Hadoop集群搭建-HA高可用(手动切换模式)(四)
步骤和集群规划
1)保存完全分布式模式配置
2)在full配置的基础上修改为高可用HA
3)第一次启动HA
4)常规启动HA
5)运行wordcount
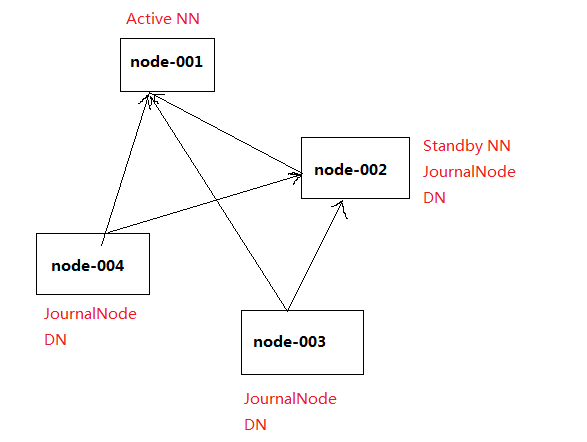
集群规划:
centos虚拟机:node-001、node-002、node-003、node-004
node-001:Active NN、JournalNode、resourcemanger
node-002:Standby NN、DN、JournalNode、nodemanger
node-003:DN、JournalNode、nodemanger
node-004:DN、JournalNode、nodemanger
一、保存full完全分布式配置
cp -r hadoop/ hadoop-full
二、修改配置成为HA(yarn部署)
主要修改core-site.xml、hdfs-site.xml、yarn-site.xml
1.修改core-site.xml文件
<configuration> <property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> </configuration>
2.修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--定义nameservices逻辑名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--映射nameservices逻辑名称到namenode逻辑名称-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--映射namenode逻辑名称到真实主机名称(RPC)-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node-001:8020</value>
</property>
<!--映射namenode逻辑名称到真实主机名称(RPC)-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node-002:8020</value>
</property>
<!--映射namenode逻辑名称到真实主机名称(HTTP)-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node-001:50070</value>
</property>
<!--映射namenode逻辑名称到真实主机名称(HTTP)-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node-002:50070</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/lims/bd/hdfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/lims/bd/hdfs/data</value>
<description>Determines where on the local filesystem an DFS data node
should store its blocks. If this is a comma-delimited
list of directories, then data will be stored in all named
directories, typically on different devices.
Directories that do not exist are ignored.
</description>
</property> <!--配置journalnode集群位置信息及目录-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node-002:8485;node-003:8485;node-004:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/lims/bd/hdfs/journal</value>
</property>
<!--配置故障切换实现类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--指定切换方式为SSH免密钥方式-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/lims/.ssh/id_dsa</value>
</property>
<!--设置自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>false</value>
</property>
</configuration>
3.用scp分发到各个节点
scp hadoop/* lims@node-002:/home/lims/bd/hadoop-2.8.5/etc/hadoop
scp hadoop/* lims@node-003:/home/lims/bd/hadoop-2.8.5/etc/hadoop
scp hadoop/* lims@node-004:/home/lims/bd/hadoop-2.8.5/etc/hadoop
三、第一次启动HA
1)分别在node-002,node-003,node-004三个节点启动journalnode
hadoop-daemon.sh start journalnode
2)在node-001上格式化namenode
hdfs namenode -format
3)在node-001上启动namenode
hadoop-daemon.sh start namenode
4)在node-002,即另一台namenode上同步nn1的CID等信息
hdfs namenode -bootstrapStandby
5)在node-001上启动其他服务
start-dfs.sh
5)手动切换node-001为active状态
hdfs haadmin -transitionToActive nn1
四、常规启动HA
1)启动hdfs
start-dfs.sh
2)启动yarn
start-yarn.sh
Hadoop集群搭建-HA高可用(手动切换模式)(四)的更多相关文章
- EMQ集群搭建实现高可用和负载均衡(百万级设备连接)
一.EMQ集群搭建实现高可用和负载均衡 架构服务器规划 服务器IP 部署业务 作用 192.168.81.13 EMQTTD EMQ集群 192.168.81.22 EMQTTD EMQ集群 192. ...
- Flink 集群搭建,Standalone,集群部署,HA高可用部署
基础环境 准备3台虚拟机 配置无密码登录 配置方法:https://ipooli.com/2020/04/linux_host/ 并且做好主机映射. 下载Flink https://www.apach ...
- Redis操作及集群搭建以及高可用配置
NoSQL - Redis 缓存技术 Redis功能介绍 数据类型丰富 支持持久化 多种内存分配及回收策略 支持弱事务 支持高可用 支持分布式分片集群 企业缓存产品介绍 Memcached: 优点:高 ...
- 2-20 MySQL集群搭建实现高可用
MySQL集群概述和安装环境 MySQL Cluster是MySQL适合于分布式计算环境的高实用.高冗余版本.Cluster的汉语是"集群"的意思.它采用了NDB Cluster ...
- Storm集群开启HA高可用
Storm开启HA高可用,包括Nimbus和UI开启两个及以上的进程. 基于已经安装好的Storm集群,开启关键节点角色的HA高可用. Storm安装请参考Storm集群安装Version1.0.1 ...
- flink的集群的HA高可用
对于一个企业级的应用,稳定性是首要要考虑的问题,然后才是性能,因此 HA 机制是必不可少的: 和 Hadoop 一代一样,从架构中我们可以很明显的发现 JobManager 有明显的单点问题(SPOF ...
- activeMQ集群搭建及高可用
三台服务器搭建如下的集群,达到了高可用.也同时达到了负载的目的: /****************************************************************** ...
- Redis5以上版本伪集群搭建(高可用集群模式)
redis集群需要至少要三个master节点,我们这里搭建三个master节点,并且给每个master再搭建一个slave节点,总共6个redis节点,这里用一台机器(可以多台机器部署,修改一下ip地 ...
- Hadoop 集群搭建和维护文档
一.前言 -- 基础环境准备 节点名称 IP NN DN JNN ZKFC ZK RM NM Master Worker master1 192.168.8.106 * * * * * * maste ...
随机推荐
- 7个提升Python程序性能的好习惯
原文作者:爱coding,会编程的核电工程师. 个人博客地址:zhihu.com/people/zhong-yun-75-63 掌握一些技巧,可尽量提高Python程序性能,也可以避免不必要的资源浪费 ...
- C - Heavy Transportation && B - Frogger(迪杰斯变形)
Background Hugo Heavy is happy. After the breakdown of the Cargolifter project he can now expand bus ...
- JAVA 数组作为方法返回值—返回地址
package Code411;/*一个方法可以有0,1,多个 参数,但只能有0和1个返回值希望一个方法产生多个结果数据进行返回 数组作为方法的参数,传递进去的是数组的地址值. */public cl ...
- 常用函数php
//随机数 /** * @param int $length 随机数长度 * @param string $num 是否只包含数字 * @return null|string 返回随机字符串 */ f ...
- vertx模块DeploymentManager部署管理器
DeploymentManager public DeploymentManager(VertxInternal vertx) { this.vertx = vertx; loadVerticleFa ...
- C++中的const总结
CONST 一.符号常量 声明: const 类型说明符 常量名 = 常量值: const float PI = 3.1415927; //可以交换const与float的位置 符号常量在声明时一定要 ...
- Netty实现心跳机制
netty心跳机制示例,使用Netty实现心跳机制,使用netty4,IdleStateHandler 实现.Netty心跳机制,netty心跳检测,netty,心跳 本文假设你已经了解了Netty的 ...
- lxml爬取实验
1.豆瓣 爬取单个页面数据 import requests from lxml import etree #import os url = "https://movie.douban.com ...
- VIM中的特殊字符
0.简介 在linux中vim查看一个windows下的文本文件, 经常在行尾有一个 ^M. 这其实是windows/linux/mac系统中文本换行不一致的原因导致的, 系统类别 文本换行符 转义字 ...
- react-native项目中禁止截屏与录屏
在android/app/src/main/java/com/projname/MainActivity.java文件中的onCreate方法添加一下代码即可 import android.view. ...