HBase Client JAVA API
旧 的 HBase 接口逻辑与传统 JDBC 方式很不相同,新的接口与传统 JDBC 的逻辑更加相像,具有更加清晰的 Connection 管理方式。
同时,在旧的接口中,客户端何时将 Put 写到服务端也需要设置,一个 Put 马上写到服务端,还是攒到一批写到服务端,新用户往往对此不太清楚。
在新的接口中,引入了 BufferedMutator,可以提供更加高效清晰的写操作。
HBase 0.98 与 HBase 1.0 接口名称对比

举一个例子,旧的 API 写入操作的代码:

新的 API 写入操作的代码:

可以看到,在操作前,首先建立连接,然后拿到一个对应表的句柄,之后再进行一系列操作。以上两个是同步写操作。
下面看一下批量异步写入接口:
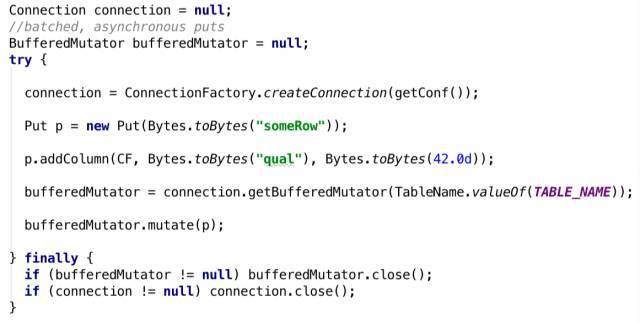
org.apache.hadoop.hbase.client.BufferedMutator主要用来对HBase的单个表进行操作。它和Put类的作用差不多,但是主要用来实现批量的异步写操作。
BufferedMutator替换了HTable的setAutoFlush(false)的作用。
可以从Connection的实例中获取BufferedMutator的实例。在使用完成后需要调用close()方法关闭连接。对BufferedMutator进行配置需要通过BufferedMutatorParams完成。
MapReduce Job的是BufferedMutator使用的典型场景。MapReduce作业需要批量写入,但是无法找到恰当的点执行flush。
BufferedMutator接收MapReduce作业发送来的Put数据后,会根据某些因素(比如接收的Put数据的总量)启发式地执行Batch Put操作,且会异步的提交Batch Put请求,这样MapReduce作业的执行也不会被打断。
BufferedMutator也可以用在一些特殊的情况上。MapReduce作业的每个线程将会拥有一个独立的BufferedMutator对象。
一个独立的BufferedMutator也可以用在大容量的在线系统上来执行批量Put操作,但是这时需要注意一些极端情况比如JVM异常或机器故障,此时有可能造成数据丢失。
官方源码路径:/hbase-2.0.4/hbase-examples/src/main/java/org/apache/hadoop/hbase/client/example/BufferedMutatorExample.java
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hbase.client.example; import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.BufferedMutator;
import org.apache.hadoop.hbase.client.BufferedMutatorParams;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.yetus.audience.InterfaceAudience;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* An example of using the {@link BufferedMutator} interface.
*/
@InterfaceAudience.Private
public class BufferedMutatorExample extends Configured implements Tool { private static final Logger LOG = LoggerFactory.getLogger(BufferedMutatorExample.class); private static final int POOL_SIZE = 10;
private static final int TASK_COUNT = 100;
private static final TableName TABLE = TableName.valueOf("foo");
private static final byte[] FAMILY = Bytes.toBytes("f"); @Override
public int run(String[] args) throws InterruptedException, ExecutionException, TimeoutException { /** a callback invoked when an asynchronous write fails. */
final BufferedMutator.ExceptionListener listener = new BufferedMutator.ExceptionListener() {
@Override
public void onException(RetriesExhaustedWithDetailsException e, BufferedMutator mutator) {
for (int i = 0; i < e.getNumExceptions(); i++) {
LOG.info("Failed to sent put " + e.getRow(i) + ".");
}
}
};
BufferedMutatorParams params = new BufferedMutatorParams(TABLE)
.listener(listener); //
// step 1: create a single Connection and a BufferedMutator, shared by all worker threads.
//
try (final Connection conn = ConnectionFactory.createConnection(getConf());
final BufferedMutator mutator = conn.getBufferedMutator(params)) { /** worker pool that operates on BufferedTable instances */
final ExecutorService workerPool = Executors.newFixedThreadPool(POOL_SIZE);
List<Future<Void>> futures = new ArrayList<>(TASK_COUNT); for (int i = 0; i < TASK_COUNT; i++) {
futures.add(workerPool.submit(new Callable<Void>() {
@Override
public Void call() throws Exception {
//
// step 2: each worker sends edits to the shared BufferedMutator instance. They all use
// the same backing buffer, call-back "listener", and RPC executor pool.
//
Put p = new Put(Bytes.toBytes("someRow"));
p.addColumn(FAMILY, Bytes.toBytes("someQualifier"), Bytes.toBytes("some value"));
mutator.mutate(p);
// do work... maybe you want to call mutator.flush() after many edits to ensure any of
// this worker's edits are sent before exiting the Callable
return null;
}
}));
} //
// step 3: clean up the worker pool, shut down.
//
for (Future<Void> f : futures) {
f.get(5, TimeUnit.MINUTES);
}
workerPool.shutdown();
} catch (IOException e) {
// exception while creating/destroying Connection or BufferedMutator
LOG.info("exception while creating/destroying Connection or BufferedMutator", e);
} // BufferedMutator.close() ensures all work is flushed. Could be the custom listener is
// invoked from here.
return 0;
} public static void main(String[] args) throws Exception {
ToolRunner.run(new BufferedMutatorExample(), args);
}
}
HBase Client JAVA API的更多相关文章
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
- 5 hbase-shell + hbase的java api
本博文的主要内容有 .HBase的单机模式(1节点)安装 .HBase的单机模式(1节点)的启动 .HBase的伪分布模式(1节点)安装 .HBase的伪分布模式(1节点)的启动 .HBase ...
- HBase的Java Api连接失败的问题及解决方法
分布式方式部署的HBase,启动正常,Shell操作正常,使用HBase的Java Api操作时总是连接失败,信息如下: This server is in the failed servers li ...
- hbase-shell + hbase的java api
本博文的主要内容有 .HBase的单机模式(1节点)安装 .HBase的单机模式(1节点)的启动 .HBase的伪分布模式(1节点)安装 .HBase的伪分布模式(1节点)的启动 .HBas ...
- linux 下通过过 hbase 的Java api 操作hbase
hbase版本:0.98.5 hadoop版本:1.2.1 使用自带的zk 本文的内容是在集群中创建java项目调用api来操作hbase,主要涉及对hbase的创建表格,删除表格,插入数据,删除数据 ...
- Hbase之Java API远程访问Kerberos认证
HbaseConnKer.java package BigData.conn; import BigData.utils.resource.ResourcesUtils; import org.apa ...
- Hbase/Hadoop Java API编程常用语句
从scanner获取rowkey: for(Result rr : scanner){ String key =Bytes.toString(rr.getRow())} HBase API - Res ...
- Hbase之JAVA API不能远程访问问题解决
1.配置Linux的hostname2.配置Linux的hosts,映射ip的hostname的关系3.配置访问windows的hosts 参考文档:http://blog.csdn.net/ty49 ...
- windows上使用metastore client java api链接hive metastore问题
https://github.com/sdravida/hadoop2.6_Win_x64 下载winutils.exe 添加到path中
随机推荐
- .NET Core微服务系列基础文章索引(目录导航Draft版)
一.为啥要写这个系列? 今年从原来的Team里面被抽出来加入了新的Team,开始做Java微服务的开发工作,接触了Spring Boot, Spring Cloud等技术栈,对微服务这种架构有了一个感 ...
- Python2中文处理纪要
python2不是以unicode作为基本代码字符类型,碰到乱码的几率是远远高于python3,但即便如此,相信很多人,也不想随意的迁移到python3,这里就总结几个我平常碰到的问题及解法. 文件中 ...
- 对于ASP.NET MVC中页面强类型的个人理解
进入ASP.NET MVC学习 发现很多和winfrom不同的东西,但是利用的C#语言还是没有变化,更多的是利用了新的语言,html jquery ajax.....唉 心累,一本书一本书看的去 看完 ...
- 如何合理封装你的轮子、飞机、大炮(以封装OkHttp为例)
前言 对于程序员来说,很多时候,我们都在造房子,从学会框架或者是学会构建整个项目之后,慢慢的我们就会觉得自己在做的事情是一种重复劳动,很多时候只不过是换个面孔而已.而更快的造房子,造好看的房子可能是进 ...
- [开源]快速构建一个WebApi项目
项目代码:MasterChief.DotNet.ProjectTemplate.WebApi 示例代码:https://github.com/YanZhiwei/MasterChief.Project ...
- Java开发知识之Java入门
Java开发知识之Java入门 一丶了解JAVA的版本 JAVA 有三个版本 JAVA SE: 标准版,开发桌面跟商务应用程序 JAVA SE 包括了Java的核心类库,集合,IO 数据库连接 以及网 ...
- RDIFramework.NET ━ .NET快速信息化系统开发框架 V3.2-> “Tab”标签新增可“最大化”显示功能
最大化工作区的功能是非常必要的,特别是当模块功能比较多时,把工作区最大的展现出来就变得很重要,RDIFramework.NET V3.2版本对工作区新增了最大功能,最大化工作区后如下图所示: 具体使 ...
- 10年架构师告诉你,他眼中的Spring容器是什么样子的
相关文章 如何慢慢地快速成长起来? 成长的故事之Spring Core系列 你是如何看待Spring容器的,是这样子吗? Spring的启动过程,你有认真思考过吗?(待写) 面向切面编程,你指的是Sp ...
- 免费报名 | 腾讯云自研数据库CynosDB交流会
本文由云+社区发表 作者:技术沙龙 All in 云+时代,数据库的高可用性.按需付费.按需扩展等属性解放了大批开发者.腾讯发布的自研数据库CynosDB作为国内首款同时兼容MySQL和PG的云原生数 ...
- AlwaysUp使用方法
AlwaysUp是一款能将可执行文件.批处理文件及快捷方式作为Windows系统服务,并且进行管理和监视确保100%运行.当程序崩溃.挂起.弹出错误对话框时,AlwaysUp 能自动重启程序,并运行自 ...