arm浮点运算
首先总结一下计算机中的浮点数的存储。
浮点数的标准是IEEE-754,规定了浮点数的存储都是通过科学计算法来存储的,n2-e的表示。
浮点数首先分为,定浮点(fixed-point)和浮点(float-point),定浮点就是说e的值是不变的。
目前浮点的计算都是将浮点转换为定浮点来计算,由此衍生出,单精度浮点和双精度浮点。
浮点数的存储,前半部分表示exponent(可以是负数,使用补码表示),后半部分表示fraction(规定fraction必须是1.x的格式)。
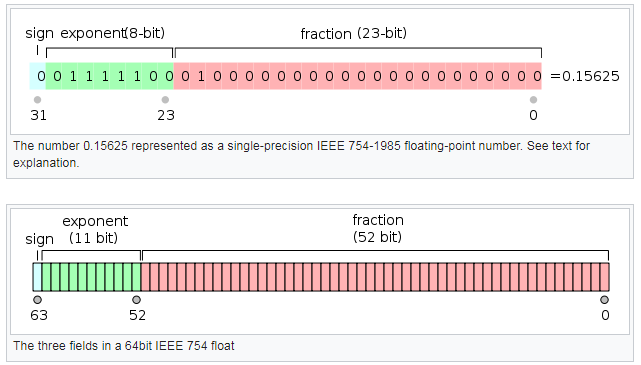
单精度的储存位宽是32bit,e占8bit,最大表示-127----128,fraction占23bit。
双精度的存储位宽是64bit,e占11bit,最大表示-1023---1024,fraction占52bit。
e的表示采用以偏置形式表示的有符号整数,单精度的e,计算应该表示为e+127从而消除负数。双精度的e,计算应该表示为e+1023。
fraction采用小数的表示方法,小数点之前除2得余数为二进制表示。小数点之后乘2得整数部分未二进制表示:
176.0625表示为单精度浮点数,
176/2 得 88,余0
88/2 得 44,余0
44/2 得 22,余0
22/2 得 11,余0
11/2 得 5, 余1
5/2 得2, 余1
2/2 得1, 余0
1/2 得0, 余1 商为零结束。
小数点之前的表示为1011_0000
0.0625*2 得0.125, 整数部分为0
0.125*2 得0.25, 整数部分为0
0.25*2 得0.5, 整数部分为0
0.5*2 得1, 整数部分为1,小数部分为0,结束。
小数点之后的表示为0001。(小数部分不一定可以被准备的表示出来,小数以5结尾为必要条件)
176.0625表示为单精度浮点数,1011_0000.0001
比如1.01 X 2-3,其中exponent表示-3+127=124(0111_1100),.01表示fraction。
单精度和双精度的,精度对比:

浮点数的规则化(normalized):
fraction必须是|1.x|的格式;
非规则化的数:
正零:所有bit都为0;
负零:除了符号位,都为0;
无穷大:exponent的所有bit都为1;fraction的所有值都为0;
负无穷大:exponent的所有bit都为1;fraction的所有值都为0,符号位为1;
非法数值:exponent的所有bit都为1;fraction的值不全为0;NaN(Not a Number)
浮点数的计算:
1)判断是否有操作数为0;
2)对阶:小阶向大阶对齐,阶小的那个数(看正负),exponent加n,fraction右移n位。
3)加减运算,fraction做加减运算,exponent不变。
4)结果规格化。(这时会有舍入处理,IEEE754规定了几种舍入)
判断溢出,浮点只有exponent的上溢,(正数相加不为负,负数相加不为正);
加减:
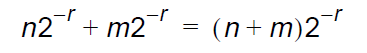
乘法:
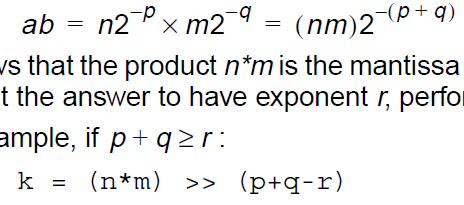
除法:

平方根:
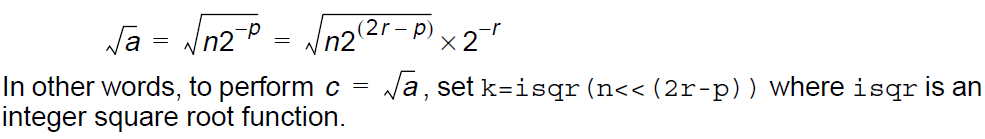
Basic op:


arm的vfp实现有vfpv3和vfpv4两种,vfpv4相比较与vfpv3主要增加了half-precision extension和乘加的指令。
arm的vfp可以实现为32个或16个double-word register,分别以vfpv3-D32和vfpv3-D16来表示。 但是neon和vfp同时实现时,vfp只可以实现为vfp-D32。
vfp的主要控制寄存器:
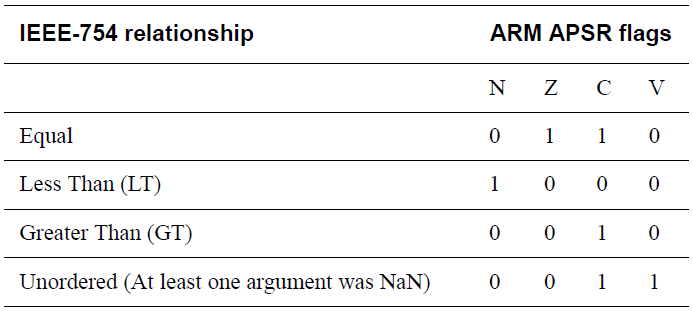
1) FPSCR(Status Control reg),保存FP运算之后的flags,rounding options,enable exception trapping。
VCMP d0,d1
VMRS APSR_nzcv, FPSCR,将SCR中的flags加载到apsr中,才能进行比较指令的跳转
BNE label
2) FPEXC(Exception reg),处理各种exception,包括FP计算过程中的overflow,underflow,inexact(需要进行rounding),invalid(NaN),Division by zero等,
硬件FP单元的使用,需要在编译器(gcc)中进行选项标注:
1) -mfpu=vfp/neon/vfpv3/vfpv4/vfpv4-d16等。指明硬件FP单元;
2) -mfloat-abi = softfp、hardfp,指明abi接口,进行正常的context switching过程中的寄存器进栈出栈。
如果是arm compiler,需要的选项,--fpu=vfpv3/vfpv3_d14等,--apcs=/hardfp或者/softfp等。
arm的SIMD指令的发展:
SIMD,一般应用在数据量较大的场合,使用一条指令,加载多个同样type和size的数据,并对数据进行并行处理;
例如,2个32bit的数据加法,被替换为,4个8bit的数据加法。
armv6,提出一些SIMD的指令,将多个16bit,8bit的数据加载到32bit寄存器中,但是并没有单独的执行单元,
也没有单独的流水线。指令名字就是在之后加16或8的后缀。使用32bitSIMD。
armv7,引入了advanced SIMD,定义了自己的向量寄存器,32*64bit register file,自己的流水线执行单元。这些SIMD的扩展被称为NEON。
向量寄存器,是一组64bit的双字,或128bit的四字,使用64bit或者128bit的SIMD。
NEON指令可以实现:
1) 存储空间访问;
2) 在NEON和general寄存器之间的数据copy;
3) 数据类型转换;
4) 数据计算;支持8bit(vido image的pixel data),16bit(audio codecs data),32bit,64bit的符号数整型,32bit/16bit的单精度浮点,
neon可以和vfp同时使用,但由于寄存器是公用的,vfp必须实现为D32 form,
V7中NEON与VFP的计算对比:
1) NEON是SIMD指令,主要处理vector数据,并行度也高(最多是4),vfp是scalar指令,SISD的形式处理FP。
2) VFP支持全IEEE754的标准,NEON只支持单精度浮点,不支持square root或者divide。
NEON指令:
VADD.I16 q0, q1, q2,表示使用8个16bit的并行加,
VMULL.S16, Q0, D2, D3,表示使用4个16bit的并行乘,
NEON在使用gcc编译器时的选项:
1) 编译汇编(指明abi接口和fpu接口),arm-none-linux-gnueabi-as -mfpu=neon asm.s
2) 关联函数intrinsics, #include <arm_neon.h>
uint32x4_t double_elements(uint32x4_t input)
{ return(vaddq_u32(input, input));
}
arm-none-linux-gnueabi-gcc -mfpu=neon intrinsic.c
3) 优先矢量化(尽可能的使用SIMD来提高性能),arm-none-linux-gnueabi-gcc -mfpu=neon -ftree-vectorize -c vectorized.c
4) 使用优化库,OpenMAX,需要下载安装,程序中加入头文件,#include <omxSP.h>
VFP在使用时,与NEON的编程类似,寄存器一部分是共享的。
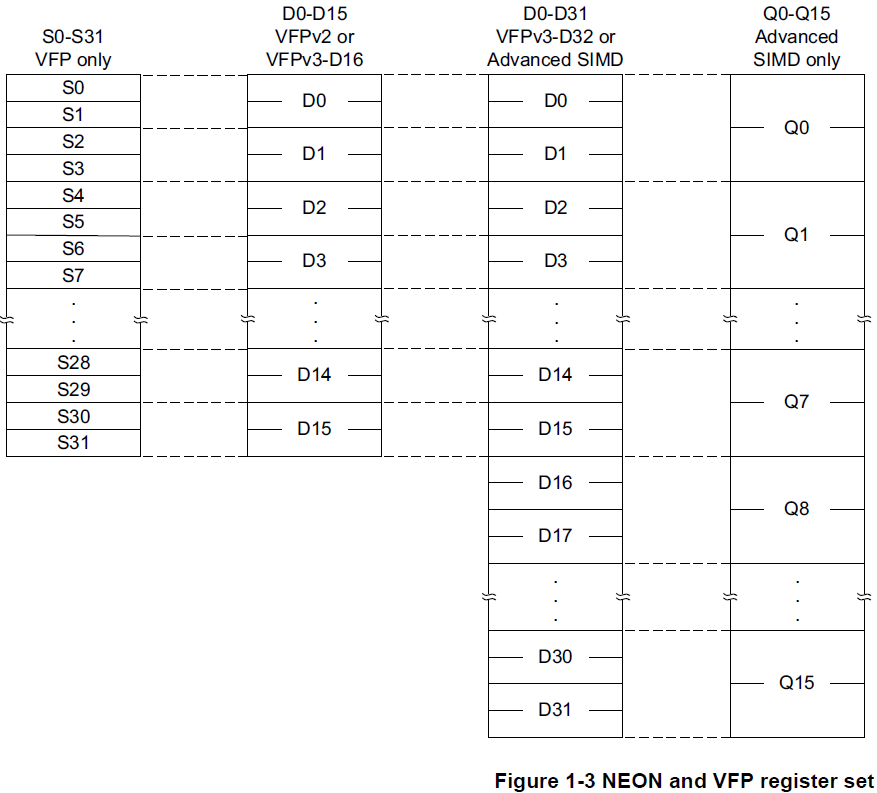
在armv8中,有分别针对aarch32(等同于v7)和aarch64的NEON指令;v8中的aarch64中使用32*128bit的register file;
v8中FP和NEON均作为一个标准部件,继承在core内部。
aarch64中的neon完全支持IEEE754标准的所有FP操作,双精度,NaN handling,rounding等。
在v8中,neon指令和fp指令与a64的指令相同,根据之后的操作数寄存器来区分(v7中neon,fp指令前加v):

arm浮点运算的更多相关文章
- ARM 浮点运算
转载: http://www.embedu.org/Column/Column821.htm http://blog.sina.com.cn/s/blog_602f87700100r5xe.html ...
- iOS程序破解——ARM汇编基础
原文在此:http://www.cnblogs.com/mddblog/p/4951650.html 一.Thumb指令与ARM指令 Thumb指令为16位,因此存储代码的密度高,节省存储空间.但是功 ...
- ARM、Intel、MIPS处理器啥区别?看完全懂了
安卓支持三类处理器(CPU):ARM.Intel和MIPS.ARM无疑被使用得最为广泛.Intel因为普及于台式机和服务器而被人们所熟知,然而对移动行业影响力相对较小.MIPS在32位和64位嵌入式领 ...
- ARM、Intel、MIPS处理器啥区别?看完全懂了【转】
转自:http://news.mydrivers.com/1/472/472317.htm 安卓支持三类处理器(CPU):ARM.Intel和MIPS.ARM无疑被使用得最为广泛.Intel因为普及于 ...
- ARM与x86之3--蝶变ARM
http://blog.sina.com.cn/s/blog_6472c4cc0100lqr8.html 蝶变ARM 1929年开始的经济大萧条,改变了世界格局.前苏联的风景独好,使得相当多的人选择了 ...
- ARM NEON编程系列1-导论
ARM NEON 编程系列1 - 导论 前言 本系列博文用于介绍ARM CPU下NEON指令优化. 博文github地址:github 相关代码github地址:github NEON历史 ARM处理 ...
- arm交叉编译器gnueabi、none-eabi、arm-eabi、gnueabihf、gnueabi区别
命名规则 交叉编译工具链的命名规则为:arch [-vendor] [-os] [-(gnu)eabi] arch – 体系架构,如ARM,MIPSvendor – 工具链提供商os – 目标操作系统 ...
- MPlayer在ARM上的移植(S5PV210开发板)
MPlayer 1.0已经把大部分解码库都自带了,如ffmpeg,但是自带的音频库在S5PV210下效果非常不好.换成使用libmad效果不错.因此MPlayer 在ARM-Linux的最简单的移植只 ...
- ARM指令协处理器处理指令
ARM支持16个协处理器,在程序执行过程中,每个协处理器忽略属于ARM处理器和其他协处理器指令,当一个协处理器硬件不能执行属于她的协处理器指令时,就会产生一个未定义的异常中断,在异常中断处理程序中,可 ...
随机推荐
- Python基础——切片实例
切片实例 L = list(range(100)) print(L, end=' ') [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 1 ...
- Python 小知识 杂七杂八 随手记
1.assert 断言语句 例1: print ‘11111111111’ assert 1==2 print ‘22222222’ 如果没有 assert 程序会输出 ‘1111111111 ...
- php实现根据字符串生成对应数组的方法
先看看如下示例: <?php $config = array( 'project|page|index' => 'content', 'project|page|nav' => ar ...
- Java 多线程 sleep()方法与yield()方法的区别
sleep()方法与yield()方法的区别如下: 1 是否考虑线程的优先级不同 sleep()方法给其他线程运行机会时不考虑线程的优先级,也就是说,它会给低优先级的线程运行的机会.而yield()方 ...
- LeetCode第二题
题目描述: You are given two non-empty linked lists representing two non-negative integers. The digits ar ...
- ES6 模块机制
ES6 实现了模块功能 将文件当作独立的模块,一个文件一个模块 每个模块可以导出自己的API成员,也可以导入其他模块或者模块中特定的API ES6 模块的设计思想,是尽量的静态化,使得编译时就能确定模 ...
- JSON.stringify 语法实例讲解+easyui data-options属性+expires【申明:来源于网络】
JSON.stringify 语法实例讲解+easyui data-options属性+expires[申明:来源于网络] JSON.stringify 语法实例讲解:http://www.jb51. ...
- Ubuntu16.04更新python3.5到python3.7
下载wget https://www.python.org/ftp/python/3.7.1/Python-3.7.1rc2.tgz 解压tar zxvf Python-3.7.1rc2.tgzcd ...
- 基础作业 本周没上课,但是请大家不要忘记学习。 本周请大家完成上周挑战作业的第一部分:给定一个整数数组(包含正负数),找到一个具有最大和的子数组,返回其最大的子数组的和。 例如:[1, -2, 3, 10, -4, 7, 2, -5]的最大子数组为[3, 10, -4, 7, 2] 输入: 请建立以自己英文名字命名的txt文件,并输入数组元素数值,元素值之间用逗号分隔。 输出 在不删除原有文件内容
1丶 实验代码 #include<stdio.h> int main(void) { int tt,nn,i,j,c[11][11]; int flag=1; scanf("%d ...
- 转:彻底搞清楚javascript中的require、import和export
原文地址:彻底搞清楚javascript中的require.import和export 为什么有模块概念 理想情况下,开发者只需要实现核心的业务逻辑,其他都可以加载别人已经写好的模块. 但是,Ja ...