Pandas 基础(15) - date_range 和 asfreq
这一节是承接上一节的内容, 依然是基于时间的数据分析, 接下来带大家理解关于 date_range 的相关用法.
首先, 引入数据文件:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/15_ts_date_range/aapl_no_dates.csv')
df.head()
输出:
这个文件的数据跟上一节用到的数据是一模一样的(大家可以对照一下), 只是时间列被去掉了. 这样设计是因为我们要引出下面要学到的函数 date_range(), 我们可以通过这个函数把缺少的时间列补上.
设定一个时间范围:
rng = pd.date_range(start='6/1/2017', end='6/30/2017', freq='B')
rng
输出:
DatetimeIndex(['2017-06-01', '2017-06-02', '2017-06-05', '2017-06-06',
'2017-06-07', '2017-06-08', '2017-06-09', '2017-06-12',
'2017-06-13', '2017-06-14', '2017-06-15', '2017-06-16',
'2017-06-19', '2017-06-20', '2017-06-21', '2017-06-22',
'2017-06-23', '2017-06-26', '2017-06-27', '2017-06-28',
'2017-06-29', '2017-06-30'],
dtype='datetime64[ns]', freq='B')
这里对 date_range() 函数一共设置了 3个参数, 前两个很好理解, 分别是开始时间, 结束时间, 最后一个 freq 是关于连续性的设定, 它有几种选择, B 的意思是 business, 也就是只取工作日, 大家可以根据输出结果, 对照着日历看下, 刚好就是省略了周末.
那下面就可以把上面得到的日期序列设为我们数据的索引列, 这个很简答了, 是 pandas 的基础操作:
df.set_index(rng, inplace=True)
输出: 
现在我们的数据表完整了, 有了时间列索引, 我们就可以轻松对数据做很多分析操作了:
求曲线图:
%matplotlib inline
df.Close.plot()
输出:
求6月1日到6月10日的数据:
df['2017-6-1':'2017-6-10']
输出:
求6月1日到6月10日的闭市数据的平均值:
df['2017-6-1':'2017-6-10'].Close.mean()
输出:
153.7642857142857
再介绍 date_range() 的另一种设置时间范围的方法:
设置一个时间序列, 参数说明:
start: 起始日期
periods: 从起始值开始向后顺延的数据条数, 单位取决于第三个数 freq
freq: 连续的方式, B 表示只取工作日
rng = pd.date_range(start='1/1/2017', periods=72, freq='B')
rng
输出:
DatetimeIndex(['2017-01-02', '2017-01-03', '2017-01-04', '2017-01-05',
'2017-01-06', '2017-01-09', '2017-01-10', '2017-01-11',
'2017-01-12', '2017-01-13', '2017-01-16', '2017-01-17',
'2017-01-18', '2017-01-19', '2017-01-20', '2017-01-23',
'2017-01-24', '2017-01-25', '2017-01-26', '2017-01-27',
'2017-01-30', '2017-01-31', '2017-02-01', '2017-02-02',
'2017-02-03', '2017-02-06', '2017-02-07', '2017-02-08',
'2017-02-09', '2017-02-10', '2017-02-13', '2017-02-14',
'2017-02-15', '2017-02-16', '2017-02-17', '2017-02-20',
'2017-02-21', '2017-02-22', '2017-02-23', '2017-02-24',
'2017-02-27', '2017-02-28', '2017-03-01', '2017-03-02',
'2017-03-03', '2017-03-06', '2017-03-07', '2017-03-08',
'2017-03-09', '2017-03-10', '2017-03-13', '2017-03-14',
'2017-03-15', '2017-03-16', '2017-03-17', '2017-03-20',
'2017-03-21', '2017-03-22', '2017-03-23', '2017-03-24',
'2017-03-27', '2017-03-28', '2017-03-29', '2017-03-30',
'2017-03-31', '2017-04-03', '2017-04-04', '2017-04-05',
'2017-04-06', '2017-04-07', '2017-04-10', '2017-04-11'],
dtype='datetime64[ns]', freq='B')
这里就得到了从1月2日开始的72个日期, 这其中是跳过了周末的日期之后, 总共加起来是72天.
下面把第三个参数改下, freq=H, 也就是以小时为单位, 从起始开始, 取72小时:
rng = pd.date_range(start='1/1/2017', periods=72, freq='H')
rng
输出:
DatetimeIndex(['2017-01-01 00:00:00', '2017-01-01 01:00:00',
'2017-01-01 02:00:00', '2017-01-01 03:00:00',
'2017-01-01 04:00:00', '2017-01-01 05:00:00',
'2017-01-01 06:00:00', '2017-01-01 07:00:00',
'2017-01-01 08:00:00', '2017-01-01 09:00:00',
'2017-01-01 10:00:00', '2017-01-01 11:00:00',
'2017-01-01 12:00:00', '2017-01-01 13:00:00',
'2017-01-01 14:00:00', '2017-01-01 15:00:00',
'2017-01-01 16:00:00', '2017-01-01 17:00:00',
'2017-01-01 18:00:00', '2017-01-01 19:00:00',
'2017-01-01 20:00:00', '2017-01-01 21:00:00',
'2017-01-01 22:00:00', '2017-01-01 23:00:00',
'2017-01-02 00:00:00', '2017-01-02 01:00:00',
'2017-01-02 02:00:00', '2017-01-02 03:00:00',
'2017-01-02 04:00:00', '2017-01-02 05:00:00',
'2017-01-02 06:00:00', '2017-01-02 07:00:00',
'2017-01-02 08:00:00', '2017-01-02 09:00:00',
'2017-01-02 10:00:00', '2017-01-02 11:00:00',
'2017-01-02 12:00:00', '2017-01-02 13:00:00',
'2017-01-02 14:00:00', '2017-01-02 15:00:00',
'2017-01-02 16:00:00', '2017-01-02 17:00:00',
'2017-01-02 18:00:00', '2017-01-02 19:00:00',
'2017-01-02 20:00:00', '2017-01-02 21:00:00',
'2017-01-02 22:00:00', '2017-01-02 23:00:00',
'2017-01-03 00:00:00', '2017-01-03 01:00:00',
'2017-01-03 02:00:00', '2017-01-03 03:00:00',
'2017-01-03 04:00:00', '2017-01-03 05:00:00',
'2017-01-03 06:00:00', '2017-01-03 07:00:00',
'2017-01-03 08:00:00', '2017-01-03 09:00:00',
'2017-01-03 10:00:00', '2017-01-03 11:00:00',
'2017-01-03 12:00:00', '2017-01-03 13:00:00',
'2017-01-03 14:00:00', '2017-01-03 15:00:00',
'2017-01-03 16:00:00', '2017-01-03 17:00:00',
'2017-01-03 18:00:00', '2017-01-03 19:00:00',
'2017-01-03 20:00:00', '2017-01-03 21:00:00',
'2017-01-03 22:00:00', '2017-01-03 23:00:00'],
dtype='datetime64[ns]', freq='H')
上面介绍了关于生成日期序列的函数 date_range() 的用法.
下面介绍一下日期序列的补充函数 asfreq(). 在上面的例子中, 数据里缺少了周末的数据, 所以如果想要补充这部分数据的话, 可以用下面的方式. 上面的代码中, 参数 D 表示以"天"为单位, 连续取值:
df.asfreq('D', method='pad')
输出:
参数 W 表示以"周"为单位, 连续取值:
df.asfreq('W', method='pad')
输出: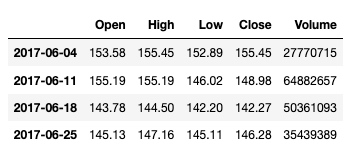
参数 H 表示以"小时"为单位, 连续取值:
df.asfreq('H', method='pad')
输出:
在 1 到10范围内取72个随机数:
import numpy as np
np.random.randint(1,10,len(rng))
输出:
array([1, 2, 5, 6, 6, 5, 9, 8, 3, 2, 5, 8, 9, 4, 5, 4, 9, 9, 4, 9, 9, 8,
5, 3, 2, 8, 3, 9, 8, 7, 8, 4, 8, 8, 8, 4, 4, 5, 1, 1, 3, 8, 3, 2,
9, 6, 5, 8, 2, 7, 5, 7, 5, 1, 5, 6, 6, 3, 4, 4, 4, 3, 5, 3, 3, 9,
1, 2, 8, 7, 9, 6])
把上面的 72 个数生成一个序列, 以上面的时间序列为索引:
ts=pd.Series(np.random.randint(1,10,len(rng)), index=rng)
ts.head(10)
输出:
2017-01-01 00:00:00 7
2017-01-01 01:00:00 9
2017-01-01 02:00:00 4
2017-01-01 03:00:00 3
2017-01-01 04:00:00 3
2017-01-01 05:00:00 8
2017-01-01 06:00:00 7
2017-01-01 07:00:00 8
2017-01-01 08:00:00 2
2017-01-01 09:00:00 2
Freq: H, dtype: int64
以上是关于时间序列的第二小节, 下节会继续哦, enjoy~~~~
Pandas 基础(15) - date_range 和 asfreq的更多相关文章
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- [.net 面向对象编程基础] (15) 抽象类
[.net 面向对象编程基础] (15) 抽象类 前面我们已经使用到了虚方法(使用 Virtual修饰符)和抽象类及抽象方法(使用abstract修饰符)我们在多态一节中说到要实现类成员的重写必须定义 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
随机推荐
- C#基础加强(6)之引用相等与运算符重载
引用相等 介绍 在 C# 中可以通过 object.ReferenceEquals(obj1, obj2) 方法来判断两个变量引用的是不是同一个地址,如果是,那么就是引用相等. 引用相等是针对引用类型 ...
- python 小试一题
a = 66count = 1while count <=3 : b = int(input("猜测这个数字:")) if b < a: print("猜测的 ...
- 获奖感想与Java阶段性学习总结
获奖感想 其实我早就知道有小黄衫这个东西,而且它就在我的目标清单里,不过没想到娄老师发的这么早.我想小黄衫代表着的是老师对我这一阶段来学习成果和努力的肯定,虽然Java学习中付出很多时间精力,现在也值 ...
- table添加正确的样式
以前在做表格的时候,会在表格<table>标签中添加一些属性,来改变表格的样式,经常用到的有这几个 width 表格的宽度border 表格边框的宽度cellpadding 单元边沿与其 ...
- memcached----------linux下安装memcached,以及php的memcached扩展。
1.通过wget http://www.memcached.org/files/memcached-1.4.24.tar.gz下载最新源码2.解压tar -xf memcached-1.4.24.ta ...
- 工具方法: jQuery.方法() $.extend (小计)
$.extend(布尔值,目标对象,合并对象,……) 布尔值 : true,深拷贝(递归拷贝) false,浅拷贝(非递归拷贝) ...
- 【Access】数据库四门功课--[增删改查]基础篇
一.增 以userinfo为例 1.增加一条完整的数据 INSERT INTO userinfo VALUES (1, 2, 3, 4); 基本格式:INSERT INTO AAA VALUES (X ...
- debugging kubernetes (Delve and Goland)
1. Build from source cd GOPATH mkdir k8s.io cd k8s.io git clone https://github.com/kubernetes/kubern ...
- SlidingMenu第一篇 --- 导入SlidingMenu库
1. 下载地址:https://github.com/jfeinstein10/SlidingMenu 2. 找到下载好的SlidingMeun的library目录 3. 导入库(将上述地址复制到 ...
- Windows下安装Redis服务
说明:本文拷贝自https://jingyan.baidu.com/article/0f5fb099045b056d8334ea97.html Redis是有名的NoSql数据库,一般Linux都会默 ...