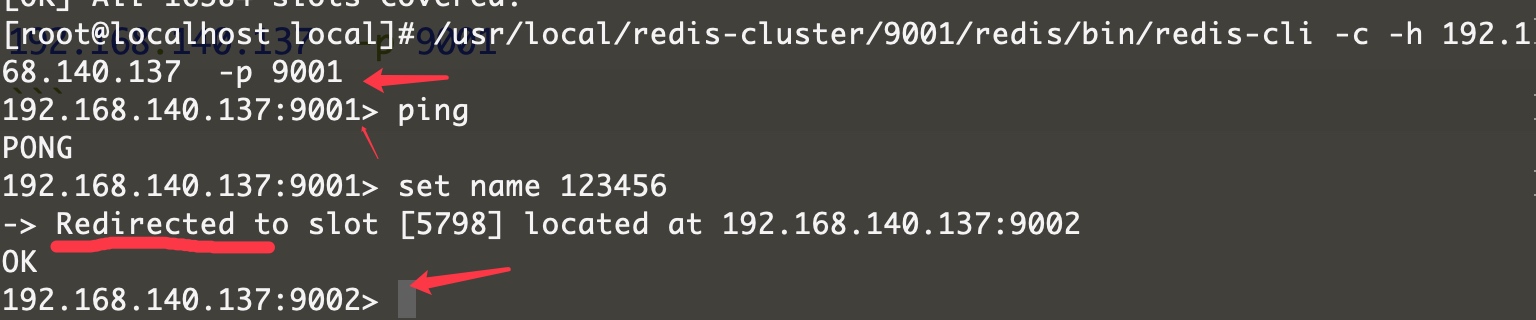
## 这里要输入-c,表示集群环境
/usr/local/redis-cluster/9001/redis/bin/redis-cli -c -h 192.168.140.137 -p 9001
set name 123456 ## 会发现它自动跳转到9002redis上面
3.12 SpringBoot整合Redis集群
spring:
redis:
database: 0
# host: 132.168.44.127
# port: 6379
# password: 123456
jedis:
pool:
max-active: 8
max-wait: -1
max-idle: 8
min-idle: 0
timeout: 10000
cluster:
nodes:
- 192.168.140.137:9001
- 192.168.140.137:9002
- 192.168.140.137:9003
- 192.168.140.137:9004
- 192.168.140.137:9005
- 192.168.140.137:9006
###扩展注册方式 代码获取到配置文件 灵活该密码
四、Redis集群的几个注意事项
- Redis集群使用CRC16对key进行hash,集群固定使用16384对hash出来的值取模。因为取模结果一定在16384之内,所以集群中的sharding(分片)实际就是如何将16384个值在n个主节点间分配(从节点是主节点的近似副本,原因见3),如何分配取决于你的配置。
- Redis生产级集群需要容灾,为此,一般部署为n个主+n*m个从。n大小主要取决于单机性能,m大小主要取决于机器稳定性。
- Redis集群是弱一致性的,此处的一致,主要指主从之间的数据一致性。主要是因为redis在做数据更新时,不要求主从数据同步复制一定要成功。
- 集群最小的主数量为3,主数量应为奇数,以便做选举判决。
五、集群事务
Redis集群默圦是不支持亊各,但是亊各可以在単独节点上可以支持
写插件Redis+Lua
【Redis】集群方式的更多相关文章
- Spring-Session实现Session共享Redis集群方式配置教程
循序渐进,由易到难,这样才更有乐趣! 概述 本篇开始继续上一篇的内容基础上进行,本篇主要介绍Spring-Session实现配置使用Redis集群,会有两种配置方式,一种是Redis-Cluster, ...
- 超详细,多图文介绍redis集群方式并搭建redis伪集群
超详细,多图文介绍redis集群方式并搭建redis伪集群 超多图文,对新手友好度极好.敲命令的过程中,难免会敲错,但为了截好一张合适的图,一旦出现一点问题,为了好的演示效果,就要从头开始敲.且看且珍 ...
- Redis集群方式
Redis有三种集群方式:主从复制,哨兵模式和集群. 1.主从复制 主从复制原理: 从服务器连接主服务器,发送SYNC命令: 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用 ...
- Linux Redis集群搭建与集群客户端实现(Python)
硬件环境 本文适用的硬件环境如下 Linux版本:CentOS release 6.7 (Final) Redis版本: Redis已经成功安装,安装路径为/home/idata/yangfan/lo ...
- Linux Redis集群搭建与集群客户端实现
硬件环境 本文适用的硬件环境如下 Linux版本:CentOS release 6.7 (Final) Redis版本: Redis已经成功安装,安装路径为/home/idata/yangfan/lo ...
- redis的三种集群方式
redis有三种集群方式:主从复制,哨兵模式和集群. 1.主从复制 主从复制原理: 从服务器连接主服务器,发送SYNC命令: 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用 ...
- spring boot下JedisCluster方式连接Redis集群的配置
最近在使用springboot做项目,使用redis做缓存.在外网开发的时候redis服务器没有使用集群配置,所有就是用了RedisTemplate的方式进行连接redis服务器.但是项目代码挪到内网 ...
- Redis集群模式下的redis-py-cluster方式读写测试
与MySQL主从复制,从节点可以分担部分读压力不一样,甚至可以增加slave或者slave的slave来分担读压力,Redis集群中的从节点,默认是不分担读请求的,从节点只作为主节点的备份,仅负责故障 ...
- Redis集群搭建的三种方式
一.Redis主从 1.1 Redis主从原理 和MySQL需要主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生性能瓶颈,特别是在读压力上,为了分担压力,Redis支持主从复制. ...
随机推荐
- 5.Go-封装、继承、接口、多态和断言
面向对象 Go语言开发者认为:面向对象就是特定类型(结构体)有着自己的方法,利用这个方法完成面向对象编程, 并没有提封装.继承.多态.所以Go语言进行面向对象编程时,重点在于灵活使用方法. Go语言有 ...
- 【Java例题】1.3给朋友的贺卡
3.对“Hello World”程序进行改造, 能够显示一张发给朋友的贺卡.格式如下: ****************************** 张三,你好! 祝你学习愉快! 你的好朋友:李四 2 ...
- 使用Yapi展示你的api接口
今天研究了下一款非常好用的api集中展示工具---Yapi,具体网址 https://hellosean1025.github.io/yapi/documents/index.html 如图,看下基本 ...
- 【原创】POI操作Excel导入导出工具类ExcelUtil
关于本类线程安全性的解释: 多数工具方法不涉及共享变量问题,至于添加合并单元格方法addMergeArea,使用ThreadLocal变量存储合并数据,ThreadLocal内部借用Thread.Th ...
- 武林 HDU - 1107
题目链接:https://vjudge.net/problem/HDU-1107 注意:题目中只有两个不同门派的人在同一个地方才能对决,其他情况都不能对决. 还有,这步的有效的攻击只有走到下一步之后才 ...
- Android 使用 DiffUtil 处理 RecyclerView 数据更新问题
背景 RecyclerView.Adapter#notifyDataSetChanged() 会每次刷新整个布局: 每次手动调用 RecyclerView.Adapter#notifyItemXx 系 ...
- 解决H5微信浏览器中audio兼容-- 背景音乐无法自动播放
我们知道,ios 在safari浏览器中,audio标签不能在没有用户交互的情况下自动播放或有js直接控制播放,这是系统限制的一些原因. 但是背景音乐在微信浏览器可以设置自动播放,config配置一下 ...
- ajax方法请求成功后,没有执行success的方法
$.ajax( { type: "POST", url: "AddSupplier.aspx", dataType:"text", data ...
- WPF注册热键后处理热键消息(非winform方式)
由于最近在做wpf版的截图软件,在处理全局热键的时候,发现国内博客使用的都是winform窗体的键盘处理方式,此方式需要使用winform的动态库,如此不协调的代码让我开始在github中寻找相关代码 ...
- Excel VBA 在保留原单元格数据的情况下,将计算的百分比加在后面
算的是红框占绿框的百分比 难点在保留原数据的情况下,把百分比加在后面.通过公式我是不会,但程序实现也不难. 先在Excel中的开发工具中打开visual basic,或者用宏也可以 导入代码文件,代码 ...