【Storm篇】--Storm从初始到分布式搭建
一、前述
Storm是一个流式处理框架,相比较于SparkStreaming是一个微批处理框架,hadoop是一个批处理框架。
二 、搭建流程
1.集群规划
Nimbus Supervisor Zookeeper
node01 1
node02 1 1
node03 1 1
node04 1 1
2.配置
node01作为nimbus。
vim conf/storm.yaml
storm.zookeeper.servers:
- "node02"
- "node03"
- "node04" storm.local.dir: "/tmp/storm" nimbus.host: "node01" supervisor.slots.ports:
-
-
-
-
PS:supervisor.slots.ports 相当于启动4个worker进程
配置一定要顶格写!!!!!!!
3.创建log文件
在storm目录中创建logs目录
mkdir logs启动ZooKeeper集群
4.启动服务
node1上启动Nimbus
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
tail -f logs/nimbus.log
./bin/storm ui >> ./logs/ui.out 2>&1 &
tail -f logs/ui.log 节点node02和node03,node04启动supervisor,按照配置,每启动一个supervisor就有了4个slots
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
tail -f logs/supervisor.log
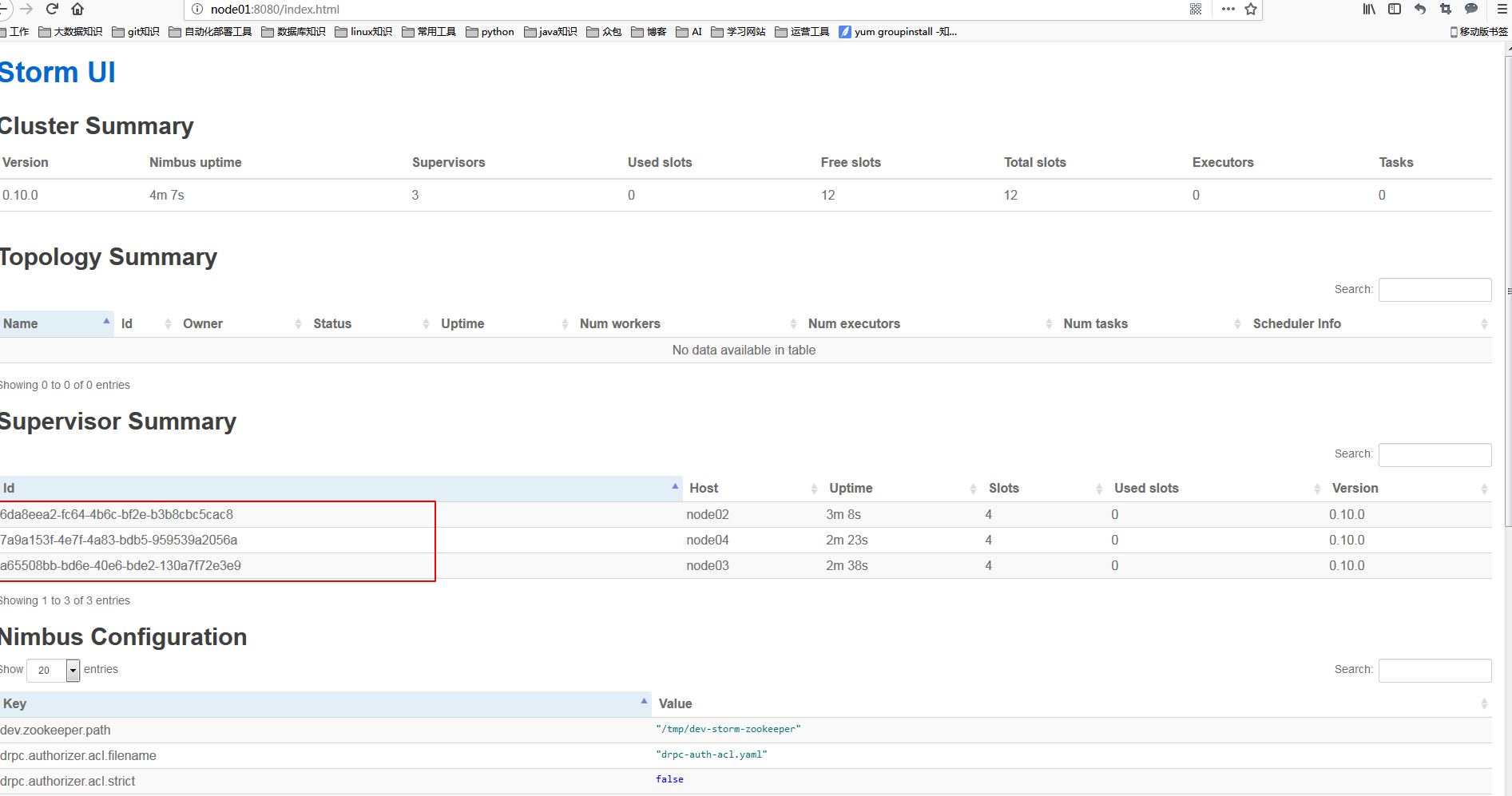
(当然node1也可以启动supervisor) http://node1:8080/
提交任务到Storm集群当中运行:
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test 环境变量可以配置也可以不配置
export STORM_HOME=/opt/sxt/storm
export PATH=$PATH:$STORM_HOME/bin
【Storm篇】--Storm从初始到分布式搭建的更多相关文章
- Storm伪分布式搭建
配置zookeeper 下载zookeeper tar包 解压:tar -zxvf zookeeper-3.4.10.tar.gz -C /root/training/ 配置 cd /root/tra ...
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- 【Storm篇】--Storm基础概念
一.前述 Storm是个实时的.分布式以及具备高容错的计算系统,Storm进程常驻内存 ,Storm数据不经过磁盘,在内存中处理. 二.相关概念 1.异步: 流式处理(异步)客户端提交数据进行结算,并 ...
- 【Storm】Storm实战之频繁二项集挖掘
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
- 【Storm】Storm实战之频繁二项集挖掘(附源码)
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
- 第三篇——第二部分——第二文 计划搭建SQL Server镜像
原文:第三篇--第二部分--第二文 计划搭建SQL Server镜像 本文紧跟上一章:SQL Server镜像简介 本文出处:http://blog.csdn.net/dba_huangzj/arti ...
- Centos7完全分布式搭建Hadoop2.7.3
(一)软件准备 1,hadoop-2.7.3.tar.gz(包) 2,三台机器装有cetos7的机子 (二)安装步骤 1,给每台机子配相同的用户 进入root : su root ---------& ...
随机推荐
- 利用Skywalking-netcore监控你的应用性能
Skywalking SkyWalking开源项目由吴晟于2015年创建,同年10月在GitHub上作为个人项目开源. SkyWalking项目的核心目标,是针对微服务.Cloud Native.容器 ...
- 003 css总结
1.题目 有哪项方式可以对一个DOM设置它的CSS样式? CSS都有哪些选择器? CSS选择器的优先级是怎么样定义的? CSS中可以通过哪些属性定义,使得一个DOM元素不显示在浏览器可视范围内? 超链 ...
- 部署ceph
前提:因为ceph部署时要去国外源下载包,导致下载安装时会卡住,因此我们只需通过国内的源找到对应的rpm下载安装. 一.环境准备 4台机器,1台机器当部署节点和客户端,3台ceph节点,ceph节点配 ...
- 关于WinCC OA
简介 WinCC OA 的全称是:SIMATIC WinCC Open Architecture,是奥地利ETM公司(ETM professional control GmbH)开发的SCADA软件系 ...
- hadoop hdfs ha 模式
这是我自己在公司一个搭建公司大数据框架是自己的选项,在配置yarn ha 出现了nodemanager起不来的问题于是我把yarn搭建为普通yarn 如果有人解决 高yarn的nodemanager问 ...
- tensorflow 使用 2 Felch ,Feed
Felch ::在会话里可以执行多个 op , import tensorflow as tf input1 = tf.constant(3.0) input2 = tf.constant(2.0) ...
- SpringBoot整合多数据源实现
项目架构 1.导入相关依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifac ...
- Cocos2d-js和Android交互
说白了,就是JavaScript和Java之间的函数互相调用. 先看一下效果 有了这个交互,为了以后接sdk做准备. 要点: javascript调用java: jsb.reflection.call ...
- Web开发者の实用代码账簿
介里就都是恶魔菌整理的我平时会用的代码啦-现在在这里总结规划一下,希望能对你以及其他阅读这篇文章的小可耐们有帮助喵!欢迎订阅我的博客来get恶魔菌记事簿的新动态鸭! ↓ ↓ ↓ 以下就是内容啦~记得看 ...
- python中的单向循环链表实现
引子 所谓单向循环链表,不过是在单向链表的基础上,如响尾蛇般将其首尾相连,也因此有诸多类似之处与务必留心之点.尤其是可能涉及到头尾节点的操作,不可疏忽. 对于诸多操所必须的遍历,这时的条件是什么?又应 ...