Coursera, Big Data 3, Integration and Processing (week 4)
Week 4
Big Data Precessing Pipeline

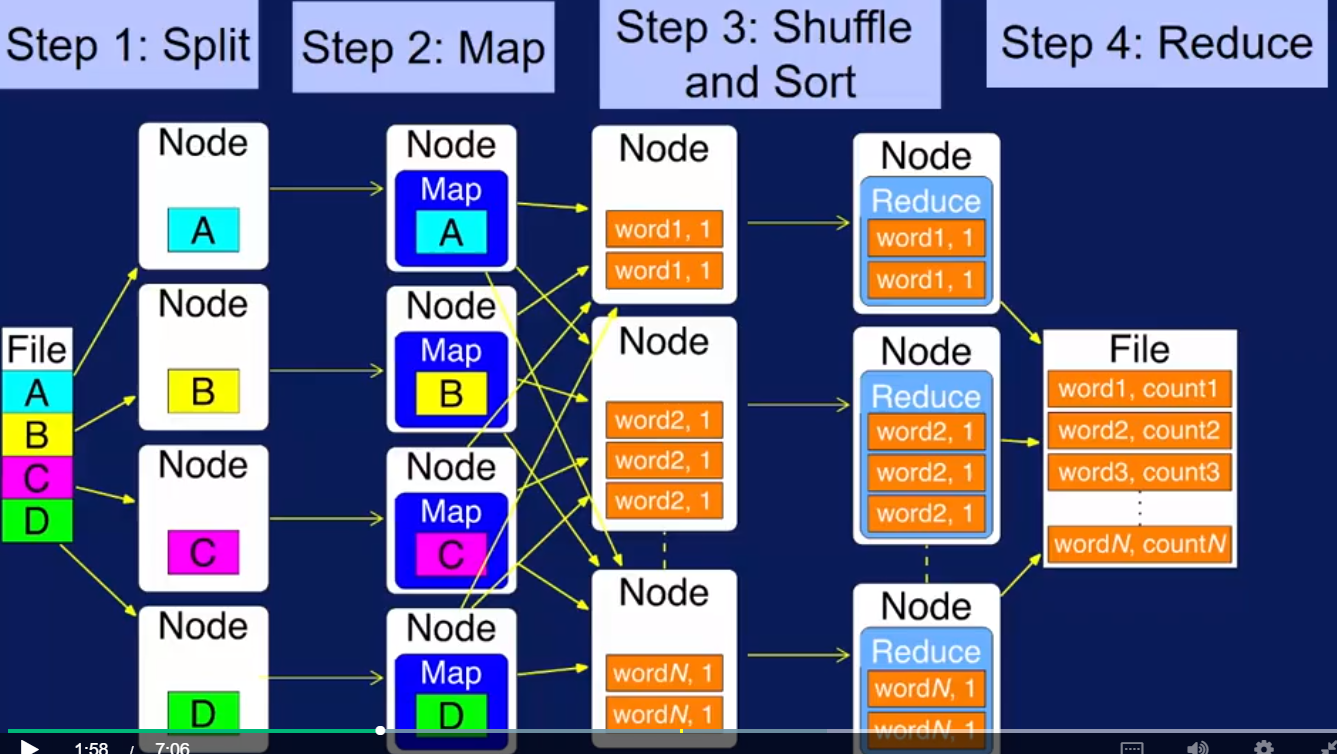

上图可以generalize 成下图,也就是Big data pipeline
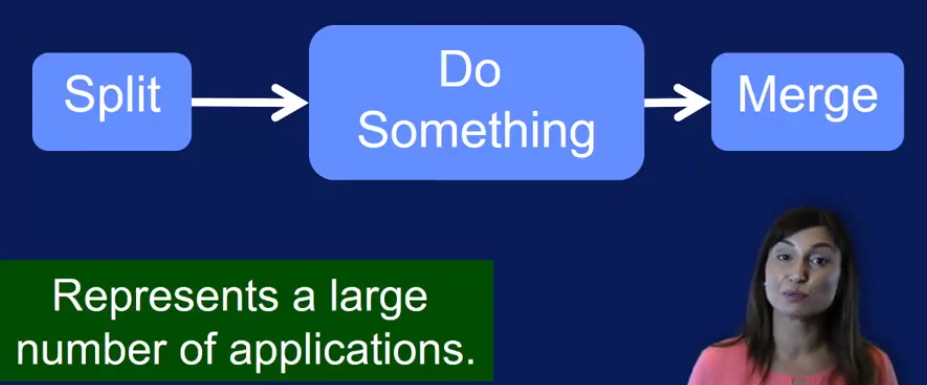
some high level processing operations in big data pipeline
在一个pipeline里 有哪些data transformation 方法?课程上讲了一个类比data transformation的例子,把原木加工成家具.
基本的data transformation 操作有 : Map 是第一个,还有Reduce, Cross/Cartesian, Match/Join, Co-Group, Filter
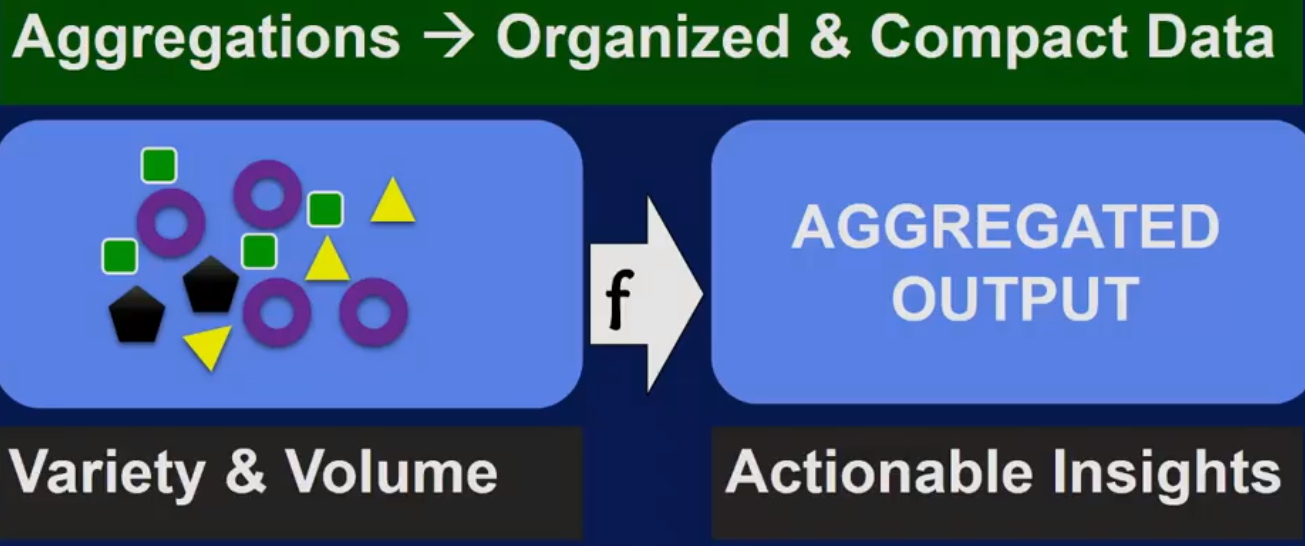
Aggregation opeartions in big data pipeline


比如上图中,每个星星的值是1,求和就是一个aggregation操作,还有对所有星星按颜色分类也是一个aggression操作。 对全部数据求 sum, avg, max, min, std 都是aggression操作
analytical opearations in big data pipeline


Classification - DT
Clustering - K-means
Path analysis - find shortest path from home to work
Connectivity analyasis - graph
Big data processing tool and systems


上面是 big data 的3层结构, 系列课程的整个course 2就是讲最底层的 data management and storage 的. 第二层就是这个course 3 主要讲的内容

Redis, AeroSpike - key value storage
Lucene
Gephi - vector and graph data storage
Vertica, Cassadra, HBase- column store database
Solr, Asterisk DB - for managing unstrunctured and semi-structured text.
mongodb - document store
下面看第二层
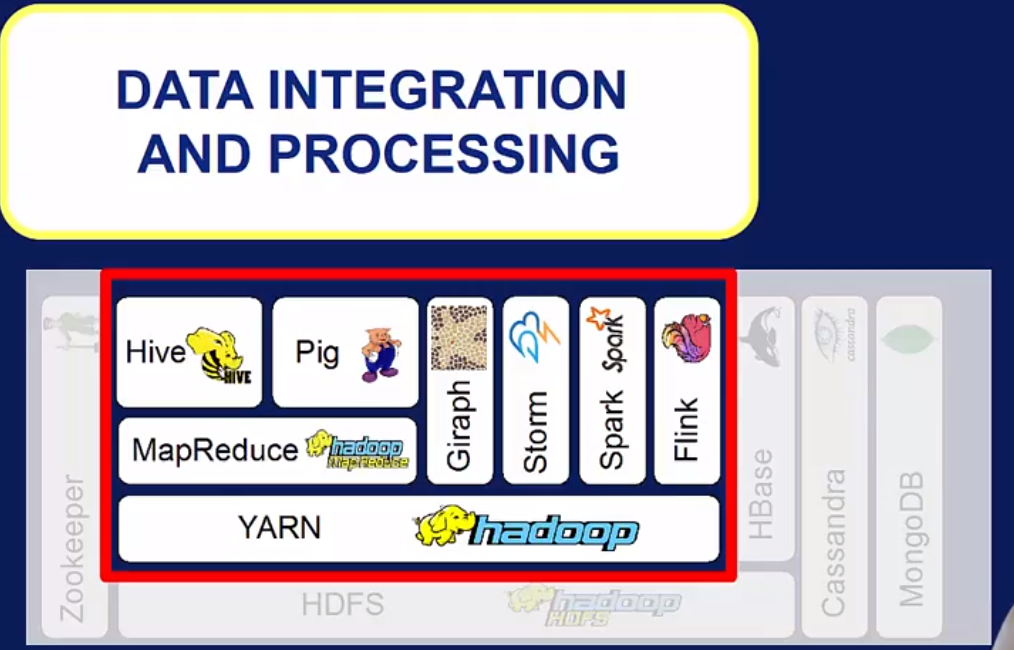
YARN - enabler
Hive, Spark SQL - query interface
Pig - 脚本化使用 Map-Reduce 框架
Giraph, Spark GraphX - graph analytics
Mahout, Spark MLib - machine learning
接下来是第三层
OOZiE - workflow scheduler, 可以和第二层的很多tool 交互
ZooKeeper - Resource coordination and monitoring tool
现在回到第二层,主要讲5个data processing engine

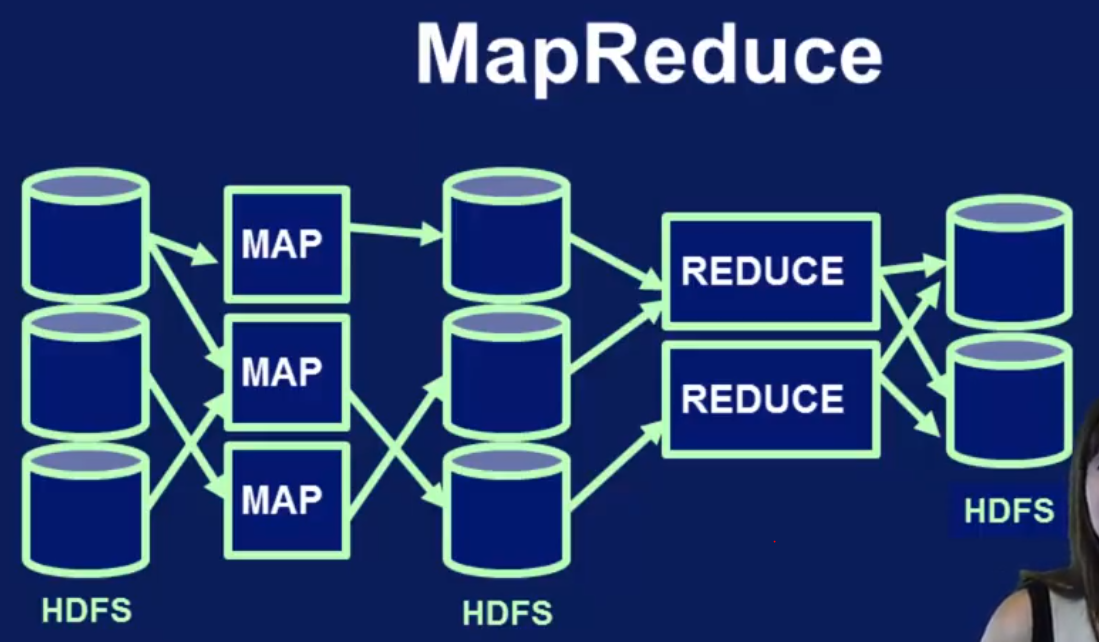
Map-Reduce 从HDFS读数据,没有in-memory 支持,意味着Mapper只能写数据到files然后Reduce去读, 这就导致high letency 和 less scalable. 虽然也有python库但是只有Java可以作为高效编程语言. 
Spark 支持迭代的交互的data processing pipeline. 有in-memory 结构的RDD(Resilient Distributed Datasets)支持, 除了支持 Map, Reduce 还支持Join, Filter 操作. 所有的transformation操作都能放到 RDD里,所有效率很高. 除了能从HDFS读数据,还可以从很多storage platform读数据。可以用micro-batching 技术读取streaming data.

Flink 和Spark 类似,同时提供了连接stream data ingestion engine (比如Kafka, Flume) 的接口. Flink 有自己的 execution engine 叫 Nephele, 它支持在Hadoop上跑,可以在自己的Nephele上跑。 除了支持Map, Reduce, 还支持join, group by. Flink最大的优点是有一个优化器可以自动选择最优模式和实行策略.

Beam, 来自google

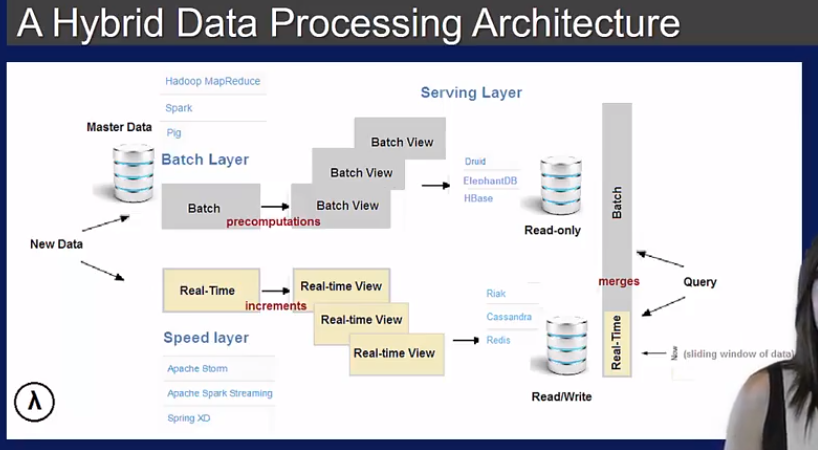
Storm, 提供了输入抽象 spouts 和计算抽象 bolts. Storm 提供了Lambda Architecture, 可以把streaming 处理和 batch 处理分开处理

开始版本的Storm 是下面这样的,batch 和 steam 分开处理
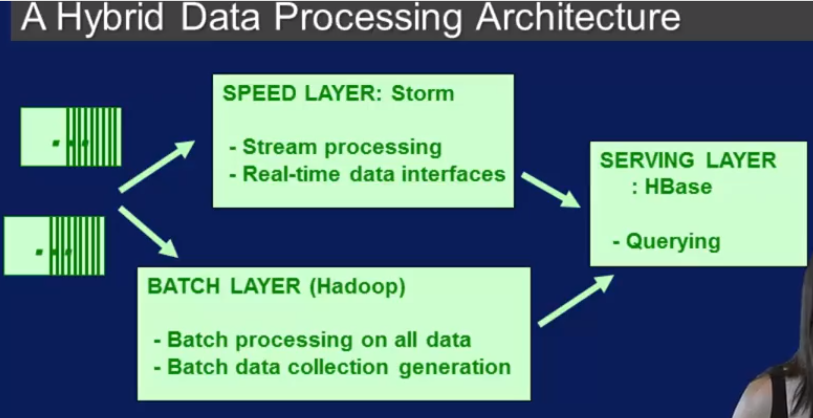
新版本的storm 可以用spark 既处理stream又处理batch.
Dive into Spark

Hadoop 的MapReduce 又弊端,首先它是针对batch processing的,对streaming 不支持,还有它只支持Map 和Reduce两种操作,很多情况下无法满足一个复杂Pipeline的需求

Spark 的优点如下

Spark组件建立在Spark计算引擎上, 其中Spark Core 包括支持分布式调度,内存管理,全容错。和像YARN和Mesos 这样的资源调度器,以及像HBase等各种NoSQL数据库交互都是通过Spark Core.Core 非常重要的一个部分是用来定义RDD的APIs.
Spark SQL 可以通过共同的query languange 查询结构化和非结构化数据.
Spark Streaming 对streaming data 做操作的.
MLlib 是机器学习库
GraphX - 图处理分析库

Getting started with Spark

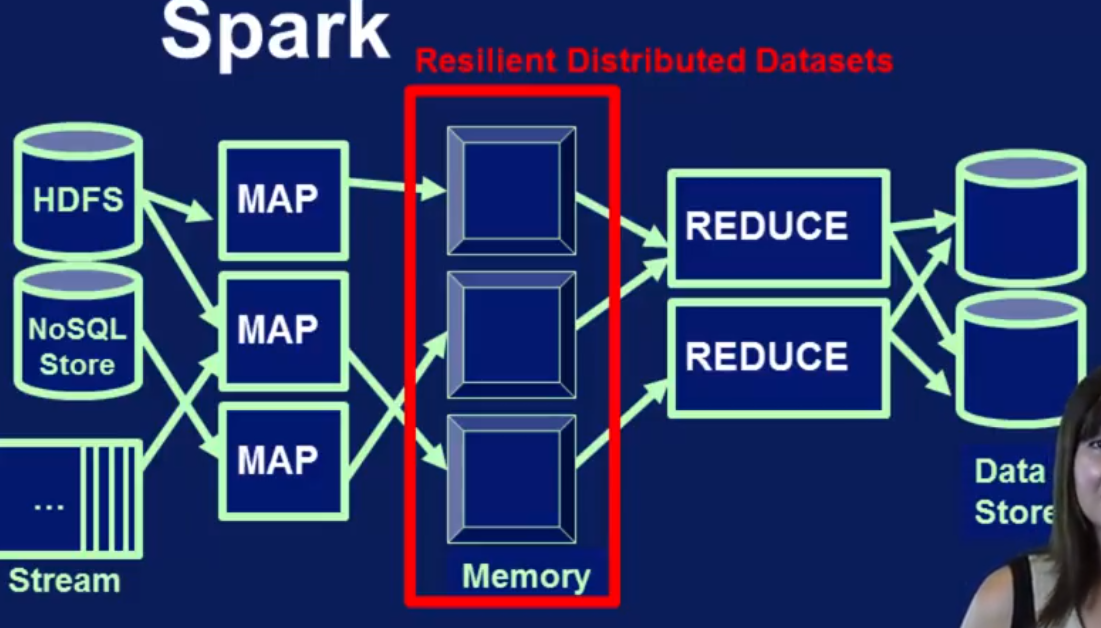



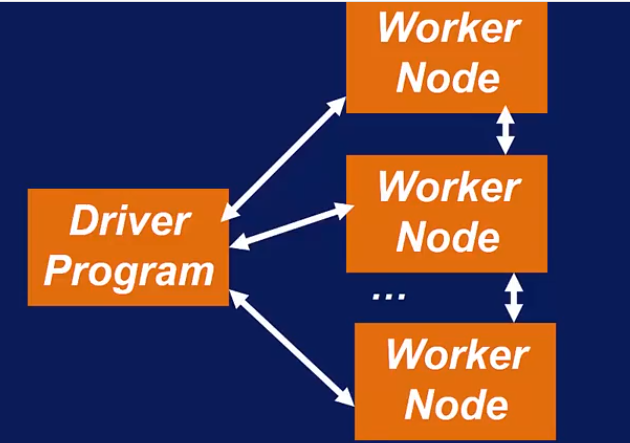
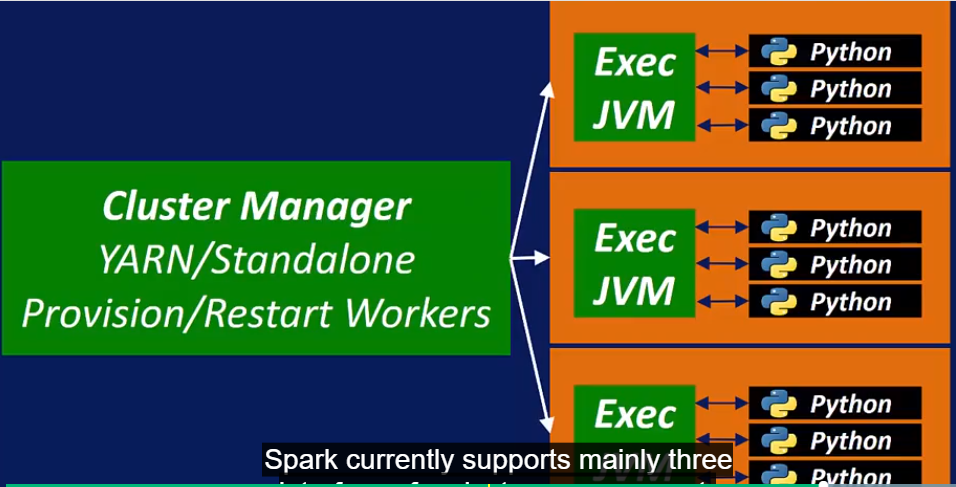
Spark Cluster Manager 支持3种接口: Standalone Cluster Manger, YARN, Mesos.
怎么选 cluster manager, 见下面link.

Summary architecure
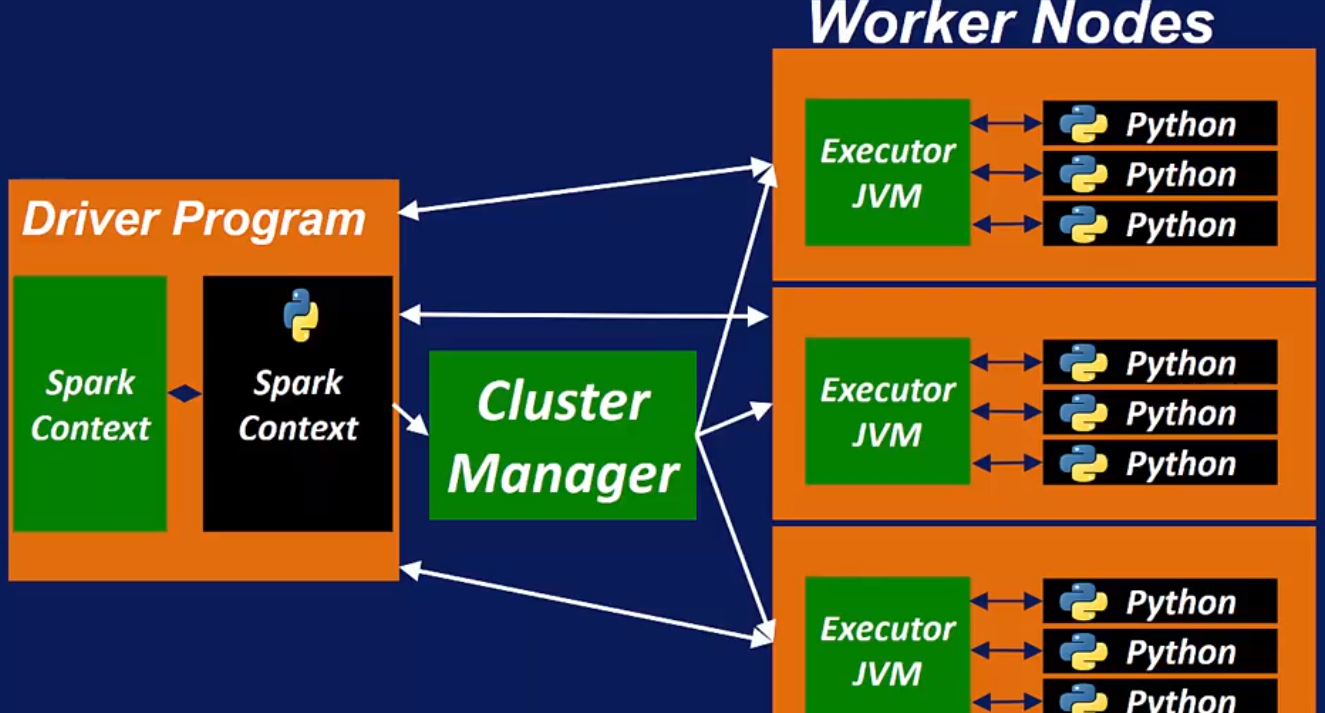
Terms:
neo4j - graph database, 用来查询的query language 叫 Cypher.
Kafka - stream data ingestion engine
Flume - stream data ingestion engine, collects and aggregates log data
Coursera, Big Data 3, Integration and Processing (week 4)的更多相关文章
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4 streaming data format 下面讲 data lakes schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到mode ...
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统? 如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的. ...
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- In-Stream Big Data Processing
http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/ Overview In recent y ...
随机推荐
- me
PXKUNUIN6A- eyJsaWNlbnNlSWQiOiJQWEtVTlVJTjZBIiwibGljZW5zZWVOYW1lIjoi5b285bK4IDEiLCJhc3NpZ25l ZU5hbWU ...
- 数据库的设计:深入理解 Realm 的多线程处理机制
你已经阅读过 Realm 关于线程的基础知识.你已经知道了在处理多线程的时候你不需要关心太多东西了,因为强大的 Realm 会帮你处理好这些,但是你还是很想知道更多细节…… 你想知道在 Realm 的 ...
- P1744 采购特价商品 题解(讲解图论)
图论的超级初级题目(模板题) 最短路径的模板题 图是啥?(白纸上的符号?) 对于一个拥有n个顶点的无向连通图,它的边数一定多于n-1条.若从中选择n-1条边,使得无向图仍然连通,则由n个顶点及这 n- ...
- 《通过C#学Proto.Actor模型》之 HelloWorld
在微服务中,数据最终一致性的一个解决方案是通过有状态的Actor模型来达到,那什么是Actor模型呢? Actor是并行的计算模型,包含状态,行为,并且包含一个邮箱,来异步处理消息. 关于Actor的 ...
- iOS开发基础-九宫格坐标(3)之Xib
延续iOS开发基础-九宫格坐标(2)的内容,对其进行部分修改. 本部分采用 Xib 文件来创建用于显示图片的 UIView 对象. 一.简单介绍 Xib 和 storyboard 的比较: 1) X ...
- 调参必备---GridSearch网格搜索
什么是Grid Search 网格搜索? Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果.其原理就像是在数组里找最 ...
- openstack搭建之-glance配置(9)
一. base节点配置 #设置数据库,创建glance数据库,并设置权限 mysql -u root -proot CREATE DATABASE glance; GRANT ALL PRIVILEG ...
- Mac之brew使用
brew : 终端程序管理工具 能让你更快速的安装你想要的工具.而不用考虑大量的依赖. 安装命令 给官网的一样也可以自己去官网查看 它就类似于centos下的yum 和 Ubuntu下的apt-get ...
- static:get()什么意思
在类里面static关键词相当于self关键词
- IDEA设置本地maven仓库
IDEA设置本地maven仓库 1.下载apache-maven-3.3.9,解压 2.在系统”环境变量“,”系统变量“设置MVN_HOME,如图: 3.在PATH设置,如: %M2_HOME%\bi ...