NLP相似度之tf-idf计算
当然,在学习过程中也是参考了很多其他的资料,代码都是一行一行敲出来的。
一、将多个文件合并成一个文件,避免频繁的打开和关闭
import sys for line in sys.stdin:
ss = line.strip().split('\t')
file_name = ss[0].strip()
file_context = ss[1].strip()
word_list = file_context.split(' ') word_set = set()
for word in word_list:
word_set.add(word) for word in word_set:
print '\t'.join([word, ''])
执行命令:就可以得到合并后的文件啦!!!
python convert.py input_tfidf_dir/ > merge_files.data
tf-idf计算流程图:
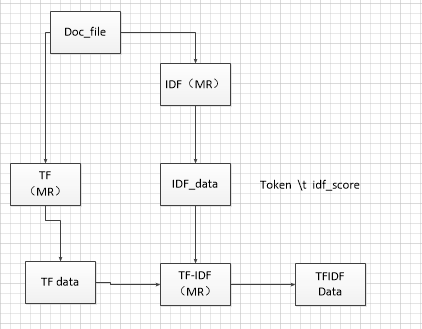
二 、计算IDF的值:
map阶段:读取每一行
import sys for line in sys.stdin:
ss = line.strip().split('\t')
file_name = ss[0].strip()
file_context = ss[1].strip()
word_list = file_context.split(' ') word_set = set()
for word in word_list:
word_set.add(word) for word in word_set:
print '\t'.join([word, ''])
reduce阶段:
import sys
import math current_word = None
doc_cnt = 508
count_pool = []
sum = 0 for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue word, val = ss
if current_word == None:
current_word = word
if current_word != word:
for count in count_pool:
sum += count idf_score = math.log(float(doc_cnt) / (float(sum) + 1))
print '\t'.join([current_word, str(idf_score)]) current_word = word
count_pool = []
sum = 0 count_pool.append((int(val))) for count in count_pool:
sum += count idf_score = math.log(float(doc_cnt) / (float(sum) + 1))
print '\t'.join([current_word, str(idf_score)])
三、计算TF的值:
# 计算tf
# 读取合并后的数据
# 执行命令 cat merge_files.data | python map_tf.py mapper_func idf.data import sys word_dict = {}
idf_dict = {} # 读取计算的idf数据文件
def read_idf_file_func(idf_file_fd):
with open() as fd:
for line in fd:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
token = ss[0].strip()
idf_score = ss[1].strip()
idf_dict[token] = float(idf_score)
return idf_dict # cat merge_files.data | python map_tf.py mapper_func
def mapper_func(idf_file_fd):
idf_dict = read_idf_file_func(idf_file_fd)
# 标准输入
for line in sys.stdin:
ss = line.strip().split('\t')
file_name = ss[0].strip()
file_context = ss[1].strip()
word_list = file_context.split(' ') for word in word_list:
if word not in word_dict:
word_dict[word] = 1
else:
word_dict[word] += 1 for k,v in word_dict.item():
if k not in idf_dict:
continue
print(file_name,k,v,idf_file_fd[k])
print(k,v) if __name__ == "__main__":
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
NLP相似度之tf-idf计算的更多相关文章
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
随机推荐
- QSS 记录
1.border-style 属性分别有 none 定义无边框. hidden 与 "none" 相同.不过应用于表时除外,对于表,hidden 用于解决边框冲突. dotted ...
- Java源码阅读顺序
阅读顺序参考链接:https://blog.csdn.net/qq_21033663/article/details/79571506 阅读源码:JDK 8 计划阅读的package: 1.java. ...
- 『Python』为什么调用函数会令引用计数+2
一.问题描述 Python中的垃圾回收是以引用计数为主,分代收集为辅,引用计数的缺陷是循环引用的问题.在Python中,如果一个对象的引用数为0,Python虚拟机就会回收这个对象的内存. sys.g ...
- Vant UI 安装
一:安装 npm i vant -S 二.引入组件(共有三个方法) 方法一:使用 babel-plugin-import (推荐) 1. 安装 babel-plugin-import 插件 npm i ...
- 命令“copy /V 已退出,代码为 1
这个错误出现在vs生成事件里的命令行里. 第一种:简单粗暴直接清空命令行 第二种:通过输出的打印结果来分析: 比如我的出现这个原因一般有两种情况: 第一种:是可能我引用的共享盘Z盘无法连接: 第二种: ...
- vscode相关配置
一.插件 二.首先项设置: { "git.enableSmartCommit": true, "gitlens.advanced.messages": { &q ...
- python - 列表,元组
1.列表 定义:能装对象的对象 在python中使用[] 来描述列表,内部元素用逗号隔开,对数据类型没有要求. 列表存在索引和切片,和字符串的操作是一样的 2.列表相关 ...
- 通讯录管理系统(C语言)
/* * 对通讯录进行插入.删除.排序.查找.单个显示功能 */ #include <stdio.h> #include <malloc.h> #include <str ...
- 第二课 ---git时光穿梭(版本回退)
1. git status 掌握仓库当前的状态. 2. git diff 查看修改的内容部分. //版本回退: 1.查看更新的历史记录. git log git log --pretty=o ...
- 总结const、readonly、static三者的区别
const:静态常量,也称编译时常量(compile-time constants),属于类型级,通过类名直接访问,被所有对象共享! a.叫编译时常量的原因是它编译时会将其替换为所对应的值: b.静态 ...